目录
作业要求:
一、数据预处理(包括数据扩展、数据过滤、数据加载等)
1.数据查看
2.上传数据
3.查看数据读取情况
4.时间维度的切割
二、单维度数据描述分析
2.1 条数统计
(1)查询数据的总条数
(2)非空查询条数
(3)查询无重复总条数
(4)查询UID唯一的条数
2.2 时间分析(包括每个时间段查询的条数等)
(1) sql查询每个时间段查询条数
(2) 存储到Mysql中
(3) python连接mysql进行可视化分析
2.3 关键词分析
(1) 查询关键词的平均长度
(2) 查询关键词各长度的条数
(3) 查询频度最高的前1000词排行榜
2.4 UID分析
(1) UID平均查询次数
(2) 查询1次、2次、3次大于3次的UID的个数
(3) 用户搜索次数排行榜
2.5 URL分析
(1) URL点击排行榜
(2) 直接输入URL作为查询词的条数
(3) 直接输入URL的查询中,点击的结果就是用户输入的URL的网址的条数
(4) 使用搜狗访问其他搜索引擎的次数
2.6 RANK分析
(1) 包括Rank在10以内的条数
3、多维度用户行为分析
3.1 查询次数最多的用户的用户行为分析
(1) 查询最多的用户是谁
(2) 他所查询的关键词及其频次
(3) 这一天的各时间段内的查询次数等
3.2 所有Url为百度的网站搜索的关键词分析
(1) 查看用户点击http://www.baidu.com/所用的搜索关键词及其计数统计
(2)查询点击http://www.baidu.com/各个时间段的条数统计等
3.3查询关键词“仙剑奇侠传”的用户行为分析
(1) 查询搜索过“仙剑奇侠传”的uid排行榜
(2) 查看榜首的UID的相关搜索记录
