文章目录
- 网络协议栈基础知识回顾
- 网络分层
- 网络分层的目的
- 各层作用简介
- 延伸-ip地址,有类,无类,cidr
- socket实现分析
- tcp/udp回顾
- socket编程回顾
- TCP编程回顾
- UDP编程回顾
- 差异
- socket相关接口实现浅析
- sokcet实现解析
- 创建socket的三个参数
- socket函数定义及其参数
- 创建socket结构体
- 关联文件描述符
- bind实现解析
- listen实现解析
- accept实现解析
- connect实现解析
- connect入口
- TCP连接建立处理过程分析
- 三次握手-客户端发送SYC报文
- 三次握手-服务端接收SYC,回复SYC-ACK
- 三次握手-客户端接收SYC-ACK,回复ACK
- 三次握手-服务端接收ACK报文
- 函数调用总览图
- 状态变化总览图
- linux内核中的面向对象
- linux内核socket实现变动
- 数据包的发送与接收
- 数据包发送
- 数据包接收
- 转发流程简述
网络协议栈基础知识回顾
网络分层
各网络分层协议的举例
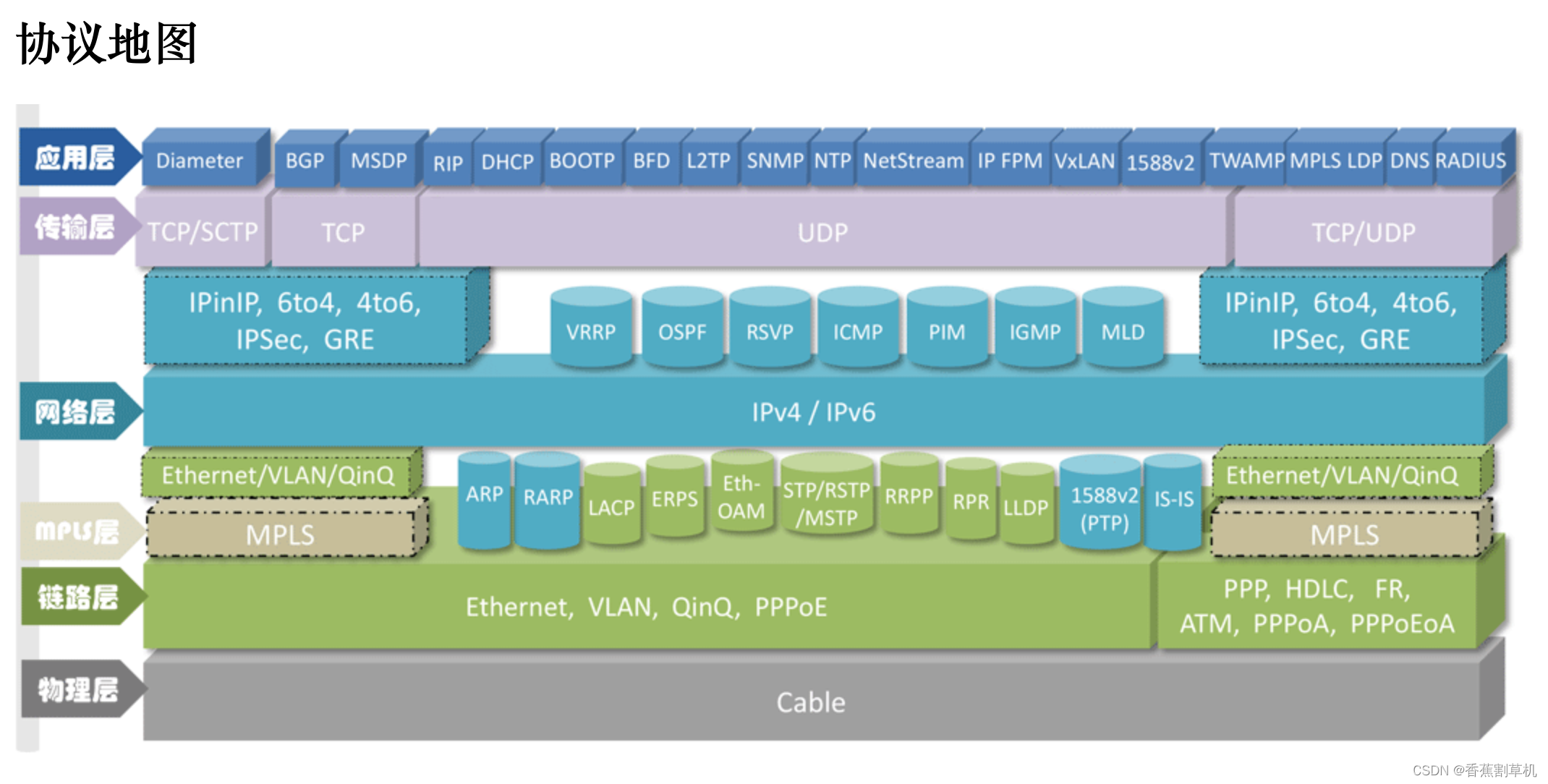
网络分层的目的
网络分层目的:因为网络环境过于复杂,不是一个能够集中控制的体系。全球数以亿计的服务器和设备各有各的体系,但是都可以通过同一套网络协议栈通过切分成多个层次和组合,来满足不同服务器和设备的通信需求。
举例:一个数据包的发送
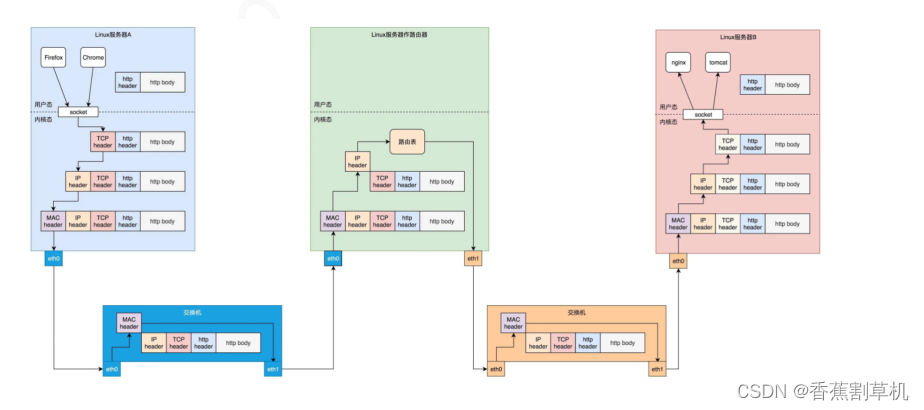
网络分层后,交换机只需要实现二层,路由器只需要实现二三层。
各层作用简介
以陆运运送货物为例子,类比网络分层的作用,此处片面的描述作用范围。

经过三层转发时,每次源目的mac全部会变更,而源目的ip是肯定不会变的。
首先货物要包装好,然后发件人填写发件人的名字和收件人的名字(源目的端口号),填写收件人和发件人的地址(源目的ip),查看离自己最近的网点(比如某xx驿站)的地址把货物送出(默认路由和目的mac),货物会从网点出发,经过一个个中转站,最终把货物送达最后一个中转站,然后由中转站又到达了某某网点,快递员配送到收件人手中。
延伸-ip地址,有类,无类,cidr
ABCDE类ip地址
网络号主机号
可变长子网掩码
cidr
socket实现分析
操作系统选择对于网络协议的实现模式是,二到四层的处理代码在内核里面,七层的处理代码让应用自己去做,两者需要跨内核态和用户态通信,就需要一个系统调用完成这个衔接,这就是 Socket。
tcp/udp回顾
两个传输层协议的区别:
- TCP 是面向连接的,UDP 是面向无连接的。
- TCP 提供可靠交付,无差错、不丢失、不重复、并且按序到达;UDP 不提供可靠交付,不保证不丢失,不保证按顺序到达。
- TCP 是面向字节流的,发送时发的是一个流,没头没尾;UDP 是面向数据报的,一个一个地发送。
- TCP 是可以提供流量控制和拥塞控制的,既防止对端被压垮,也防止网络被压垮。
问题:
- 所谓的连接,容易让人误以为,使用 TCP 会使得两端之间的通路和使用 UDP 不一样,那我们会在沿途建立一条线表示这个连接吗?
- 我从中国访问美国网站,中间这么多环节,我怎么保证连接不断呢?
- 中间有个网络管理员拔了一根网线不就断了吗?我不能控制它,它也不会通知我,我一个个人电脑怎么能够保持连接呢?
- 还让我做流量控制和拥塞控制,我既管不了中间的链路,也管不了对端的服务器呀,我怎么能够做到?
