参考
- 自定义 Kubernetes 调度器 阳明
- https://github.com/cnych/sample-scheduler-extender
kube-scheduler 源码位置
kubernetes 调度器的源码位于 kubernetes/pkg/scheduler 中,大体的代码目录结构如下所示:(不同的版本目录结构可能不太一样)
kubernetes/pkg/scheduler
-- scheduler.go //调度相关的具体实现
|-- algorithm
| |-- predicates //节点筛选策略
| |-- priorities //节点打分策略
|-- algorithmprovider
| |-- defaults //定义默认的调度器
其中 Scheduler 创建和运行的核心程序,对应的代码在 pkg/scheduler/scheduler.go,如果要查看kube-scheduler 的入口程序,对应的代码在 cmd/kube-scheduler/scheduler.go。
Kubernetes 调度程序是如何工作的
- 默认调度器根据指定的参数启动(我们使用 kubeadm 搭建的集群,启动配置文件位于
/etc/kubernetes/manifests/kube-schdueler.yaml) - watch apiserver,将
spec.nodeName为空的 Pod 放入调度器内部的调度队列中 - 从调度队列中 Pop 出一个 Pod,开始一个标准的调度周期
- 从 Pod 属性中检索“硬性要求”(比如 CPU/内存请求值,nodeSelector/nodeAffinity),然后过滤阶段发生,在该阶段计算出满足要求的节点候选列表
- 从 Pod 属性中检索“软需求”,并应用一些默认的“软策略”(比如 Pod 倾向于在节点上更加聚拢或分散),最后,它为每个候选节点给出一个分数,并挑选出得分最高的最终获胜者
- 和 apiserver 通信(发送绑定调用),然后设置 Pod 的
spec.nodeName属性以表示将该 Pod 调度到的节点。
调度框架
调度框架定义了一组扩展点,用户可以实现扩展点定义的接口来定义自己的调度逻辑(我们称之为扩展),并将扩展注册到扩展点上,调度框架在执行调度工作流时,遇到对应的扩展点时,将调用用户注册的扩展。调度框架在预留扩展点时,都是有特定的目的,有些扩展点上的扩展可以改变调度程序的决策方法,有些扩展点上的扩展只是发送一个通知。
我们知道每当调度一个 Pod 时,都会按照两个过程来执行:调度过程和绑定过程。
调度过程为 Pod 选择一个合适的节点,绑定过程则将调度过程的决策应用到集群中(也就是在被选定的节点上运行 Pod),将调度过程和绑定过程合在一起,称之为调度上下文(scheduling context)。需要注意的是调度过程是同步运行的(同一时间点只为一个 Pod 进行调度),绑定过程可异步运行(同一时间点可并发为多个 Pod 执行绑定)。
调度过程和绑定过程遇到如下情况时会中途退出:
- 调度程序认为当前没有该 Pod 的可选节点
- 内部错误
这个时候,该 Pod 将被放回到 待调度队列,并等待下次重试。
扩展点(Extension Points)
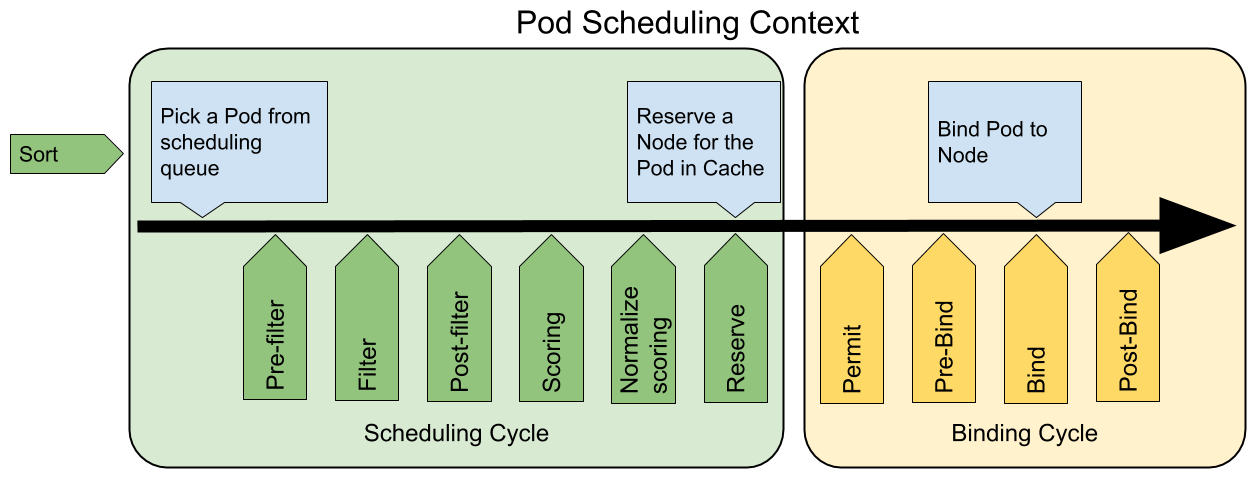
下图展示了调度框架中的调度上下文及其中的扩展点,一个扩展可以注册多个扩展点,以便可以执行更复杂的有状态的任务。
 scheduling framework extensions
scheduling framework extensions
QueueSort扩展用于对 Pod 的待调度队列进行排序,以决定先调度哪个 Pod,QueueSort扩展本质上只需要实现一个方法Less(Pod1, Pod2)用于比较两个 Pod 谁更优先获得调度即可,同一时间点只能有一个QueueSort插件生效。Pre-filter扩展用于对 Pod 的信息进行预处理,或者检查一些集群或 Pod 必须满足的前提条件,如果pre-filter返回了 error,则调度过程终止。Filter扩展用于排除那些不能运行该 Pod 的节点,对于每一个节点,调度器将按顺序执行filter扩展;如果任何一个filter将节点标记为不可选,则余下的filter扩展将不会被执行。调度器可以同时对多个节点执行filter扩展。Post-filter是一个通知类型的扩展点,调用该扩展的参数是filter阶段结束后被筛选为可选节点的节点列表,可以在扩展中使用这些信息更新内部状态,或者产生日志或 metrics 信息。Scoring扩展用于为所有可选节点进行打分,调度器将针对每一个节点调用Soring扩展,评分结果是一个范围内的整数。在normalize scoring阶段,调度器将会把每个scoring扩展对具体某个节点的评分结果和该扩展的权重合并起来,作为最终评分结果。Normalize scoring扩展在调度器对节点进行最终排序之前修改每个节点的评分结果,注册到该扩展点的扩展在被调用时,将获得同一个插件中的scoring扩展的评分结果作为参数,调度框架每执行一次调度,都将调用所有插件中的一个normalize scoring扩展一次。Reserve是一个通知性质的扩展点,有状态的插件可以使用该扩展点来获得节点上为 Pod 预留的资源,该事件发生在调度器将 Pod 绑定到节点之前,目的是避免调度器在等待 Pod 与节点绑定的过程中调度新的 Pod 到节点上时,发生实际使用资源超出可用资源的情况。(因为绑定 Pod 到节点上是异步发生的)。这是调度过程的最后一个步骤,Pod 进入 reserved 状态以后,要么在绑定失败时触发 Unreserve 扩展,要么在绑定成功时,由 Post-bind 扩展结束绑定过程。Permit扩展用于阻止或者延迟 Pod 与节点的绑定。Permit 扩展可以做下面三件事中的一项:- approve(批准):当所有的 permit 扩展都 approve 了 Pod 与节点的绑定,调度器将继续执行绑定过程
- deny(拒绝):如果任何一个 permit 扩展 deny 了 Pod 与节点的绑定,Pod 将被放回到待调度队列,此时将触发
Unreserve扩展 - wait(等待):如果一个 permit 扩展返回了 wait,则 Pod 将保持在 permit 阶段,直到被其他扩展 approve,如果超时事件发生,wait 状态变成 deny,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展