(3)查看榜尾的UID的相关搜索记录
3.4 较活跃的时间段的行为分析
(1) 最活跃时间段
(2) 在活跃时间段内点击网址排行榜
(3) 在活跃时间段内搜索关键词排行榜
(4) 在活跃时间段内用户排行榜
3.5 RANK与Order的相关性分析
(1) 被用户第一次点击的总条数
(2) Rank 前10的被第一次点击的条数
(3) Rank 前5的被第一次点击的条数
(4) Rank前3的被第一次点击的条数
(5) Rank前1的被第一次点击的条数
(6) 所有Rank为1的条数
(7) Rank为1的条目在1次内被点击的条数
(8) Rank为1的条目在3次内被点击的条数
(9) Rank为1的条目在5次内被点击的条数
(10) Rank为1的条目在10次内被点击的条数
(11) 总结
4、算法应用(应用sparkML二选其一)
4.1 对搜狗用户数据日志中的 URL 返回排名和用户点击顺序应用sparkML中的kmeans算法聚类,并对算法进行评估比较,给出合理化解释。
4.2 使用朴素贝叶斯算法(或其他算法)对用户查询主题进行分类分析和使用 K-Means 算法对用户查询主题进行聚类分析,发现用户的行为特征,并对算法进行评估比较,并给出合理化解释。
5、 整体总结
5.1 单维度数据描述分析
5.2 多维度用户行为分析
5.3 算法
作业要求:
数据集来自于搜狗实验室的用户搜索日志,该用户搜索日志是包括了大约为一个月(2008年6月)的搜索引擎部分网页的用户点击情况和搜索需求情况的网页搜索日志的数据集合,适合需要分析搜索引擎用户行为的研究实验。该用户搜索日志的数据格式为访问时间、用户ID、该URL在返回结果中的排名、用户点击的顺序号、用户点击的URL。其中,用户ID是根据用户使用浏览器访问搜索引擎时的Cookie自动赋值的,这标识同一用户输入的不同查询可以被识别出来。(本次选用精简版(一天数据,63MB))
