目录
- 1.基本配置
- 2.数据读入
- 3.模型构建
- 3.1神经网络的构造
- 3.2神经网络中常见的层
- 常见网络层的构造
- 常见的网络层
- 3.3模型示例
- 卷积神经网络(LeNet)
- 深度卷积神经网络(AlexNet)
- 4.模型初始化
- 5.损失函数
- 6.训练和评估
深度学习和机器学习在流程上基本类似,但在代码实现上有较大差异。
- 由于深度学习所需的样本量很大,一次加载全部数据运行可能会超出内存容量而无法实现,需要每次读取固定数量的样本送入模型中训练,故设计批(batch)训练等提高模型表现的策略。
- 在模型实现上,由于深度神经网络层数往往较多,同时会有一些用于实现特定功能的层(如卷积层、池化层、批正则化层、LSTM层等),因此深度神经网络往往需要“逐层”搭建,或者预先定义好可以实现特定功能的模块,再把这些模块组装起来。
- 损失函数和优化器要能够保证反向传播,能够在用户自行定义的模型结构上实现。
- 由于所需的算力大,需要把模型和数据“放到”GPU上去做运算,同时还需要保证损失函数和优化器能够在GPU上工作。
深度学习中训练和验证过程最大的特点在于读入数据是按批的,每次读入一个批次的数据,放入GPU中训练,然后将损失函数反向传播回网络最前面的层,同时使用优化器调整网络参数。这里会涉及到各个模块配合的问题。训练/验证后还需要根据设定好的指标计算模型表现。
1.基本配置
导入必须的包:
import os
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
import torch.optim as optimizer
如下几个超参数可以统一设置,方便后续调试时修改:
- batch size
- 初始学习率(初始)
- 训练次数(max_epochs)
- GPU配置
batch_size = 16
# 批次的大小
lr = 1e-4
# 优化器的学习率
max_epochs = 100
我们的数据和模型如果没有经过显式指明设备,默认会存储在CPU上,为了加速模型的训练,我们需要显式调用GPU,一般情况下GPU的设置有两种常见的方式:
# 方案一:使用os.environ,这种情况如果使用GPU不需要设置
import os
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号
# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
device = torch.device("cuda:1" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号
2.数据读入
PyTorch数据读入是通过Dataset+DataLoader的方式完成的,Dataset定义好数据的格式和数据变换形式,DataLoader用iterative的方式不断读入批次数据。
我们可以定义自己的Dataset类来实现灵活的数据读取,定义的类需要继承PyTorch自身的Dataset类。主要包含三个函数:
- __ init __: 用于向类中传入外部参数,同时定义样本集
- __ getitem __: 用于逐个读取样本集合中的元素,可以进行一定的变换,并将返回训练/验证所需的数据
- __ len__: 用于返回数据集的样本数
下面以自定义数据集为例给出构建Dataset类的方式:
import torch
from torch.utils.data import Dataset
class MyDataset(Dataset):
def __init__(self, X, y=None):
self.data = torch.from_numpy(X).float()
if y is not None:
y = y.astype(np.int)
self.label = torch.LongTensor(y)
else:
self.label = None
def __getitem__(self, idx):
if self.label is not None:
return self.data[idx], self.label[idx]
else:
return self.data[idx]
def __len__(self):
return len(self.data)
构建好Dataset后,就可以使用DataLoader来按批次读入数据:
train_set = MyDataset(train_x, train_y)
val_set = MyDataset(val_x, val_y)
train_loader = DataLoader(train_set, batch_size=batch_size, num_workers=0, shuffle=True, drop_last=True) #only shuffle the training data
val_loader = DataLoader(val_set, batch_size=batch_size,num_workers=0, shuffle=False)
其中:
- batch_size:样本是按“批”读入的,batch_size就是每次读入的样本数
- num_workers:有多少个进程用于读取数据,Windows下该参数设置为0,Linux下常见的为4或者8,根据自己的电脑配置来设置
- shuffle:是否将读入的数据打乱,一般在训练集中设置为True,验证集中设置为False
