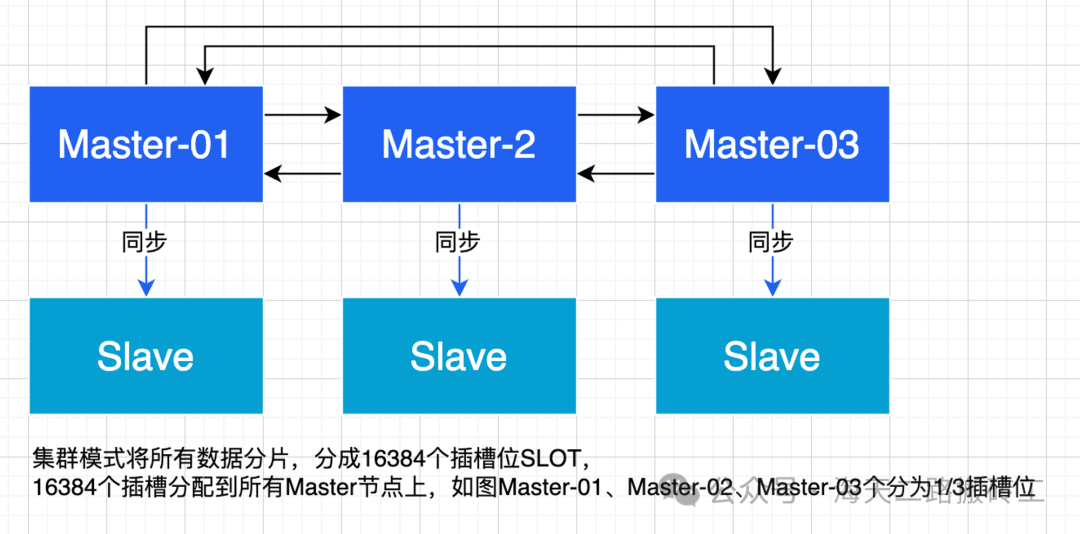
Introduction
前两期我们对Pandas的数据结构和常用的计算方法进行了介绍,在地球科学领域时间序列分析是很重要的一种数据处理方式。
通过理解数据的时间变化特征,我们可以更深入地理解研究对象的演化规律与物理机制。
因此,本期我们就从Pandas中时间序列数据处理的角度,来探究地球科学领域中时间序列数据的一些常用方法。
❝时间戳
是指一个表示某个特定时间点的字符串或编码信息。它通常由一组数字组成,代表从某个参考时间(例如格林威治时间 1970 年 1 月 1 日 00:00:00 UTC)开始经过的时间量,单位为秒或毫秒。
Python中,可以使用
time模块和datetime模块来处理时间戳。由于Pandas模块中内置了这些函数,因此我们不需要再单独使用上述模块处理。
时间序列的创建
Pandas中时间序列的创建主要有两种方式:
-
通过Pandas中内置的
date_range函数创建时间序列,该函数可以指定起始日期、结束日期、时间步长等参数,并返回一个DatetimeIndex对象。 -
通过Pandas中
to_datetime函数将其他格式的日期时间字符串转换为DatetimeIndex对象(当我们需要将读取到Pandas中的表格日期转换为时间格式时,将十分有用)。
下面通过例子来说明这两种方法的使用。
使用date_range创建时间序列
date_range函数能通过组合不同的参数以多种形式创建连续的时间序列,我们首先通过指定起止时间和时间步长freq生成时间序列。
Pandas中常见的时间步长包括:
-
S:秒 -
T:分钟 -
H:小时 -
D:天 -
B:工作日 -
W:周 -
M:月 -
Q:季度 -
Y:年
我们可以在时间步长前面加上数字来自定义时间步长,比如2H表示2小时。
import pandas as pd
# 已知起始日期和结束日期,生成日期序列,默认时间步长为1天
date_range = pd.date_range(start='2021-01-01', end='2021-01-04')
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-05-07', freq='M') # 设置步长为月
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-08-07', freq='3M') # 设置步长为3个月
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-05-07', freq='5W') # 设置步长为周
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-01-06', freq='B') # 设置步长为工作日
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-11-07', freq='Q') # 设置步长为季度
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2023-05-07', freq='YS') # 设置步长为半年
print(date_range)
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04'], dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2021-01-31', '2021-02-28', '2021-03-31', '2021-04-30'], dtype='datetime64[ns]', freq='M')
DatetimeIndex(['2021-01-31', '2021-04-30', '2021-07-31'], dtype='datetime64[ns]', freq='3M')
DatetimeIndex(['2021-01-03', '2021-02-07', '2021-03-14', '2021-04-18'], dtype='datetime64[ns]', freq='5W-SUN')
DatetimeIndex(['2021-01-01', '2021-01-04', '2021-01-05', '2021-01-06'], dtype='datetime64[ns]', freq='B')
DatetimeIndex(['2021-03-31', '2021-06-30', '2021-09-30'], dtype='datetime64[ns]', freq='Q-DEC')
DatetimeIndex(['2021-01-01', '2022-01-01', '2023-01-01'], dtype='datetime64[ns]', freq='AS-JAN')
我们可以注意到,Pandas按周、月份、季度步长生成的日期为最后一天。而且,季度的计算方式默认按照了自然节律的3-4-5月为第一季度来计算。
我们可以进行一些自定义操作:
date_range = pd.date_range(start='2021-01-01', end='2021-04-07', freq='MS') # 设置生成日期为当月第一天,MS(month start)