- 按照网络分层,TCP 和 UDP 都是基于 IP 协议的,IP 都不能保证可靠,说丢就丢,TCP 怎么能够保证呢?
- IP 层都是一个包一个包地发送,TCP 怎么就变成流了?
解答:
1.连接代表一种状态,不是和广域网通信中电路交换一样有一条专用线路,实际tcp无法决定中间经过的线路。所谓的连接,就是两端数据结构状态的协同,两边的状态能够对得上。
2和3.符合 TCP 协议的规则,就认为连接存在;两面状态对不上,连接就算断了,所以中间环节的通断不代表tcp的通断
4.流量控制和拥塞控制其实就是根据收到的对端的网络包,调整两端数据结构的状态。TCP 协议的设计理论上认为,这样调整了数据结构的状态,就能进行流量控制和拥塞控制了,其实在通路上是不是真的做到了,谁也管不着。
5.所谓的可靠,也是两端的数据结构做的事情。不丢失其实是数据结构在“点名”,顺序到达其实是数据结构在“排序”,面向数据流其实是数据结构将零散的包,按照顺序捏成一个流发给应用层。总而言之,“连接”两个字让人误以为功夫在通路,其实功夫在两端。
6.在上层接收者的角度,tcp的报文是流的形式。
socket编程回顾
int socket(int domain, int type, int protocol);
socket 函数用于创建一个 socket 的文件描述符,唯一标识一个 socket。
socket 函数有三个参数,这里我们只讨论tcp/udp相关的。
- domain:表示使用什么 IP 层协议。AF_INET 表示 IPv4,AF_INET6 表示 IPv6。
- type:表示 socket 类型。SOCK_STREAM,顾名思义就是 TCP 面向流的,SOCK_DGRAM 就是 UDP 面向数据报的,SOCK_RAW 可以直接操作 IP 层。
- protocol 表示的协议,包括 IPPROTO_TCP、IPPTOTO_UDP。
返回值为句柄
通信结束后,我们还要像关闭文件一样,关闭 socket。
TCP编程回顾
相关的系统API接口如下

UDP编程回顾

差异
可以看到udp通信,没有listen-accept-connect,但是都有socket,bind,发送接收。udp不存在客户端和服务端的概念,大家就都是客户端,也同时都是服务端。
socket相关接口实现浅析
用户态与内核态通信的最常用的方法就是系统调用,这里以socket系列函数为切入点,来学习内核的相关知识。
sokcet实现解析
创建socket的三个参数
在创建 Socket 的时候,有三个参数。
一个是 family,表示地址族。第二个参数是 type,也即 Socket 的类型。第三个参数是 protocol,是协议。协议数目是比较多的,也就是说,多个协议会属于同一种类型。
接下来对这三个参数简单看一下。
首先是地址族
/* Supported address families. */
#define AF_UNSPEC 0
#define AF_UNIX 1 /* Unix domain sockets */
#define AF_LOCAL 1 /* POSIX name for AF_UNIX */
#define AF_INET 2 /* Internet IP Protocol */
...
#define AF_ATMPVC 8 /* ATM PVCs */
#define AF_X25 9 /* Reserved for X.25 project */
#define AF_INET6 10 /* IP version 6 */
...
#define AF_NETLINK 16
#define AF_ROUTE AF_NETLINK /* Alias to emulate 4.4BSD */
#define c 17 /* Packet family */
...
#define AF_ATMSVC 20 /* ATM SVCs */
...
#define AF_ISDN 34 /* mISDN sockets */
...
#define AF_MAX 41 /* For now.. */
其中比较常见的比如代表IPV4和IPV6的AF_INET及AF_INET6,以及常用的域套接字AF_UNIX以及netlink的AF_NETLINK,还有二层的AF_PACKET;其中也有可能是广域网传输协议的ATM,X.25,ISDN等,他们都是广域网的基于分组交换的传输协议。像其中AF_ATMPVC为ATM的永久虚电路,AF_ATMSVC为交换虚电路。
接下来是socket类型
/**
* enum sock_type - Socket types
* @SOCK_STREAM: stream (connection) socket
* @SOCK_DGRAM: datagram (conn.less) socket
* @SOCK_RAW: raw socket
* @SOCK_RDM: reliably-delivered message
* @SOCK_SEQPACKET: sequential packet socket
* @SOCK_DCCP: Datagram Congestion Control Protocol socket
* @SOCK_PACKET: linux specific way of getting packets at the dev level.
* For writing rarp and other similar things on the user level.
*
* When adding some new socket type please
* grep ARCH_HAS_SOCKET_TYPE include/asm-* /socket.h, at least MIPS
* overrides this enum for binary compat reasons.
*/
enum sock_type {
SOCK_STREAM = 1,
SOCK_DGRAM = 2,
SOCK_RAW = 3,
SOCK_RDM = 4,
SOCK_SEQPACKET = 5,
SOCK_DCCP = 6,
SOCK_PACKET = 10,
};
解释如下:
SOCK_STREAM: 提供面向连接的稳定数据传输,流式传输。
SOCK_DGRAM: 使用不连续不可靠的数据包连接。
SOCK_SEQPACKET: 提供连续可靠的数据包连接。
SOCK_RAW: 提供原始网络协议存取。
SOCK_RDM: 提供可靠的数据包连接。
SOCK_DCCP: 数据报拥塞控制协议(Datagram Congestion Control Protocol)
SOCK_PACKET: 与网络驱动程序直接通信。
最后看下协议,先看inet4的:
/* Standard well-defined IP protocols. */
enum {
IPPROTO_IP = 0, /* Dummy protocol for TCP */
#define IPPROTO_IP IPPROTO_IP
IPPROTO_ICMP = 1, /* Internet Control Message Protocol */
#define IPPROTO_ICMP IPPROTO_ICMP
IPPROTO_IGMP = 2, /* Internet Group Management Protocol */
#define IPPROTO_IGMP IPPROTO_IGMP
IPPROTO_IPIP = 4, /* IPIP tunnels (older KA9Q tunnels use 94) */
...
IPPROTO_RAW = 255, /* Raw IP packets */
#define IPPROTO_RAW IPPROTO_RAW
IPPROTO_MAX
};
其实对于协议,每种协议族可能是不同的,比如netlink的protocol:
#define NETLINK_ROUTE 0 /* Routing/device hook */
#define NETLINK_UNUSED 1 /* Unused number */
#define NETLINK_USERSOCK 2 /* Reserved for user mode socket protocols */
...
#define MAX_LINKS 32
再比如unix socket,更是限定了只能是0或者PF_UNIX。
socket函数定义及其参数
socket函数在内核中的定义为:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
//code
}
Linux的系统调用在内核中的入口函数都是 sys_xxx ,因此socket的调用应该是:
asmlinkage long sys_socket(int, int, int);
真正定义代码不是sys_socket的原因可以参考之前系统初始化章节讲述的内容。简单来说,内核通过复杂的宏定义做了转换。这里只需要知道,在用户态调用socket后,后续就会陷入内核态来执行sys_socket就行了,也就是SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)这个宏所定义的函数。
接着看代码:
SYSCALL_DEFINE3(socket, int, family, int, type, int, protocol)
{
int retval;
struct socket *sock;
int flags;
......
if (SOCK_NONBLOCK != O_NONBLOCK && (flags & SOCK_NONBLOCK))
flags = (flags & ~SOCK_NONBLOCK) | O_NONBLOCK;
retval = sock_create(family, type, protocol, &sock);
......
retval = sock_map_fd(sock, flags & (O_CLOEXEC | O_NONBLOCK));
......
return retval;
}
Socket 系统调用会调用 sock_create 创建一个 struct socket 结构,然后通过 sock_map_fd 和文件描述符对应起来。
下面分两步看socket的实现,即socket结构的创建与和文件描述符的关联。
创建socket结构体
前面提到的sock_create实际调用了__sock_create。
int sock_create(int family, int type, int protocol, struct socket **res)
{
return __sock_create(current->nsproxy->net_ns, family, type, protocol, res, 0);
}
代码主要逻辑如下:
int __sock_create(struct net *net, int family, int type, int protocol,
struct socket **res, int kern)
{
int err;
struct socket *sock;
const struct net_proto_family *pf;
......
/*
* Allocate the socket and allow the family to set things up. if
* the protocol is 0, the family is instructed to select an appropriate
* default.
*/
sock = sock_alloc();
......
sock->type = type;//类型在此处赋值
......
pf = rcu_dereference(net_families[family]);
......
err = pf->create(net, sock, protocol, kern);
......
