文章目录
- 前言
- 1.列表
- 1.1.列表简介
- 1.2.列表的创建
- 1.2.1.基本方式[]
- 1.2.2.list()方法
- 1.2.3.range()创建整数列表
- 1.2.4.推导式生成列表
- 1.3. 列表各种函数的使用
- 1.3.1.增加元素
- 1.3.2.删除元素
- 1.3.3.元素的访问和计数
- 1.3.4.切片
- 1.3.5.列表的排序
- 1.4.二维列表
- 2.元组
- 2.1.元组的简介
- 2.2.元组的创建
- 2.2.1.使用()创建元组
- 2.2.2.tuple()方法
- 2.3.元组的元素访问和计数
- 2.3.1.元组的元素不能修改
- 2.3.3. 元组的排序
- 2.4.zip()
- 2.5.生成器推导式创建元组
- 2.6.元组总结
- 3.字典
- 3.1.字典的简介
- 3.2.字典的创建
- 3.3.字典元素的访问
- 3.4.字典元素添加、修改、删除
- 3.5.序列解包
- 3.6.表格数据使用字典和列表存储和访问
- 4.集合
- 4.1.集合创建和删除
- 4.2.集合相关操作
前言
上一篇博客,我们学习了字符串的相关操作,今天我们学习序列
序列是一种数据存储方式,用来存储一系列的数据。在内存中,序
列就是一块用来存放多个值的连续的内存空间。比如一个整数序列
[10,20,30,40]。
由于Python3中一切皆对象,在内存中实际是按照如下方式存储
的:
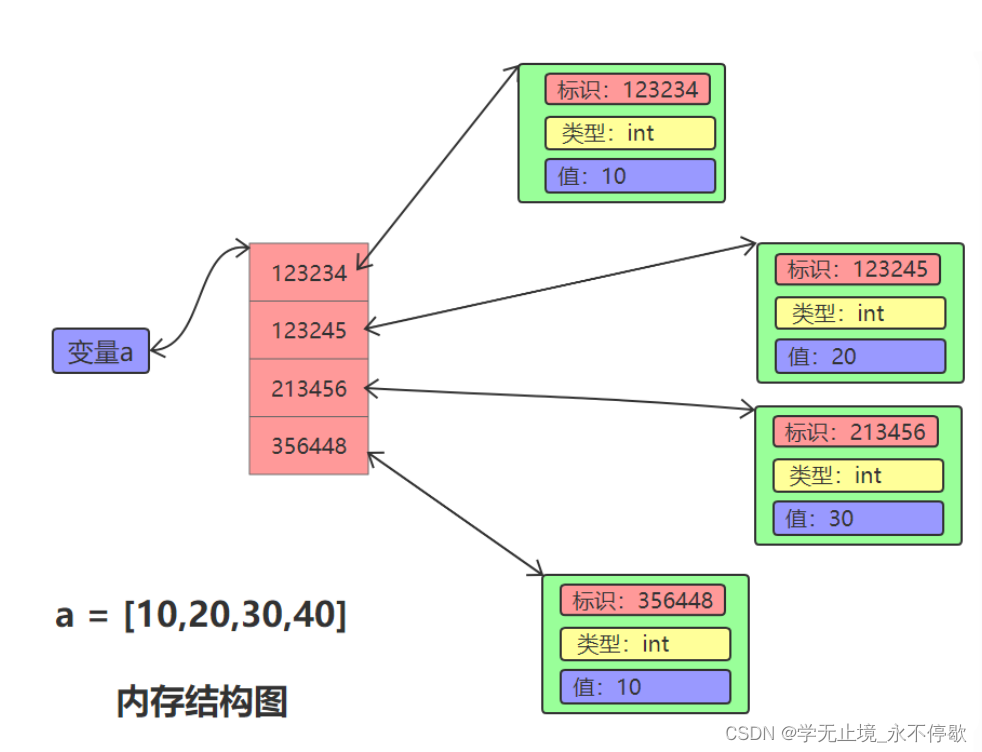
从图示中,我们可以看出序列中存储的是整数对象的地址,而不是
整数对象的值。
我们上一章学习的字符串就是一种序列。关于字符串里面很
多操作,在这一章中仍然会用到,大家一定会感觉非常熟悉。
本章内容,我们必须非常熟悉。无论是在学习还是工作中,
序列都是每天都会用到的技术,可以非常方便的帮助我们进行
数据存储的操作。
