Kafka简介
Kafka 是一个高吞吐量的分布式的基于发布/订阅模式的消息队列(Message Queue),主要应用与大数据实时处理领域。
1. 以时间复杂度为O(1)的方式提供消息持久化能力。
2. 高吞吐率。(Kafka 的吞吐量是MySQL 吞吐量的30-40倍,并且Kafka的扩展性远高于MySQL)
3. 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输,同时支持离线数据处理和实时数据处理。
Kafka架构演变
JMS架构
- JAVA中可以根据JMS(Java Message Service)实现在多个应用程序之间的消息传递,它类似于JDBC,提供一种和厂商无关的公共API,通过标准的生产、发送、接收消息的接口简化企业应用的开发。
- JMS消息有两种类型:
点对点(Point-to-Point):消息分发给一个单独的使用者。
发布/订阅(Publish/Subscribe):生产者发布事件,而使用者订阅感兴趣的事件,并使用事件。该类型消息一般与特定的主题**(Topic)**关联。
可以用下面的图表示一下JMS的两种消息模型
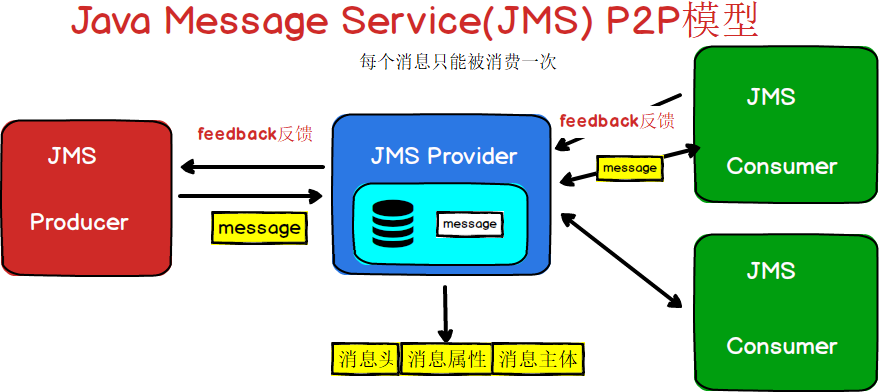
图1
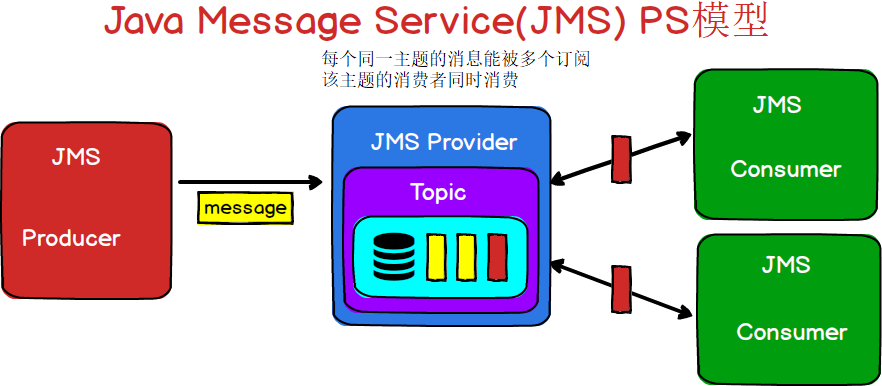
图2
Kafka架构
我们常听到的几个消息中间,例如:RabbitMQ、RocketMQ、ActiveMQ、Kafka。
那么为什么Kafka不叫KafkaMQ呢?