- drop_last:对于样本最后一部分没有达到批次数的样本,使其不再参与训练
3.模型构建
3.1神经网络的构造
PyTorch中神经网络构造一般是基于nn.Module类的模型来完成的,它让模型构造更加灵活。
Module 类是 torch.nn 模块里提供的一个模型构造类,是所有神经网络模块的基类,我们可以继承它来定义我们想要的模型。
定义的 MLP 类重载了 Module 类的 __ init __ 函数和 forward 函数。它们分别用于创建模型参数和定义前向计算(正向传播)。下面的 MLP 类定义了一个具有两个隐藏层的多层感知机。
import torch
from torch import nn
class MLP(nn.Module):
# 声明带有模型参数的层,这里声明了两个全连接层
def __init__(self, **kwargs):
# 调用MLP父类Block的构造函数来进行必要的初始化。这样在构造实例时还可以指定其他函数
super(MLP, self).__init__(**kwargs)
self.hidden = nn.Linear(784, 256)
self.act = nn.ReLU()
self.output = nn.Linear(256,10)
# 定义模型的前向计算,即如何根据输入x计算返回所需要的模型输出
def forward(self, x):
o = self.act(self.hidden(x))
return self.output(o)
以上的 MLP 类中⽆须定义反向传播函数。系统将通过⾃动求梯度⽽自动⽣成反向传播所需的 backward 函数。
net = MLP() # 实例化模型
print(net) # 打印模型
'''
MLP(
(hidden): Linear(in_features=784, out_features=256, bias=True)
(act): ReLU()
(output): Linear(in_features=256, out_features=10, bias=True)
)
'''
3.2神经网络中常见的层
常见网络层的构造
1.不含模型参数的层
MyLayer 类通过继承 Module 类自定义了一个将输入减掉均值后输出的层,并将层的计算定义在了 forward 函数里。这个层里不含模型参数。
import torch
from torch import nn
class MyLayer(nn.Module):
def __init__(self, **kwargs):
super(MyLayer, self).__init__(**kwargs)
def forward(self, x):
return x - x.mean()
实例化该层,然后做前向计算
layer = MyLayer()
layer(torch.tensor([1, 2, 3, 4, 5], dtype=torch.float))
#tensor([-2., -1., 0., 1., 2.])
2.含模型参数的层
自定义含模型参数的自定义层,其中的模型参数可以通过训练学出。
class MyListDense(nn.Module):
def __init__(self):
super(MyListDense, self).__init__()
self.params = nn.ParameterList([nn.Parameter(torch.randn(4, 4)) for i in range(3)])
self.params.append(nn.Parameter(torch.randn(4, 1)))
def forward(self, x):
for i in range(len(self.params)):
x = torch.mm(x, self.params[i])
return x
net = MyListDense()
print(net)
常见的网络层
卷积层
二维卷积层将输入和卷积核做互相关运算,并加上一个标量偏差来得到输出。卷积层的模型参数包括了卷积核和标量偏差。在训练模型的时候,通常我们先对卷积核随机初始化,然后不断迭代卷积核和偏差。
import torch
from torch import nn
# 卷积运算(二维互相关)
def corr2d(X, K):
h, w = K.shape
X, K = X.float(), K.float()
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i: i + h, j: j + w] * K).sum()
return Y
# 二维卷积层
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super(Conv2D, self).__init__()
self.weight = nn.Parameter(torch.randn(kernel_size))
self.bias = nn.Parameter(torch.randn(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
填充(padding)是指在输⼊高和宽的两侧填充元素(通常是0元素)。
下面的例子里我们创建一个⾼和宽为3的二维卷积层,然后设输⼊高和宽两侧的填充数分别为1。给定一个高和宽为8的输入,我们发现输出的高和宽也是8。