1.列表
1.1.列表简介
- 列表:用于存储任意数目、任意类型的数据集合。
- 列表是内置可变序列,是包含多个元素的有序连续的内存空间。
列表的标准语法格式:
a = [10,20,30,40]
其中,10,20,30,40这些称为:列表a的元素。
- 列表中的元素可以各不相同,可以是任意类型。比如:
a = [10,20,‘abc’,True]
- Python的列表大小可变,根据需要随时增加或缩小
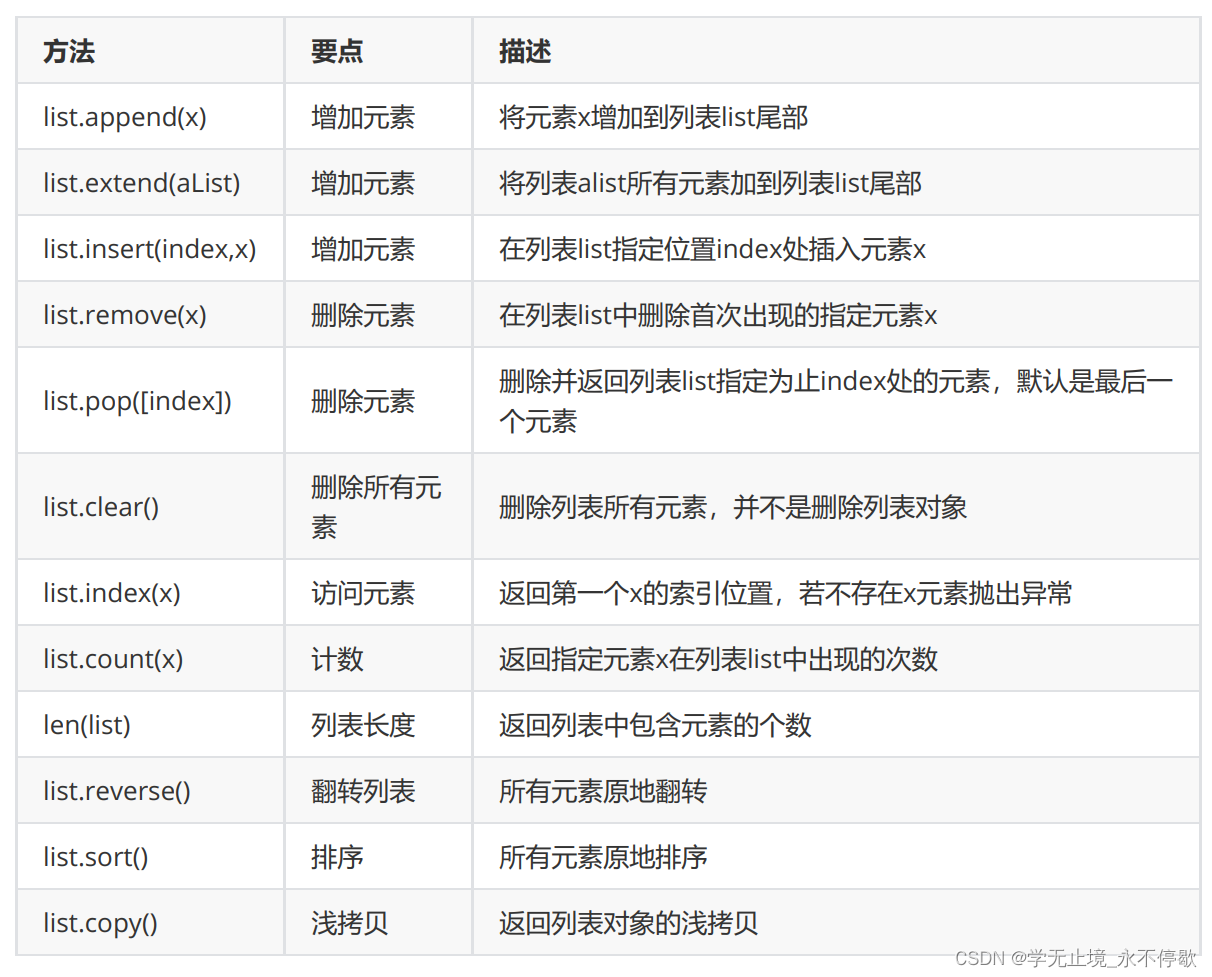
这是列表中一些常用的方法,等会需要与进行演示
1.2.列表的创建
1.2.1.基本方式[]
a = [1,2,3,4,5]
b = [] # 空链表
print(a)
print(b)
1.2.2.list()方法
使用list()可以将任何可迭代的数据转化成列表。
a = list()
b = list(range(10))
c = list('hello world')
print(a)
print(b)
print(c)
1.2.3.range()创建整数列表
ange()可以帮助我们非常方便的创建整数列表,这在开发中极其有
用。语法格式为:range([start,] end [,step])
start参数:可选,表示起始数字。默认是0
end参数:必选,表示结尾数字。
step参数:可选,表示步长,默认为1
例子:
a = list(range(1,10))
b = list(range(1,10,2))
c = list(range(10,1,-1))
print(a)
print(b)
print(c)
在Python中有很多(num1,num2)的时候,实际的取值范围是[num1,num2)(即num1可以取到,num2不能取到)
⚠python3中range()返回的是一个range对象,而不是列表。
我们需要通过list()方法将其转换成列表对象