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-05-07', freq='QS') # 设置生成日期为季度第一天,且季度起算月变为了1月
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2024-05-07', freq='YS') # 设置生成日期为每年第一天
print(date_range)
date_range = pd.date_range(start='2021-01-01', end='2021-01-15', freq='W-MON') # 设置生成日期为每周的星期一
print(date_range)
date_range = pd.date_range(start='2023-01-01', end='2024-01-15', freq='QS-FEB') # 设置生成日期为季度第一天,且以2月为季度起始
print(date_range)
DatetimeIndex(['2021-01-01', '2021-02-01', '2021-03-01', '2021-04-01'], dtype='datetime64[ns]', freq='MS')
DatetimeIndex(['2021-01-01', '2021-04-01'], dtype='datetime64[ns]', freq='QS-JAN')
DatetimeIndex(['2021-01-01', '2022-01-01', '2023-01-01', '2024-01-01'], dtype='datetime64[ns]', freq='AS-JAN')
DatetimeIndex(['2021-01-04', '2021-01-11'], dtype='datetime64[ns]', freq='W-MON')
DatetimeIndex(['2023-02-01', '2023-05-01', '2023-08-01', '2023-11-01'], dtype='datetime64[ns]', freq='QS-FEB')
有些情况下,我们只知道初始日期或截止日期,我们可以通过所需的时间步长和周期数来计算时间序列。
date_range = pd.date_range(start='2021-01-01', freq='D', periods=7) # 已知起始日期、频率、周期,生成日期序列
print(date_range)
date_range = pd.date_range(end='2021-01-07', freq='W', periods=7) # 已知结束日期、频率、周期,生成日期序列
print(date_range)
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05', '2021-01-06', '2021-01-07'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2020-11-22', '2020-11-29', '2020-12-06', '2020-12-13',
'2020-12-20', '2020-12-27', '2021-01-03'],
dtype='datetime64[ns]', freq='W-SUN')
此外,date_range函数还包含了几个可能用到的参数:
-
tz:指定时区,默认为None,表示使用系统默认时区 -
normalize:将日期归一化到00:00,默认为False -
name:指定生成的时间序列名称 -
inclusive:旧版中为closed,生成的日期范围是否包含开始和结束日期,默认为left(左闭右开)。其他可选值有right(左开右闭)、both(左闭右闭)、neither(左开右开)
date_range = pd.date_range('2021-01-01', '2021-01-05', freq='D', tz='Asia/Tokyo') # 东九区东京时间
print(date_range)
print(date_range.tz_convert('UTC')) # 转换为中时区标准时间
DatetimeIndex(['2021-01-01 00:00:00+09:00', '2021-01-02 00:00:00+09:00',
'2021-01-03 00:00:00+09:00', '2021-01-04 00:00:00+09:00',
'2021-01-05 00:00:00+09:00'],
dtype='datetime64[ns, Asia/Tokyo]', freq='D')
DatetimeIndex(['2020-12-31 15:00:00+00:00', '2021-01-01 15:00:00+00:00',
'2021-01-02 15:00:00+00:00', '2021-01-03 15:00:00+00:00',
'2021-01-04 15:00:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
date_range = pd.date_range('2021-01-01 12:25:56', '2021-12-31', freq='M')
print(date_range[0])
date_range = pd.date_range('2021-01-01 12:25:56', '2021-12-31', freq='M', normalize=True) # 归一化日期至00:00:00