表1 搜索日志中的字段信息
| 名称 |
内容 |
| ts |
用户点击发生时的日期时间 |
| Uid |
由系统自动分配的用户识别号 |
| Keywords | 查询关键词 |
| rank |
该URL在返回结果中的排名 |
| order |
用户点击的顺序号 |
| url |
用户点击的URL |
数据样本格式的截图如图所示。

以搜狗实验室用户搜索日志作为数据集,借助Scala语言在Spark环境下对用户访问搜狗搜索引擎时产生的数据进行分析,将结果选用适当可视化技术展示,并给出结果的合理化解释。
一、数据预处理(包括数据扩展、数据过滤、数据加载等)
1.数据查看
将数据集文件解压到指定目录E:\IdeaProjects\TestDemo1\data\input当中
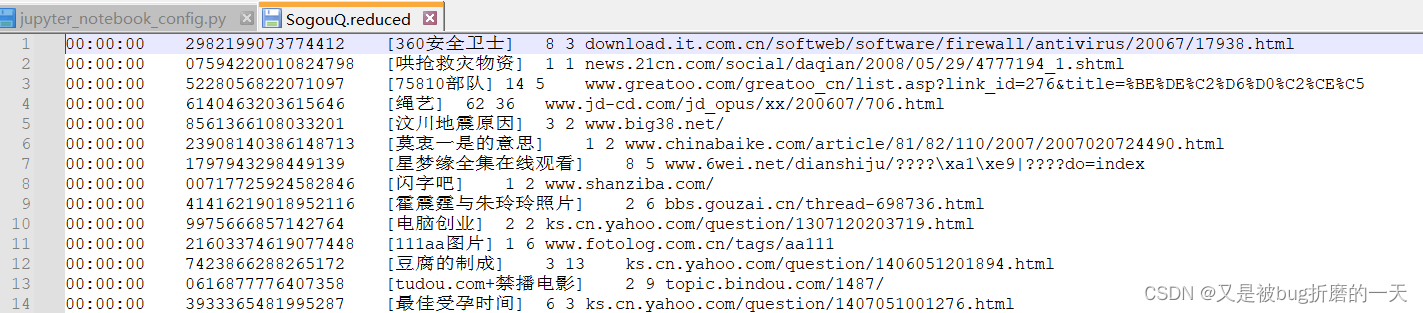
查看数据情况:
字段解释:
访问时间 用户id 查询词 该url在返回结果中的排名 用户点击的顺序号 用户点击的url
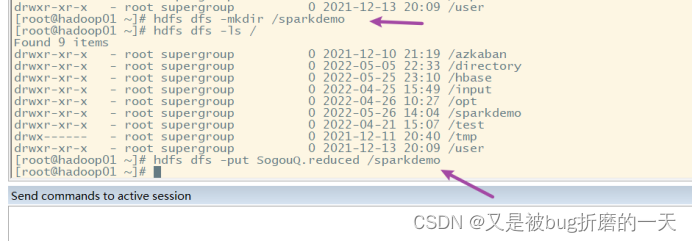
2.上传数据
有集群的可以往这个集群上传文件,就像下图这样,我只是为了快速完成作业,没有搭建集群,直接读取的本地的Sogou.reduced文件(毕竟这个数据也很小,才63MB,没必要用集群)
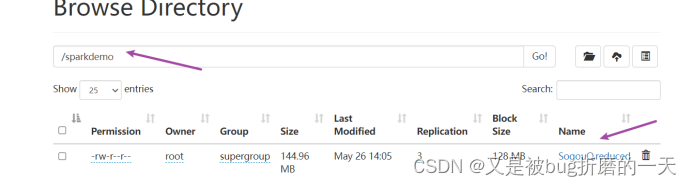
3.查看数据读取情况