a = range(10)
b = [range(10)]
c = list(range(10))
print(a)
print(type(a))
print(b)
print(c)
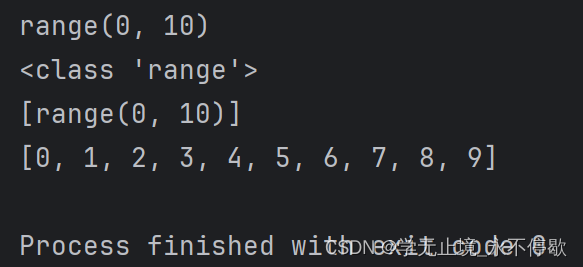
a说明是一个range类型,是一个迭代器对象
b说明不能使用[]来接受迭代器对象
c说明list()可以将迭代器对象转化为列表。
1.2.4.推导式生成列表
使用列表推导式可以非常方便的创建列表,在开发中经常使用。
⚠但是,由于涉及到for循环和if语句。在此,仅做基本介绍。
在我们控制语句后面,会详细讲解更多列表推导式的细节。
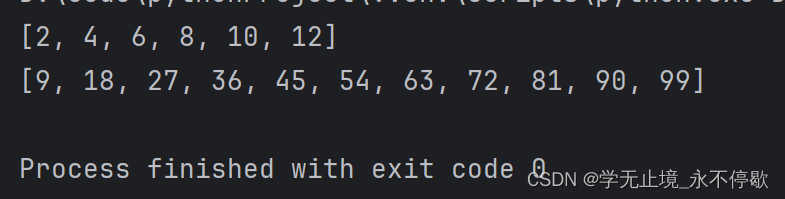
a = [x*2 for x in [1,2,3,4,5,6]]
print(a)
# 生成一个100以内能被9整除的元素组成的列表
b = [x for x in range(1,101) if x %9==0]
print(b)
1.3. 列表各种函数的使用
要讲增加、删除、查找、切片等方法
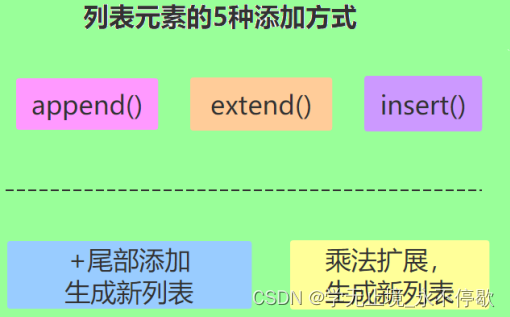
1.3.1.增加元素
当列表增加和删除元素时,列表会自动进行内存管理,大大减
少了程序员的负担。但这个特点涉及列表元素的大量移动,效
率较低。
⚠除非必要,我们一般只在列表的尾部添加元素或删除元素,
这会大大提高列表的操作效率。
append()
# append()
a = [10,20]
a.append(30)
print(a)
+运算符操作
并不是真正的尾部添加元素,而是创建新的列表对象;将原列表的元素和新列表的元素依次复制到新的列表对象中。这样,会涉及大量的复制操作,对于操作大量元素不建议使用。
a = [10,20]
print(id(a))
a = a + [30]
