目录
unordered系列关联式容器
unordered_mapunordered_map在线文档说明
unordered_map的接口说明
unordered系列优势
哈希
解决哈希冲突
1.闭散列——开放定址法
思考:哈希表什么情况下进行扩容?如何扩容?
插入元素代码
查找元素
删除元素
用哈希统计某元素出现次数
编辑
闭散列——线性探测完整代码
线性探测缺陷
开散列
拉链法(哈希桶)
插入
查找元素
删除
完整代码
unordered系列关联式容器
在C++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到$log_2
N$,即最差情况下需要比较红黑树的高度次,当树中的节点非常多时,查询效率也不理想。最好
的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是其底层结构不同。
unordered_map
unordered_map在线文档说明
1. unordered_map是存储<key, value>键值对的关联式容器,其允许通过keys快速的索引到与
其对应的value, unordered_map/ unordered_set都是无序的。
2. 在unordered_map中,键值通常用于惟一地标识元素,而映射值是一个对象,其内容与此
键关联。键和映射值的类型可能不同。
3. 在内部,unordered_map没有对<kye, value>按照任何特定的顺序排序, 为了能在常数范围内
找到key所对应的value,unordered_map将相同哈希值的键值对放在相同的桶中。
4. unordered_map容器通过key访问单个元素要比map快,但它通常在遍历元素子集的范围迭
代方面效率较低。
5. unordered_maps实现了直接访问操作符(operator[]),它允许使用key作为参数直接访问
value。
6. 它的迭代器至少是前向迭代器
unordered_map的接口说明
1. unordered_map的构造
| 函数声明 | 功能介绍 |
| unordered_map | 构造不同格式的unordered_map对象 |
2. unordered_map的容量
| 函数声明 | 功能介绍 |
| bool empty() const | 检测unordered_map是否为空 |
| size_t size() const | 获取unordered_map的有效元素个数 |
3. unordered_map的迭代器
| 函数声明 | 功能介绍 |
| begin | 返回unordered_map第一个元素的迭代器 |
| end | 返回unordered_map最后一个元素下一个位置的迭代器 |
| cbegin | 返回unordered_map第一个元素的const迭代器 |
| cend | 返回unordered_map最后一个元素下一个位置的const迭代器 |
力扣
class Solution {
public:
int repeatedNTimes(vector<int>& nums) {
unordered_map<int,int> countMap;
for(auto e:nums)
countMap[e]++;
for(auto& kv:countMap)
{
if(kv.second==nums.size()/2)
return kv.first;
}
return 0;
}
};最后如果不写这个return 0就会报错,这是编译错误,可能会在vs下正常跑,但是在这里会报错,所以要在最后面加return
对比map和set的区别:
1.map和set遍历是有序的,unordered系列是无序的
2.map和set是双向迭代器,unordered系列是单向的
unordered系列在面对大量数据时,增删查改的效率更优,尤其是查
力扣:找交集
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
unordered_set<int> s1;
for(auto e:nums1)
{
s1.insert(e);
}
unordered_set<int> s2;
for(auto e:nums2)
{
s2.insert(e);
}
vector<int> A;
for(auto e:s1)
{
if(s2.find(e)!=s2.end())
A.push_back(e);
}
return A;
}
};这里插入的时候就会去重
unordered系列优势

