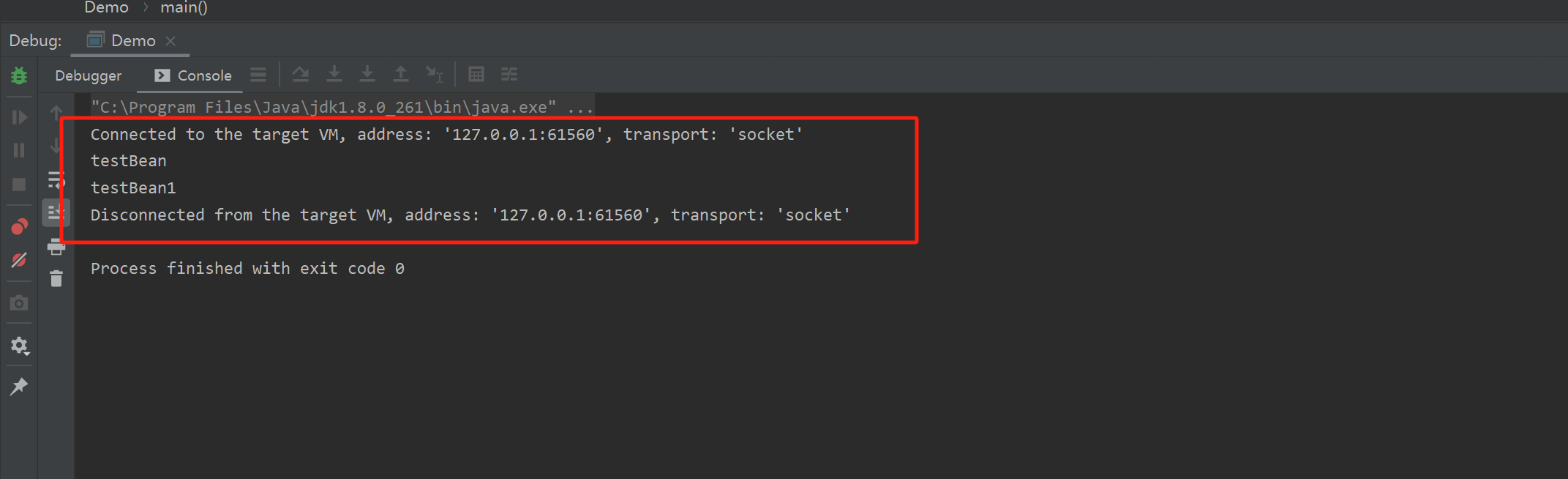
此问题很常见,然而网上关于此问题的分析大多不够深刻,甚至有错误;加之Qt5又更改了一些编码策略,而很多文章并未提及版本问题,或是就算提了,读者也不重视。这些因素很容易让读者产生误导。今日我彻底研究透了这个问题,在此记录。
环境:Qt 4.8.7, Qt Creator 4.2.2, MSVC 2015
Qt 4.8.7 + MSVC 的中文乱码问题,实际上有两层原因。
第一层:MSVC 不识别无 BOM 的 UTF-8
Qt Creator 默认源代码文件编码是无BOM的UTF-8,而MSVC编译器会误认为这是本地多字节字符集(MBCS)编码(对于简中地区,即GBK,代码页936)。
解决方法1(推荐):Qt Creator选项—文本编辑器—文件编码—UTF8 BOM——如果编码是UTF8则添加—确定。
解决方法2:Qt Creator选项—文本编辑器—文件编码—默认编码—GBK—确定。
注意:修改以上两种方法提及的设置后,Qt Creator并不会自动修改已保存的文件的编码或BOM。我们需要修改一下含中文的文件,重新Ctrl+S保存,这样才能将这些设置应用于这些文件。
第二层:QString 构造函数默认假定的文本编码不正确
我们代码中的字符串,特别是用于测试这个乱码问题的字符串,一般都是C样式的,即用一对双引号包围的const char []类型字符串字面量,如 "Hello World" 。然而 Qt 里很多函数的参数要求的字符串类型都是 QString,我们填入这种C样式字符串时就会有个隐式转换,转为QString类型,其实也就是QString这个构造函数在帮我们转换:
explicit QString::QString(const char* ch) 然而const char*类型只表明了这个字符串是多字节字符集,却没指明是哪一种,他可能是GBK, UTF-8等等,甚至可能是跟咱这边八竿子打不着的西欧语言字符集Latin-1(ISO-8859-1)。不加声明的话,MSVC默认我们的字符串字面量是本地多字节字符集(MBCS),即GBK编码,如下图左侧“标题title”文本所示情况。而如果在这种C样式字符串的引号前加上“u8”二字,则MSVC就会认为此字符串是UTF-8编码,如下图右侧“文本text”文本所示情况。![]()
MSVC在我们有或没有声明的情况下判断出了此字符串的编码后,对此字符串进行编码,也就是将它们转换为二进制的字节数据,传给QString的构造函数。
注意:
①即使在上一层问题的解决中,我们选择了保留UTF-8,加上BOM供MSVC识别,以上所述MSVC对C样式字符串的编码的解析方式仍然成立。他不会因为你的源码文件是UTF-8编码,就将其中的这种字符串优先视为UTF-8。所以上一层问题你选择了哪种解决方法对这一层问题是没有影响的。
②“u8”标记只是给MSVC编译器的提示,MSVC处理后,不管是加了u8还是没加,一律变成const char[]这样的字节数组。也就是说,有没有u8,QString的构造函数是不知道的,看不见的。他只知道传进来了一个const char* 类型。
传给QString的构造函数后,QString要解码这些二进制数据,也就是将它们映射到可显示(我们能看懂)的字符上。由于这些数据不能体现编码,他就要猜。咱当然希望他猜是GBK啦,但是事与愿违,Qt库毕竟不是中国人写的。他默认猜成西欧语言字符集Latin-1(如图)!这就会导致我们在代码里写了些汉字,却显示出一堆拉丁字母甚至音标。这也是为何在没有QString参与的情况下只解决第一层问题就好了,例如控制台窗口的std::cout,而在需要把const char*转换成QString时就又会出问题。