print(id(a))
print(a)
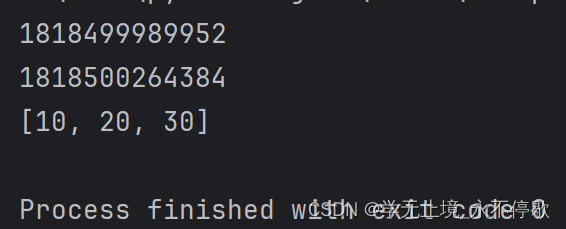
通过如上测试,我们发现变量a的地址发生了变化。也就是创建了新的列表对象
extend()方法
将目标列表的所有元素添加到本列表的尾部,属于原地操作,不创建新的列表对象。
a = [10,20]
b = [30,50]
a.extend(b)
print(a)
insert()插入元素
使用 insert() 方法可以将指定的元素插入到列表对象的任意制定位。
这样会让插入位置后面所有的元素进行移动,会影响处理速度。涉及大量元素时,尽量避免使用。类似发生这种移动的函数还有:
remove() 、 pop() 、 del() ,它们在删除非尾部元素时也会发生操作位置后面元素的移动
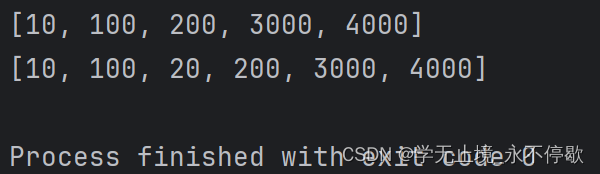
a = [100,200,3000,4000]
a.insert(0,10)
print(a)
a.insert(2,20)
print(a)
** 乘法扩展**
使用乘法扩展列表,生成一个新列表,新列表元素是原列表元素的多次重复。
a = ['hello']
b = a*3
print(b)
1.3.2.删除元素
del
删除列表指定位置的元素。
a = [10,20,30,40]
del a[2]
print(a)
pop
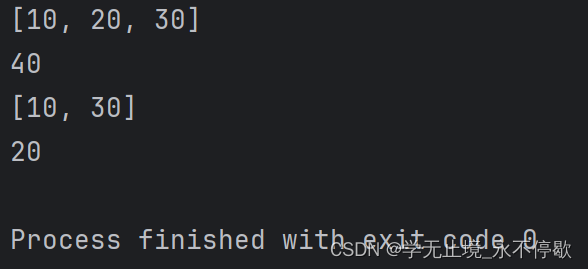
pop()删除并返回指定位置元素,如果未指定位置则默认操作列表最后一个元素。
a = [10,20,30,40]
b = a.pop()
print(a)
print(b)
c = a.pop(1)
print(a)
print(c)
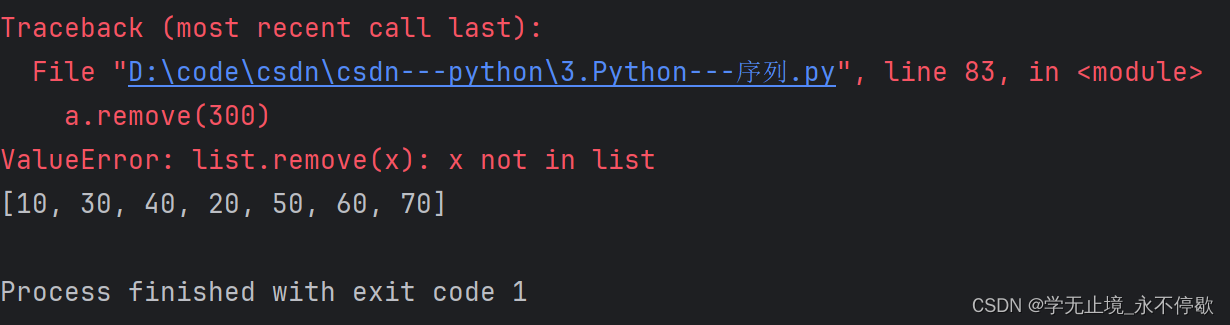
remove
删除首次出现的指定元素,若不存在该元素抛出异常。