10000个数据进行插入时,set快,查找的时候unordered_set快,删除的时候set快

十万个数据时,size是插入的值,因为可能有重复的,所以不是十万。数据较大时,unordered系列的优势便显现出来了。
当六百多万数据时,unordered_set的插入就比较慢
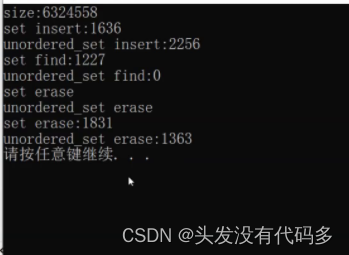
比较程序
void test_op()
{
int n = 1000000;
vector<int> v;
v.reserve(n);
srand(time(0));
for (int i = 0; i < n; ++i)
{
//v.push_back(i);
v.push_back(rand() + i); // ظ
//v.push_back(rand()); // ظ
}
size_t begin1 = clock();
set<int> s;
for (auto e : v)
{
s.insert(e);
}
size_t end1 = clock();
size_t begin2 = clock();
unordered_set<int> us;
for (auto e : v)
{
us.insert(e);
}
size_t end2 = clock();
cout << "size:" << s.size() << endl;
cout << "set insert:" << end1 - begin1 << endl;
cout << "unordered_set insert:" << end2 - begin2 << endl;
size_t begin3 = clock();
for (auto e : v)
{
s.find(e);
}
size_t end3 = clock();
size_t begin4 = clock();
for (auto e : v)
{
us.find(e);
}
size_t end4 = clock();
cout << "set find:" << end3 - begin3 << endl;
cout << "unordered_set find:" << end4 - begin4 << endl;
size_t begin5 = clock();
for (auto e : v)
{
s.erase(e);
}
size_t end5 = clock();
cout << "set erase" << endl;
size_t begin6 = clock();
for (auto e : v)
{
us.erase(e);
}
size_t end6 = clock();
cout << "unordered_set erase" << endl;
cout << "set erase:" << end5 - begin5 << endl;
cout << "unordered_set erase:" << end6 - begin6 << endl;
unordered_map<string, int> countMap;
countMap.insert(make_pair("ƻ", 1));
}
哈希
哈希也叫做散列,本质是让值跟存储位置建立映射的关联关系。
顺序结构以及平衡树中,元素关键码与其存储位置之间没有对应的关系,因此在查找一个元素
时,必须要经过关键码的多次比较。顺序查找时间复杂度为O(N),平衡树中为树的高度,即
O($log_2 N$),搜索的效率取决于搜索过程中元素的比较次数。
理想的搜索方法:可以不经过任何比较,一次直接从表中得到要搜索的元素。
如果构造一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间能够建立
一一映射的关系,那么在查找时通过该函数可以很快找到该元素
当向该结构中:
插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此位置进行存放
搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此位置
取元素比较,若关键码相等,则搜索成功
该方式即为哈希(散列)方法,哈希方法中使用的转换函数称为哈希(散列)函数,构造出来的结构称
为哈希表(Hash Table)(或者称散列表)
例如:数据集合{1,7,6,4,5,9};
哈希函数设置为:hash(key) = key % capacity; capacity为存储元素底层空间总的大小
用该方法进行搜索不必进行多次关键码的比较,因此搜索的速度比较快
但有个问题,如果有个300,400,这俩个映射道德位置都是0,就会出现不同的值映射相同的问题,这叫哈希冲突/哈希碰撞。
解决哈希冲突
1.闭散列——开放定址法
a.线性探测
线性探测:从发生冲突的位置开始,依次向后探测,直到寻找到下一个空位置为止
插入
通过哈希函数获取待插入元素在哈希表中的位置
如果该位置中没有元素则直接插入新元素,如果该位置中有元素发生哈希冲突,
使用线性探测找到下一个空位置,插入新元素
思考:哈希表什么情况下进行扩容?如何扩容?