那么解决思路已经很明显了。要么修改它的设置,让他猜成GBK(或UTF-8),要么明明白白的告诉他我们的字符串是啥编码(使用 QString::fromXXX 函数)。
解决方法1(推荐):在 QApplication 对象创建前将“C样式字符串的编码(CodecForCStrings)”设为UTF-8,并在每个含中文的字符串字面量的前导引号前加上u8二字(如QString str(u8"这是中文");)。设置“C样式字符串的编码”的方法是:在程序的入口点(main函数)中最开始的位置加上图中这句代码(别忘了加头文件):
QTextCodec::setCodecForCStrings(QTextCodec::codecForName("UTF-8"));
解决方法2: 跟方法1一样修改“C样式字符串的编码”,但设为本地多字节字符集(MBCS,一般是GBK),代码中的字符串字面量不加“u8”(如QString str("这是中文");)。具体方法和上条类似,不再赘述,但main函数中加的那句代码改为:
QTextCodec::setCodecForCStrings(QTextCodec::codecForLocale());解决方法3: 在每个字符串字面量的前导引号前加上u8,并用 QString::fromLocal8Bit() 包裹,如图:

解决方法4:字符串字面量的前导引号前不加u8,并用 QString::fromLocal8Bit() 包裹,如图:

依次解决以上两层问题后,中文就不再乱码了。再次强调,本文只针对 Qt 4.8.7 + MSVC2015 环境提供问题原理和解决方案,Qt5就不一样了,说不定微软也会在未来的MSVC中添加对无BOM的UTF-8文件的识别。那时,问题的解决将简单很多。
szx0427 作于 2024/07/17