Pre-bind扩展用于在 Pod 绑定之前执行某些逻辑。例如,pre-bind 扩展可以将一个基于网络的数据卷挂载到节点上,以便 Pod 可以使用。如果任何一个pre-bind扩展返回错误,Pod 将被放回到待调度队列,此时将触发 Unreserve 扩展。Bind扩展用于将 Pod 绑定到节点上:- 只有所有的 pre-bind 扩展都成功执行了,bind 扩展才会执行
- 调度框架按照 bind 扩展注册的顺序逐个调用 bind 扩展
- 具体某个 bind 扩展可以选择处理或者不处理该 Pod
- 如果某个 bind 扩展处理了该 Pod 与节点的绑定,余下的 bind 扩展将被忽略
Post-bind是一个通知性质的扩展:- Post-bind 扩展在 Pod 成功绑定到节点上之后被动调用
- Post-bind 扩展是绑定过程的最后一个步骤,可以用来执行资源清理的动作
Unreserve是一个通知性质的扩展,如果为 Pod 预留了资源,Pod 又在被绑定过程中被拒绝绑定,则 unreserve 扩展将被调用。Unreserve 扩展应该释放已经为 Pod 预留的节点上的计算资源。在一个插件中,reserve 扩展和 unreserve 扩展应该成对出现。
扩展点接口的源码定义
如果我们要实现自己的插件,必须向调度框架注册插件并完成配置,另外还必须实现扩展点接口,对应的扩展点接口我们可以在源码 pkg/scheduler/framework/v1alpha1/interface.go 文件中找到,如下所示:
// Plugin is the parent type for all the scheduling framework plugins.
type Plugin interface {
Name() string
}
type QueueSortPlugin interface {
Plugin
Less(*PodInfo, *PodInfo) bool
}
// PreFilterPlugin is an interface that must be implemented by "prefilter" plugins.
// These plugins are called at the beginning of the scheduling cycle.
type PreFilterPlugin interface {
Plugin
PreFilter(pc *PluginContext, p *v1.Pod) *Status
}
// FilterPlugin is an interface for Filter plugins. These plugins are called at the
// filter extension point for filtering out hosts that cannot run a pod.
// This concept used to be called 'predicate' in the original scheduler.
// These plugins should return "Success", "Unschedulable" or "Error" in Status.code.
// However, the scheduler accepts other valid codes as well.
// Anything other than "Success" will lead to exclusion of the given host from
// running the pod.
type FilterPlugin interface {
Plugin
Filter(pc *PluginContext, pod *v1.Pod, nodeName string) *Status
}
// PostFilterPlugin is an interface for Post-filter plugin. Post-filter is an
// informational extension point. Plugins will be called with a list of nodes
// that passed the filtering phase. A plugin may use this data to update internal
// state or to generate logs/metrics.
type PostFilterPlugin interface {
Plugin
PostFilter(pc *PluginContext, pod *v1.Pod, nodes []*v1.Node, filteredNodesStatuses NodeToStatusMap) *Status
}
// ScorePlugin is an interface that must be implemented by "score" plugins to rank
// nodes that passed the filtering phase.
type ScorePlugin interface {
Plugin
Score(pc *PluginContext, p *v1.Pod, nodeName string) (int, *Status)
}
// ScoreWithNormalizePlugin is an interface that must be implemented by "score"
// plugins that also need to normalize the node scoring results produced by the same
// plugin's "Score" method.
type ScoreWithNormalizePlugin interface {
ScorePlugin
NormalizeScore(pc *PluginContext, p *v1.Pod, scores NodeScoreList) *Status
}
// ReservePlugin is an interface for Reserve plugins. These plugins are called
// at the reservation point. These are meant to update the state of the plugin.