负载因子越小:冲突的概率越小,反之,越大。负载因子到一个基准值就扩容,基准值越大,冲突越多,效率越低,空间利用率越高。
当扩容后,进行插入,插入则会变为这样
插入1 4 5 6 7 44 9,原表中是这样
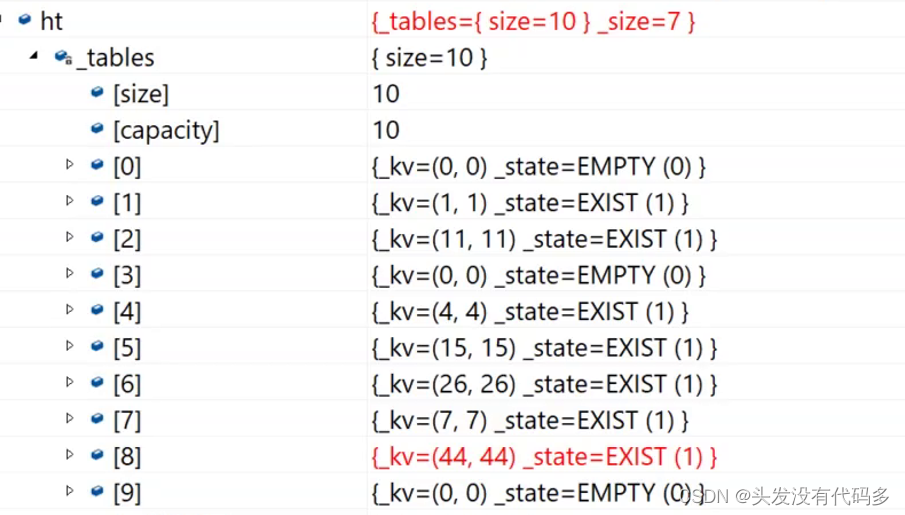
我们设置的基准值为7,>=7的时候就插入,当插入9的时候就会扩容,扩容并不是直接把旧表拷贝下来,而是要找相对应的位置再插入元素。下图为新表部分数据,通过7和11还有5就可以看出不是直接拷贝的旧表。
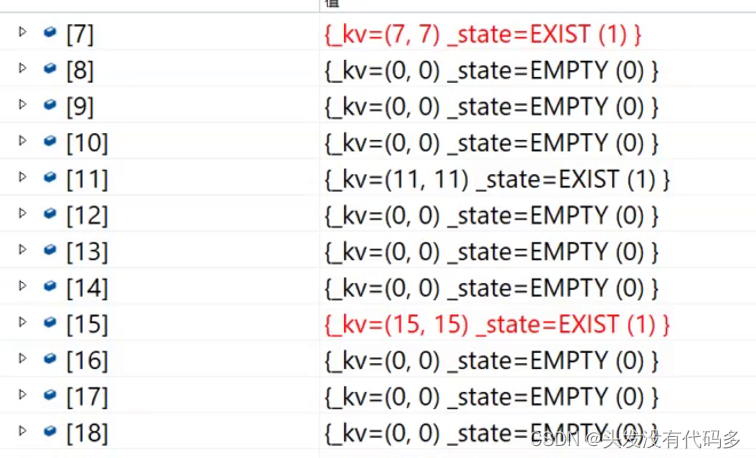
插入元素代码
enum State//标志位的三种状态,空,存在,删除
{
EMPTY,
EXIST,
DELETE
};
template<class K, class V>
struct HashData//标志位
{
pair <K, V> _kv;
State _state=EMPTY;
};
template<class K, class V>
class HashTable
{
public:
bool insert(const pair <K, V> & kv)
{
if (_table.size()==0||_size *10/ _table.size() >= 7)//负载因子大于7就扩容
{
//扩容不能直接开空间,拷贝数据,因为表大小变了,映射关系也变了,如10之前映射5,扩容后就不一定映射5
size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
//vector<HashData<K, V>> newTables;//建一张新表
//newTables.resize(newSize);//让capacity和size保持一致
旧表的数据映射到新表
//for ()
//{
//}
//_table.swap(newTables);//旧表和新表交换,这种方法有点繁琐
//我们可创建一个哈希表,对哈希表里面的table进行resize
HashTable<K, V> newHT;//创建一个跟自己类型相同的对象
newHT._table.resize(newSize);
for (auto e: _table)
{
if (e._state == EXIST)
{
newHT.insert(e._kv);//再调insert
}
_table.swap(newHT._table);
//数据交换后,不需要对新表进行释放空间,因为_table是vector,它有自己的析构函数
}
}
size_t hashi = kv.first % _table.size();//这里要对size取模,不能对容量capacity取模,访问的下标必须是在size范围以内
//线性探测
while (_table[hashi]._state==EXIST)//如果这个位置有值了
{
hashi++;//往后走找空位置
hashi %= _table.size();//走到结尾之后要回到最初位置,这里不会存在死循环,因为前面有扩容
}
_table[hashi]._kv = kv;//找到空位置了,把值放进去
_table[hashi]._state = EXIST;//修改状态;
++_size;
return true;
}
private:
vector <HashData<K, V>> _table;
size_t _size=0;//哈希表的有效数据,因为中间可能有空白间隔
};插入的时候负数也可以插入
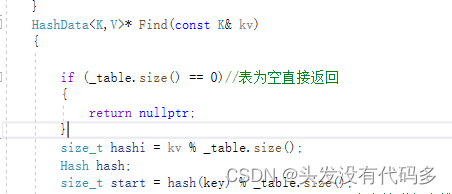
查找元素
HashData<K,V>* Find(const K& kv)
{
if (_table.size() == 0)//表为空直接返回
{
return nullptr;
}
size_t hashi = kv % _table.size();
while (_table[hashi]._state != EMPTY)//不为空就进行查找
{
size_t start = kv % _table.size();
if (_table[hashi]._state!=DELETE&&_table[hahsi] == kv)//如果该位置既不是空也不是删除,且满足查找条件则返回该位置数值
{
return _table[hashi];
}
hashi++;
hashi %= _table.size();
if (hashi == start)
{
break;//找了一圈了没找到,跳出循环
}
}
return nullptr;
}删除元素
void Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret)
{
ret->_state = DELETE;
--_size;
return true;
}
else
return false;
}用哈希统计某元素出现次数
void TestHT2()
{
string arr[] = { "苹果", "西瓜", "苹果", "西瓜", "苹果", "苹果", "西瓜", "苹果", "香蕉", "苹果", "香蕉" };
HashTable<string, int> countHT;
for (auto& str : arr)
{
auto ptr = countHT.Find(str);
if (ptr)
{
ptr->_kv.second++;
}
else
{
countHT.Insert(make_pair(str, 1));
}
}
}
此时传的是string,在取模的时候会出现问题,C++在unordered_map中对这种问题有解决方法

