一、JavaSE + JaveEE ——
Java 数据结构 —— 集合类
1. HashMap 底层,链表与红黑树转换原因
- JDK 1.7 HashMap 底层使用 “数组+链表” 实现,数组为主体,链表为了解决 哈希冲突
- JDK 1.8 HashMap 底层使用 “数组+链表+红黑树” 实现
当链表长度超过8且数组长度过64时将链表转为红黑树,若当前数组长度小于64,会优先进行数组扩容,转换的原因是当链表过长时线性结构遍历速度过慢
2. Hashtable 和 ConcurrentHashMap 的底层实现
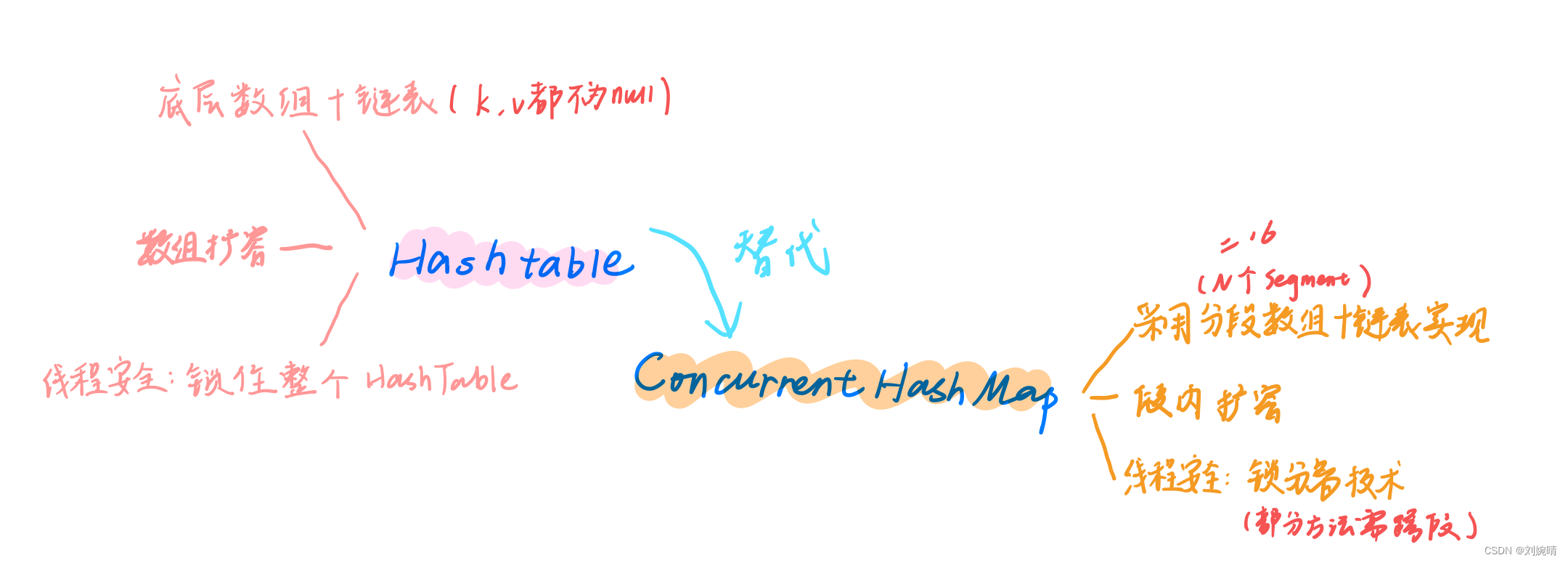
1. Hashtable
- 底层:采用 数组+链表 实现,无论key还是value都不能为null
- 实现线程安全的方式:在修改数据时锁住整个HashTable,效率低
- 扩容:newsize = oldsize*2+1,将数组大小扩大为原来的两倍
2. ConcurrentHashMap - 底层:Hashtable 的升级,底层采用 分段数组+链表 实现,把整个Map分为N个Segment (默认为 16 个)
- 线程安全通过 锁分离技术 实现,允许多个修改操作并发进行。但是有些方法需要跨段(
size() 、containsValue()),即要锁定整个表(按顺序锁定所有段,操作完毕后,按顺序释放所有段的锁) - 扩容:不对整个Map进行扩容,而是进行段内扩容,段内元素超过该段对应Entry数组长度的75%触发扩容,插入前检测需不需要扩容,有效避免无效扩容
3. ArrayList 和 LinkedList的区别和使用场景
ArrayList 和 LinkedList 均是 List 集合类的实现类
1. ArrayList
- 采用可变数组保存对象
- 随机访问元素速度快
- 插入与删除元素的速度相对较慢
- 适合于具有快速访问对象需求的场景
2. LinkedList
- 采用链表结构保存对象
- 随机访问元素速度相对较慢
- 便于向集合中插入或者删除元素
- 适合于需要频繁向集合中插入和删除元素的场景
注: 随机访问 —— 指检索集合中特定索引位置的元素
Java 多线程
4. 线程池的参数及创建线程的方式 *
5. volatile保证了什么 及具体的内存屏障,volatile加在基本类型和对象上的区别
6. synchronized 和 ReentrantLock 区别和场景
Java 虚拟机 —— JVM
7. 垃圾回收的算法及详细介绍
8. 反射的介绍与使用场景
9. 两种动态代理的区别(现敲jdk方式)
JavaEE —— 框架题
10. SpringBoot 和 Spring的区别,自动装配的原理
11. SpringCloudAlibaba的组件介绍
数据库 ——
- 项目用到的 Redis 数据结构和使用场景
- Redis 快的原因
- 缓存常见问题和解决方案(引申到多级缓存)
- 多级缓存(Redis,Nginx,本地缓存)的实现思路
- 自己实现 Redis分布式锁的坑,与zk分布式锁的区别
- Redis的主从架构和主从哨兵区别,Redis 主从数据一致性问题
- MySQL 的 ACID、隔离级别和并发问题,MVCC
- MySQL的 聚蔟索引和非聚蔟索引,B+ 树相比其他结构的优势
计算机基础 ——
- 三次握手目的
- 线程生命周期与状态转换
- HTTP 和 HTTPS
- 用户态和内核态切换为什么消耗资源
- select、poll 和 epoll相比于前两种的优点