*res = sock;
return 0;
}
可以看到代码中首先分配了一个 struct socket 结构。然后从net_families取了个net_proto_family类型的结构体的指指针用来初始化刚创建的socket结构体,最后返回回去。
在此处,所有类型的地址族都会在net_families中注册对应的结构体成员,并在此处可以用前面看过的family的参数取出注册的内容。
其结构体定义如下:
struct net_proto_family {
int family;
int (*create)(struct net *net, struct socket *sock,
int protocol, int kern);
struct module *owner;
};
如上代码所述,实际调用的就是里面的create函数指针。
这里以几种常见协议族为例,看下注册的内容:
static const struct net_proto_family inet_family_ops = {
.family = PF_INET,
.create = inet_create,
.owner = THIS_MODULE,
};
static const struct net_proto_family netlink_family_ops = {
.family = PF_NETLINK,
.create = netlink_create,
.owner = THIS_MODULE, /* for consistency 8) */
};
static const struct net_proto_family packet_family_ops = {
.family = PF_PACKET,
.create = packet_create,
.owner = THIS_MODULE,
};
static const struct net_proto_family unix_family_ops = {
.family = PF_UNIX,
.create = unix_create,
.owner = THIS_MODULE,
};
再以PF_INET为例看下注册,sock_register其实就是把ops注册到数组中去了:
/*
* Tell SOCKET that we are alive...
*/
(void)sock_register(&inet_family_ops);
继续看inet_create的实现,只列出关键实现:
static int inet_create(struct net *net, struct socket *sock, int protocol, int kern)
{
struct sock *sk;
struct inet_protosw *answer;
struct inet_sock *inet;
struct proto *answer_prot;
unsigned char answer_flags;
int try_loading_module = 0;
int err;
sock->state = SS_UNCONNECTED;//初始化socket状态
/* Look for the requested type/protocol pair. */
lookup_protocol:
list_for_each_entry_rcu(answer, &inetsw[sock->type], list) {
err = 0;
/* Check the non-wild match. */
if (protocol == answer->protocol) {//比较是否是用户指定的协议
if (protocol != IPPROTO_IP)
break;
} else {
/* Check for the two wild cases. */
if (IPPROTO_IP == protocol) {
protocol = answer->protocol;
break;
}
if (IPPROTO_IP == answer->protocol)
break;
}
err = -EPROTONOSUPPORT;
}
......
sock->ops = answer->ops;//赋值
answer_prot = answer->prot;
answer_flags = answer->flags;
......
sk = sk_alloc(net, PF_INET, GFP_KERNEL, answer_prot, kern);//会在内部将answer_prot赋值给sk
......
inet = inet_sk(sk);
inet->nodefrag = 0;
if (SOCK_RAW == sock->type) {
inet->inet_num = protocol;//在这里指定协议
if (IPPROTO_RAW == protocol)
inet->hdrincl = 1;
}
inet->inet_id = 0;
sock_init_data(sock, sk);//将sk状态初始化为TCP_CLOSE
sk->sk_destruct = inet_sock_destruct;
sk->sk_protocol = protocol;
sk->sk_backlog_rcv = sk->sk_prot->backlog_rcv;
inet->uc_ttl = -1;
inet->mc_loop = 1;
inet->mc_ttl = 1;
inet->mc_all = 1;
inet->mc_index = 0;
inet->mc_list = NULL;
inet->rcv_tos = 0;
if (inet->inet_num) {
inet->inet_sport = htons(inet->inet_num);
/* Add to protocol hash chains. */
err = sk->sk_prot->hash(sk);
}
if (sk->sk_prot->init) {
err = sk->sk_prot->init(sk);
}
......
}
inetsw是一个数组,里面存储了各种socket类型对应的链表,链表中存储了inet_protosw结构体。
这里需要注意的是,可能是因为AF_INET协议族较为复杂,所以才使用了数组inetsw来存储inet的特定类型的特定协议的answer,然后从answer中取得ops,prot等。像unix socket,netlink socket,packet socket等, 都是直接从一个全局结构体变量取就可以了。
在inet_create 的 list_for_each_entry_rcu 循环中,会从 inetsw 数组中,根据 type 找到属于这个类型的列表,然后依次比较列表中的 struct inet_protosw 的 protocol 是不是用户指定的 protocol;如果是,就得到了符合用户指定的 family->type->protocol 的 struct inet_protosw *answer 对象。
而这个inet_protosw是在哪注册的呢?是在inet_init中注册的:
static int __init inet_init(void)
{
struct inet_protosw *q;
struct list_head *r;
int rc = -EINVAL;
...
/* Register the socket-side information for inet_create. */
for (r = &inetsw[0]; r < &inetsw[SOCK_MAX]; ++r)
INIT_LIST_HEAD(r);
for (q = inetsw_array; q < &inetsw_array[INETSW_ARRAY_LEN]; ++q)
inet_register_protosw(q);
...
上面的INIT_LIST_HEAD是给数组中每个类型的链表初始化,而后调用inet_register_protosw,将 inetsw_array 注册到 inetsw 数组里面去,即inetsw中按类型分链表,每个链表存储了同一类型的不同协议的inet_protosw结构体。而inetsw_array内容如下:
/* Upon startup we insert all the elements in inetsw_array[] into
* the linked list inetsw.
*/
static struct inet_protosw inetsw_array[] =
{
{
.type = SOCK_STREAM,
.protocol = IPPROTO_TCP,
.prot = &tcp_prot,
.ops = &inet_stream_ops,
.flags = INET_PROTOSW_PERMANENT |
INET_PROTOSW_ICSK,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_UDP,
.prot = &udp_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_PERMANENT,
},
{
.type = SOCK_DGRAM,
.protocol = IPPROTO_ICMP,
.prot = &ping_prot,
.ops = &inet_dgram_ops,
.flags = INET_PROTOSW_REUSE,
},
{
.type = SOCK_RAW,
.protocol = IPPROTO_IP, /* wild card */
.prot = &raw_prot,
.ops = &inet_sockraw_ops,
.flags = INET_PROTOSW_REUSE,
}
};
回到inet_create的代码,接下来,struct socket *sock 的 ops 成员变量,被赋值为 answer 的 ops。对于 TCP 来讲,就是 inet_stream_ops。后面任何用户对于这个 socket 的操作,都是通过 inet_stream_ops 进行的。
const struct proto_ops inet_stream_ops = {
.family = PF_INET,
.owner = THIS_MODULE,
.release = inet_release,
.bind = inet_bind,
.connect = inet_stream_connect,
.socketpair = sock_no_socketpair,
.accept = inet_accept,
.getname = inet_getname,
.poll = tcp_poll,
.ioctl = inet_ioctl,
.listen = inet_listen,
.shutdown = inet_shutdown,
.setsockopt = sock_common_setsockopt,
.getsockopt = sock_common_getsockopt,
.sendmsg = inet_sendmsg,
.recvmsg = inet_recvmsg,
.mmap = sock_no_mmap,
.sendpage = inet_sendpage,
.splice_read = tcp_splice_read,
#ifdef CONFIG_COMPAT
.compat_setsockopt = compat_sock_common_setsockopt,
.compat_getsockopt = compat_sock_common_getsockopt,
.compat_ioctl = inet_compat_ioctl,
#endif
};
接下来,创建一个 struct sock *sk 对象。需要注意的是socket和sock这两个变量,socket 和 sock 看起来几乎一样,容易让人混淆,这里需要说明一下,socket 是用于负责对上给用户提供接口,并且和文件系统关联。而 sock,负责向下对接内核网络协议栈。
在 sk_alloc 函数中,struct inet_protosw *answer 结构的 tcp_prot 赋值给了 struct sock *sk 的 sk_prot 成员。tcp_prot 的定义如下,里面定义了很多的函数,都是 sock 之下内核协议栈的动作。
struct proto tcp_prot = {
.name = "TCP",
.owner = THIS_MODULE,
.close = tcp_close,
.connect = tcp_v4_connect,
.disconnect = tcp_disconnect,
.accept = inet_csk_accept,
.ioctl = tcp_ioctl,
.init = tcp_v4_init_sock,
.destroy = tcp_v4_destroy_sock,
.shutdown = tcp_shutdown,
.setsockopt = tcp_setsockopt,
.getsockopt = tcp_getsockopt,
.recvmsg = tcp_recvmsg,
.sendmsg = tcp_sendmsg,
...