这里的hash<KEY>是一个仿函数,这个仿函数是处理不能取模的类型的,如string,它会把string转成一个能够取模的值。
我们增加一个哈希的仿函数

插入函数中,不要直接取模,先调用仿函数,再取模


find函数也一样
这是就是把key交给仿函数转换一下,但是string不支持转
方法一 写一个针对string的转换,把string转换为整形

这是把每个字符的ASCII码值加起来,然后返回去取模,但是在传参的时候要显示的去传

在unordered_map中用string去做Key,不需要仿函数

如果在使用哈希时,也不想每次都专门写一个仿函数,我们可以做特化
方法二 特化
如果是string, HashFunc会优先走特化版本
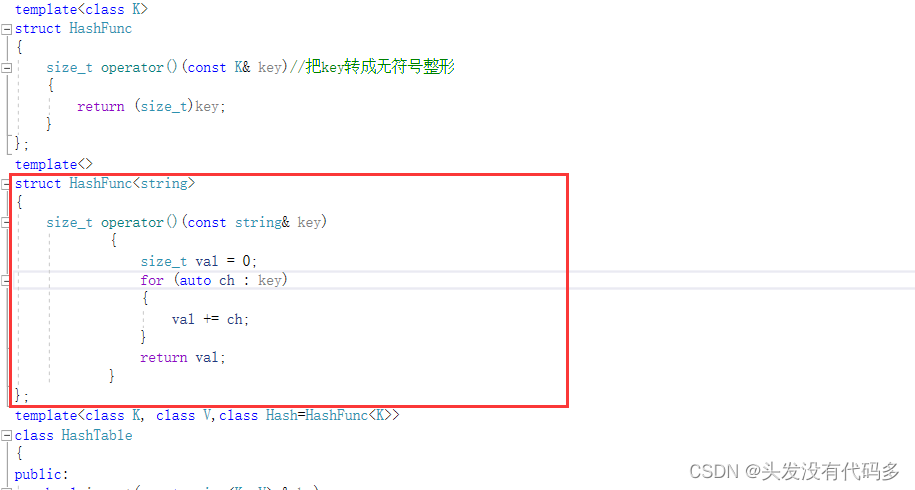

HashFunc改进
HashFunc里面的成员函数是把所有字母的ASCII码值加起来的,但是遇到下面这种
abcd,bcda,dbca情况HashFunc此时功能就不太完整。
我们采用BKDR的方式,对每次的值*131,这是大佬设计的一个算法,