// This concept used to be called 'assume' in the original scheduler.
// These plugins should return only Success or Error in Status.code. However,
// the scheduler accepts other valid codes as well. Anything other than Success
// will lead to rejection of the pod.
type ReservePlugin interface {
Plugin
Reserve(pc *PluginContext, p *v1.Pod, nodeName string) *Status
}
// PreBindPlugin is an interface that must be implemented by "prebind" plugins.
// These plugins are called before a pod being scheduled.
type PreBindPlugin interface {
Plugin
PreBind(pc *PluginContext, p *v1.Pod, nodeName string) *Status
}
// PostBindPlugin is an interface that must be implemented by "postbind" plugins.
// These plugins are called after a pod is successfully bound to a node.
type PostBindPlugin interface {
Plugin
PostBind(pc *PluginContext, p *v1.Pod, nodeName string)
}
// UnreservePlugin is an interface for Unreserve plugins. This is an informational
// extension point. If a pod was reserved and then rejected in a later phase, then
// un-reserve plugins will be notified. Un-reserve plugins should clean up state
// associated with the reserved Pod.
type UnreservePlugin interface {
Plugin
Unreserve(pc *PluginContext, p *v1.Pod, nodeName string)
}
// PermitPlugin is an interface that must be implemented by "permit" plugins.
// These plugins are called before a pod is bound to a node.
type PermitPlugin interface {
Plugin
Permit(pc *PluginContext, p *v1.Pod, nodeName string) (*Status, time.Duration)
}
// BindPlugin is an interface that must be implemented by "bind" plugins. Bind
// plugins are used to bind a pod to a Node.
type BindPlugin interface {
Plugin
Bind(pc *PluginContext, p *v1.Pod, nodeName string) *Status
}
调度插件的开关和顺序
- https://pkg.go.dev/k8s.io/kubernetes/pkg/scheduler/apis/config#KubeSchedulerConfiguration
- https://kubernetes.io/docs/reference/command-line-tools-reference/kube-scheduler/
对于调度框架插件的启用或者禁用,我们同样可以使用上面的 KubeSchedulerConfiguration 资源对象来进行配置。下面的例子中的配置启用了一个实现了 reserve 和 preBind 扩展点的插件,并且禁用了另外一个插件,同时为插件 foo 提供了一些配置信息:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
...
plugins:
reserve:
enabled:
- name: foo
- name: bar
disabled:
- name: baz
preBind:
enabled:
- name: foo
disabled:
- name: baz
pluginConfig:
- name: foo
args: >
foo插件可以解析的任意内容
扩展的调用顺序如下:
- 如果某个扩展点没有配置对应的扩展,调度框架将使用默认插件中的扩展
- 如果为某个扩展点配置且激活了扩展,则调度框架将先调用默认插件的扩展,再调用配置中的扩展
- 默认插件的扩展始终被最先调用,然后按照
KubeSchedulerConfiguration中扩展的激活enabled顺序逐个调用扩展点的扩展 - 可以先禁用默认插件的扩展,然后在
enabled列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
假设默认插件 foo 实现了 reserve 扩展点,此时我们要添加一个插件 bar,想要在 foo 之前被调用,则应该先禁用 foo 再按照 bar foo 的顺序激活。示例配置如下所示:
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
...
plugins:
reserve:
enabled:
- name: bar
- name: foo
disabled:
- name: foo
在源码目录 pkg/scheduler/framework/plugins/examples 中有几个示范插件,我们可以参照其实现方式。
示例
其实要实现一个调度框架的插件,并不难,我们只要实现对应的扩展点,然后将插件注册到调度器中即可,下面是默认调度器在初始化的时候注册的插件:
func NewRegistry() Registry {
return Registry{
// FactoryMap:
// New plugins are registered here.
// example:
// {
// stateful_plugin.Name: stateful.NewStatefulMultipointExample,
// fooplugin.Name: fooplugin.New,
// }
}
}
但是可以看到默认并没有注册一些插件,所以要想让调度器能够识别我们的插件代码,就需要自己来实现一个调度器了,当然这个调度器我们完全没必要完全自己实现,直接调用默认的调度器,然后在上面的 NewRegistry() 函数中将我们的插件注册进去即可。在 kube-scheduler 的源码文件 kubernetes/cmd/kube-scheduler/app/server.go 中有一个 NewSchedulerCommand 入口函数,其中的参数是一个类型为 Option 的列表,而这个 Option 恰好就是一个插件配置的定义:
// Option configures a framework.Registry.
type Option func(framework.Registry) error
// NewSchedulerCommand creates a *cobra.Command object with default parameters and registryOptions
func NewSchedulerCommand(registryOptions ...Option) *cobra.Command {
......