print(date_range[0])
2021-01-31 12:25:56
2021-01-31 00:00:00
date_range = pd.date_range('2021-01-01', '2021-12-31', freq='Q', name='Seasonal')
print(date_range)
date_range = pd.date_range('2024-05-01', '2024-05-04', inclusive='left')
print(date_range)
date_range = pd.date_range('2024-05-01', '2024-05-04', inclusive='right')
print(date_range)
date_range = pd.date_range('2024-05-01', '2024-05-04', inclusive='both')
print(date_range)
date_range = pd.date_range('2024-05-01', '2024-05-04', inclusive='neither')
print(date_range)
DatetimeIndex(['2021-03-31', '2021-06-30', '2021-09-30', '2021-12-31'], dtype='datetime64[ns]', name='Seasonal', freq='Q-DEC')
DatetimeIndex(['2024-05-01', '2024-05-02', '2024-05-03'], dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2024-05-02', '2024-05-03', '2024-05-04'], dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2024-05-01', '2024-05-02', '2024-05-03', '2024-05-04'], dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2024-05-02', '2024-05-03'], dtype='datetime64[ns]', freq='D')
从其他格式创建时间序列
这里的其他格式一般就是指字符串形式的日期时间,如'2021-01-01'。当我们从外部文件导入大量带时间的数据时,可以通过to_datetime函数便捷地将其转换为时间序列。
我们从外部读取一个.csv文件,并将其日期时间列转换为时间序列。
pth = r'F:\Proj_Geoscience.Philosophy\Material\tmp_SSP2.csv'
df = pd.read_csv(pth, index_col=0)
print(df)
ACCESS-CM2 EC-Earth3 EC-Earth3-Veg MPI-ESM1-2-HR GFDL-ESM4 \
1990-12-31 -9.838771 -9.637003 -9.321887 -10.383628 -9.549001
1991-12-31 -10.165740 -9.453364 -9.650858 -10.076542 -9.783594
1992-12-31 -10.944804 -10.569817 -9.624666 -10.221733 -9.442735
1993-12-31 -11.011893 -10.919116 -9.689930 -10.822980 -9.617322
1994-12-31 -9.935500 -9.687431 -10.403852 -10.077468 -9.583637
... ... ... ... ... ...
2096-12-31 -6.101502 -6.675644 -5.595156 -6.935057 -8.173742
2097-12-31 -6.801526 -4.585644 -6.461058 -7.107297 -7.350170
2098-12-31 -7.923017 -6.654356 -6.137528 -6.842564 -7.736062
2099-12-31 -6.628777 -7.413971 -4.578230 -7.274006 -7.175193
2100-12-31 -6.997662 -4.661766 -5.654026 -7.408147 -7.621691
[111 rows x 7 columns]
❝这里对一个气温数据进行了读取,我们使用了Pandas中的
read_csv函数。第一行默认成为了DataFrame的列名,由于我们指定了参数index_col=0,因此第一列被设置为行名。
下面我们将DataFrame的索引由字符串转换为日期格式:
print(df.index)
df.index = pd.to_datetime(df.index)
print(df.index)
Index(['1990-12-31', '1991-12-31', '1992-12-31', '1993-12-31', '1994-12-31',
'1995-12-31', '1996-12-31', '1997-12-31', '1998-12-31', '1999-12-31',
...