这些值看起来都挺接近,但是都不一样,这样可以解决上面的问题
闭散列——线性探测完整代码
enum State//标志位的三种状态,空,存在,删除
{
EMPTY,
EXIST,
DELETE
};
template<class K, class V>
struct HashData//标志位
{
pair <K, V> _kv;
State _state=EMPTY;
};
//struct HashFuncString
//{
// size_t operator()(const string& key)
// {
// size_t val = 0;
// for (auto ch : key)
// {
// val += ch;
// }
// return val;
// }
//};
template<class K>
struct HashFunc
{
size_t operator()(const K& key)//把key转成无符号整形
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
size_t operator()(const string& key)
{
size_t val = 0;
for (auto ch : key)
{
val *= 131;
val += ch;
}
return val;
}
};
template<class K, class V,class Hash=HashFunc<K>>
class HashTable
{
public:
bool insert(const pair <K, V> & kv)
{
if (Find(kv.first))
{
return false;//该元素存在,就不插入了
}
if (_table.size()==0||_size *10/ _table.size() >= 7)//负载因子大于7就扩容
{
//扩容不能直接开空间,拷贝数据,因为表大小变了,映射关系也变了,如10之前映射5,扩容后就不一定映射5
size_t newSize = _table.size() == 0 ? 10 : _table.size() * 2;
//vector<HashData<K, V>> newTables;//建一张新表
//newTables.resize(newSize);//让capacity和size保持一致
旧表的数据映射到新表
//for ()
//{
//}
//_table.swap(newTables);//旧表和新表交换,这种方法有点繁琐
//我们可创建一个哈希表,对哈希表里面的table进行resize
HashTable<K, V,Hash> newHT;//创建一个跟自己类型相同的对象
newHT._table.resize(newSize);
for (auto e: _table)
{
if (e._state == EXIST)
{
newHT.insert(e._kv);//再调insert
}
_table.swap(newHT._table);
//数据交换后,不需要对新表进行释放空间,因为_table是vector,它有自己的析构函数
}
}
Hash hash;
size_t hashi =hash( kv.first) % _table.size();//这里要对size取模,不能对容量capacity取模,访问的下标必须是在size范围以内
//线性探测
while (_table[hashi]._state==EXIST)//如果这个位置有值了
{
hashi++;//往后走找空位置
hashi %= _table.size();//走到结尾之后要回到最初位置,这里不会存在死循环,因为前面有扩容
}
_table[hashi]._kv = kv;//找到空位置了,把值放进去
_table[hashi]._state = EXIST;//修改状态;
++_size;
return true;
}
void Erase(const K& key)
{
HashData<K, V>* ret = Find(key);
if (ret)
{
ret->_state = DELETE;
--_size;
return true;
}
else
return false;
}
HashData<K,V>* Find(const K& kv)
{
if (_table.size() == 0)//表为空直接返回
{
return nullptr;
}
size_t hashi = kv % _table.size();
Hash hash;
size_t start = hash(key) % _table.size();
while (_table[hashi]._state != EMPTY)//不为空就进行查找
{
size_t start = kv % _table.size();
if (_table[hashi]._state!=DELETE&&_table[hahsi] == kv)//如果该位置既不是空也不是删除,且满足查找条件则返回该位置数值
{
return _table[hashi];
}
hashi++;
hashi %= _table.size();
if (hashi == start)
{
break;//找了一圈了没找到,跳出循环
}
}
return nullptr;
}
private:
vector <HashData<K, V>> _table;
size_t _size=0;//哈希表的有效数据,因为中间可能有空白间隔
};
void Test1()
{
int a[] = {1,11,4,15,26,7,44,9};
HashTable<int, int> ht;
for (auto e : a)
{
ht.insert(make_pair(e, e));
}
}线性探测缺陷

若有这样一组值,线性探测在某个位置冲突很多的情况下,会互相占用,导致一大片出现冲突,如这里下标为2的位置被占用,2只能去占另外的位置,为了解决这种问题,有种解决方式叫二次探测
b.二次探测
一次探测是每次+i,二次探测是每次加i²,是相对于其实位置每次加i²,i开始是1,若每次计算完,那个地方有元素,则i变为2,
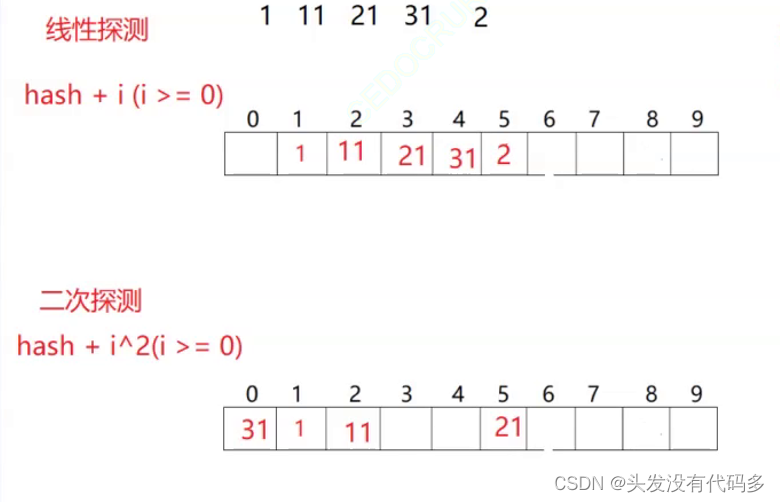
如这里插入12 12%10=2,2+2²