新建scala文件ques1.scala
package sparkhomework
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapred.TextInputFormat
import org.apache.spark.{SparkConf, SparkContext}
object ques1 {
def main(args: Array[String]): Unit = {
// 1创建sparkConf 设置AppName 以及 master
val conf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("ques1")
// 2 创建sparkContext 提交Spark App的入口
val sc: SparkContext = new SparkContext(conf)
//设置日志级别
sc.setLogLevel("WARN")
// 3 业务操作-读取数据
val dataRDD = sc.hadoopFile(
"file:///E:/IdeaProjects/TestDemo1/data/input/SogouQ.reduced",
classOf[TextInputFormat],
classOf[LongWritable],
classOf[Text])
.map(pair => new String(pair._2.getBytes,
0, pair._2.getLength, "GBK"))
dataRDD
// 4.查看数据读取情况
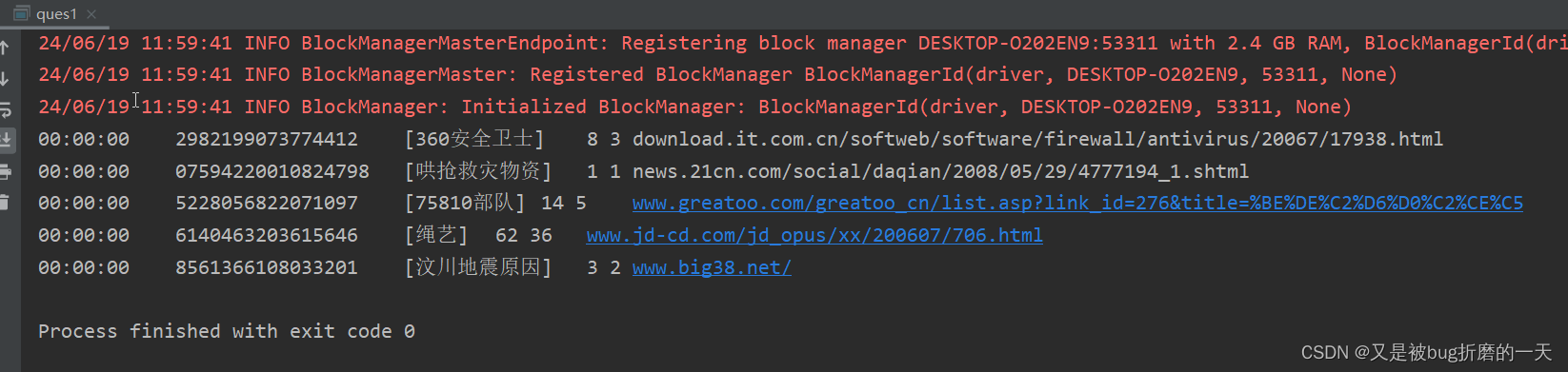