因为其他几个MQ基本上都遵循了JMS的协议,而Kafka虽然也借鉴了JMS的思想,但是呢,它又并没有完全的遵循JMS的设计。
下面我们根据我们对JMS的分析,来看下Kafka具备的特点:
- 在Kafka中,使用的是发布/订阅模式
- 在Kafka中,传递的消息被称为record对象
- 在Kafka中,通过启动一个独立的进程来提供消息的临时存储,由于这个进程只是用来进行消息的传递,并不会对数据进行修改,所以我们将这个进程可以看做是一个代理或者中介。也就是一个Broker
- 在Kafka中,也是通过主题(Topic)对消息进行分类。
- 在Kafka中,为了保证数据的安全性,将消息也会保存到磁盘文件中。基于早起的Kafka就是用来做日志传输的,所以Kafka用来持久化的文件都是以 .log结尾的。
- 在Kafka中,为了保证消息的有序性,在同一个主题下的消息都会分配一个类似于数组索引的标记,记作:偏移量(offset),它是从O开始的。
那么,通过上面的了解,我们可以得到一个简易版的Kafka结构
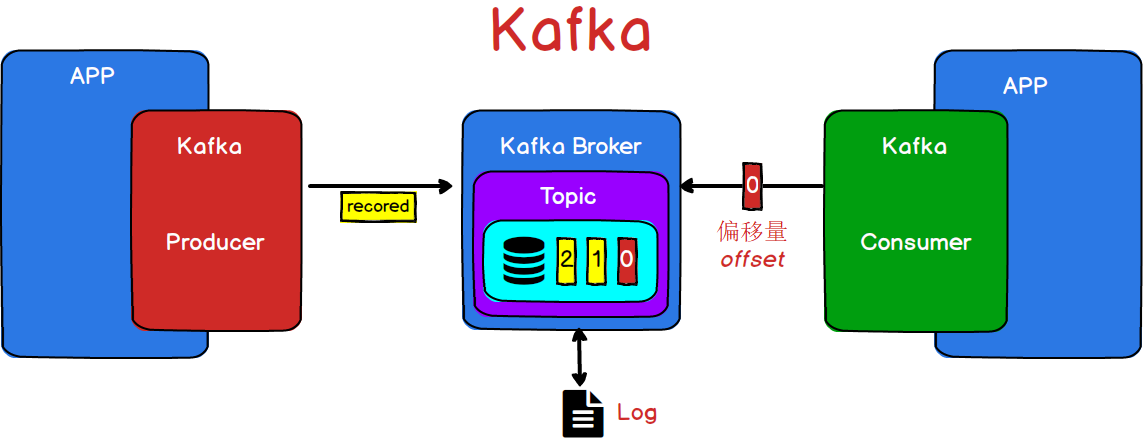
图3
看到图3这个图,是不是感觉对Kafka已经有了基本的了解,那么我们思考一个问题。
Kafka既然一直以单机10万级的高吞吐量而闻名,上面的这个架构明显无法满足其要求,那么它是如何实现的呢?
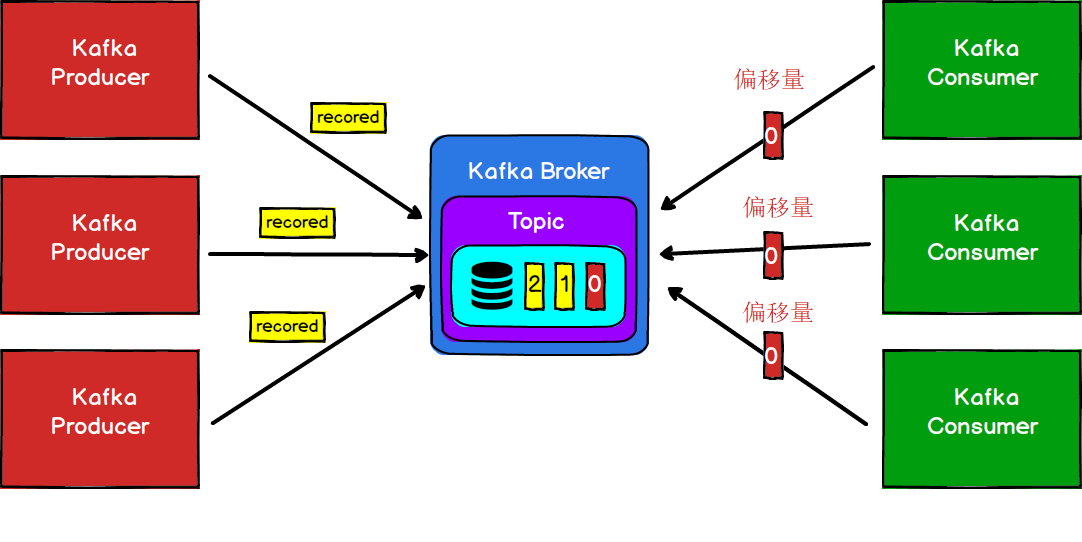