代码
Hash hash;
szie_t start = hash( kv.first) % _table.size();
szie_t i = 0;
size_t hashi=start+i;
while (_table[hashi]._state==EXIST)//如果这个位置有值了
{
++i
hashi=start+i*i;//往后走找空位置
hashi %= _table.size();//走到结尾之后要回到最初位置,这里不会存在死循环,因为前面有扩容
}
_table[hashi]._kv = kv;//找到空位置了,把值放进去
_table[hashi]._state = EXIST;//修改状态;
++_size;二次探测仍然是占用式:这个地方被占了,我就去占其它地方。有种更好的办法叫拉链法
开散列
拉链法(哈希桶)

这个表是指针数组
当好多元素要填入同一个位置时,这个时候会把这些数据通过单链表连接起来,注意挂起来(挂起来的这一串数据可以看作是一个桶)的数据不一定有序,这里这是巧合 。
使用单链表的时间复杂度是O(N),最极端情况要插入的数据都在同一个位置,在一个位置全部挂起来,这里由于控制了复杂因子,出现这种极坏的情况是极低的。即使出现了,也是小范围性的出现。
数据挂起来时采用头插,尾插都行,我们这里采用头插
插入
这里插入不能像前面那样复用Insert,因为会创建新节点,而且释放旧表又要写析构函数,比较麻烦,我们可以直接将旧表的桶搬下来,给新表使用,这里新表不手动释放原因,新表是一个局部变量,除了作用域后会空间会被释放


bool Insert(const pair<K, V>& kv)
{
//去重,如果有重复元素就不插入
if (Find(kv.first))
return false;
//扩容,负载因子到1就扩容
if (_size == _tables.size())
{
//这里不能复用Inert,因为会创建新节点,而且要写析构函数释放旧表
size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
vector<Node*> newTables;
newTables.resize(newSize, nullptr);
//旧表中的节点移动映射到新表
for (size_t i=0;i<_tables.size();++i)
{
Node* cur = _tables[i];
while (cur)
{
size_t hashi = cur->kv.first % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;//旧表中的桶置为空
}
_tables.swap(newTables);
}
size_t hashi = kv.first % _tables.size();//计算要插入元素的位置
//头插 新节点->next指向头,之后更新头节点为新节点
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_size;
return true;
}查找元素
Node* Find(const K& key)
{
if (_tables.size() == 0)
{
return nullptr;
}
size_t hashi = key % _table.size();//找到桶所在位置
Node* cur = _tables[hashi];
while (cur)
{
if (key.first == cur->kv.first)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}进行插入测试,插入22的时候会进行扩容


原表:1:1和11是一个桶 6:26 9:99
4:14和4 7:7
5:55,15 8:78
增容映射后新表:把11直接挂到了11这个位置,1挂到1这个位置

删除
类似于链表的删除,不能直接用Find找到就删除,因为这里是单链表删除后还要把前后连接起来。
情况1 cur是第一个节点,prev是nullptr,这种情况需单独处理
情况2 下图最左边这种情况,只需让prev的next指向cur的next
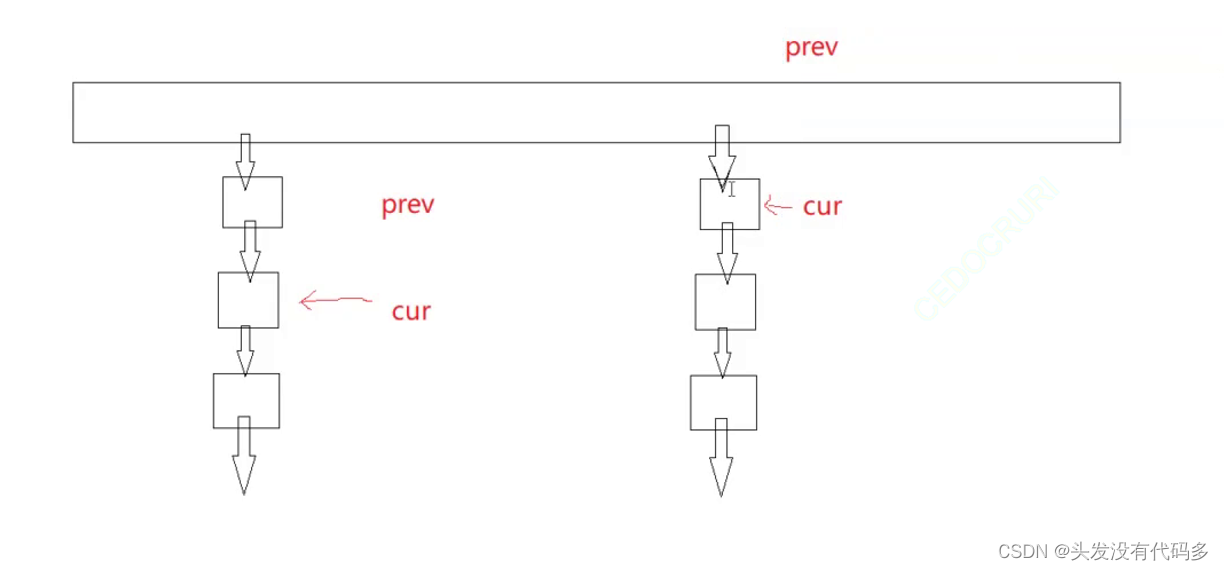
bool Erase(const K& key)
{
if (_tables.size() == 0)//如果该哈希表为空,就直接返回
{
return nullptr;
}
size_t hashi = key % _tables.size();
Node* prev = nullptr;//要找的节点的前一个节点
Node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
{
//cur符合情况1
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
//中间情况,情况2
else
{
prev->_next = cur->_next;
}
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}仿函数,跟前面一样需要增加一个仿函数,处理string类。
尽量让哈西表的大小是一个素数(这个优化不是必须的),这种情况下冲突会降低,STL源码中有素数表。