};
因此很多ops调用的函数实际最后调用的是prot中的函数。比如ops中的recvmsg函数:
int inet_recvmsg(struct kiocb *iocb, struct socket *sock, struct msghdr *msg,
size_t size, int flags)
{
struct sock *sk = sock->sk;
int addr_len = 0;
int err;
sock_rps_record_flow(sk);
err = sk->sk_prot->recvmsg(iocb, sk, msg, size, flags & MSG_DONTWAIT,
flags & ~MSG_DONTWAIT, &addr_len);
if (err >= 0)
msg->msg_namelen = addr_len;
return err;
}
总的来说,proto_ops结构完成了从与协议无关的套接口层到协议相关的传输层的转接,而proto结构又将传输层映射到网络层。
回到 inet_create 函数中,接下来创建一个 struct inet_sock 结构,这个结构一开始就是 struct sock,然后扩展了一些其他的信息,剩下的代码就填充这些信息。这一幕我们会经常看到,将一个结构放在另一个结构的开始位置,然后扩展一些成员,通过对于指针的强制类型转换,来访问这些成员。
关联文件描述符
接下来看sock_map_fd函数:
static int sock_map_fd(struct socket *sock, int flags)
{
struct file *newfile;
int fd = get_unused_fd_flags(flags);
if (unlikely(fd < 0))
return fd;
newfile = sock_alloc_file(sock, flags, NULL);
if (likely(!IS_ERR(newfile))) {
fd_install(fd, newfile);//完成文件与进程的关联
return fd;
}
put_unused_fd(fd);
return PTR_ERR(newfile);
}
这里可以看到,先获取了一个未使用的文件句柄,然后创建一个socket文件,最后使用fd_install来对应,然后将这个fd返回,最终这个fd将返回给用户,至此sokcet创建结束。
bind实现解析
函数原型
int bind(int sockfd, const struct sockaddr *addr,socklen_t addrlen);
成功返回0,否则返回-1
bind的实现少一点:
/*
* Bind a name to a socket. Nothing much to do here since it's
* the protocol's responsibility to handle the local address.
*
* We move the socket address to kernel space before we call
* the protocol layer (having also checked the address is ok).
*/
SYSCALL_DEFINE3(bind, int, fd, struct sockaddr __user *, umyaddr, int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);//根据句柄找到对应的socket
if (sock) {
err = move_addr_to_kernel(umyaddr, addrlen, &address);
if (err >= 0) {
err = security_socket_bind(sock,
(struct sockaddr *)&address,
addrlen);
if (!err)
err = sock->ops->bind(sock,
(struct sockaddr *)
&address, addrlen);
}
fput_light(sock->file, fput_needed);
}
return err;
}
在 bind 中,sockfd_lookup_light 会根据 fd 文件描述符,找到 struct socket 结构。然后实际使用copy_from_user将 sockaddr 从用户态拷贝到内核态,然后调用 struct socket 结构里面 ops 的 bind 函数。根据前面创建 socket 的时候的设定,调用的是 inet_stream_ops 的 bind 函数,也即调用 inet_bind。
int inet_bind(struct socket *sock, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *addr = (struct sockaddr_in *)uaddr;
struct sock *sk = sock->sk;
struct inet_sock *inet = inet_sk(sk);
struct net *net = sock_net(sk);
unsigned short snum;
......
snum = ntohs(addr->sin_port);
......
inet->inet_rcv_saddr = inet->inet_saddr = addr->sin_addr.s_addr;//监听的ip地址
/* Make sure we are allowed to bind here. */
if ((snum || !inet->bind_address_no_port) &&
sk->sk_prot->get_port(sk, snum)) {
......
}
inet->inet_sport = htons(inet->inet_num);//监听的端口号,赋值在下面说明
inet->inet_daddr = 0;
inet->inet_dport = 0;
sk_dst_reset(sk);
}
bind 里面会调用 sk_prot 的 get_port 函数,也即 inet_csk_get_port 来检查端口是否冲突,是否可以绑定。
在get_port时会调用inet_bind_hash把inet_num设置为用户指定的接口
void inet_bind_hash(struct sock *sk, struct inet_bind_bucket *tb,
const unsigned short snum)
{
inet_sk(sk)->inet_num = snum;//用户sport赋值
sk_add_bind_node(sk, &tb->owners);
inet_csk(sk)->icsk_bind_hash = tb;
}
如果允许,则会设置 struct inet_sock 的本方的地址 inet_saddr 和本方的端口 inet_sport,对方的地址 inet_daddr 和对方的端口 inet_dport 都初始化为 0。
listen实现解析
原型
int listen(int sockfd, int backlog);
backlog为最大连接数
成功返回0,失败返回-1
/*
* Perform a listen. Basically, we allow the protocol to do anything
* necessary for a listen, and if that works, we mark the socket as
* ready for listening.
*/
SYSCALL_DEFINE2(listen, int, fd, int, backlog)
{
struct socket *sock;
int err, fput_needed;
int somaxconn;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (sock) {
somaxconn = sock_net(sock->sk)->core.sysctl_somaxconn;
if ((unsigned int)backlog > somaxconn)//请求队列最大长度
backlog = somaxconn;
err = security_socket_listen(sock, backlog);
if (!err)
err = sock->ops->listen(sock, backlog);
fput_light(sock->file, fput_needed);
}
return err;
}
在 listen 中,我们还是通过 sockfd_lookup_light,根据 fd 文件描述符,找到 struct socket 结构。接着,我们调用 struct socket 结构里面 ops 的 listen 函数。根据前面创建 socket 的时候的设定,调用的是inet_stream_ops 的 listen 函数,也即调用 inet_listen。
int inet_listen(struct socket *sock, int backlog)
{
struct sock *sk = sock->sk;
unsigned char old_state;
int err;
old_state = sk->sk_state;
/* Really, if the socket is already in listen state
* we can only allow the backlog to be adjusted.
*/
if (old_state != TCP_LISTEN) {
err = inet_csk_listen_start(sk, backlog);
}
sk->sk_max_ack_backlog = backlog;
}
如果这个 socket 还不在 TCP_LISTEN 状态,会调用 inet_csk_listen_start 进入监听状态。
int inet_csk_listen_start(struct sock *sk, int backlog)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct inet_sock *inet = inet_sk(sk);
int err = -EADDRINUSE;
reqsk_queue_alloc(&icsk->icsk_accept_queue);
sk->sk_max_ack_backlog = backlog;
sk->sk_ack_backlog = 0;
inet_csk_delack_init(sk);
sk_state_store(sk, TCP_LISTEN);
if (!sk->sk_prot->get_port(sk, inet->inet_num)) {
......
}
......
}
首先,我们遇到的是 icsk_accept_queue。它是干什么的呢?
在 TCP 的状态里面,有一个 listen 状态,当调用 listen 函数之后,就会进入这个状态,虽然我们写程序的时候,一般要等待服务端调用 accept 后,等待在哪里的时候,让客户端就发起连接。其实服务端一旦处于 listen 状态,不用 accept,客户端也能发起连接。其实 TCP 的状态中,没有一个是否被 accept 的状态,那 accept 函数的作用是什么呢?
在内核中,为每个 Socket 维护两个队列。一个是已经建立了连接的队列,这时候连接三次握手已经完毕,处于 established 状态;一个是还没有完全建立连接的队列,这个时候三次握手还没完成,处于 new_syn_rcvd 的状态。
服务端调用 accept 函数,其实是在第一个队列中拿出一个已经完成的连接进行处理。如果还没有完成就阻塞等待。这里的 icsk_accept_queue 就是第一个队列。因此后面解析accept时就会用到他。
初始化完之后,将 TCP 的状态设置为 TCP_LISTEN,再次调用 get_port 判断端口是否冲突。
accept实现解析
SYSCALL_DEFINE3(accept, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen)
{
return sys_accept4(fd, upeer_sockaddr, upeer_addrlen, 0);
}
实现:
/*
* For accept, we attempt to create a new socket, set up the link
* with the client, wake up the client, then return the new
* connected fd. We collect the address of the connector in kernel
* space and move it to user at the very end. This is unclean because
* we open the socket then return an error.
*
* 1003.1g adds the ability to recvmsg() to query connection pending
* status to recvmsg. We need to add that support in a way thats
* clean when we restucture accept also.
*/
SYSCALL_DEFINE4(accept4, int, fd, struct sockaddr __user *, upeer_sockaddr,
int __user *, upeer_addrlen, int, flags)
{
struct socket *sock, *newsock;
struct file *newfile;
int err, len, newfd, fput_needed;
struct sockaddr_storage address;
...
sock = sockfd_lookup_light(fd, &err, &fput_needed);
if (!sock)
goto out;
err = -ENFILE;
newsock = sock_alloc();
if (!newsock)
goto out_put;
newsock->type = sock->type;
newsock->ops = sock->ops;
...
newfd = get_unused_fd_flags(flags);
if (unlikely(newfd < 0)) {
err = newfd;
sock_release(newsock);
goto out_put;
}
newfile = sock_alloc_file(newsock, flags, sock->sk->sk_prot_creator->name);
if (unlikely(IS_ERR(newfile))) {
err = PTR_ERR(newfile);
put_unused_fd(newfd);
sock_release(newsock);
goto out_put;
}
...
err = sock->ops->accept(sock, newsock, sock->file->f_flags);
if (err < 0)
goto out_fd;
...