图4
一般情况下我们的生产者和消费者都会有多个,就像图4一样。但是这样的话,一旦大量的请求同事访问同一个Broker势必会造成IO热点问题,从而造成单一的Broker成为其性能瓶颈。甚至当Broker节点宕机以后,造成数据的丢失。
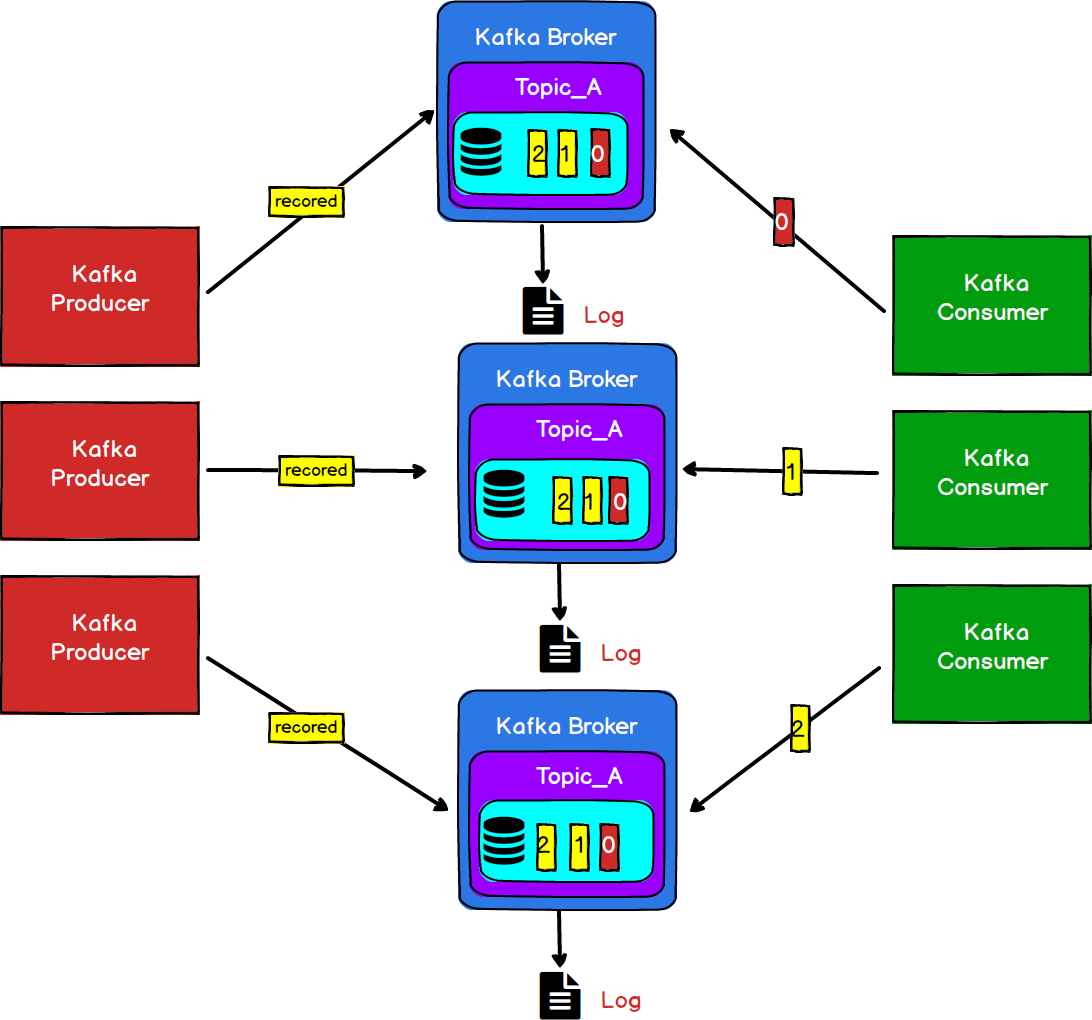
图5
我们通常会采用横向扩展(增加服务节点,搭建服务器集群)的方式来降低单点服务器故障带来的风险。如图5所示。
这样的设计确实可以缓解一部分服务器的压力,但是我们知道,在Kafka中是根据Topic来区分消息的,如果我们的多个生产者和消费者都需要订阅同一个Topic,那么我们全部的请求是不是还是都请求到一个同一个Broker上了,这样还是会造同样的性能瓶颈。
我们看下Kafka是怎么做的。(重点)
Kafka中,会把一个大的Topic分配到不同的Broker上,也就是说在不同的Broker中保存的是同一个Topic中的数据,Kafka把不同Broker中存放同一个Topic的数据的区域叫做Partition,也叫做分区,本质是一个有序的队列。同时为了区分同一个Topi下不同Broker中的Partition,会给每一个Partition进行编号。
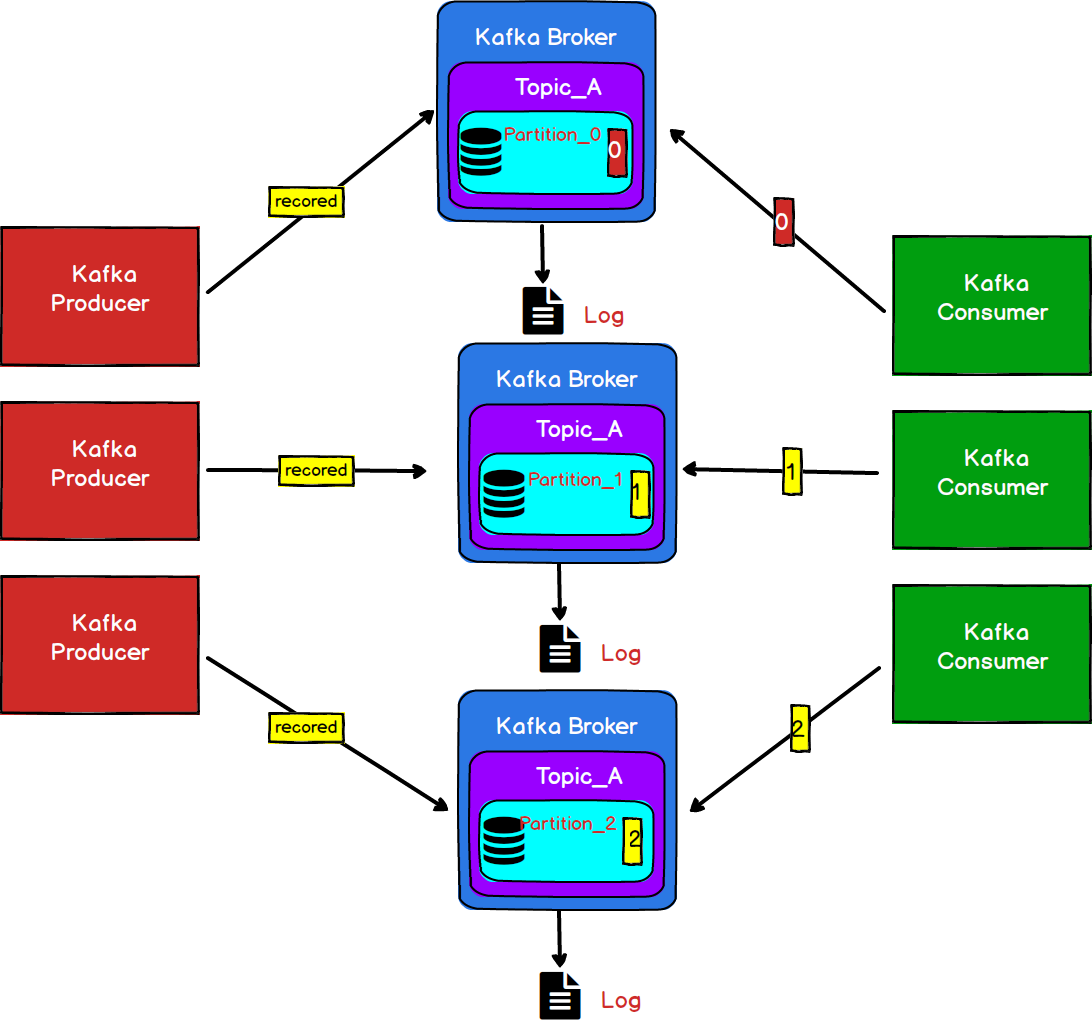
图6
这样,我们的生产者就可以将消息发送到不同的分区,同理,消费者也可以从不同的分区上对消息进行消费,是不是就能够极大地降低了单个节点的IO次数。