val res = dataRDD.take(5)
res.foreach(println)
// 5.关闭sc
sc.stop()
}
}
运行结果:
4.时间维度的切割
新建ques2.scala文件,以后的代码都是基于这个代码的基础上一点点添加上的
package sparkhomework
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.SparkSession
object ques2 {
def main(args: Array[String]): Unit = {
// 1 使用SparkSession.builder创建SparkSession,设置AppName以及master
val spark: SparkSession = SparkSession.builder()
.master("local[3]") // 设置master URL,例如本地模式使用3个线程
.appName("ques2") // 设置应用名称
.getOrCreate() // 如果已存在SparkSession,则返回它,否则创建一个新的
// 设置日志级别
spark.sparkContext.setLogLevel("WARN")
// 3 业务操作-读取数据
// 提前把SogouQ.reduced文件的编码从GBK转换成UTF-8,我用的工具是notepad++
val data = spark.read.textFile("file:///E:/IdeaProjects/TestDemo1/data/input/SogouQ.reduced")
// 转换成rdd
val dataRDD = data.rdd
val sgrdd = dataRDD
.map(x => x.split("\\s+"))
.filter(_.length == 6)
.map(x => (x(0), x(1), x(2), x(3).toInt, x(4).toInt, x(5)))
val sgrdd1: RDD[(String, String, String, String, String, Int, Int, String)] = sgrdd.map(
line => {
val sgtime: Array[String] = line._1.split(":")
val sghour: String = sgtime(0) //切分成时、分、秒
val sgmin: String = sgtime(1)
val sgsec: String = sgtime(2)
// 数据预处理,进行分词,去除 "[360安全卫士]" 词语两边的方括号
val querywords = line._3.replaceAll("\\[","")
.replace("]","")
(line._2, sghour, sgmin, sgsec, querywords, line._4, line._5, line._6)
}
)
import spark.implicits._// 导入隐式转换,用于将RDD转换为DataFrame
// 转成dataframe
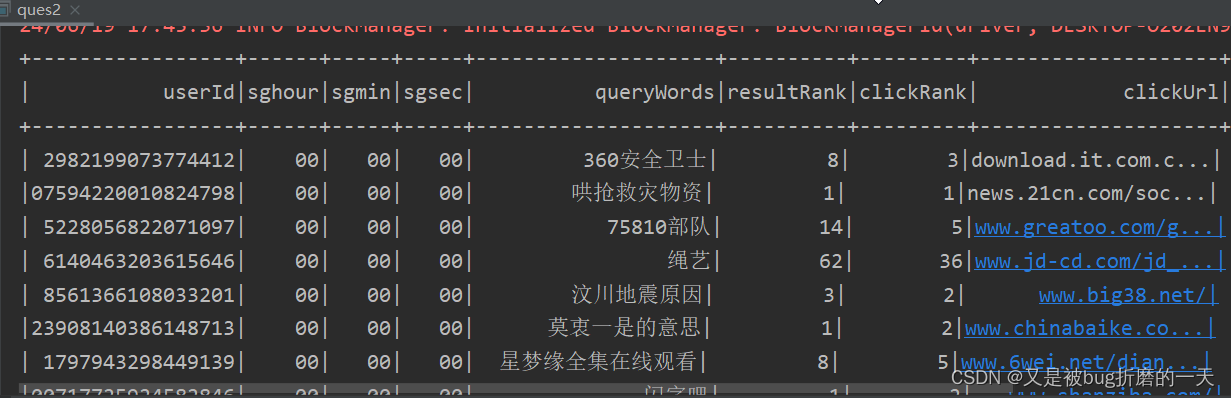