}
所以我们完全就可以直接调用这个函数来作为我们的函数入口,并且传入我们自己实现的插件作为参数即可,而且该文件下面还有一个名为 WithPlugin 的函数可以来创建一个 Option 实例:
// WithPlugin creates an Option based on plugin name and factory.
func WithPlugin(name string, factory framework.PluginFactory) Option {
return func(registry framework.Registry) error {
return registry.Register(name, factory)
}
}
所以最终我们的入口函数如下所示:
func main() {
rand.Seed(time.Now().UTC().UnixNano())
command := app.NewSchedulerCommand(
app.WithPlugin(sample.Name, sample.New),
)
logs.InitLogs()
defer logs.FlushLogs()
if err := command.Execute(); err != nil {
_, _ = fmt.Fprintf(os.Stderr, "%v\n", err)
os.Exit(1)
}
}
其中 app.WithPlugin(sample.Name, sample.New) 就是我们接下来要实现的插件,从 WithPlugin 函数的参数也可以看出我们这里的 sample.New 必须是一个 framework.PluginFactory 类型的值,而 PluginFactory 的定义就是一个函数:
type PluginFactory = func(configuration *runtime.Unknown, f FrameworkHandle) (Plugin, error)
所以 sample.New 实际上就是上面的这个函数,在这个函数中我们可以获取到插件中的一些数据然后进行逻辑处理即可,插件实现如下所示,我们这里只是简单获取下数据打印日志,如果你有实际需求的可以根据获取的数据就行处理即可,我们这里只是实现了 PreFilter、Filter、PreBind 三个扩展点,其他的可以用同样的方式来扩展即可:
// 插件名称
const Name = "sample-plugin"
type Args struct {
FavoriteColor string `json:"favorite_color,omitempty"`
FavoriteNumber int `json:"favorite_number,omitempty"`
ThanksTo string `json:"thanks_to,omitempty"`
}
type Sample struct {
args *Args
handle framework.FrameworkHandle
}
func (s *Sample) Name() string {
return Name
}
func (s *Sample) PreFilter(pc *framework.PluginContext, pod *v1.Pod) *framework.Status {
klog.V(3).Infof("prefilter pod: %v", pod.Name)
return framework.NewStatus(framework.Success, "")
}
func (s *Sample) Filter(pc *framework.PluginContext, pod *v1.Pod, nodeName string) *framework.Status {
klog.V(3).Infof("filter pod: %v, node: %v", pod.Name, nodeName)
return framework.NewStatus(framework.Success, "")
}
func (s *Sample) PreBind(pc *framework.PluginContext, pod *v1.Pod, nodeName string) *framework.Status {
if nodeInfo, ok := s.handle.NodeInfoSnapshot().NodeInfoMap[nodeName]; !ok {
return framework.NewStatus(framework.Error, fmt.Sprintf("prebind get node info error: %+v", nodeName))
} else {
klog.V(3).Infof("prebind node info: %+v", nodeInfo.Node())
return framework.NewStatus(framework.Success, "")
}
}
//type PluginFactory = func(configuration *runtime.Unknown, f FrameworkHandle) (Plugin, error)
func New(configuration *runtime.Unknown, f framework.FrameworkHandle) (framework.Plugin, error) {
args := &Args{}
if err := framework.DecodeInto(configuration, args); err != nil {
return nil, err
}
klog.V(3).Infof("get plugin config args: %+v", args)
return &Sample{
args: args,
handle: f,
}, nil
}
完整代码可以前往仓库 https://github.com/cnych/sample-scheduler-framework 获取。
实现完成后,编译打包成镜像即可,然后我们就可以当成普通的应用用一个 Deployment 控制器来部署即可,由于我们需要去获取集群中的一些资源对象,所以当然需要申请 RBAC 权限,然后同样通过 --config 参数来配置我们的调度器,同样还是使用一个 KubeSchedulerConfiguration 资源对象配置,可以通过 plugins 来启用或者禁用我们实现的插件,也可以通过 pluginConfig 来传递一些参数值给插件:
用 KubeSchedulerConfiguration 来自定义调度器实现的行为。当使用 --config 选项进行初始化时,该配置被传递到 kube-scheduler。
scheduler-config ConfigMap 存储配置数据。sample-scheduler Deployment 的 Pod 将 my-scheduler-config ConfigMap 挂载为一个卷。
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: sample-scheduler-clusterrole
rules:
- apiGroups:
- ""
resources:
- endpoints
- events
verbs:
- create
- get
- update
- apiGroups:
- ""
resources:
- nodes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- pods
verbs:
- delete
- get
- list
- watch
- update
- apiGroups:
- ""
resources:
- bindings
- pods/binding
verbs:
- create
- apiGroups:
- ""
resources:
- pods/status
verbs:
- patch
- update
- apiGroups:
- ""
resources:
- replicationcontrollers
- services
verbs:
- get
- list
- watch
- apiGroups:
- apps
- extensions
resources:
- replicasets
verbs:
- get
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
verbs:
- get
- list
- watch
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- persistentvolumeclaims
- persistentvolumes
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
verbs:
- get
- list
- watch
- apiGroups:
- "storage.k8s.io"
resources:
- storageclasses
- csinodes
verbs:
- get
- list
- watch
- apiGroups:
- "coordination.k8s.io"
resources:
- leases
verbs:
- create
- get
- list
- update
- apiGroups:
- "events.k8s.io"
resources:
- events
verbs:
- create
- patch
- update
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: sample-scheduler-sa
namespace: kube-system