上面的结构虽然能够降低我们单个Broker的压力,但是,每个消费者只是消费了固定分区的数据,也就是说消费者虽然订阅了同一个主题,但是并没有去消费一个完整的Topic的数据,这样肯定不行的,我们必须要保证每一个消费者都能消费到完整的topic的消息。
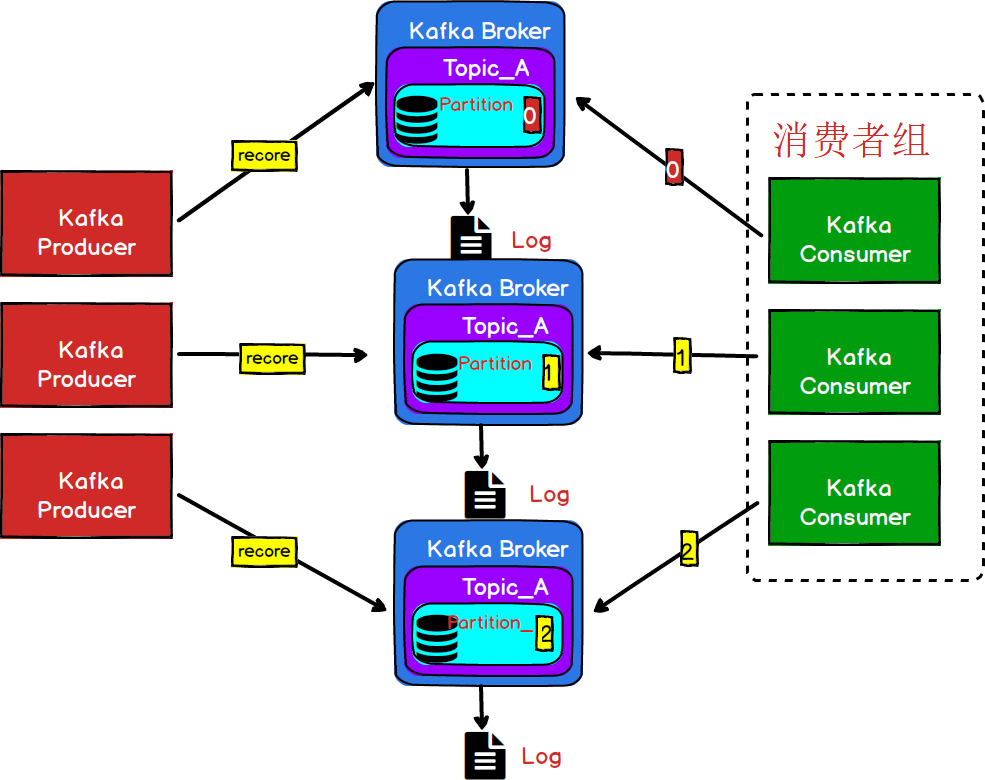
图7
为了解决消费者能够完整的消费同一个Topic下不同分区的数据,Kafka引入了消费者组(Consumer Grop)的概念。保证多个分区的消息能够被同一个消费者组消费。
- 消费者组,由多个consumer组成。形成一个消费者组的条件,是所有消费者的groupid相同。
- 消费者组内每个消费者负责消费不同分区的数据,一个分区只能由一个组内消费者消费。
- **消费者组之间互不影响。**所有的消费者都属于某个消费者组,即消费者组是逻辑上的一个订阅者。
我们了解了Kafka在生产者和消费者之间的关系,那么作为一个消息中间件,保证消息的可靠性和完整无疑是非常重要的。目前的架构中,虽然每一个Broker节点都会有一个.log的文件用于数据的持久化,但是如果其中一个Broker节点宕机,那么这个节点下的.log文件肯定也就无法被加载了。所以,仅仅将消息持久化到磁盘文件中,还是无法保证数据的完整性。
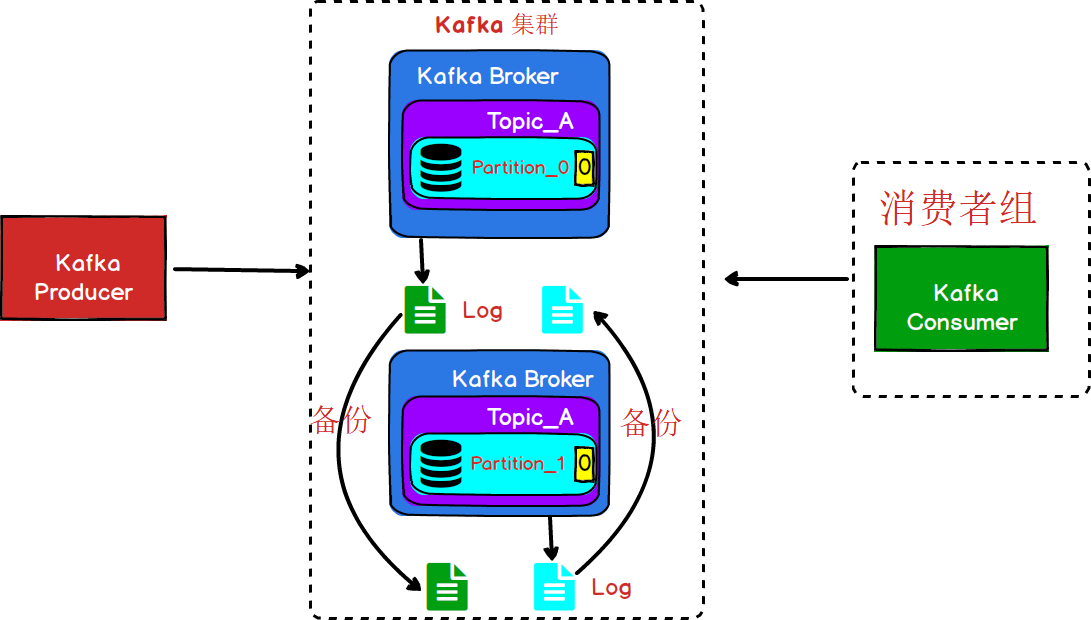
图8