'2091-12-31', '2092-12-31', '2093-12-31', '2094-12-31', '2095-12-31',
'2096-12-31', '2097-12-31', '2098-12-31', '2099-12-31', '2100-12-31'],
dtype='object', length=111)
DatetimeIndex(['1990-12-31', '1991-12-31', '1992-12-31', '1993-12-31',
'1994-12-31', '1995-12-31', '1996-12-31', '1997-12-31',
'1998-12-31', '1999-12-31',
...
'2091-12-31', '2092-12-31', '2093-12-31', '2094-12-31',
'2095-12-31', '2096-12-31', '2097-12-31', '2098-12-31',
'2099-12-31', '2100-12-31'],
dtype='datetime64[ns]', length=111, freq=None)
我们也可以直接对字符串、列表等进行转换,而不一定都是Pandas对象。
print(pd.to_datetime('2021-01'))
print(pd.to_datetime(['2021-01-01', '2021-01-02']))
2021-01-01 00:00:00
DatetimeIndex(['2021-01-01', '2021-01-02'], dtype='datetime64[ns]', freq=None)
to_datetime函数中,format参数可以指定日期格式,如%Y-%m-%d表示年-月-日。对于非常规的日期格式,我们可以自定义日期格式来解析和转换。
其中,年、月、日、时、分、秒分别用%Y、%m、%d、%H、%M、%S表示。
print(pd.to_datetime('202101', format='%Y%m')) # 直接解析将报错,因此需要指定日期的格式
print(pd.to_datetime(['20211', '20212', '202112'], format='%Y%m'))
2021-01-01 00:00:00
DatetimeIndex(['2021-01-01', '2021-02-01', '2021-12-01'], dtype='datetime64[ns]', freq=None)
偏移时间序列
一些情况下,存在多源时间序列不匹配的问题,可能需要对时间序列进行偏移。Pandas中提供了多种方法对时间序列进行偏移。
date_range = pd.date_range('2021-01-01', '2021-01-05', freq='D')
print(date_range)
print(date_range.shift(1)) # 根据当前步长单位进行偏移
print(date_range.shift(-3))
print(date_range.shift(2, freq='M')) # 根据指定步长单位进行偏移
print(date_range + pd.offsets.Week(3))
# 生成时间偏移量
dt = pd.to_timedelta(3, unit='D')
print(dt)
print(date_range + dt)
dt = pd.to_timedelta(['1 D', '2 H', '3 minutes', '4 seconds', '5 w'])
print(date_range + dt)
dt = pd.to_timedelta('5 days 7 hours 30 minutes 10 seconds')
print(date_range + dt)
DatetimeIndex(['2021-01-01', '2021-01-02', '2021-01-03', '2021-01-04',
'2021-01-05'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2021-01-02', '2021-01-03', '2021-01-04', '2021-01-05',
'2021-01-06'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2020-12-29', '2020-12-30', '2020-12-31', '2021-01-01',
'2021-01-02'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2021-02-28', '2021-02-28', '2021-02-28', '2021-02-28',
'2021-02-28'],
dtype='datetime64[ns]', freq=None)
DatetimeIndex(['2021-01-22', '2021-01-23', '2021-01-24', '2021-01-25',
'2021-01-26'],
dtype='datetime64[ns]', freq=None)
3 days 00:00:00
DatetimeIndex(['2021-01-04', '2021-01-05', '2021-01-06', '2021-01-07',
'2021-01-08'],
dtype='datetime64[ns]', freq='D')
DatetimeIndex(['2021-01-02 00:00:00', '2021-01-02 02:00:00',
'2021-01-03 00:03:00', '2021-01-04 00:00:04',
'2021-02-09 00:00:00'],
dtype='datetime64[ns]', freq=None)
DatetimeIndex(['2021-01-06 07:30:10', '2021-01-07 07:30:10',
'2021-01-08 07:30:10', '2021-01-09 07:30:10',
'2021-01-10 07:30:10'],
dtype='datetime64[ns]', freq='D')
时间序列数据处理
由于时间的周期性、月份长度不一致等的存在,时间序列数据相较简单的代数运算更为繁琐。下面我们通过一组伪气象数据来举例说明。
import numpy as np
# 生成一组日气温数据
df_tmp = pd.DataFrame(index=pd.date_range('2024-01-01', '2024-12-31', freq='D'))
df_tmp['Moscow'] = np.random.rand(len(df_tmp)) * 10 - 15
df_tmp['Istanbul'] = np.random.rand(len(df_tmp)) * 10 + 5
df_tmp['Delhi'] = np.random.rand(len(df_tmp)) * 10 + 25
df_tmp['Tokyo'] = np.random.rand(len(df_tmp)) * 10 + 15
df_tmp['Oslo'] = np.random.rand(len(df_tmp)) * 10 - 5
print(df_tmp)
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 -12.507333 8.843648 33.246008 22.083794 1.464828
2024-01-02 -5.420229 10.210387 26.832628 18.923657 -0.535928
2024-01-03 -5.777253 11.924500 32.288078 16.753620 -1.134632
2024-01-04 -10.513435 7.863196 29.965339 20.013110 -1.965073
2024-01-05 -14.257012 9.221470 25.657996 17.241110 -0.337181
... ... ... ... ... ...
