上一篇文章是关于大语言模型的调参数,写了temperature这个参数近期的一个工作。那接下来,就不得不再来讲讲top-p这个参数啦。首先还是上文章,同样是非常新的一个工作,2024年7月1日submit的呢。
文章链接:https://arxiv.org/abs/2407.01082
GitHub链接:GitHub - menhguin/minp_paper: Code Implementation, Evaluations, Documentation, Links and Resources for Min P paper
简而言之,这篇文章的作者们提出了一种min P的采样方式,来让大语言模型生成的输出更加能够保证文本的连贯性和质量,且一定程度上能生产出更有创造性和多样化的文本内容。首先,咱们看看top p采样是干啥的,一句话就是The cumulative probability cutoff for token selection。我们需要从模型的概率分布中选择一组 token,使得这些 token 的累计概率达到或超过 p。例如,设定 p=0.9,那么就对那些累计概率总和达到 90% 的 token 进行采样。具体步骤的话:
- 排序:将所有 token 按照其概率从大到小排序。
- 累积概率:计算这些 token 的累积概率。
- 选择子集:选择累积概率达到 p 的最小子集。
- 重新归一化:对选择的子集进行归一化,使得它们的概率总和为 1。
- 采样:从归一化后的子集中随机采样一个 token。
但是呢,这种采样方式会有一些缺点:采样概率p如果设置太低,模型的输出就会太固定,因为横竖就只有那几个单词。设置太高,模型输出太过混乱,会把一些无关词采样进来。
然后,我们看看作者给出的min-p采样效果的示意图:
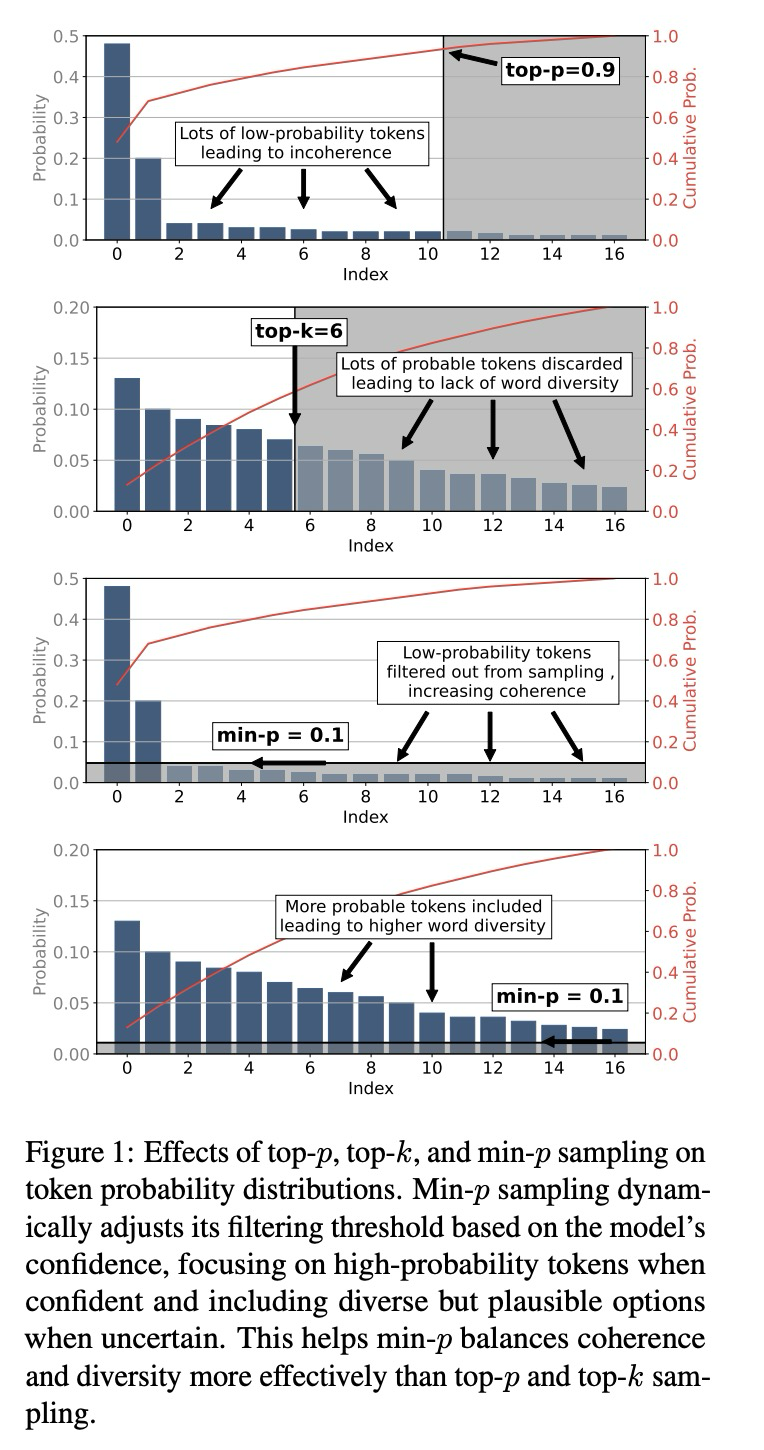
可以看到,min p达到的效果是这样的:
第一张图和第三张图,只有前几个token概率极高,后面的token概率都是一样的小的时候,min p采样集中只关注高概率的那些token。
第二张图和第四张图,当各个token的概率大家看起来都差不多的时候,则尽可能多的进行采样以保证有一定的多样性。
接着,咱们看看min p是咋做的:

首先,采样的对象是在概率大于等于Pscaled上的数据进行的,Pscaled的计算方式则是利用相对概率值Pbase乘以最大概率值Pmax,所有满足的token采样后概率进行归一化,再随机采样。文章给出了两个利用min-p采样后的示例:
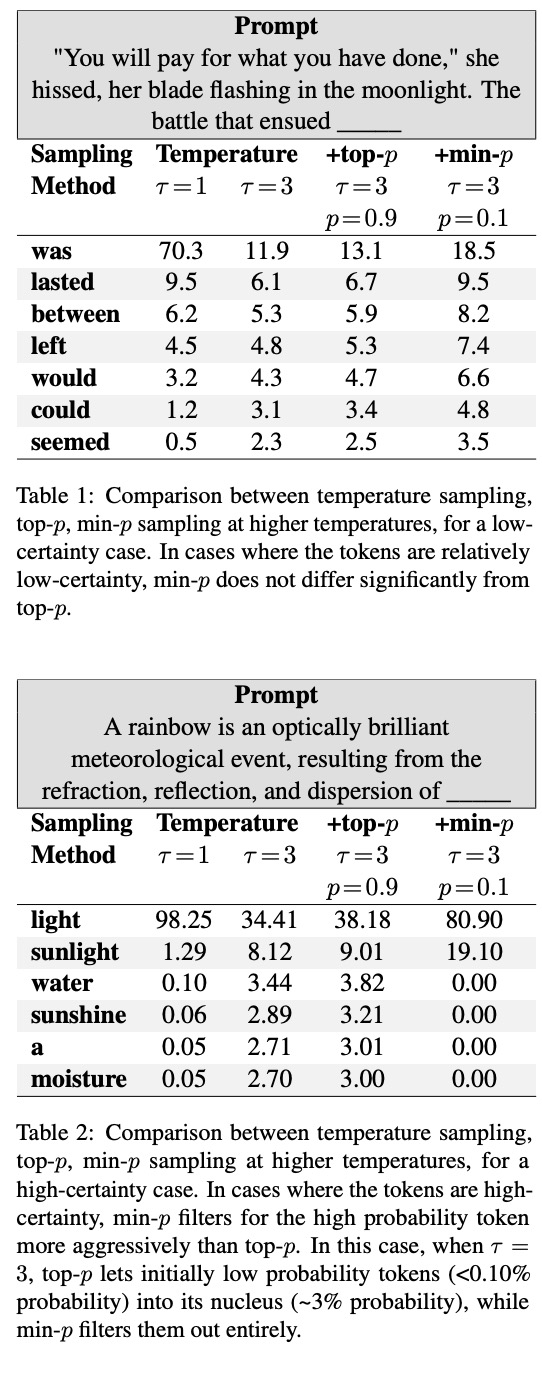
确实一定程度上达到了作者描述的那个效果呢。另外,作者还做了具体的文本生成任务实验,分别是Graduate-level reasoning、Grade School math和Creative Writing。效果当然也是呱呱叫啦,具体大家可以去看一下文章,不过最后作者指出了工作的缺点,首先文章只用了Mistral 7B模型,并没有尝试其他的模型,所以结论的鲁棒性还是持疑一下。另外,再Creative Writing这个任务上,从如何衡量创新性的角度上来看,测评不够严谨。
anyway,可能还是希望大语言模型保守点好。






![XSS: 原理 反射型实例[入门]](https://i-blog.csdnimg.cn/direct/b933cbc12930451c8234daf4a12f597d.png)



![[web]-图片上传、文件包含-图片上传](https://i-blog.csdnimg.cn/direct/773b3cb05faa455fbf47033a1b24b790.png)






