🎯要点
🎯 数学模型邻接矩阵及其相关的转移概率 | 🎯蒙特卡罗模拟进化动力学 | 🎯细胞进化交叉图族概率 | 🎯进化图模型及其数学因子 | 🎯混合图模式对进化概率的影响 | 🎯造血干细胞群体的空间图结构
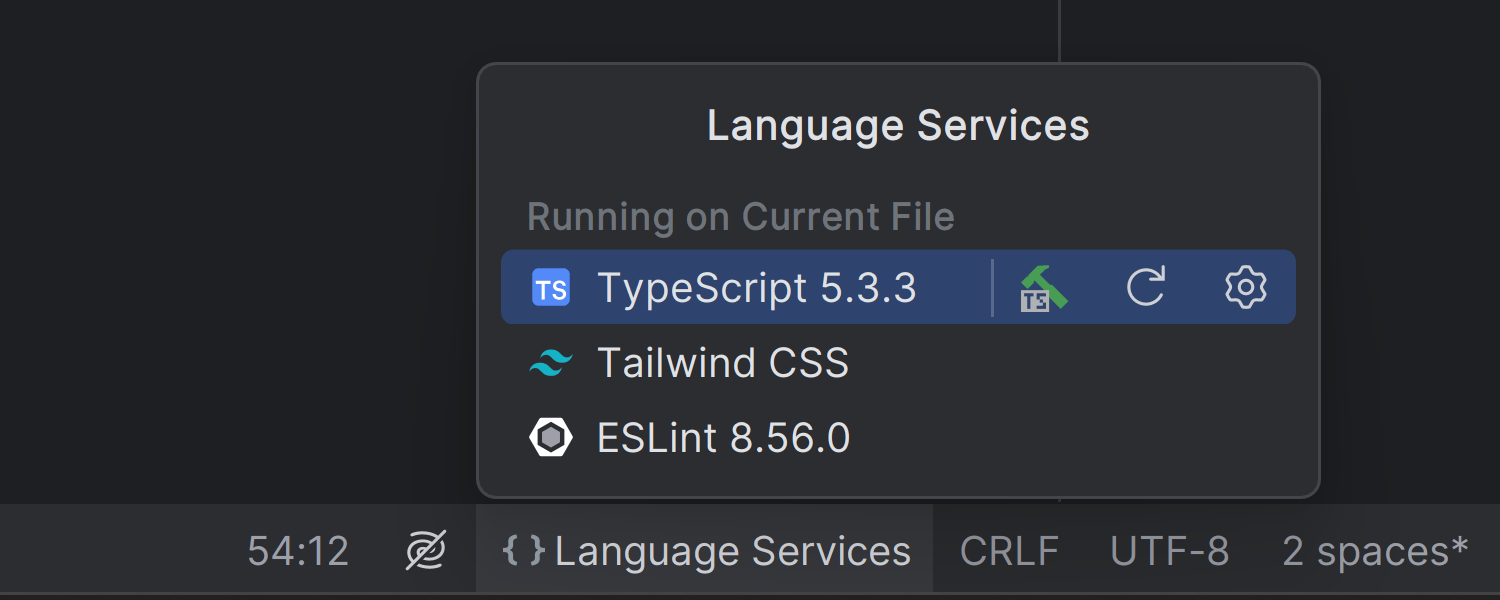
📜网络结构模型用例
📜Python社群纽带关系谱和图神经
📜Python元胞自动机沙堆糖景堵塞模型图学习
📜Python竞技比赛流体动力学艺术品和药物质量图学习


🍇Python图数据
我们经常使用表格来概括地表示信息。但图形使用专门的数据结构:节点代表一个元素,而不是表行。边连接两个节点以指示它们的关系。这种图数据结构使我们能够从独特的角度观察数据,这就是为什么图数据科学被应用于从分子生物学到社会科学的各个领域。
创建一个图很简单:
import networkx as nx
G = nx.Graph()
但 G 还不是一个图,它没有节点和边。
我们可以通过将 Graph() 的返回值与 .add_node() 链接在一起(或对于列表中的多个节点,使用 .add_nodes_from())来将节点添加到网络。我们还可以通过传递字典作为参数来向节点添加任意特征或属性,如节点 4 和节点 5 所示:
G.add_node("node 1")
G.add_nodes_from(["node 2", "node 3"])
G.add_nodes_from([("node 4", {"abc": 123}), ("node 5", {"abc": 0})])
print(G.nodes)
print(G.nodes["node 4"]["abc"]) # accessed like a dictionary
输出:
['node 1', 'node 2', 'node 3', 'node 4', 'node 5']
123
与节点技术类似,我们可以使用 .add_edge() 并将两个节点的名称作为参数(或 .add_edges_from() 用于列表中的多个边),并且可以选择包含属性字典:
G.add_edge("node 1", "node 2")
G.add_edge("node 1", "node 6")
G.add_edges_from([("node 1", "node 3"),
("node 3", "node 4")])
G.add_edges_from([("node 1", "node 5", {"weight" : 3}),
("node 2", "node 4", {"weight" : 5})])
NetworkX 库支持此类图,其中每条边可以具有权重。例如,在社交网络图中,节点是用户,边是交互,权重可以表示给定一对用户之间发生了多少次交互 - 这是一个高度相关的指标。
NetworkX 使用 G.edges 时会列出所有边,但不包括它们的属性。如果我们想要边属性,我们可以使用 G[node_name] 获取连接到节点的所有内容,或使用G[node_name][connected_node_name]获取特定边的属性:
print(G.nodes)
print(G.edges)
print(G["node 1"])
print(G["node 1"]["node 5"])
输出:
['node 1', 'node 2', 'node 3', 'node 4', 'node 5', 'node 6']
[('node 1', 'node 2'), ('node 1', 'node 6'), ('node 1', 'node 3'), ('node 1', 'node 5'), ('node 2', 'node 4'), ('node 3', 'node 4')]