2024-12-27 -12.507982 13.790553 30.266854 18.228648 3.433193
2024-12-28 -6.739498 10.727600 25.824327 21.259728 2.114948
2024-12-29 -9.713740 6.009821 28.296607 15.202731 -1.782476
2024-12-30 -12.356168 13.890982 27.810067 23.585278 2.910837
2024-12-31 -13.592953 9.560644 25.159271 22.388183 -3.792435
[366 rows x 5 columns]
# 常规的代数统计
print(df_tmp.mean())
print(df_tmp.min())
print(df_tmp.max())
Moscow -10.028244
Istanbul 9.980530
Delhi 29.889565
Tokyo 19.897225
Oslo -0.263960
dtype: float64
Moscow -14.968037
Istanbul 5.008738
Delhi 25.021508
Tokyo 15.016760
Oslo -4.997246
dtype: float64
Moscow -5.049498
Istanbul 14.995171
Delhi 34.974616
Tokyo 24.968358
Oslo 4.908233
dtype: float64
长期气候态是地球科学的重要内容,因此我们可以使用resample方法将日尺度数据采样为月度、年度、季度、周度等。
print(df_tmp.resample('M').mean()) # 月平均气温
print(df_tmp.resample('QS-DEC').mean()) # 季节平均气温
Moscow Istanbul Delhi Tokyo Oslo
2024-01-31 -10.254586 9.863383 29.811591 19.542478 0.118495
2024-02-29 -10.574170 8.663596 29.921715 20.434315 -0.765250
2024-03-31 -10.193746 10.903090 29.499974 20.089061 -0.521395
2024-04-30 -9.694386 10.436401 30.207367 19.352587 -0.458590
2024-05-31 -10.342069 9.759788 29.882693 19.872505 0.738848
2024-06-30 -10.516414 9.650099 30.606493 19.379372 -0.368868
2024-07-31 -9.736534 9.504273 29.598204 19.380998 0.145924
2024-08-31 -10.828593 9.994522 29.959532 20.387590 -0.642251
2024-09-30 -9.257497 10.375339 30.400341 19.200840 0.207057
2024-10-31 -9.458752 10.574113 29.696168 20.774836 -0.787231
2024-11-30 -9.482097 10.315962 30.240406 20.126591 -0.410509
2024-12-31 -9.997802 9.668432 28.913538 20.210843 -0.455287
Moscow Istanbul Delhi Tokyo Oslo
2023-12-01 -10.409052 9.283486 29.864818 19.973533 -0.308648
2024-03-01 -10.080890 10.365666 29.859606 19.775936 -0.076268
2024-06-01 -10.358819 9.717018 30.048746 19.719645 -0.287524
2024-09-01 -9.400100 10.423478 30.107732 20.042229 -0.335250
2024-12-01 -9.997802 9.668432 28.913538 20.210843 -0.455287
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 -12.507333 8.843648 33.246008 22.083794 1.464828
2024-01-02 -5.420229 10.210387 26.832628 18.923657 -0.535928
2024-01-03 -5.777253 11.924500 32.288078 16.753620 -1.134632
2024-01-04 -10.513435 7.863196 29.965339 20.013110 -1.965073
2024-01-05 -14.257012 9.221470 25.657996 17.241110 -0.337181
... ... ... ... ... ...