inline size_t __stl_next_prime(size_t n)//获取下一个素数
{
static const size_t __stl_num_primes = 28;
static const size_t __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (size_t i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
return __stl_prime_list[i];
}
}
return -1;
}先测试1w个数据
void TestHT3()
{
int n = 10000;
vector<int> v;
v.reserve(n);
srand(time(0));
for (int i = 0; i < n; ++i)
{
v.push_back(rand()); // 重复多
}
size_t begin1 = clock();
HashTable<int, int> ht;
for (auto e : v)
{
ht.Insert(make_pair(e, e));
}
size_t end1 = clock();
cout << "数据个数:" << ht.Size() << endl;
cout << "表的长度:" << ht.TablesSize() << endl;
cout << "桶的个数:" << ht.BucketNum() << endl;
cout << "平均每个桶的长度:" << (double)ht.Size() / (double)ht.BucketNum() << endl;
cout << "最长的桶的长度:" << ht.MaxBucketLenth() << endl;
cout << "负载因子:" << (double)ht.Size() / (double)ht.TablesSize() << endl;
}
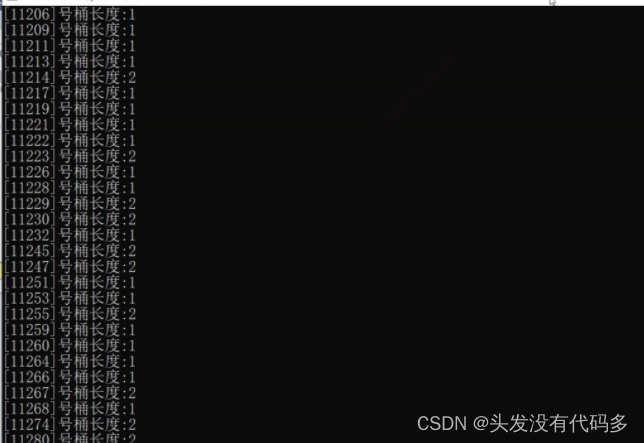
大多数桶的长度是一俩个,最长的桶长度是2个
100w个数据