val sgdata1 = sgrdd1.toDF("userId","sghour", "sgmin", "sgsec", "queryWords", "resultRank", "clickRank", "clickUrl")
//输出查看
sgdata1.show()
//关闭sc
spark.stop()
}
}运行结果:
二、单维度数据描述分析
2.1 条数统计
(1)查询数据的总条数

可以看出数据总条数有1724253条。
(2)非空查询条数
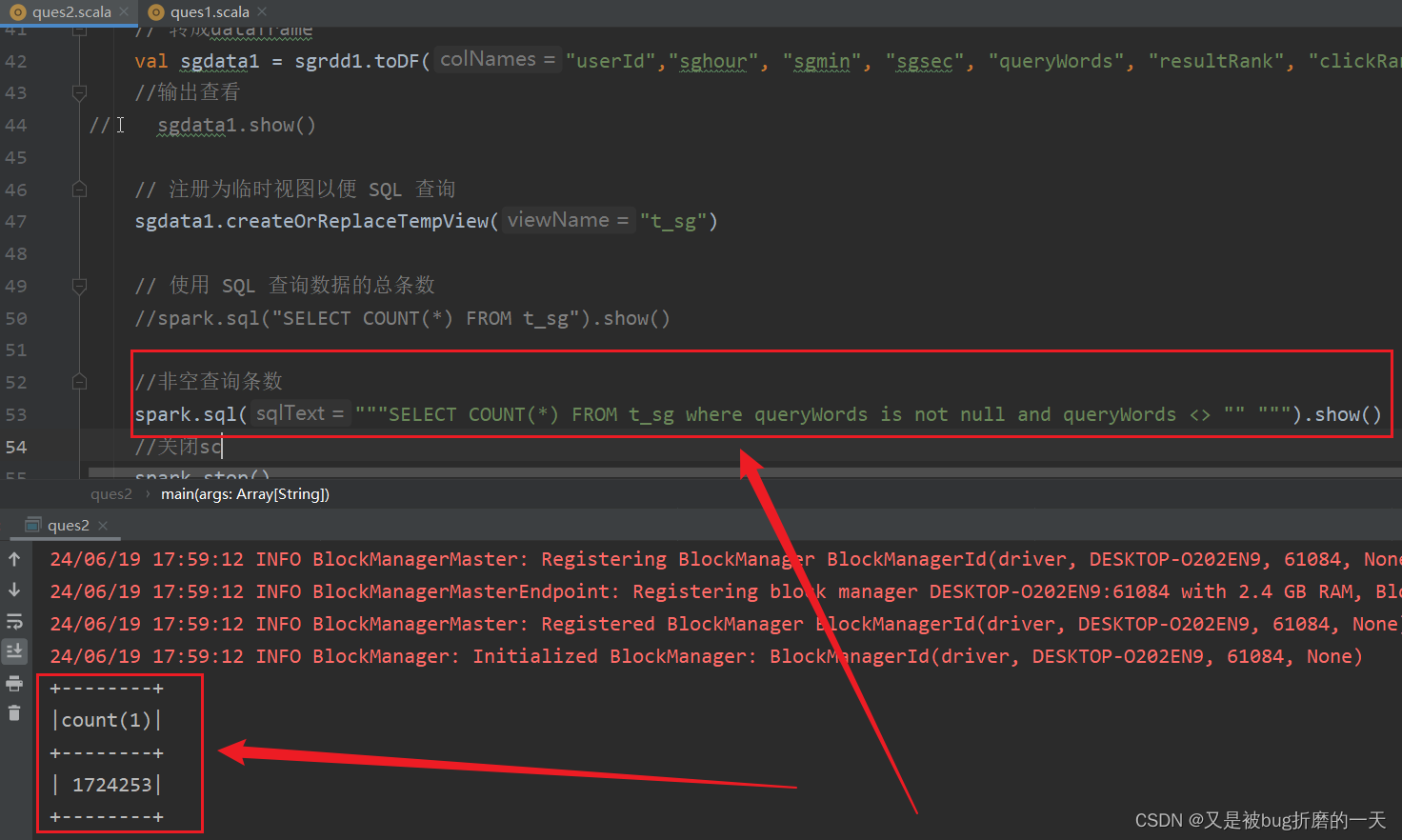
非空查询条数有1724253,跟总条数的数量一样,说明没有空查询。
(3)查询无重复总条数
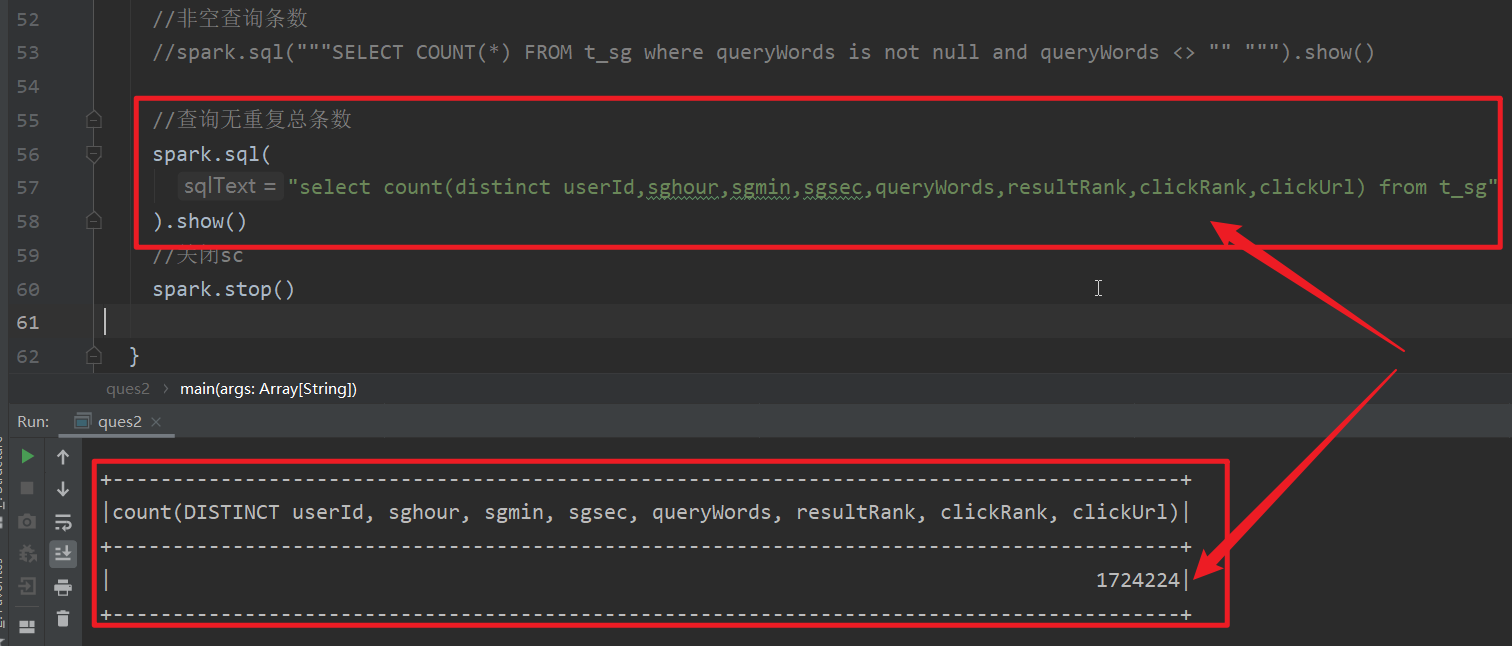
无重复条数有1724224条,也就是说,重复的条数有1724253-1724224=29条。
(4)查询UID唯一的条数
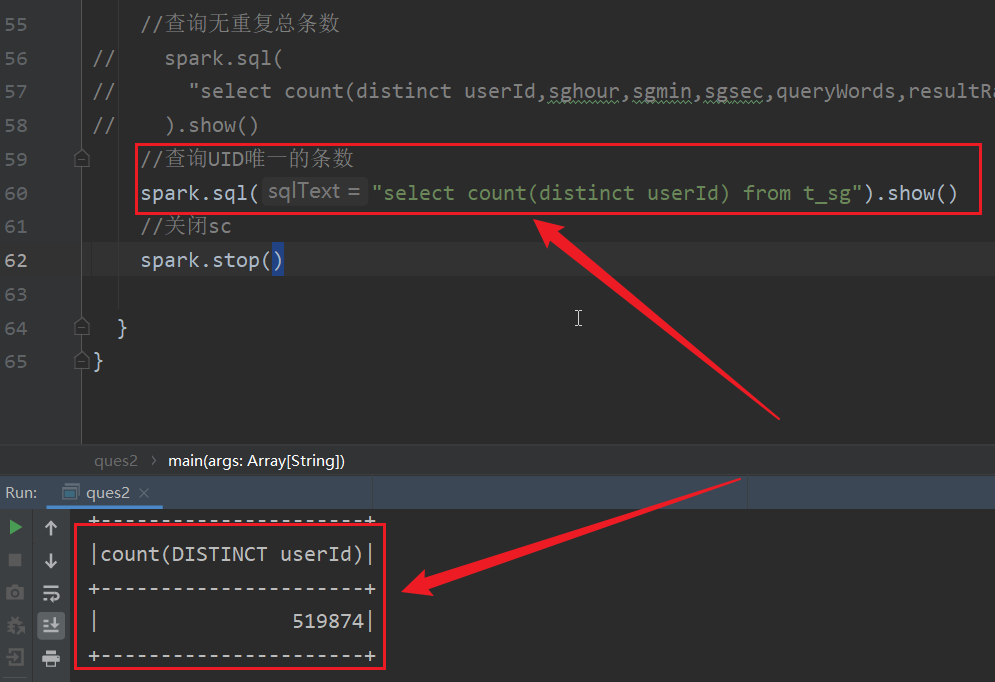
查询到的用户id唯一的条数有519874,即这一天内,共有519874个用户使用搜狗搜索引擎。
2.2 时间分析(包括每个时间段查询的条数等)
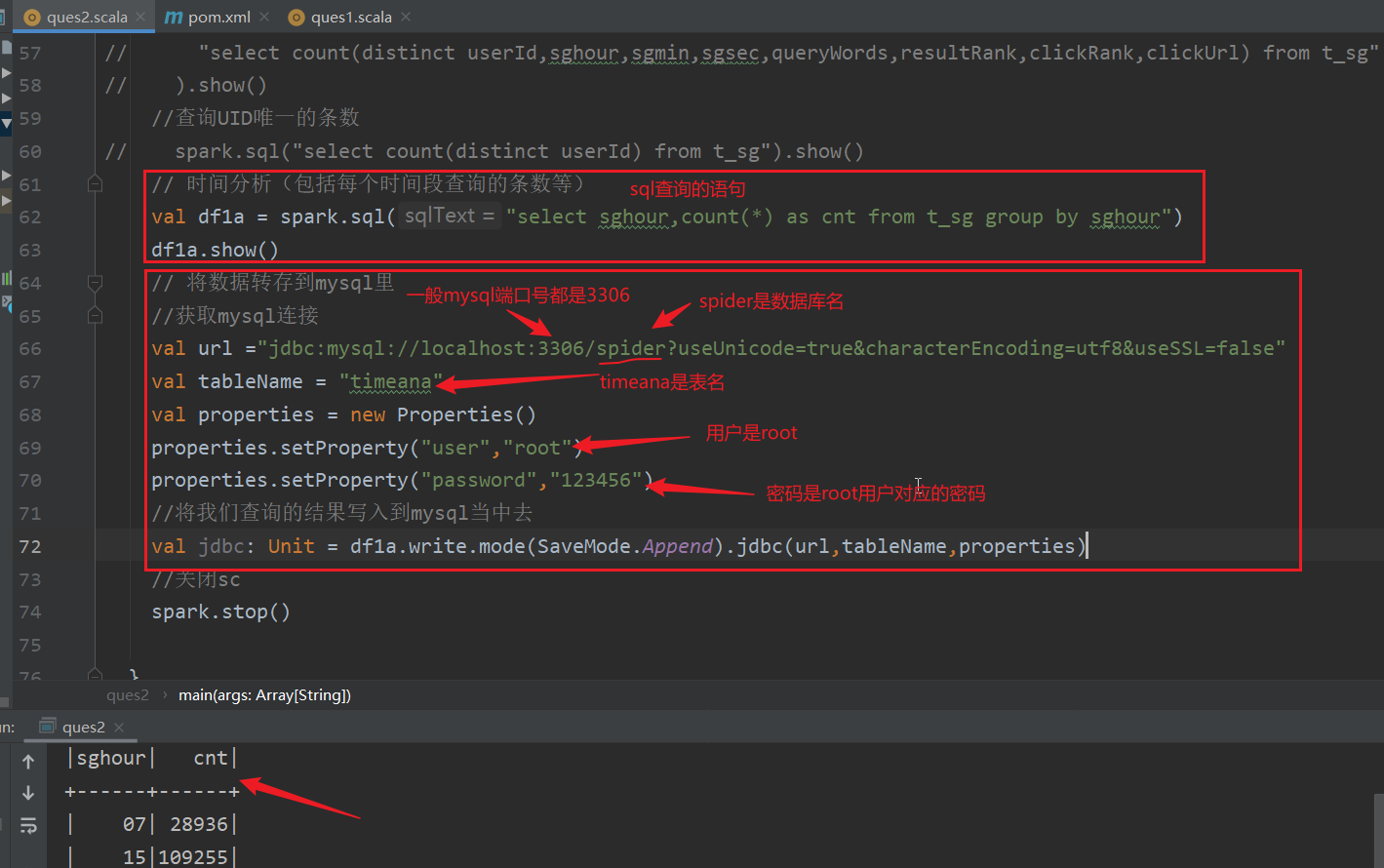
(1) sql查询每个时间段查询条数
前边已经将时间维度切分成时分秒这样的

现在就是根据sghour分组统计每小时的查询的条数有多少
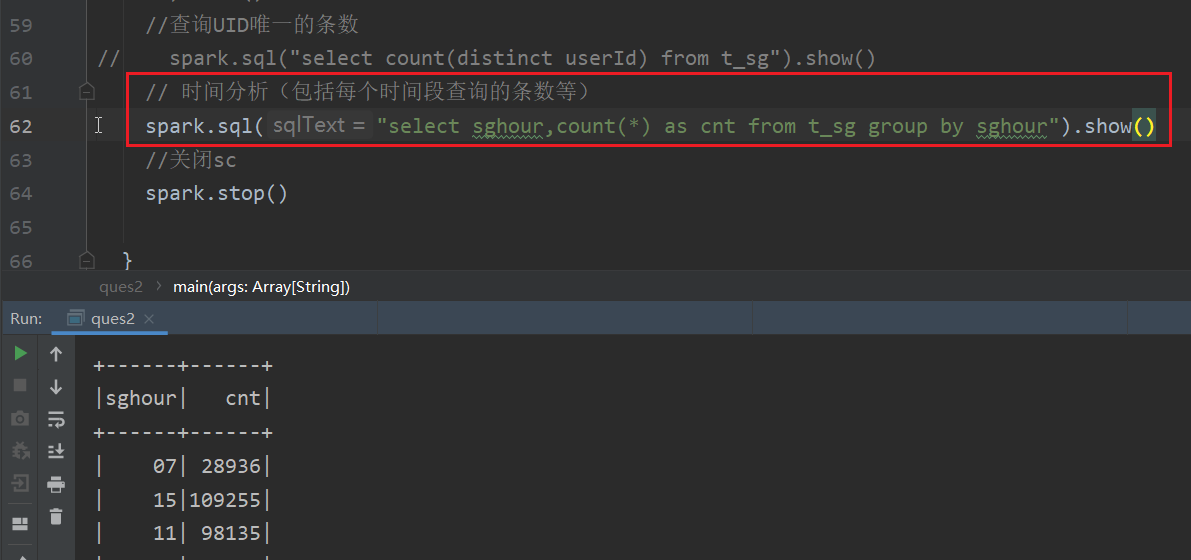
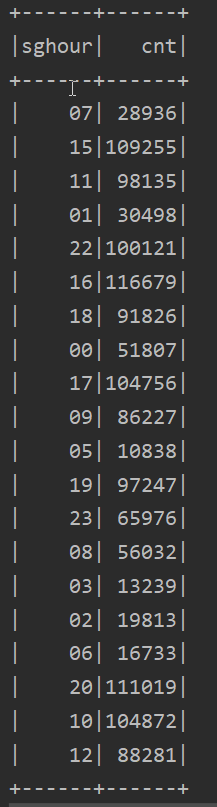
查询结果如下:
(2) 存储到Mysql中
将上边的运行结果转存到mysql中,(需要提前建库建表!)