2024-12-27 -12.507982 13.790553 30.266854 18.228648 3.433193
2024-12-28 -6.739498 10.727600 25.824327 21.259728 2.114948
2024-12-29 -9.713740 6.009821 28.296607 15.202731 -1.782476
2024-12-30 -12.356168 13.890982 27.810067 23.585278 2.910837
2024-12-31 -13.592953 9.560644 25.159271 22.388183 -3.792435
[366 rows x 5 columns]
若该要素为降水,总降水量相对平均降水可能更有意义,此时采样函数可将mean更换为sum计算总降水量。
df_prc = df_tmp.copy() / 10
df_prc[df_prc < 0] = 0
print(df_prc)
print(df_prc.resample('Y').sum()) # 年降水量
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 0.0 0.884365 3.324601 2.208379 0.146483
2024-01-02 0.0 1.021039 2.683263 1.892366 0.000000
2024-01-03 0.0 1.192450 3.228808 1.675362 0.000000
2024-01-04 0.0 0.786320 2.996534 2.001311 0.000000
2024-01-05 0.0 0.922147 2.565800 1.724111 0.000000
... ... ... ... ... ...
2024-12-27 0.0 1.379055 3.026685 1.822865 0.343319
2024-12-28 0.0 1.072760 2.582433 2.125973 0.211495
2024-12-29 0.0 0.600982 2.829661 1.520273 0.000000
2024-12-30 0.0 1.389098 2.781007 2.358528 0.291084
2024-12-31 0.0 0.956064 2.515927 2.238818 0.000000
[366 rows x 5 columns]
Moscow Istanbul Delhi Tokyo Oslo
2024-12-31 0.0 365.287396 1093.958072 728.238447 41.132944
在我们常见的ERA5数据中,它提供的月降水数据通常为月内日均降水。针对每个月长度不一致和平闰年的问题,我们可以使用Pandas的时间序列简单解决。
df_prc_month_day = pd.DataFrame(index=pd.date_range('2024-01-01', periods=12, freq='M'))
df_prc_month_day['Delhi'] = np.random.rand(df_prc_month_day.shape[0]) * 15
df_prc_month_day['Mumbai'] = np.random.rand(df_prc_month_day.shape[0]) * 15
df_prc_month_day['Bangalore'] = np.random.rand(df_prc_month_day.shape[0]) * 15
print(df_prc_month_day)
Delhi Mumbai Bangalore
2024-01-31 3.940283 14.243030 14.550210
2024-02-29 10.600057 3.372597 11.475781
2024-03-31 10.650589 0.588919 9.247578
2024-04-30 0.923979 11.217988 8.438911
2024-05-31 1.447532 10.217217 13.743340
2024-06-30 12.765974 8.176907 3.823629
2024-07-31 6.710510 13.173852 2.471967
2024-08-31 11.528575 0.201862 3.447648
2024-09-30 9.430506 14.604422 12.244354
2024-10-31 7.503884 14.636888 10.372287
2024-11-30 9.426874 12.573375 3.150358
2024-12-31 7.260503 8.289384 1.363746
print(df_prc_month_day.mul(df_prc_month_day.index.days_in_month, axis=0))
Delhi Mumbai Bangalore
2024-01-31 122.148777 441.533943 451.056512
2024-02-29 307.401667 97.805311 332.797655