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: sample-scheduler-clusterrolebinding
namespace: kube-system
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: sample-scheduler-clusterrole
subjects:
- kind: ServiceAccount
name: sample-scheduler-sa
namespace: kube-system
---
# 用 KubeSchedulerConfiguration 来自定义调度器实现的行为。当使用 --config 选项进行初始化时,该配置被传递到 kube-scheduler。
# scheduler-config ConfigMap 存储配置数据。sample-scheduler Deployment 的 Pod 将 my-scheduler-config ConfigMap 挂载为一个卷。
# KubeSchedulerConfiguration 配置文件,通过 scheduler-config ConfigMap 存储
apiVersion: v1
kind: ConfigMap
metadata:
name: scheduler-config
namespace: kube-system
data:
scheduler-config.yaml: |
apiVersion: kubescheduler.config.k8s.io/v1alpha1
kind: KubeSchedulerConfiguration
schedulerName: sample-scheduler
leaderElection:
leaderElect: true
lockObjectName: sample-scheduler
lockObjectNamespace: kube-system
plugins:
preFilter:
enabled:
- name: "sample-plugin"
filter:
enabled:
- name: "sample-plugin"
preBind:
enabled:
- name: "sample-plugin"
pluginConfig:
- name: "sample-plugin"
args:
favorite_color: "#326CE5"
favorite_number: 7
thanks_to: "thockin"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-scheduler
namespace: kube-system
labels:
component: sample-scheduler
spec:
replicas: 1
selector:
matchLabels:
component: sample-scheduler
template:
metadata:
labels:
component: sample-scheduler
spec:
serviceAccount: sample-scheduler-sa
priorityClassName: system-cluster-critical
volumes:
- name: scheduler-config
configMap:
name: scheduler-config # 引入定义的 KubeSchedulerConfiguration 配置文件
containers:
- name: scheduler-ctrl
image: cnych/sample-scheduler:v0.1.6
imagePullPolicy: IfNotPresent
args:
- sample-scheduler-framework
- --config=/etc/kubernetes/scheduler-config.yaml # 该 scheduler 运行参数指定 KubeSchedulerConfiguration 配置文件
- --v=3
resources:
requests:
cpu: "50m"
volumeMounts:
- name: scheduler-config
mountPath: /etc/kubernetes
直接部署上面的资源对象即可,这样我们就部署了一个名为 sample-scheduler 的调度器了,接下来我们可以部署一个应用来使用这个调度器进行调度:
apiVersion: apps/v1
kind: Deployment
metadata:
name: test-scheduler
spec:
replicas: 1
selector:
matchLabels:
app: test-scheduler
template:
metadata:
labels:
app: test-scheduler
spec:
schedulerName: sample-scheduler
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
ports:
- containerPort: 80
这里需要注意的是我们现在手动指定了一个 schedulerName 的字段,将其设置成上面我们自定义的调度器名称 sample-scheduler。
我们直接创建这个资源对象,创建完成后查看我们自定义调度器的日志信息:
$ kubectl get pods -n kube-system -l component=sample-scheduler
NAME READY STATUS RESTARTS AGE
sample-scheduler-7c469787f-rwhhd 1/1 Running 0 13m
$ kubectl logs -f sample-scheduler-7c469787f-rwhhd -n kube-system
I0104 08:24:22.087881 1 scheduler.go:530] Attempting to schedule pod: default/test-scheduler-6d779d9465-rq2bb
I0104 08:24:22.087992 1 plugins.go:23] prefilter pod: test-scheduler-6d779d9465-rq2bb
I0104 08:24:22.088657 1 plugins.go:28] filter pod: test-scheduler-6d779d9465-rq2bb, node: ydzs-node1
I0104 08:24:22.088797 1 plugins.go:28] filter pod: test-scheduler-6d779d9465-rq2bb, node: ydzs-node2
I0104 08:24:22.088871 1 plugins.go:28] filter pod: test-scheduler-6d779d9465-rq2bb, node: ydzs-node3
I0104 08:24:22.088946 1 plugins.go:28] filter pod: test-scheduler-6d779d9465-rq2bb, node: ydzs-node4
I0104 08:24:22.088992 1 plugins.go:28] filter pod: test-scheduler-6d779d9465-rq2bb, node: ydzs-master
I0104 08:24:22.090653 1 plugins.go:36] prebind node info: &Node{ObjectMeta:{ydzs-node3 /api/v1/nodes/ydzs-node3 1ff6e228-4d98-4737-b6d3-30a5d55ccdc2 15466372 0 2019-11-10 09:05:09 +0000 UTC <nil> <nil> ......}
I0104 08:24:22.091761 1 factory.go:610] Attempting to bind test-scheduler-6d779d9465-rq2bb to ydzs-node3
I0104 08:24:22.104994 1 scheduler.go:667] pod default/test-scheduler-6d779d9465-rq2bb is bound successfully on node "ydzs-node3", 5 nodes evaluated, 4 nodes were found feasible. Bound node resource: "Capacity: CPU<4>|Memory<8008820Ki>|Pods<110>|StorageEphemeral<17921Mi>; Allocatable: CPU<4>|Memory<7906420Ki>|Pods<110>|StorageEphemeral<16912377419>.".
可以看到当我们创建完 Pod 后,在我们自定义的调度器中就出现了对应的日志,并且在我们定义的扩展点上面都出现了对应的日志,证明我们的示例成功了,也可以通过查看 Pod 的 schedulerName 来验证:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
test-scheduler-6d779d9465-rq2bb 1/1 Running 0 22m
$ kubectl get pod test-scheduler-6d779d9465-rq2bb -o yaml
......
restartPolicy: Always
schedulerName: sample-scheduler
securityContext: {}
serviceAccount: default
......