从图8中我们可以看到,Kafka中其实是采用的备份的机制,但是并不是在同一个Broker进行备份,这种方式下的备份,及时某一个Broker宕机了,其他的Broker节点还是会有完整的数据。(这种备份机制一般都会满足一个条件,备份数量<=集群中Broker数量-1,就像图8的情况,集群中有2个节点,如果每个节点的备份数量>1是没有意义的。因为任何一个节点的宕机,无论备份多少份数据都是无法被读取的。)
- 为了数据的可靠性,可以将数据文件进行备份,但是Kafka中没有备份的概念,Kafka中称之为副本。
- 多个副本中,同时只能有一个提供数据的读写操作。其他文件只是用来作备份。
- 具有读写能力的副本被称作Leader,作为备份的的副本称之为Follower副本。
Kafka基础组件
下面总结了Kafka一些重要组件概念,帮组大家对Kafka有个整体的认识和感知。
-
**Producer:**即消息生产者,向Kafka Broker 发消息的客户端。
-
**Consumer:**即消息消费者,从 Kafka Broker 读消息的客户端。
-
**Broker:**一台 Kafka 机器就是一个 Broker。一个集群是由多个 Broker 组成的且一个 Broker 可以容纳多个 Topic。
-
**Topic:**可以简单理解为队列,Topic 将消息分类,生产者和消费者面向的都是同一个 Topic。
-
