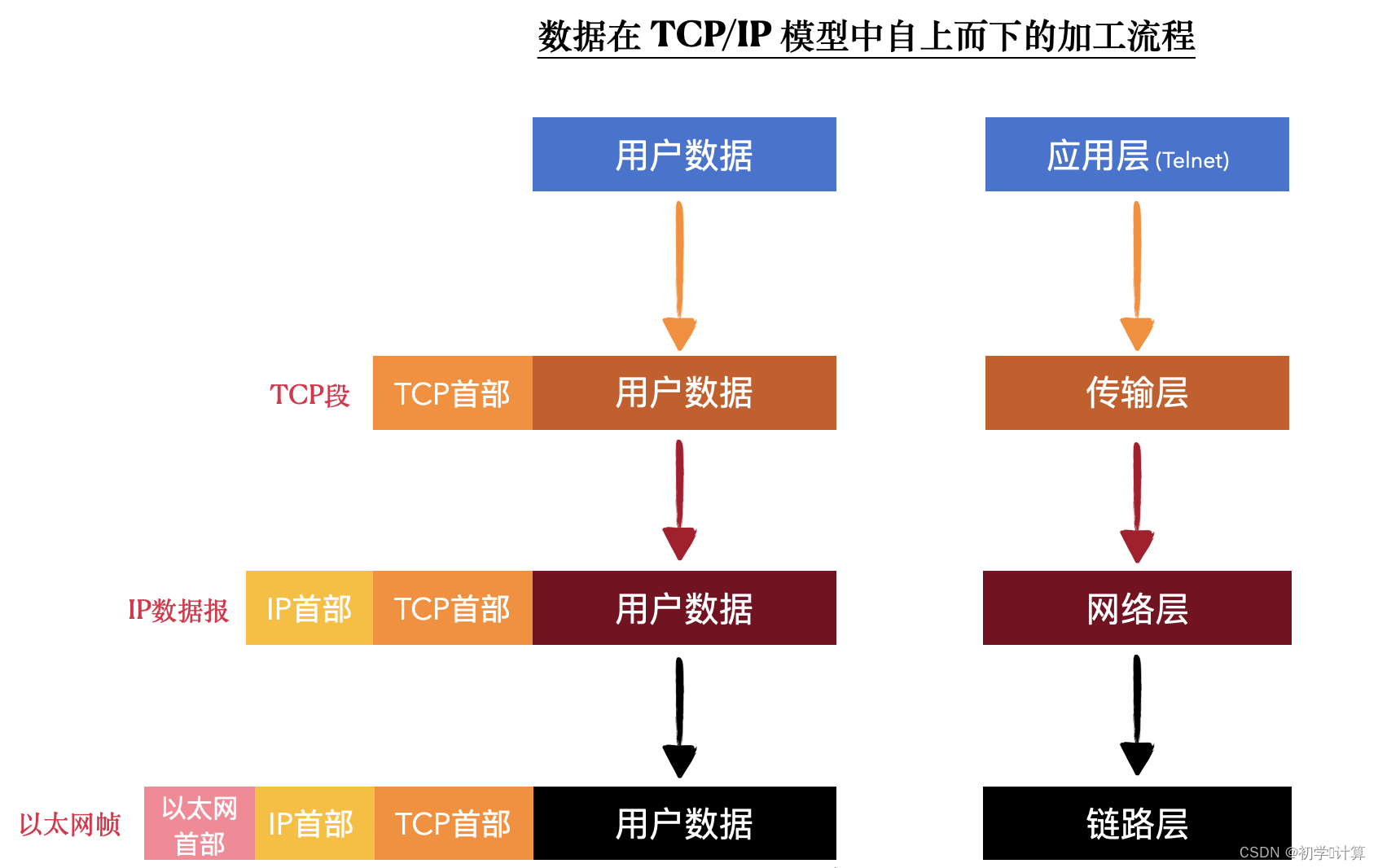
在做nlp时,首先要对文本进行分词,也就是给定一个句子,将其归到词表中的一系列token上,token有对应的数字(token_id)。

上图是bert的分词器的json内容,可以看到词表是一个字典,key为token,value为对应的id。
像 “[unused6]”:6 这样的条目。这些条目称为“未使用”(unused)标记,它们在模型的原始训练过程中没有特定的用途,但被包括在词汇表中为了可能的未来使用。
一、分词方法
Char level:字符级别。就是把文本拆分成一个个字符单独表示。
优点:能够解决OOV的问题。缺点:1.切分太细,完全失去词语级别丰富的语义信息;2.序列长度增大,增加模型推理的成本开销。
Word level:通过空格或者标点符号来把文本分成一个个单词。
优点:1.单个Word(词)粒度能够保留完整语义信息;2.减少token数。缺点:1.OOV问题;2.不能识别复数、时态等关联。
Subword level:把一个单词用多个子词表示,粒度介于Word和Char之间。能够应对OOV 问题、token 数量较少、能够考虑到复合词、时态变化、单复数。
子词级别的分词算法有BPE(Byte Pair Encoding, 字节对编码),BBPE(Byte-level BPE)、WordPiece、UniLM等。
二、BPE
https://huggingface.co/learn/nlp-course/zh-CN/chapter6/5?fw=pt
https://martinlwx.github.io/zh-cn/the-bpe-tokenizer/

三、BBPE
字节层面上的BPE算法,跟BPE的流程一样。
从发明时即为了解决中文、日本编码词表过大的问题,但是不适合中文。但中文、日本如果使用BEP对字符(characters)进行构造词表的话,其具有的生僻词会占据浪费比较大词表空间;单个汉字最长还是需要用3个token进行编码,大大增加了推理负担。
LLaMa模型的Tokenizer采用的就是BBPE。
四、WordPiece
WordPiece的流程和BPE几乎一样,也是每次词表中选出两个Subword合并成新的Subword,不同点在于WordPiece基于语言模型似然概率的最大值生成新的Subword而不是BPE根据最高频字节对。

五、UniLM
可以看成是WordPiece算法在执行过程中进行反向操作。相比WordPiece借助语言模型选择合并计算概率最大的相邻字符对加入词表中作为新的Subword,UniLM是开始时先构建足够大的词表,之后每一步选择一定比例的计算概率低的Subword从词表中删除。
1.初始时,建立一个足够大的词表。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
2.针对当前词表,用EM算法求解每个子词在语料上的概率。
3.对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
4.将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
5.重复步骤2到4,直到词表大小减少到设定范围。
六、分词器在大模型的应用
现在最主流的就是BPE。
llama支持中文能力较弱,所以要扩充词表,比如哈工大的中文版llama。
有些开源模型如BLOOM支持各种语言,但是词表太大,算力要求高,所以要裁剪掉不是中文的词表,不影响使用,而且减少了算力成本。
具体可见:https://mp.weixin.qq.com/s/pikAI1jL13kNsG8o4wzdHg
参考:
https://zhuanlan.zhihu.com/p/649030161
https://zhuanlan.zhihu.com/p/631008016?utm_id=0














106:提取不重复的整数107:哈夫曼编码108:abb](https://i-blog.csdnimg.cn/direct/82987a255aad4d168f6f92ba8da6131c.png)

![【代码随想录】【算法训练营】【第62天】 [卡码108]冗余连接 [卡码109]冗余连接II](https://i-blog.csdnimg.cn/direct/b0dc25b819274fa2abf56a603f491f57.png)