/* File flags are not inherited via accept() unlike another OSes. */
fd_install(newfd, newfile);
err = newfd;
out_put:
fput_light(sock->file, fput_needed);
out:
return err;
out_fd:
fput(newfile);
put_unused_fd(newfd);
goto out_put;
}
accept 函数的实现,印证了 socket 的原理中说的那样,原来的 socket 是监听 socket,这里我们会找到原来的 struct socket,并基于它去创建一个新的 newsock。这才是连接 socket。除此之外,我们还会创建一个新的 struct file 和 fd,并关联到 socket。
这里面还会调用 struct socket 的 sock->ops->accept,也即会调用 inet_stream_ops 的 accept 函数,也即 inet_accept。
/*
* Accept a pending connection. The TCP layer now gives BSD semantics.
*/
int inet_accept(struct socket *sock, struct socket *newsock, int flags)
{
struct sock *sk1 = sock->sk;
int err = -EINVAL;
struct sock *sk2 = sk1->sk_prot->accept(sk1, flags, &err);
if (!sk2)
goto do_err;
...
sock_graft(sk2, newsock);//将新的sk和新的sock关联
newsock->state = SS_CONNECTED;//如果上面accept返回,则变为已连接
...
}
static inline void sock_graft(struct sock *sk, struct socket *parent)
{
...
parent->sk = sk;
sk_set_socket(sk, parent);
sk->sk_uid = SOCK_INODE(parent)->i_uid;
...
}
inet_accept 会调用 struct sock 的 sk1->sk_prot->accept,也即 tcp_prot 的 accept 函数,inet_csk_accept 函数。
/*
* This will accept the next outstanding connection.
*/
struct sock *inet_csk_accept(struct sock *sk, int flags, int *err)
{
struct inet_connection_sock *icsk = inet_csk(sk);
struct request_sock_queue *queue = &icsk->icsk_accept_queue;//这里的队列就是listen中初始化的全连接队列
struct sock *newsk;
struct request_sock *req;
int error;
...
/* Find already established connection */
if (reqsk_queue_empty(queue)) {
long timeo = sock_rcvtimeo(sk, flags & O_NONBLOCK);
/* If this is a non blocking socket don't sleep */
error = -EAGAIN;
if (!timeo)
goto out_err;
error = inet_csk_wait_for_connect(sk, timeo);
if (error)
goto out_err;
}
req = reqsk_queue_remove(queue);
newsk = req->sk;
...
out:
release_sock(sk);
if (req)
__reqsk_free(req);
return newsk;
...
}
这里用到了前面listen初始化的队列icsk_accept_queue,如果 icsk_accept_queue 为空,则调用 inet_csk_wait_for_connect 进行等待;等待的时候,调用 schedule_timeout,让出 CPU,并且将进程状态设置为 TASK_INTERRUPTIBLE。
/*
* Wait for an incoming connection, avoid race conditions. This must be called
* with the socket locked.
*/
static int inet_csk_wait_for_connect(struct sock *sk, long timeo)
{
struct inet_connection_sock *icsk = inet_csk(sk);
DEFINE_WAIT(wait);
int err;
for (;;) {
prepare_to_wait_exclusive(sk_sleep(sk), &wait,
TASK_INTERRUPTIBLE);
release_sock(sk);
if (reqsk_queue_empty(&icsk->icsk_accept_queue))
timeo = schedule_timeout(timeo);
sched_annotate_sleep();
lock_sock(sk);
err = 0;
if (!reqsk_queue_empty(&icsk->icsk_accept_queue))
break;
err = -EINVAL;
if (sk->sk_state != TCP_LISTEN)
break;
err = sock_intr_errno(timeo);
if (signal_pending(current))
break;
err = -EAGAIN;
if (!timeo)
break;
}
finish_wait(sk_sleep(sk), &wait);
return err;
}
如果再次 CPU 醒来,我们会接着判断 icsk_accept_queue 是否为空,同时也会调用 signal_pending 看有没有信号可以处理。一旦 icsk_accept_queue 不为空,就从 inet_csk_wait_for_connect 中返回,在队列中取出一个 struct sock 对象赋值给 newsk。
因此accept就是检查是否有人连接,如果有就返回一个新的socket。当执行accept后,sk->sk_state仍为TCP_LISTEN
那这个队列什么时候不为空呢?当三次握手结束就可以,因此下面解析的是connect函数的实现。
connect实现解析
connect入口
SYSCALL_DEFINE3(connect, int, fd, struct sockaddr __user *, uservaddr,
int, addrlen)
{
struct socket *sock;
struct sockaddr_storage address;
int err, fput_needed;
sock = sockfd_lookup_light(fd, &err, &fput_needed);
err = move_addr_to_kernel(uservaddr, addrlen, &address);
err = sock->ops->connect(sock, (struct sockaddr *)&address, addrlen, sock->file->f_flags);
}
差不多的流程,实际调用 inet_stream_ops 的 connect 函数,也即调用 inet_stream_connect。
/*
* Connect to a remote host. There is regrettably still a little
* TCP 'magic' in here.
*/
int __inet_stream_connect(struct socket *sock, struct sockaddr *uaddr,
int addr_len, int flags, int is_sendmsg)
{
struct sock *sk = sock->sk;
int err;
long timeo;
switch (sock->state) {
......
case SS_UNCONNECTED:
err = -EISCONN;
if (sk->sk_state != TCP_CLOSE)//socket刚创建后sk->sk_state被初始化为TCP_CLOSE
goto out;
err = sk->sk_prot->connect(sk, uaddr, addr_len);
sock->state = SS_CONNECTING;//设置socket状态为SS_CONNECTING
break;
}
timeo = sock_sndtimeo(sk, flags & O_NONBLOCK);
if ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
......
if (!timeo || !inet_wait_for_connect(sk, timeo, writebias))//非SYC_SEND和SYC_RECV状态后退出
goto out;
err = sock_intr_errno(timeo);
if (signal_pending(current))
goto out;
}
sock->state = SS_CONNECTED;//三次握手完毕,设置socket状态为SS_CONNECTED
}
在inet_create中,state已被初始化为SS_UNCONNECTED,调用 struct sock 的 sk->sk_prot->connect,也即 tcp_prot 的 connect 函数——tcp_v4_connect 函数,用来发送SYC报文并把sk->sk_state设为TCPF_SYN_SENT。这里先把inet_wait_for_connect看完,马上再看tcp_v4_connect :
static long inet_wait_for_connect(struct sock *sk, long timeo, int writebias)
{
...
/* Basic assumption: if someone sets sk->sk_err, he _must_
* change state of the socket from TCP_SYN_*.
* Connect() does not allow to get error notifications
* without closing the socket.
*/
while ((1 << sk->sk_state) & (TCPF_SYN_SENT | TCPF_SYN_RECV)) {
release_sock(sk);
timeo = wait_woken(&wait, TASK_INTERRUPTIBLE, timeo);
lock_sock(sk);
if (signal_pending(current) || !timeo)
break;
}
remove_wait_queue(sk_sleep(sk), &wait);
sk->sk_write_pending -= writebias;
return timeo;
}
这里是在等待不是TCPF_SYN_SENT | TCPF_SYN_RECV就会退出。
接下来看下SYC报文的发送,也即tcp_v4_connect。
TCP连接建立处理过程分析
三次握手-客户端发送SYC报文
int tcp_v4_connect(struct sock *sk, struct sockaddr *uaddr, int addr_len)
{
struct sockaddr_in *usin = (struct sockaddr_in *)uaddr;
struct inet_sock *inet = inet_sk(sk);
struct tcp_sock *tp = tcp_sk(sk);
__be16 orig_sport, orig_dport;
__be32 daddr, nexthop;
struct flowi4 *fl4;
struct rtable *rt;
......
nexthop = daddr = usin->sin_addr.s_addr;
......
orig_sport = inet->inet_sport;
orig_dport = usin->sin_port;
rt = ip_route_connect(fl4, nexthop, inet->inet_saddr,
RT_CONN_FLAGS(sk), sk->sk_bound_dev_if,
IPPROTO_TCP,
orig_sport, orig_dport, sk);//路由查找
......
tcp_set_state(sk, TCP_SYN_SENT);//在此处改变状态,即sk->sk_state
err = inet_hash_connect(tcp_death_row, sk);
sk_set_txhash(sk);
rt = ip_route_newports(fl4, rt, orig_sport, orig_dport,
inet->inet_sport, inet->inet_dport, sk);
/* OK, now commit destination to socket. */
sk->sk_gso_type = SKB_GSO_TCPV4;
sk_setup_caps(sk, &rt->dst);
if (likely(!tp->repair)) {
if (!tp->write_seq)
tp->write_seq = secure_tcp_seq(inet->inet_saddr,//序列号处理
inet->inet_daddr,
inet->inet_sport,
usin->sin_port);
tp->tsoffset = secure_tcp_ts_off(sock_net(sk),
inet->inet_saddr,
inet->inet_daddr);
}
rt = NULL;
......
err = tcp_connect(sk);//发送SYC报文处理
......