在最新的 Kubernetes v1.17 版本中,Scheduler Framework 内置的预选和优选函数已经全部插件化,所以要扩展调度器我们应该掌握并理解调度框架这种方式。
kube-scheduler 配置文件及插件 KubeSchedulerConfiguration
-
kube-scheduler 配置文件及插件
-
https://kubernetes.io/docs/reference/config-api/kube-scheduler-config.v1/
-
调度器配置 KubeSchedulerConfiguration k8s 官网
-
配置多个调度器 k8s 官网
-
k8s调度器多配置文件 k8s 官网
配置文件
配置文件通过kube-scheduler进程的选项–configfile指定,文件格式为配置API格式,此配置API不会通过RESTful对外暴露,只能通过指定文件的形式创建,配置文件每个字段的意思和插件参数可参考官网,下面看一个配置文件示例
// 注意 该文件可包含 多个调度器 scheduler 的配置文件(profiles 是个数组)
apiVersion: kubescheduler.config.k8s.io/v1beta1
kind: KubeSchedulerConfiguration
//Leader选举配置
leaderElection:
leaderElect: true
//apiserver通信配置
clientConnection:
kubeconfig: /etc/kubernetes/scheduler.conf
//通过profiles指定调度器,可以指定多个调度器
profiles:
//调度器[0]配置,名字是'default-scheduler'
- schedulerName: default-scheduler
//扩展点上的插件配置
plugins:
//queueSort扩展点禁用所有默认插件,使能Test
queueSort:
enabled:
- name: Test
disabled:
- name: "*"
//PreFilter扩展点使能Test
preFilter:
enabled:
- name: Test
//插件参数配置
pluginConfig:
- name: Test
args:
abcd: efg
//调度器[1]配置,名字是'scheduler1'
- schedulerName: scheduler1
//扩展点上的插件配置
plugins:
//queueSort扩展点禁用所有默认插件,使能Test
queueSort:
enabled:
- name: Test
- name: test2
disabled:
- name: "*"
配置API对应到代码中的结构体如下
//pkg/scheduler/apis/config/types.go
// KubeSchedulerConfiguration configures a scheduler
type KubeSchedulerConfiguration struct {
//k8s所有的api都有的元数据,用来指定APIVersion和kind
metav1.TypeMeta
//并行个数,默认值为16。后面执行调度算法时,会启动Parallelism个协程执行filter
Parallelism int32
//暂且不关心
LeaderElection componentbaseconfig.LeaderElectionConfiguration
//保存和apiserver通信的信息
ClientConnection componentbaseconfig.ClientConnectionConfiguration
//指定健康检查server监听的ip,默认为0.0.0.0:10251
HealthzBindAddress string
//指定metrics server监听的ip,默认为0.0.0.0:10251
MetricsBindAddress string
//debug相关配置,暂且忽略
componentbaseconfig.DebuggingConfiguration
//并不是每次调度都要尝试所有node,这样效率会比较低,所以可通过此参数指定参加调度的百分比
PercentageOfNodesToScore int32
//pod调度失败后,会先被放入不可调度队列,再由协程或其他事件触发将pod放入podBackoff队列,
//pod第一次调度失败后,会在podBackoff队列的时间为PodInitialBackoffSeconds*1,默认为1s,即调度失败1s后进行第二次调度
PodInitialBackoffSeconds int64
//pod第二次调度失败后,会在podBackoff队列的时间为PodInitialBackoffSeconds*2,依次类推,但是最大值为PodMaxBackoffSeconds,
//可参考函数calculateBackoffDuration,只要调度失败就会一直尝试,除非此pod被删除
PodMaxBackoffSeconds int64
//此参数用来指定调度器,为数组类型,表示可指定多个调度器。
//创建pod时可通过pod.Spec.SchedulerName指定使用哪个调度器,如果没有指定,则使用默认的调度器default-scheduler
Profiles []KubeSchedulerProfile
//暂且忽略
Extenders []Extender
}
KubeSchedulerProfile表示一个调度器
//pkg/scheduler/apis/config/types.go
// KubeSchedulerProfile is a scheduling profile.
type KubeSchedulerProfile struct {
//调度器名字,如果pod.Spec.SchedulerName指定了,则使用指定的调度器进行调度
SchedulerName string
//包括多个扩展点,每个扩展点又包含多个插件
Plugins *Plugins
//插件的参数,有些插件需要参数,可通过此配置指定
PluginConfig []PluginConfig
}
Plugins用来指定调度器的多个扩展点,调度器执行过程中按照顺序执行扩展点上的插件
type Plugins struct {
// QueueSort is a list of plugins that should be invoked when sorting pods in the scheduling queue.
QueueSort PluginSet
// PreFilter is a list of plugins that should be invoked at "PreFilter" extension point of the scheduling framework.
PreFilter PluginSet
// Filter is a list of plugins that should be invoked when filtering out nodes that cannot run the Pod.
Filter PluginSet
// PostFilter is a list of plugins that are invoked after filtering phase, no matter whether filtering succeeds or not.
PostFilter PluginSet
// PreScore is a list of plugins that are invoked before scoring.
PreScore PluginSet
// Score is a list of plugins that should be invoked when ranking nodes that have passed the filtering phase.
Score PluginSet
// Reserve is a list of plugins invoked when reserving/unreserving resources
// after a node is assigned to run the pod.
Reserve PluginSet
// Permit is a list of plugins that control binding of a Pod. These plugins can prevent or delay binding of a Pod.
Permit PluginSet
// PreBind is a list of plugins that should be invoked before a pod is bound.
PreBind PluginSet
// Bind is a list of plugins that should be invoked at "Bind" extension point of the scheduling framework.
// The scheduler call these plugins in order. Scheduler skips the rest of these plugins as soon as one returns success.