import torch
from torch import nn
# 为了方便起见,我们定义了一个计算卷积层的函数。
# 此函数初始化卷积层权重,并对输入和输出提高和缩减相应的维数
def comp_conv2d(conv2d, X):
# 这里的(1,1)表示批量大小和通道数都是1
X = X.reshape((1, 1) + X.shape)
Y = conv2d(X)
# 省略前两个维度:批量大小和通道
return Y.reshape(Y.shape[2:])
# 请注意,这里每边都填充了1行或1列,因此总共添加了2行或2列
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1)
X = torch.rand(size=(8, 8))
comp_conv2d(conv2d, X).shape
#torch.Size([8, 8])
当卷积核的高度和宽度不同时,我们可以填充不同的高度和宽度,使输出和输入具有相同的高度和宽度。在如下示例中,我们使用高度为5,宽度为3的卷积核,高度和宽度两边的填充分别为2和1。
conv2d = nn.Conv2d(1, 1, kernel_size=(5, 3), padding=(2, 1))
comp_conv2d(conv2d, X).shape
#torch.Size([8, 8])
在二维互相关运算中,卷积窗口从输入数组的最左上方开始,按从左往右、从上往下 的顺序,依次在输⼊数组上滑动。我们将每次滑动的行数和列数称为步幅(stride)。
我们将高度和宽度的步幅设置为2,从而将输入的高度和宽度减半。
conv2d = nn.Conv2d(1, 1, kernel_size=3, padding=1, stride=2)
comp_conv2d(conv2d, X).shape
#torch.Size([4, 4])
- 填充可以增加输出的高度和宽度。这常用来使输出与输入具有相同的高和宽。
- 步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的1/n(n是一个大于1的整数)。
- 填充和步幅可用于有效地调整数据的维度。
池化层
池化层每次对输入数据的一个固定形状窗口(⼜称池化窗口)中的元素计算输出。不同于卷积层里计算输⼊和核的互相关性,池化层直接计算池化窗口内元素的属性(均值、最大值等)。常见的池化包括最大池化或平均池化。在二维最⼤池化中,池化窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输⼊数组上滑动。当池化窗口滑动到某⼀位置时,窗口中的输入子数组的最大值即输出数组中相应位置的元素。
import torch
from torch import nn
def pool2d(X, pool_size, mode='max'):#默认为最大
p_h, p_w = pool_size
Y = torch.zeros((X.shape[0] - p_h + 1, X.shape[1] - p_w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
if mode == 'max':
Y[i, j] = X[i: i + p_h, j: j + p_w].max()
elif mode == 'avg':
Y[i, j] = X[i: i + p_h, j: j + p_w].mean()
return Y
X = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]], dtype=torch.float)
pool2d(X, (2, 2))
'''tensor([[4., 5.],
[7., 8.]])'''
pool2d(X, (2, 2), 'avg')
'''tensor([[2., 3.],
[5., 6.]])'''
- 对于给定输入元素,最大池化层会输出该窗口内的最大值,平均池化层会输出该窗口内的平均值。
- 池化层的主要优点之一是减轻卷积层对位置的过度敏感。
3.3模型示例
卷积神经网络(LeNet)
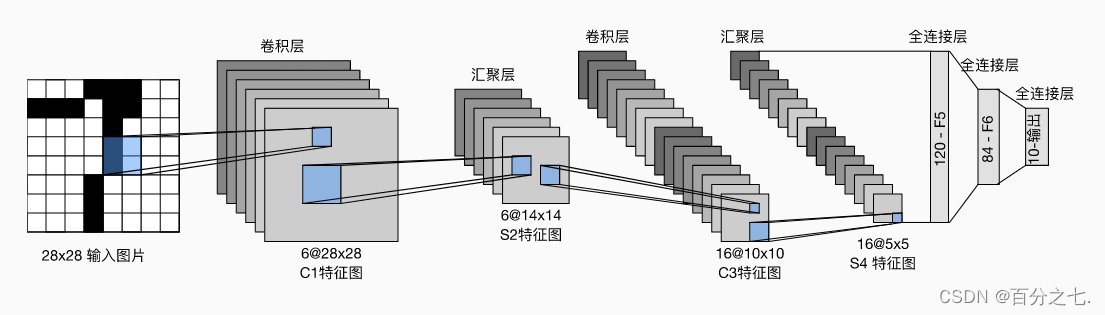
这是一个简单的前馈神经网络 (feed-forward network)(LeNet)。它接受一个输入,然后将它送入下一层,一层接一层的传递,最后给出输出。
一个神经网络的典型训练过程如下:
1.定义包含一些可学习参数(或者叫权重)的神经网络
2.在输入数据集上迭代
3.通过网络处理输入
4.计算 loss (输出和正确答案的距离)
5.将梯度反向传播给网络的参数
6.更新网络的权重,一般使用一个简单的规则:weight = weight - learning_rate * gradient
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 输入图像channel:1;输出channel:6;5x5卷积核
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
# an affine operation: y = Wx + b
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# 2x2 Max pooling
x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