1000w

1500w

1600w

完整代码
#define _CRT_SECURE_NO_WARNINGS
template<class K>
struct HashFunc
{
size_t operator()(const K& key)
{
return (size_t)key;
}
};
template<>
struct HashFunc<string>
{
// BKDR
size_t operator()(const string& key)
{
size_t val = 0;
for (auto ch : key)
{
val *= 131;
val += ch;
}
return val;
}
};
namespace HashBucket
{
template<class K,class V>
struct HashNode
{
pair<K, V> _kv;
HashNode<K, V>* _next;
HashNode(const pair<K,V>& key)
:_kv(lv),
_next(nullptr)
{}
};
template<class K,class V,class Hash=HashFunc<K>>
class HashTable
{
~HashTable()//数组会被自动释放,可桶需要手动释放
{
for (size_t i = 0; i < _table.size(); ++i)
{
Node* cur = _tables.size();
while (cur)
{
Node* next = cur->next;
free(cur);
cur = next;
}
_tables[i] = nullptr;
}
}
typedef HashNode<K, V> Node;
public:
inline size_t __stl_next_prime(size_t n)//获取下一个素数
{
static const size_t __stl_num_primes = 28;
static const size_t __stl_prime_list[__stl_num_primes] =
{
53, 97, 193, 389, 769,
1543, 3079, 6151, 12289, 24593,
49157, 98317, 196613, 393241, 786433,
1572869, 3145739, 6291469, 12582917, 25165843,
50331653, 100663319, 201326611, 402653189, 805306457,
1610612741, 3221225473, 4294967291
};
for (size_t i = 0; i < __stl_num_primes; ++i)
{
if (__stl_prime_list[i] > n)
{
return __stl_prime_list[i];
}
}
return -1;
}
bool Insert(const pair<K, V>& kv)
{
//去重,如果有重复元素就不插入
if (Find(kv.first))
return false;
Hash hash;
//扩容,负载因子到1就扩容
if (_size == _tables.size())
{
//这里不能复用Inert,因为会创建新节点,而且要写析构函数释放旧表
size_t newSize = _tables.size() == 0 ? 10 : _tables.size() * 2;
vector<Node*> newTables;
newTables.resize(newSize, nullptr);
//旧表中的节点移动映射到新表
for (size_t i=0;i<_tables.size();++i)
{
Node* cur = _tables[i];
while (cur)
{
size_t hashi = hash(cur->kv.first) % newTables.size();
cur->_next = newTables[hashi];
newTables[hashi] = cur;
cur = next;
}
_tables[i] = nullptr;//旧表中的桶置为空
}
_tables.swap(newTables);
}
Hash hash;
size_t hashi = hash(kv.first) % _tables.size();//计算要插入元素的位置
//头插 新节点->next指向头,之后更新头节点为新节点
Node* newnode = new Node(kv);
newnode->_next = _tables[hashi];
_tables[hashi] = newnode;
++_size;
return true;
}
Node* Find(const K& key)
{
if (_tables.size() == 0)
{
return nullptr;
}
Hash hash;
size_t hashi = hash(key) % _table.size();//找到桶所在位置
Node* cur = _tables[hashi];
while (cur)
{
if (key.first == cur->kv.first)
{
return cur;
}
cur = cur->_next;
}
return nullptr;
}
bool Erase(const K& key)
{
if (_tables.size() == 0)//如果该哈希表为空,就直接返回
{
return nullptr;
}
Hash hash;
size_t hashi = hash(key) % _tables.size();
Node* prev = nullptr;//要找的节点的前一个节点
Node* cur = _tables[hashi];
while (cur)
{
if (cur->_kv.first == key)
{
//cur符合情况1
if (prev == nullptr)
{
_tables[hashi] = cur->_next;
}
//中间情况,情况2
else
{
prev->_next = cur->_next;
}
delete cur;
--_size;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
//有效数据个数
size_t Size()
{
return _size;
}
size_t BucketNum()//返回桶的数量
{
size_t num = 0;
for (size_t i = 0; i < _tables.size(); ++i)
{
if (_tables[i])
{
++num;
}
}
}
//表的长度
size_t TableSize()
{
return _tables.size();
}
size_t MaxBucketLenth()
{
size_t Maxlen = 0;
for (size_t i = 0; i < _tables.size(); ++i)
{
size_t len = 0;
Node* cur = _tables[i];
while (cur)
{
++len;
cur = cur->_next;
}
if(len>0)
printf("[%d]号桶长度:%d\n", i, len);
Maxlen = len > Maxlen ? len : Maxlen;
}
}
private:
vector<Node*> _tables;
size_t _size=0;//存储有效数据个数
};
}
void TestHT3()
{
int n = 10000;
vector<int> v;
v.reserve(n);
srand(time(0));
for (int i = 0; i < n; ++i)
{
v.push_back(rand()); // 重复多
}
size_t begin1 = clock();
HashTable<int, int> ht;
for (auto e : v)
{
ht.Insert(make_pair(e, e));
}
size_t end1 = clock();
cout << "数据个数:" << ht.Size() << endl;
cout << "表的长度:" << ht.TablesSize() << endl;
cout << "桶的个数:" << ht.BucketNum() << endl;
cout << "平均每个桶的长度:" << (double)ht.Size() / (double)ht.BucketNum() << endl;
cout << "最长的桶的长度:" << ht.MaxBucketLenth() << endl;
cout << "负载因子:" << (double)ht.Size() / (double)ht.TablesSize() << endl;
}