}
在 tcp_v4_connect 函数中,ip_route_connect 其实是做一个路由的选择。为什么呢?因为三次握手马上就要发送一个 SYN 包了,这就要凑齐源地址、源端口、目标地址、目标端口。目标地址和目标端口是服务端的,已经知道源端口是客户端随机分配的,源地址应该用哪一个呢?这时候要选择一条路由,看从哪个网卡出去,就应该填写哪个网卡的 IP 地址。接下来,在调用tcp_connect发送 SYN 之前,我们先将客户端 socket 的状态设置为 TCP_SYN_SENT。然后初始化 TCP 的 seq num,也即 write_seq,然后调用 tcp_connect 进行发送。
继续看tcp_connect:
/* Build a SYN and send it off. */
int tcp_connect(struct sock *sk)
{
struct tcp_sock *tp = tcp_sk(sk);
struct sk_buff *buff;
int err;
......
tcp_connect_init(sk);
......
buff = sk_stream_alloc_skb(sk, 0, sk->sk_allocation, true);
......
tcp_init_nondata_skb(buff, tp->write_seq++, TCPHDR_SYN);//初始化SYC报文
tcp_mstamp_refresh(tp);
tp->retrans_stamp = tcp_time_stamp(tp);
tcp_connect_queue_skb(sk, buff);
tcp_ecn_send_syn(sk, buff);
/* Send off SYN; include data in Fast Open. */
err = tp->fastopen_req ? tcp_send_syn_data(sk, buff) :
tcp_transmit_skb(sk, buff, 1, sk->sk_allocation);//发送SYC报文
......
tp->snd_nxt = tp->write_seq;
tp->pushed_seq = tp->write_seq;
buff = tcp_send_head(sk);
if (unlikely(buff)) {
tp->snd_nxt = TCP_SKB_CB(buff)->seq;
tp->pushed_seq = TCP_SKB_CB(buff)->seq;
}
......
/* Timer for repeating the SYN until an answer. */
inet_csk_reset_xmit_timer(sk, ICSK_TIME_RETRANS,
inet_csk(sk)->icsk_rto, TCP_RTO_MAX);//重复发送SYC直到接收到回复
return 0;
}
接着回到sock->ops->connect那里,后面调用inet_wait_for_connect 等待服务端的ACK。此时客户端的sk_state为TCP_SYN_SENT。
三次握手-服务端接收SYC,回复SYC-ACK
接下来看服务端的处理,服务端此时处于调用完accept之后的TCP_LISTEN状态。在服务端要接收这个SYC报文,在经过ip_local_deliver_finish后,会调用ip_protocol_deliver_rcu来进行下一步处理,也就是ip层及之上协议的处理,这个函数中通过inet_protos找到对应的handler,具体怎么注册的这里略过,大概调用顺序如下:

对应变量如下:
static const struct net_protocol tcp_protocol = {
.handler = tcp_v4_rcv,
.err_handler = tcp_v4_err,
.no_policy = 1,
.icmp_strict_tag_validation = 1,
};
对于tcp的协议,调用handler,即tcp_v4_rcv进行处理,当还没收到SYC报文时,此时sock->sk_state还处于TCP_LISTEN状态,所以进入如下处理:
int tcp_v4_rcv(struct sk_buff *skb)
{
...
if (sk->sk_state == TCP_LISTEN) {
ret = tcp_v4_do_rcv(sk, skb);
goto put_and_return;
}
...
}
tcp_v4_do_rcv继续调用tcp_rcv_state_process,
/* The socket must have it's spinlock held when we get
* here, unless it is a TCP_LISTEN socket.
*
* We have a potential double-lock case here, so even when
* doing backlog processing we use the BH locking scheme.
* This is because we cannot sleep with the original spinlock
* held.
*/
int tcp_v4_do_rcv(struct sock *sk, struct sk_buff *skb)
{
struct sock *rsk;
if (sk->sk_state == TCP_ESTABLISHED) { /* Fast path */
...
}
if (tcp_checksum_complete(skb))
goto csum_err;
if (sk->sk_state == TCP_LISTEN) {
struct sock *nsk = tcp_v4_cookie_check(sk, skb);
if (!nsk)
goto discard;
if (nsk != sk) {
if (tcp_child_process(sk, nsk, skb)) {
rsk = nsk;
goto reset;
}
return 0;
}
} else
sock_rps_save_rxhash(sk, skb);
if (tcp_rcv_state_process(sk, skb)) {
rsk = sk;
goto reset;
}
return 0;
...
}
因为CONFIG_SYN_COOKIES未开启,tcp_child_process未走到(通过gdb断点确认),直接执行tcp_rcv_state_process。
顾名思义,tcp_rcv_state_process是用来处理接收一个网络包后引起状态变化的。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
......
case TCP_LISTEN:
......
if (th->syn) {//接收到SYC报文
acceptable = icsk->icsk_af_ops->conn_request(sk, skb) >= 0;
if (!acceptable)
return 1;
consume_skb(skb);
return 0;
}
......
}
目前服务端是处于 TCP_LISTEN 状态的,而且发过来的包是 SYN,因而就有了上面的代码,调用 icsk->icsk_af_ops->conn_request 函数。这个函数是在tcp对应的proto的init函数中赋值的。
icsk->icsk_af_ops = &ipv4_specific;
...
const struct inet_connection_sock_af_ops ipv4_specific = {
.queue_xmit = ip_queue_xmit,
.send_check = tcp_v4_send_check,
.rebuild_header = inet_sk_rebuild_header,
.sk_rx_dst_set = inet_sk_rx_dst_set,
.conn_request = tcp_v4_conn_request,//这个函数
.syn_recv_sock = tcp_v4_syn_recv_sock,
.net_header_len = sizeof(struct iphdr),
.setsockopt = ip_setsockopt,
.getsockopt = ip_getsockopt,
.addr2sockaddr = inet_csk_addr2sockaddr,
.sockaddr_len = sizeof(struct sockaddr_in),
.mtu_reduced = tcp_v4_mtu_reduced,
};
因此实际调用的是调用的是 tcp_v4_conn_request。tcp_v4_conn_request 会调用 tcp_conn_request,这个函数也比较长,里面调用了 send_synack,但实际调用的是 tcp_v4_send_synack。
int tcp_conn_request(struct request_sock_ops *rsk_ops,
const struct tcp_request_sock_ops *af_ops,
struct sock *sk, struct sk_buff *skb)
{
...
req = inet_reqsk_alloc(rsk_ops, sk, !want_cookie);//状态在此改变
if (!req)
goto drop;
......
if (fastopen_sk) {
...
} else {//通过gdb确认走此分支
tcp_rsk(req)->tfo_listener = false;
if (!want_cookie) {
req->timeout = tcp_timeout_init((struct sock *)req);
inet_csk_reqsk_queue_hash_add(sk, req, req->timeout);
}
af_ops->send_synack(sk, dst, &fl, req, &foc,
!want_cookie ? TCP_SYNACK_NORMAL :
TCP_SYNACK_COOKIE,
skb);
if (want_cookie) {
reqsk_free(req);
return 0;
}
}
......
}
struct request_sock *inet_reqsk_alloc(const struct request_sock_ops *ops,
struct sock *sk_listener,
bool attach_listener)
{
struct request_sock *req = reqsk_alloc(ops, sk_listener,
attach_listener);
if (req) {
struct inet_request_sock *ireq = inet_rsk(req);
ireq->ireq_opt = NULL;
#if IS_ENABLED(CONFIG_IPV6)
ireq->pktopts = NULL;
#endif
atomic64_set(&ireq->ir_cookie, 0);
ireq->ireq_state = TCP_NEW_SYN_RECV;//ireq状态改变
write_pnet(&ireq->ireq_net, sock_net(sk_listener));
ireq->ireq_family = sk_listener->sk_family;
}
return req;
}
/*
* Send a SYN-ACK after having received a SYN.