建表:
use spider;
CREATE TABLE timeana (
sghour INT,
cnt INT
);
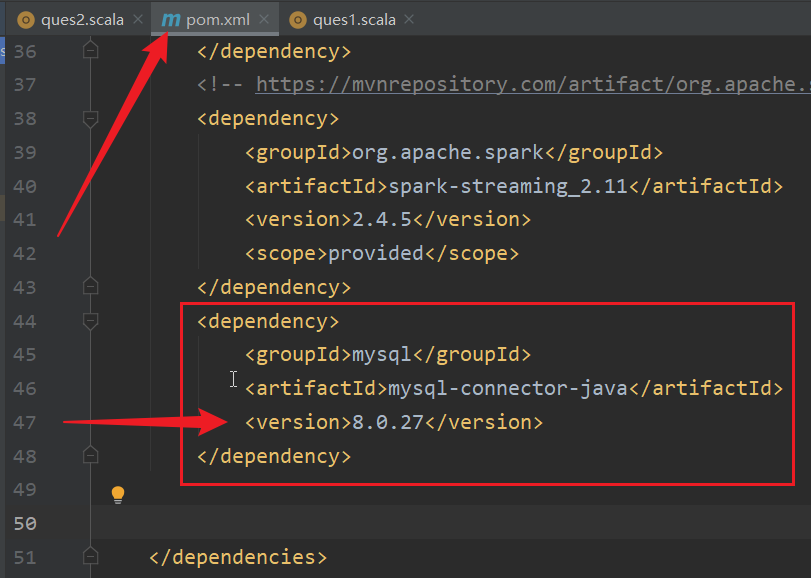
我的 MySQL 服务器版本是 8.0的版本,那么可以使用 8.0.27的驱动
pom文件中添加如下红框的内容,再右键选择maven,选择reimport就可以导入mysql的jdbc驱动了
navicat查看表中的数据

(3) python连接mysql进行可视化分析
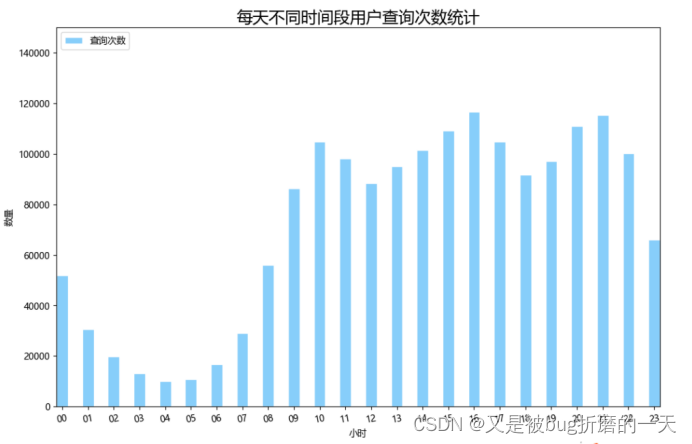
从上图中可以看出,一天当中最活跃的时间段是16时,一小时内查询次数达到120000左右,最不活跃的时间段是凌晨04时,查询次数只有不到10000,总体来看,用户在9点到22点最为活跃。可以推测,一般人们在工作学习时间出于工作或学习的目的会较多的使用搜狗搜索引擎搜索,而在21点之后人们逐渐进入休息时间,搜索次数会逐渐减少。
9点到22点中查询次数出现了两次低谷,分别是12点-13点和18点-19点,可以推测这个时间段是人们吃午饭和吃晚饭休息的时间段所以查询次数会出现低谷的现象。

![XSS: 原理 反射型实例[入门]](https://i-blog.csdnimg.cn/direct/b933cbc12930451c8234daf4a12f597d.png)



![[web]-图片上传、文件包含-图片上传](https://i-blog.csdnimg.cn/direct/773b3cb05faa455fbf47033a1b24b790.png)