2024-03-31 330.168271 18.256477 286.674931
2024-04-30 27.719360 336.539649 253.167335
2024-05-31 44.873482 316.733731 426.043535
2024-06-30 382.979229 245.307224 114.708863
2024-07-31 208.025813 408.389426 76.630984
2024-08-31 357.385838 6.257732 106.877081
2024-09-30 282.915194 438.132673 367.330612
2024-10-31 232.620416 453.743526 321.540895
2024-11-30 282.806225 377.201245 94.510754
2024-12-31 225.075581 256.970890 42.276127
针对气象条件的不稳定,平滑去噪是我们常用到的方法,或者我们需要计算三日内降水等指标,均需要使用时间序列数据处理实现。下面我们使用Pandas中内置的经典方法——滑动窗口法rolling来实现滤波。
该函数常用参数包括:
-
window:滑动窗口大小,一般需要两端对称,因此多设置为奇数 -
min_periods:窗口内最小观测值个数,若窗口内数值个数小于该值将赋空值 -
center:是否将窗口中心点对齐到原始时间序列的中间,默认为False(居右)。 -
axis:指定滑动轴,默认为0
print(df_tmp.rolling(window=7).mean()) # 7天滑动平均气温
print(df_tmp.rolling(window=7, center=True).mean()) # 窗口中心居中
print(df_tmp.rolling(window=7, min_periods=1, center=True).mean()) # 最小窗口设为1
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 NaN NaN NaN NaN NaN
2024-01-02 NaN NaN NaN NaN NaN
2024-01-03 NaN NaN NaN NaN NaN
2024-01-04 NaN NaN NaN NaN NaN
2024-01-05 NaN NaN NaN NaN NaN
... ... ... ... ... ...
2024-12-27 -7.933149 9.308903 28.475941 21.106085 0.941338
2024-12-28 -7.550998 9.987686 27.761081 20.676448 1.004559
2024-12-29 -7.847822 9.231643 27.501335 19.853021 1.114749
2024-12-30 -8.812310 10.297097 27.865765 20.486932 1.071464
2024-12-31 -9.804272 10.878143 27.248562 21.308512 0.326890
[366 rows x 5 columns]
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 NaN NaN NaN NaN NaN
2024-01-02 NaN NaN NaN NaN NaN
2024-01-03 NaN NaN NaN NaN NaN
2024-01-04 -10.173355 10.262110 29.808843 19.473300 -0.561775
2024-01-05 -9.968426 10.657593 29.773274 19.517357 -1.058107
... ... ... ... ... ...
2024-12-27 -8.812310 10.297097 27.865765 20.486932 1.071464
2024-12-28 -9.804272 10.878143 27.248562 21.308512 0.326890
2024-12-29 NaN NaN NaN NaN NaN
2024-12-30 NaN NaN NaN NaN NaN
2024-12-31 NaN NaN NaN NaN NaN
[366 rows x 5 columns]
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 -8.554563 9.710433 30.583013 19.443545 -0.542701
2024-01-02 -9.695053 9.612640 29.598010 19.003058 -0.501597
2024-01-03 -10.340545 9.784317 29.339153 18.711367 -0.478302
2024-01-04 -10.173355 10.262110 29.808843 19.473300 -0.561775
2024-01-05 -9.968426 10.657593 29.773274 19.517357 -1.058107
... ... ... ... ... ...