* This still operates on a request_sock only, not on a big
* socket.
*/
static int tcp_v4_send_synack(const struct sock *sk, struct dst_entry *dst,
struct flowi *fl,
struct request_sock *req,
struct tcp_fastopen_cookie *foc,
enum tcp_synack_type synack_type,
struct sk_buff *syn_skb)
{
const struct inet_request_sock *ireq = inet_rsk(req);
struct flowi4 fl4;
int err = -1;
struct sk_buff *skb;
u8 tos;
/* First, grab a route. */
if (!dst && (dst = inet_csk_route_req(sk, &fl4, req)) == NULL)
return -1;
//构造报文
skb = tcp_make_synack(sk, dst, req, foc, synack_type, syn_skb);
if (skb) {
...
if (!INET_ECN_is_capable(tos) &&
tcp_bpf_ca_needs_ecn((struct sock *)req))
tos |= INET_ECN_ECT_0;
rcu_read_lock();
//发送报文
err = ip_build_and_send_pkt(skb, sk, ireq->ir_loc_addr,
ireq->ir_rmt_addr,
rcu_dereference(ireq->ireq_opt),
tos);
rcu_read_unlock();
err = net_xmit_eval(err);
}
return err;
}
具体发送的过程略过,看注释我们能知道,这是收到了 SYN 后,回复一个 SYN-ACK,回复完毕后,服务端处于 TCP_SYN_RECV。
三次握手-客户端接收SYC-ACK,回复ACK
服务端的SYC-ACK发送完毕,看客户端的接收处理,还是tcp_rcv_state_process 函数,只不过由于客户端目前处于 TCP_SYN_SENT 状态,就进入了下面的代码分支。
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
const struct tcphdr *th = tcp_hdr(skb);
struct request_sock *req;
int queued = 0;
bool acceptable;
switch (sk->sk_state) {
......
case TCP_SYN_SENT:
tp->rx_opt.saw_tstamp = 0;
tcp_mstamp_refresh(tp);
queued = tcp_rcv_synsent_state_process(sk, skb, th);
if (queued >= 0)
return queued;
/* Do step6 onward by hand. */
tcp_urg(sk, skb, th);
__kfree_skb(skb);
tcp_data_snd_check(sk);
return 0;
}
......
}
static int tcp_rcv_synsent_state_process(struct sock *sk, struct sk_buff *skb,
const struct tcphdr *th)
{
...
if (th->ack) {
...
tcp_finish_connect(sk, skb);//设置状态为TCP_ESTABLISHED
...
tcp_send_ack(sk);//回复ack报文
}
...
}
...
}
void tcp_finish_connect(struct sock *sk, struct sk_buff *skb)
{
struct tcp_sock *tp = tcp_sk(sk);
struct inet_connection_sock *icsk = inet_csk(sk);
tcp_set_state(sk, TCP_ESTABLISHED);
...
}
tcp_rcv_synsent_state_process 会调用 tcp_send_ack,发送一个 ACK-ACK,发送后客户端处于 TCP_ESTABLISHED 状态。
三次握手-服务端接收ACK报文
//SYC_RECV状态的sock创建
//理解结构复用非常重要!!!!
//前面接收syn后的ireq->ireq_state = TCP_NEW_SYN_RECV;
//和此处的sk->sk_state == TCP_NEW_SYN_RECV;其实是一个结构体
/*
* From tcp_input.c
*/
int tcp_v4_rcv(struct sk_buff *skb)
{
...
if (sk->sk_state == TCP_NEW_SYN_RECV) {
struct request_sock *req = inet_reqsk(sk);
bool req_stolen = false;
struct sock *nsk;
...
{
...
if (!tcp_filter(sk, skb)) {
th = (const struct tcphdr *)skb->data;
iph = ip_hdr(skb);
tcp_v4_fill_cb(skb, iph, th);
nsk = tcp_check_req(sk, skb, req, false, &req_stolen);
}
...
if (nsk == sk) {
reqsk_put(req);
tcp_v4_restore_cb(skb);
} else if (tcp_child_process(sk, nsk, skb)) {//走此分支,nsk替代request_sock继续处理
tcp_v4_send_reset(nsk, skb);
goto discard_and_relse;
} else {
sock_put(sk);
return 0;//处理ok,返回
}
}
...
}
/*
* Process an incoming packet for SYN_RECV sockets represented as a
* request_sock. Normally sk is the listener socket but for TFO it
* points to the child socket.
*
* XXX (TFO) - The current impl contains a special check for ack
* validation and inside tcp_v4_reqsk_send_ack(). Can we do better?
*
* We don't need to initialize tmp_opt.sack_ok as we don't use the results
*/
struct sock *tcp_check_req(struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
bool fastopen, bool *req_stolen)
{
...
/* OK, ACK is valid, create big socket and
* feed this segment to it. It will repeat all
* the tests. THIS SEGMENT MUST MOVE SOCKET TO
* ESTABLISHED STATE. If it will be dropped after
* socket is created, wait for troubles.
*/
child = inet_csk(sk)->icsk_af_ops->syn_recv_sock(sk, skb, req, NULL,
req, &own_req);
if (!child)
goto listen_overflow;
if (own_req && rsk_drop_req(req)) {
reqsk_queue_removed(&inet_csk(sk)->icsk_accept_queue, req);
inet_csk_reqsk_queue_drop_and_put(sk, req);
return child;
}
sock_rps_save_rxhash(child, skb);
tcp_synack_rtt_meas(child, req);
*req_stolen = !own_req;
return inet_csk_complete_hashdance(sk, child, req, own_req);//从半连接队列删除,添加到全连接队列,下方用gdb确认
...
}
/*
* The three way handshake has completed - we got a valid synack -
* now create the new socket.
*/
struct sock *tcp_v4_syn_recv_sock(const struct sock *sk, struct sk_buff *skb,
struct request_sock *req,
struct dst_entry *dst,
struct request_sock *req_unhash,
bool *own_req)
{
...
newsk = tcp_create_openreq_child(sk, req, skb);
if (!newsk)
goto exit_nonewsk;
...
}
/* This is not only more efficient than what we used to do, it eliminates
* a lot of code duplication between IPv4/IPv6 SYN recv processing. -DaveM
*
* Actually, we could lots of memory writes here. tp of listening
* socket contains all necessary default parameters.
*/
struct sock *tcp_create_openreq_child(const struct sock *sk,
struct request_sock *req,
struct sk_buff *skb)
{
struct sock *newsk = inet_csk_clone_lock(sk, req, GFP_ATOMIC);
...
}
/**
* inet_csk_clone_lock - clone an inet socket, and lock its clone
* @sk: the socket to clone
* @req: request_sock
* @priority: for allocation (%GFP_KERNEL, %GFP_ATOMIC, etc)
*
* Caller must unlock socket even in error path (bh_unlock_sock(newsk))
*/
struct sock *inet_csk_clone_lock(const struct sock *sk,
const struct request_sock *req,
const gfp_t priority)
{
struct sock *newsk = sk_clone_lock(sk, priority);
if (newsk) {
struct inet_connection_sock *newicsk = inet_csk(newsk);
inet_sk_set_state(newsk, TCP_SYN_RECV);
...
}
调用流程为:tcp_v4_rcv->tcp_rcv_state_process->tcp_check_req->inet_csk(sk)->icsk_af_ops->syn_recv_sock->tcp_v4_syn_recv_sock->tcp_create_openreq_child
调用栈如下:
#0 tcp_create_openreq_child (sk=sk@entry=0xffff000019188000, req=req@entry=0xffff0000192d6000, skb=skb@entry=0xffff000019185a00) at net/ipv4/tcp_minisocks.c:460
#1 0xffff8000106fc7a0 in tcp_v4_syn_recv_sock (sk=0xffff000019188000, skb=0xffff000019185a00, req=0xffff0000192d6000, dst=0x0, req_unhash=0xffff0000192d6000, own_req=0xffff80001163b66f) at net/ipv4/tcp_ipv4.c:1521
#2 0xffff8000107882bc in tcp_v6_syn_recv_sock (sk=0xffff000019188000, skb=0xffff000019185a00, req=<optimized out>, dst=<optimized out>, req_unhash=<optimized out>, own_req=0xffff80001163b66f) at net/ipv6/tcp_ipv6.c:1216
#3 0xffff8000106ff664 in tcp_check_req (sk=sk@entry=0xffff000019188000, skb=skb@entry=0xffff000019185a00, req=req@entry=0xffff0000192d6000, fastopen=fastopen@entry=false, req_stolen=req_stolen@entry=0xffff80001163b737) at ./include/net/inet_connection_sock.h:147
#4 0xffff8000106fe418 in tcp_v4_rcv (skb=0xffff000019185a00) at net/ipv4/tcp_ipv4.c:1992
...