{'node 2': {}, 'node 6': {}, 'node 3': {}, 'node 5': {'weight': 3}}
{'weight': 3}
星球大战角色图:
首先,我们将使用 nx.draw(G_starWars, with_labels = True) 可视化数据,通常一起出现的角色,如 R2-D2 和 C-3PO,看起来联系紧密。相比之下,我们可以看到达斯·维德并没有与欧文分享场景。
NetworkX 还有其他布局,使用不同的标准来定位节点,例如circular_layout:
pos = nx.circular_layout(G_starWars)
nx.draw(G_starWars, pos=pos, with_labels = True)
这种布局是中性的,因为节点的位置不取决于其重要性 - 所有节点都平等表示。(圆形布局还可以帮助可视化单独的连通分量 - 子图在任意两个节点之间都有路径 - 但在这里,整个图是一个大的连通分量。)
我们看到的两种布局都有一定程度的视觉混乱,因为边缘可以自由地交叉其他边缘。但Kamada-Kawai,另一种力导向算法,如 spring_layout,它定位节点以最小化系统能量。这减少了边缘交叉,但代价是:它比其他布局慢,因此不强烈推荐用于具有许多节点的图形。
这个有一个专门的绘图函数:
nx.draw_kamada_kawai(G_starWars, with_labels = True)
在没有任何特殊干预的情况下,算法将主要角色(如卢克、莱娅和 C-3PO)放在中心,而不太突出的角色(如卡米和多多娜将军)放在边界。
使用特定布局可视化图表可以给我们一些有趣的定性结果。尽管如此,定量结果仍然是任何数据科学分析的重要组成部分,因此我们需要定义一些指标。
现在我们可以清楚地可视化我们的网络,我们可能会对表征节点感兴趣。有多种度量来描述节点的特征,在我们的示例中,描述角色的特征。节点的一个基本指标是它的度:它有多少条边。星球大战角色的节点度衡量了他们与多少个其他角色共享一个场景。
Degree() 函数可以计算一个字符或整个网络的度数:
print(G_starWars.degree["LUKE"])
print(G_starWars.degree)
输出:
15
[('R2-D2', 9), ('CHEWBACCA', 6), ('C-3PO', 10), ('LUKE', 15), ('DARTH VADER', 4), ('CAMIE', 2), ('BIGGS', 8), ('LEIA', 12), ('BERU', 5), ('OWEN', 4), ('OBI-WAN', 7), ('MOTTI', 3), ('TARKIN', 3), ('HAN', 6), ('DODONNA', 3), ('GOLD LEADER', 5), ('WEDGE', 5), ('RED LEADER', 7), ('RED TEN', 2)]
根据度数从最高到最低对节点进行排序可以用一行代码完成:
print(sorted(G_starWars.degree, key=lambda x: x[1], reverse=True))
输出:
[('LUKE', 15), ('LEIA', 12), ('C-3PO', 10), ('R2-D2', 9), ('BIGGS', 8), ('OBI-WAN', 7), ('RED LEADER', 7), ('CHEWBACCA', 6), ('HAN', 6), ('BERU', 5), ('GOLD LEADER', 5), ('WEDGE', 5), ('DARTH VADER', 4), ('OWEN', 4), ('MOTTI', 3), ('TARKIN', 3), ('DODONNA', 3), ('CAMIE', 2), ('RED TEN', 2)]