2024-12-27 -8.812310 10.297097 27.865765 20.486932 1.071464
2024-12-28 -9.804272 10.878143 27.248562 21.308512 0.326890
2024-12-29 -10.303311 11.334780 27.572287 20.931878 0.193201
2024-12-30 -10.982069 10.795920 27.471426 20.132914 0.576813
2024-12-31 -10.600590 10.047262 26.772568 20.608980 -0.137281
[366 rows x 5 columns]
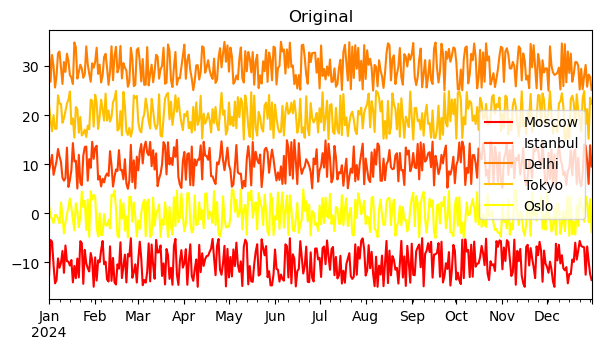
df_tmp.plot(figsize=(7, 3.5), title='Original', colormap='autumn')
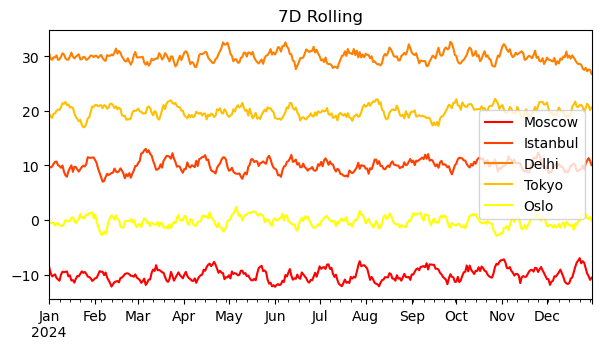
df_tmp.rolling(window=7, min_periods=1, center=True).mean().plot(figsize=(7, 3.5), title='7D Rolling', colormap='autumn')
# 根据日降水量计算72小时总降水量(三天求和)
print(df_prc.rolling(window=3, center=True, min_periods=1).sum())
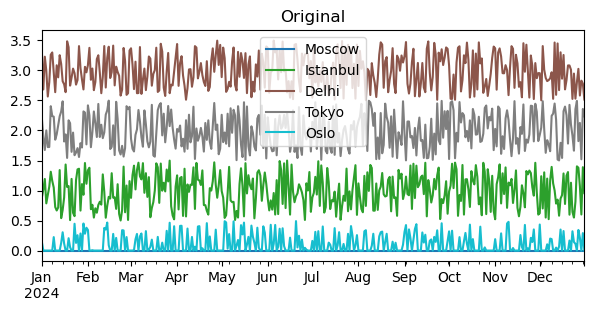
df_prc.plot(figsize=(7, 3), title='Original', colormap='tab10')
df_prc.rolling(window=3, center=True, min_periods=1).sum().plot(figsize=(7, 3), title='72 Hours Total Precipitation', colormap='tab10')
Moscow Istanbul Delhi Tokyo Oslo
2024-01-01 0.0 1.905404 6.007864 4.100745 0.146483
2024-01-02 0.0 3.097854 9.236671 5.776107 0.146483
2024-01-03 0.0 2.999808 8.908604 5.569039 0.000000
2024-01-04 0.0 2.900917 8.791141 5.400784 0.000000
2024-01-05 0.0 2.772737 8.366820 5.450713 0.000000
... ... ... ... ... ...
2024-12-27 0.0 3.854723 8.416778 6.441508 0.554814
2024-12-28 0.0 3.052797 8.438779 5.469111 0.554814
2024-12-29 0.0 3.062840 8.193100 6.004774 0.502579
2024-12-30 0.0 2.946145 8.126595 6.117619 0.291084
2024-12-31 0.0 2.345163 5.296934 4.597346 0.291084
[366 rows x 5 columns]
后记
以上就是关于Pandas处理时间序列数据的一些介绍,更多丰富、深入的用法也不过是在此基础上的拼装和拓展。我们只需要掌握好这些基础的组件,就可以通过不同的组装方式达到我们最终的目的。
但毫无疑问,这些内容还是过于浅显,更多内容还需要大家自行探索。另外,与date_range和to_datetime类似,还存在period_range和to_period函数。它们的用法几乎一致,但后者更强调时间段的概念。
但一般而言,如果我们认为连续两个时间戳之间的步长是固定的,那么时间段的概念也不再必要。因此,本文就不再赘述了(好长的一期,比我想象中的长了快一倍)。
这次我们还涉及到了与外部数据交互和可视化,这部分内容也会尽快提上议程。
那么,我们下期再见!
Manuscript: RitasCake
Proof: Philero; RitasCake
获取更多资讯,欢迎订阅微信公众号:Westerlies
跳转和鲸社区,云端运行本文案例。![]() https://www.heywhale.com/mw/project/66221ce2e584e69fbfef87ba/content
https://www.heywhale.com/mw/project/66221ce2e584e69fbfef87ba/content