其中上面还涉及从半连接队列删除添加到全连接队列的流程:
struct sock *inet_csk_complete_hashdance(struct sock *sk, struct sock *child,
struct request_sock *req, bool own_req)
{
if (own_req) {
inet_csk_reqsk_queue_drop(sk, req);//从半连接队列删除
reqsk_queue_removed(&inet_csk(sk)->icsk_accept_queue, req);//维护计数
if (inet_csk_reqsk_queue_add(sk, req, child))//添加到全连接队列
return child;
}
/* Too bad, another child took ownership of the request, undo. */
bh_unlock_sock(child);
sock_put(child);
return NULL;
}
//request_sock放置于icsk_accept_queue,实际承载了新socket的sk
struct sock *inet_csk_reqsk_queue_add(struct sock *sk,
struct request_sock *req,
struct sock *child)
{
struct request_sock_queue *queue = &inet_csk(sk)->icsk_accept_queue;
spin_lock(&queue->rskq_lock);
if (unlikely(sk->sk_state != TCP_LISTEN)) {
...
} else {
req->sk = child;
...
queue->rskq_accept_tail = req;
...
}
spin_unlock(&queue->rskq_lock);
return child;
}
调用栈如下
Thread 65 hit Breakpoint 15, inet_csk_reqsk_queue_add (sk=sk@entry=0xffff000019188000, req=req@entry=0xffff0000191cb260, child=child@entry=0xffff000014dd9bc0) at ./include/linux/spinlock.h:354
354 raw_spin_lock(&lock->rlock);
(gdb) bt
#0 inet_csk_reqsk_queue_add (sk=sk@entry=0xffff000019188000, req=req@entry=0xffff0000191cb260, child=child@entry=0xffff000014dd9bc0) at ./include/linux/spinlock.h:354
#1 0xffff8000106de0f4 in inet_csk_complete_hashdance (sk=sk@entry=0xffff000019188000, child=child@entry=0xffff000014dd9bc0, req=req@entry=0xffff0000191cb260, own_req=<optimized out>) at net/ipv4/inet_connection_sock.c:998
#2 0xffff8000106ff6a4 in tcp_check_req (sk=sk@entry=0xffff000019188000, skb=skb@entry=0xffff000014c53200, req=req@entry=0xffff0000191cb260, fastopen=fastopen@entry=false, req_stolen=req_stolen@entry=0xffff80001163b737) at net/ipv4/tcp_minisocks.c:786
#3 0xffff8000106fe418 in tcp_v4_rcv (skb=0xffff000014c53200) at net/ipv4/tcp_ipv4.c:1992
...
先看下结构的内容
/* struct request_sock - mini sock to represent a connection request
*/
struct request_sock {
struct sock_common __req_common;
#define rsk_refcnt __req_common.skc_refcnt
#define rsk_hash __req_common.skc_hash
#define rsk_listener __req_common.skc_listener
#define rsk_window_clamp __req_common.skc_window_clamp
#define rsk_rcv_wnd __req_common.skc_rcv_wnd
struct request_sock *dl_next;
u16 mss;
u8 num_retrans; /* number of retransmits */
u8 syncookie:1; /* syncookie: encode tcpopts in timestamp */
u8 num_timeout:7; /* number of timeouts */
u32 ts_recent;
struct timer_list rsk_timer;
const struct request_sock_ops *rsk_ops;
struct sock *sk;
struct saved_syn *saved_syn;
u32 secid;
u32 peer_secid;
u32 timeout;
};
struct sock {
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
...
}
再看下半连接和全连接队列的结构体和函数
//注意两个队列间转移的流程
//添加全连接inet_csk_reqsk_queue_add 添加半连接inet_csk_reqsk_queue_hash_add
/** struct request_sock_queue - queue of request_socks
*
* @rskq_accept_head - FIFO head of established children
* @rskq_accept_tail - FIFO tail of established children
* @rskq_defer_accept - User waits for some data after accept()
*
*/
struct request_sock_queue {
spinlock_t rskq_lock;
u8 rskq_defer_accept;
u32 synflood_warned;
atomic_t qlen;//半连接request_sock数量
atomic_t young;
struct request_sock *rskq_accept_head;//存储全连接request_sock
struct request_sock *rskq_accept_tail;//存储全连接request_sock
struct fastopen_queue fastopenq; /* Check max_qlen != 0 to determine
* if TFO is enabled.
*/
};
回到最开始的tcp_v4_rcv,当nsk!=sk,会调用tcp_child_process
int tcp_child_process(struct sock *parent, struct sock *child,
struct sk_buff *skb)
__releases(&((child)->sk_lock.slock))
{
int ret = 0;
int state = child->sk_state;
...
//没有用户进程读取套接字
if (!sock_owned_by_user(child)) {
//使用newsk继续处理
ret = tcp_rcv_state_process(child, skb);
/* Wakeup parent, send SIGIO */
if (state == TCP_SYN_RECV && child->sk_state != state)
parent->sk_data_ready(parent);
} else {
/* Alas, it is possible again, because we do lookup
* in main socket hash table and lock on listening
* socket does not protect us more.
*/
__sk_add_backlog(child, skb);
}
bh_unlock_sock(child);
sock_put(child);
return ret;
}
继续看tcp_rcv_state_process
/*
* This function implements the receiving procedure of RFC 793 for
* all states except ESTABLISHED and TIME_WAIT.
* It's called from both tcp_v4_rcv and tcp_v6_rcv and should be
* address independent.
*/
int tcp_rcv_state_process(struct sock *sk, struct sk_buff *skb)
{
...
switch (sk->sk_state) {
case TCP_SYN_RECV:
...
tcp_set_state(sk, TCP_ESTABLISHED);
sk->sk_state_change(sk);
/* Note, that this wakeup is only for marginal crossed SYN case.
* Passively open sockets are not waked up, because
* sk->sk_sleep == NULL and sk->sk_socket == NULL.
*/
if (sk->sk_socket)
sk_wake_async(sk, SOCK_WAKE_IO, POLL_OUT);
...
}
...
}
调用栈如下:
Thread 65 hit Breakpoint 14, tcp_set_state (sk=sk@entry=0xffff00001918dc80, state=state@entry=1) at net/ipv4/tcp.c:2282
2282 int oldstate = sk->sk_state;
(gdb) bt
#0 tcp_set_state (sk=sk@entry=0xffff00001918dc80, state=state@entry=1) at net/ipv4/tcp.c:2282
#1 0xffff8000106f10f8 in tcp_rcv_state_process (sk=sk@entry=0xffff00001918dc80, skb=skb@entry=0xffff00001900f600) at net/ipv4/tcp_input.c:6403
#2 0xffff8000106feb2c in tcp_child_process (parent=parent@entry=0xffff000019188000, child=child@entry=0xffff00001918dc80, skb=skb@entry=0xffff00001900f600) at net/ipv4/tcp_minisocks.c:838
#3 0xffff8000106fe438 in tcp_v4_rcv (skb=0xffff00001900f600) at net/ipv4/tcp_ipv4.c:2011
...
此时三次握手成功,全连接队列中会放置新的sock,等待被处理。
函数调用总览图

状态变化总览图

linux内核中的面向对象
linux内核有面向对象,可以参考文章
封装
继承 比如各种sock结构体
多态 比如同一个socket创建函数中根据对象不同,调用的creat方法不同
linux内核socket实现变动
socket相关实现在新版本与旧版本有变化,特别是服务端接收ack包的流程,差异特别大
比如tcp_v4_do_rcv 变化较大,半连接队列的存放位置,检查位置均改变。通过新的状态 NEW_SYNC_RECV引入,使半连接队列检查提前。
数据包的发送与接收
数据包发送
数据包接收
报文通过虚拟网卡上送内核协议栈
一般三层交换机的虚接口是通过tun/tap接口实现的,一个vlan包含多个member port,也就是真实的二层口,而一个二层口也可以有多个allowed vlan。
真实的物理口收包后在sdk解包获得vlan id,并通过向tun/tap设备写入来达到上送协议栈的的目的。
内核态在tun_get_user从用户态的缓冲区收包。
转发流程简述
参考资料
Linux原始套接字实现分析
深入理解Linux网络——TCP连接建立过程(三次握手源码详解)
深入理解TCP协议及其源代码








![CTF-Web习题:[BJDCTF2020]ZJCTF,不过如此](https://i-blog.csdnimg.cn/direct/dd718287fecd4185881426b1ca8ddd3e.png)