# 如果是方阵,则可以只使用一个数字进行定义
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, self.num_flat_features(x))
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def num_flat_features(self, x):
size = x.size()[1:] # 除去批处理维度的其他所有维度
num_features = 1
for s in size:
num_features *= s
return num_features
- 先使用卷积层来学习图片空间信息
- 然后使用全连接层来转换到类别空间
深度卷积神经网络(AlexNet)
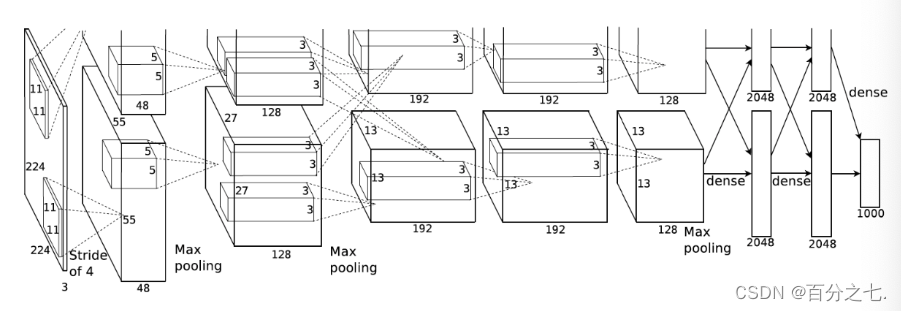
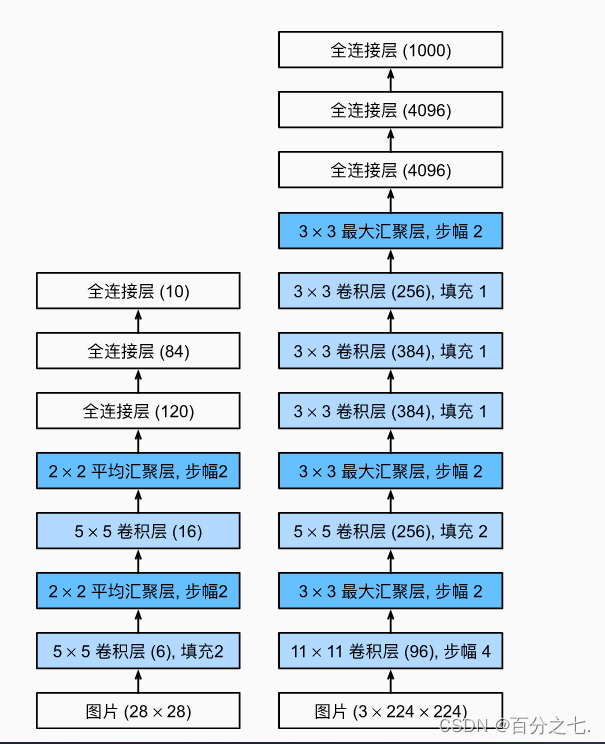
1.AlexNet比相对较小的LeNet5要深得多。AlexNet由八层组成:五个卷积层、两个全连接隐藏层和一个全连接输出层。
2.AlexNet使用ReLU而不是sigmoid作为其激活函数。
3.AlexNet使用更大的核窗口和步长,因为图片更大了。
4.AlexNet使用更大的池化窗口,使用最大池化层而不是平均池化层。
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
self.conv = nn.Sequential(
# 这里使用一个11*11的更大窗口来捕捉对象。
# 同时,步幅为4,以减少输出的高度和宽度。
# 另外,输出通道的数目远大于LeNet
nn.Conv2d(1, 96, 11, 4), # in_channels, out_channels, kernel_size, stride, padding
nn.ReLU(),
#最大池化层
nn.MaxPool2d(3, 2), # kernel_size, stride
# 减小卷积窗口,使用填充为2来使得输入与输出的高和宽一致,且增大输出通道数
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(),
nn.MaxPool2d(3, 2),
# 连续3个卷积层,且使用更小的卷积窗口。除了最后的卷积层外,进一步增大了输出通道数。
# 前两个卷积层后不使用池化层来减小输入的高和宽
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(),
nn.MaxPool2d(3, 2)
)
# 这里全连接层的输出个数比LeNet中的大数倍。使用丢弃层来缓解过拟合
self.fc = nn.Sequential(
nn.Linear(256*5*5, 4096),
nn.ReLU(),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(0.5),
# 输出层。由于这里使用Fashion-MNIST,所以用类别数为10,而非论文中的1000
nn.Linear(4096, 10),
)
def forward(self, img):
feature = self.conv(img)
output = self.fc(feature.view(img.shape[0], -1))
return output
- 激活函数从sigmoid变到了ReLu(减缓梯度消失)
- 隐藏全连接层后加入了丢弃层
4.模型初始化
在深度学习模型的训练中,权重的初始值极为重要。一个好的初始值,会使模型收敛速度提高,使模型准确率更精确。torch.nn.init提供了以下初始化方法:
| torch.nn.init.uniform_(tensor, a=0.0, b=1.0) |
| torch.nn.init.normal_(tensor, mean=0.0, std=1.0) |
| torch.nn.init.constant_(tensor, val) |
| torch.nn.init.ones_(tensor) |
| torch.nn.init.zeros_(tensor) |
| torch.nn.init.eye_(tensor) |
| torch.nn.init.dirac_(tensor, groups=1) |
| torch.nn.init.xavier_uniform_(tensor, gain=1.0) |
| torch.nn.init.xavier_normal_(tensor, gain=1.0) |
| torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan__in’, nonlinearity=‘leaky_relu’) |
| torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’) |
| torch.nn.init.orthogonal_(tensor, gain=1) |
| torch.nn.init.sparse_(tensor, sparsity, std=0.01) |
| torch.nn.init.calculate_gain(nonlinearity, param=None) |
5.损失函数