Bind PluginSet
// PostBind is a list of plugins that should be invoked after a pod is successfully bound.
PostBind PluginSet
}
上面所有扩展点的类型都是PluginSet,其用来指定每个扩展点上使能的插件和关闭的插件
type PluginSet struct {
// Enabled specifies plugins that should be enabled in addition to default plugins.
// These are called after default plugins and in the same order specified here.
Enabled []Plugin
// Disabled specifies default plugins that should be disabled.
// When all default plugins need to be disabled, an array containing only one "*" should be provided.
Disabled []Plugin
}
Plugin用来表示每个插件的信息,名字和权重,其中权重仅作用在score扩展点上
type Plugin struct {
// Name defines the name of plugin
Name string
// Weight defines the weight of plugin, only used for Score plugins.
Weight int32
}
问题1 —— scheduler 未指定 --config,是否会有默认插件运行?是什么?
问题: 如果没有指定config文件,或者config文件中没有配置插件,有没有默认的插件,如果有的话在哪设置的?
答: 有默认使能的插件的,可参考函数getDefaultPlugins,用于获取每个扩展点上默认使能的插件
//pkg/sheduler/apis/config/v1beta2/default_plugins.go
// getDefaultPlugins returns the default set of plugins.
func getDefaultPlugins() *v1beta2.Plugins {
plugins := &v1beta2.Plugins{
QueueSort: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.PrioritySort},
},
},
PreFilter: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.NodeResourcesFit},
{Name: names.NodePorts},
{Name: names.VolumeRestrictions},
{Name: names.PodTopologySpread},
{Name: names.InterPodAffinity},
{Name: names.VolumeBinding},
{Name: names.NodeAffinity},
},
},
Filter: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.NodeUnschedulable},
{Name: names.NodeName},
{Name: names.TaintToleration},
{Name: names.NodeAffinity},
{Name: names.NodePorts},
{Name: names.NodeResourcesFit},
{Name: names.VolumeRestrictions},
{Name: names.EBSLimits},
{Name: names.GCEPDLimits},
{Name: names.NodeVolumeLimits},
{Name: names.AzureDiskLimits},
{Name: names.VolumeBinding},
{Name: names.VolumeZone},
{Name: names.PodTopologySpread},
{Name: names.InterPodAffinity},
},
},
PostFilter: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.DefaultPreemption},
},
},
PreScore: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.InterPodAffinity},
{Name: names.PodTopologySpread},
{Name: names.TaintToleration},
{Name: names.NodeAffinity},
},
},
Score: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.NodeResourcesBalancedAllocation, Weight: pointer.Int32Ptr(1)},
{Name: names.ImageLocality, Weight: pointer.Int32Ptr(1)},
{Name: names.InterPodAffinity, Weight: pointer.Int32Ptr(1)},
{Name: names.NodeResourcesFit, Weight: pointer.Int32Ptr(1)},
{Name: names.NodeAffinity, Weight: pointer.Int32Ptr(1)},
// Weight is doubled because:
// - This is a score coming from user preference.
// - It makes its signal comparable to NodeResourcesFit.LeastAllocated.
{Name: names.PodTopologySpread, Weight: pointer.Int32Ptr(2)},
{Name: names.TaintToleration, Weight: pointer.Int32Ptr(1)},
},
},
Reserve: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.VolumeBinding},
},
},
PreBind: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.VolumeBinding},
},
},
Bind: v1beta2.PluginSet{
Enabled: []v1beta2.Plugin{
{Name: names.DefaultBinder},
},
},
}
applyFeatureGates(plugins)
return plugins
}
问题2 —— 若–config 指定了插件,默认插件会生效吗?同时如何使默认插件失效?
**问题 a:**如果指定了config,则只会使用配置的插件?默认的插件还生效吗
答: 默认插件还会生效,最终生效的插件为配置文件中指定的插件和默认插件的合集,可参考下面的代码mergePlugins问题b: 调度器配置的enabled/disabled指定的插件如何和默认插件组合
答: 可参考下面的代码mergePlugins,大概意思如下:如果配置文件disabled指定了【*】,则关闭所有默认插件,最终生效的【只有配置文件enabled指定的插件】。
如果配置文件disabled指定的【非*】,则最终生效的插件为【配置文件enable指定的插件和默认使能的插件的合集】。
disabled数组中使用*禁用该扩展点的所有默认插件。 如果需要,这个字段也可以用来对插件重新顺序。
可以先禁用默认插件的扩展,然后在enabled列表中的某个位置激活默认插件的扩展,这种做法可以改变默认插件的扩展被调用时的顺序
//pkg/sheduler/apis/config/v1beta2/default_plugins.go
// mergePlugins merges the custom set into the given default one, handling disabled sets.