**Partition:**为了实现Topic扩展性,提高并发能力,一个非常大的 Topic 可以分布到多个 Broker 上,一个 Topic 可以分为多个 Partition 进行存储,每个 Partition 是一个有序的队列。
-
**Consumer Group:**即消费者组,消费者组内每个消费者负责消费不同分区的数据,以提高消费能力。一个分区只能由组内一个消费者消费,不同消费者组之间互不影响。
-
**Replica:**即副本,为实现数据备份的功能,保证集群中的某个节点发生故障时,该节点上的 Partition 数据不丢失,且 Kafka 仍然能够继续工作,为此Kafka提供了副本机制,一个 Topic 的每个 Partition 都有若干个副本,一个 Leader 副本和若干个 Follower 副本。
-
**Leader:**即每个分区多个副本的主副本,生产者发送数据的对象,以及消费者消费数据的对象,都是 Leader。
-
**Follower:**即每个分区多个副本的从副本,会实时从 Leader 副本中同步数据,并保持和 Leader 数据的同步。Leader 发生故障时,某个 Follower 还会被选举并成为新的 Leader , 且不能跟 Leader 在同一个broker上, 防止崩溃数据可恢复。
-
**Offset:**消费者消费的位置信息,监控数据消费到什么位置,当消费者挂掉再重新恢复的时候,可以从消费位置继续消费。
点击下方名片,关注『编程青衫客』
随时随地获取最新好文章!