在PyTorch中,损失函数是必不可少的。它是数据输入到模型当中,产生的结果与真实标签的评价指标,我们的模型可以按照损失函数的目标来做出改进。
这里将列出PyTorch中常用的损失函数(一般通过torch.nn调用):
1.二分类交叉熵损失函数
torch.nn.BCELoss(weight=None, size_average=None, reduce=None, reduction='mean')
功能:计算二分类任务时的交叉熵(Cross Entropy)函数。、
2.交叉熵损失函数
torch.nn.CrossEntropyLoss(weight=None, size_average=None, ignore_index=-100, reduce=None, reduction='mean')
功能:计算交叉熵函数
3. L1损失函数
torch.nn.L1Loss(size_average=None, reduce=None, reduction='mean')
功能: 计算输出y和真实标签target之间的差值的绝对值。
4.MSE损失函数
torch.nn.MSELoss(size_average=None, reduce=None, reduction='mean')
功能: 计算输出y和真实标签target之差的平方。
5.平滑L1 (Smooth L1)损失函数
torch.nn.SmoothL1Loss(size_average=None, reduce=None, reduction='mean', beta=1.0)
功能: L1的平滑输出,其功能是减轻离群点带来的影响
6.目标泊松分布的负对数似然损失
torch.nn.PoissonNLLLoss(log_input=True, full=False, size_average=None, eps=1e-08, reduce=None, reduction='mean')
功能: 泊松分布的负对数似然损失函数
7.KL散度
torch.nn.KLDivLoss(size_average=None, reduce=None, reduction='mean', log_target=False)
功能: 计算KL散度,也就是计算相对熵。用于连续分布的距离度量,并且对离散采用的连续输出空间分布进行回归通常很有用。
8.多标签边界损失函数
torch.nn.MultiLabelMarginLoss(size_average=None, reduce=None, reduction='mean')
功能: 对于多标签分类问题计算损失函数。
6.训练和评估
训练模型存在两种状态:
(1)训练态:模型的参数应该支持反向传播(主要是对模型参数不断更新,训练出最优的模型)
(2)验证/测试态:不应该修改模型参数(加载上面已经训练好的模型进行预测结果)
在PyTorch中,模型的状态设置非常简便,如下的两个操作二选一即可:
model.train() # 训练状态
model.eval() # 验证/测试状态
一个完整的图像分类的训练过程如下所示:
def train(epoch):
model.train()
train_loss = 0
for data, label in train_loader:#用for循环读取DataLoader中的全部数据。
data, label = data.cuda(), label.cuda()#将数据放到GPU上用于后续计算
optimizer.zero_grad()#开始用当前批次数据做训练时,应当将优化器的梯度置零
output = model(data)#将data送入模型中训练
loss = criterion(label, output)#根据预先定义的criterion计算损失函数
loss.backward()#将loss反向传播回网络
optimizer.step()#使用优化器更新模型参数
train_loss += loss.item()*data.size(0)
train_loss = train_loss/len(train_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, train_loss))
验证/测试的流程基本与训练过程一致,不同点在于:
- 需要预先设置torch.no_grad,以及将model调至eval模式
- 不需要将优化器的梯度置零
- 不需要将loss反向回传到网络
- 不需要更新optimizer
对应的,一个完整图像分类的验证过程如下所示:
def val(epoch):
model.eval()
val_loss = 0
with torch.no_grad():#无需计算梯度
for data, label in val_loader:
data, label = data.cuda(), label.cuda()
output = model(data)
preds = torch.argmax(output, 1)
loss = criterion(output, label)
val_loss += loss.item()*data.size(0)
running_accu += torch.sum(preds == label.data)
val_loss = val_loss/len(val_loader.dataset)
print('Epoch: {} \tTraining Loss: {:.6f}'.format(epoch, val_loss))