func mergePlugins(defaultPlugins, customPlugins *v1beta2.Plugins) *v1beta2.Plugins {
if customPlugins == nil {
return defaultPlugins
}
defaultPlugins.QueueSort = mergePluginSet(defaultPlugins.QueueSort, customPlugins.QueueSort)
defaultPlugins.PreFilter = mergePluginSet(defaultPlugins.PreFilter, customPlugins.PreFilter)
defaultPlugins.Filter = mergePluginSet(defaultPlugins.Filter, customPlugins.Filter)
defaultPlugins.PostFilter = mergePluginSet(defaultPlugins.PostFilter, customPlugins.PostFilter)
defaultPlugins.PreScore = mergePluginSet(defaultPlugins.PreScore, customPlugins.PreScore)
defaultPlugins.Score = mergePluginSet(defaultPlugins.Score, customPlugins.Score)
defaultPlugins.Reserve = mergePluginSet(defaultPlugins.Reserve, customPlugins.Reserve)
defaultPlugins.Permit = mergePluginSet(defaultPlugins.Permit, customPlugins.Permit)
defaultPlugins.PreBind = mergePluginSet(defaultPlugins.PreBind, customPlugins.PreBind)
defaultPlugins.Bind = mergePluginSet(defaultPlugins.Bind, customPlugins.Bind)
defaultPlugins.PostBind = mergePluginSet(defaultPlugins.PostBind, customPlugins.PostBind)
return defaultPlugins
}
func mergePluginSet(defaultPluginSet, customPluginSet v1beta2.PluginSet) v1beta2.PluginSet {
disabledPlugins := sets.NewString()
enabledCustomPlugins := make(map[string]pluginIndex)
// replacedPluginIndex is a set of index of plugins, which have replaced the default plugins.
replacedPluginIndex := sets.NewInt()
for _, disabledPlugin := range customPluginSet.Disabled {
disabledPlugins.Insert(disabledPlugin.Name)
}
for index, enabledPlugin := range customPluginSet.Enabled {
enabledCustomPlugins[enabledPlugin.Name] = pluginIndex{index, enabledPlugin}
}
var enabledPlugins []v1beta2.Plugin
if !disabledPlugins.Has("*") {
for _, defaultEnabledPlugin := range defaultPluginSet.Enabled {
if disabledPlugins.Has(defaultEnabledPlugin.Name) {
continue
}
// The default plugin is explicitly re-configured, update the default plugin accordingly.
if customPlugin, ok := enabledCustomPlugins[defaultEnabledPlugin.Name]; ok {
klog.InfoS("Default plugin is explicitly re-configured; overriding", "plugin", defaultEnabledPlugin.Name)
// Update the default plugin in place to preserve order.
defaultEnabledPlugin = customPlugin.plugin
replacedPluginIndex.Insert(customPlugin.index)
}
enabledPlugins = append(enabledPlugins, defaultEnabledPlugin)
}
}
// Append all the custom plugins which haven't replaced any default plugins.
// Note: duplicated custom plugins will still be appended here.
// If so, the instantiation of scheduler framework will detect it and abort.
for index, plugin := range customPluginSet.Enabled {
if !replacedPluginIndex.Has(index) {
enabledPlugins = append(enabledPlugins, plugin)
}
}
return v1beta2.PluginSet{Enabled: enabledPlugins}
}
问题3 —— 若config中没有指定default-scheduler调度器配置,那创建pod时,pod.Spec.SchedulerName也没有赋值,会调度成功吗?
问题: 如果指定了config,但是config中没有指定default-scheduler调度器配置,那创建pod时,pod.Spec.SchedulerName也没有赋值,会调度成功吗? 还会有默认调度器default-scheduler吗?
答: 不会成功了,如果指定了config,则只有config中指定的调度器。
如果此时pod.Spec.SchedulerName也没有赋值,会因为找不到default-scheduler得不到调度,pod一直处于pending状态
多配置文件
你可以配置 kube-scheduler 运行多个配置文件。 每个配置文件都有一个关联的调度器名称,并且可以在其扩展点中配置一组不同的插件。
使用下面的配置样例,调度器将运行两个配置文件:一个使用默认插件,另一个禁用所有打分插件。
apiVersion: kubescheduler.config.k8s.io/v1
kind: KubeSchedulerConfiguration
profiles:
- schedulerName: default-scheduler
- schedulerName: no-scoring-scheduler
plugins:
preScore:
disabled:
- name: '*'
score:
disabled:
- name: '*'
对于那些希望根据特定配置文件来进行调度的 Pod,可以在 .spec.schedulerName 字段指定相应的调度器名称。
默认情况下,将创建一个调度器名为 default-scheduler 的配置文件。 这个配置文件包括上面描述的所有默认插件。 声明多个配置文件时,每个配置文件中调度器名称必须唯一。
如果 Pod 未指定调度器名称,kube-apiserver 将会把调度器名设置为 default-scheduler。 因此,应该存在一个调度器名为 default-scheduler 的配置文件来调度这些 Pod。

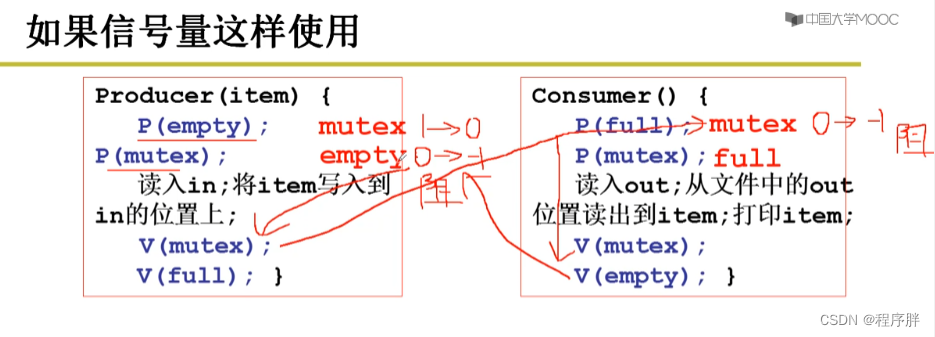
![[Linux]生产者消费者模型(基于BlockQueue的生产者消费者模型 | 基于环形队列的生产者消费者模型 | 信号量 )](https://img-blog.csdnimg.cn/c5d9adce58ec4fe89fd3578009b89f18.png)