a = [10,20,30,40,20,50,60,70]
a.remove(20)
print(a)
a.remove(300)
print(a)
1.3.3.元素的访问和计数
通过下标索引访问元素
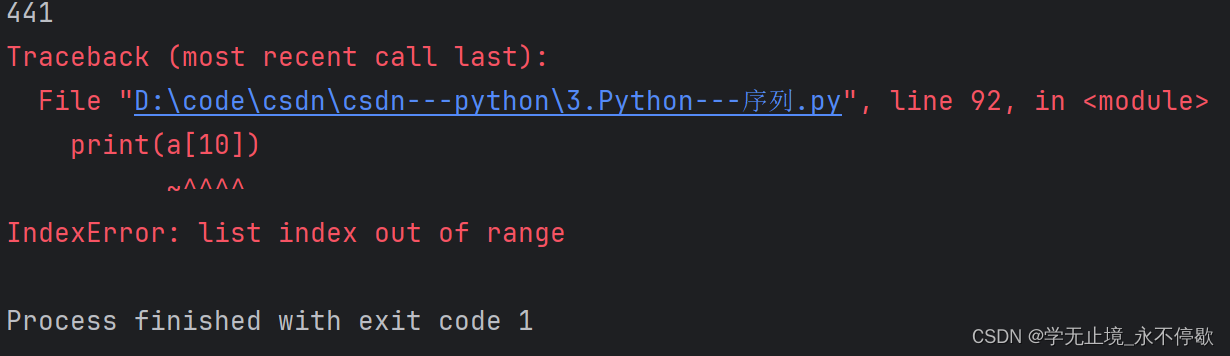
a = [10,230,403,2312,441,252]
print(a[4])
print(a[10])
index()获得指定元素在列表中首次出现的索引
index() 可以获取指定元素首次出现的索引位置。语法是: index(value,[start,[end]]) 。其中, start 和 end 指定了搜索的范围。
a = [10,20,30,40,50,30,20,10]
a1 = a.index(20)
print(a1)
a2 = a.index(30,3,6)
print(a2)
count()获得指定元素在列表中出现的次数
a = [10,20,30,40,30,20,500,30,20,10,20]
print(a.count(20))
len()返回列表长度
a = [10,20,30]
print(len(a))
成员资格判断
in和not in
a = [10,20,30,50]
print(10 in a)
print(60 not in a)
1.3.4.切片
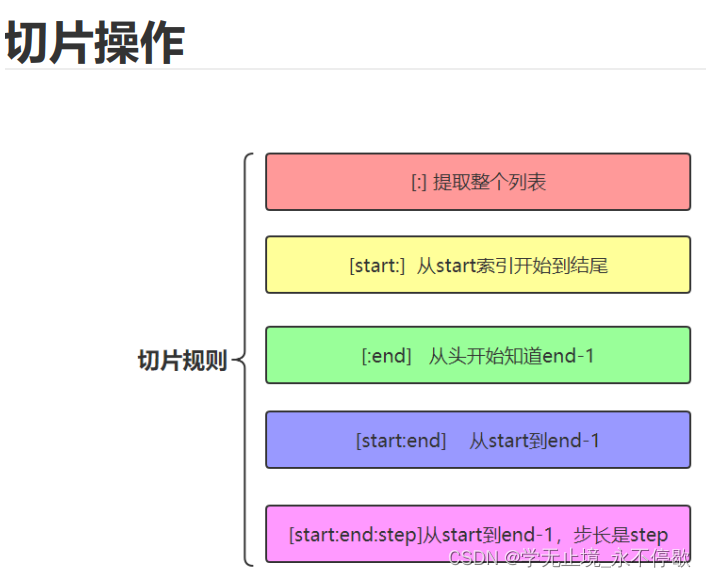
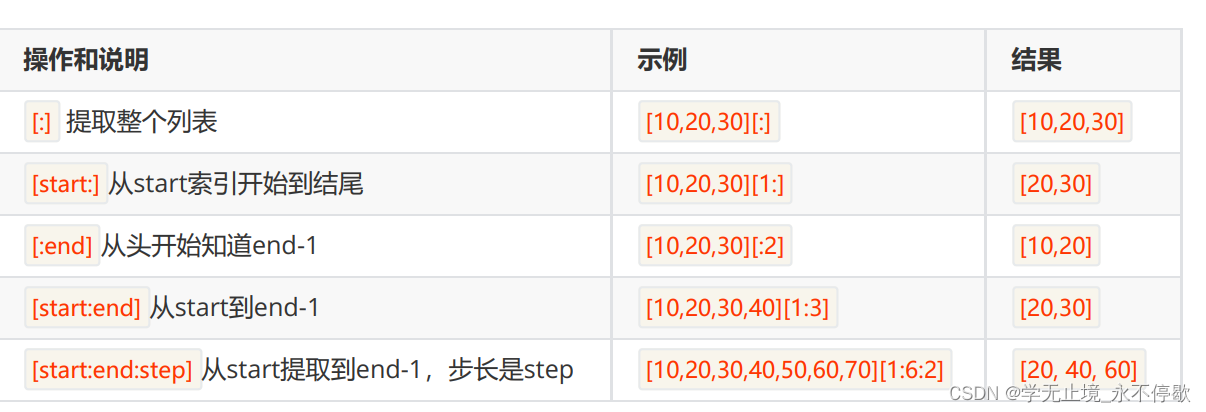
a = [10,20,30,40,50,40,30,20,10,5,4,3,2,1]
print(a[:])
print(a[1:len(a)])
print(a[1:len(a):3])
print(a[::-1])
切片操作时,起始偏移量和终止偏移量不在 [0,字符串长度-1] 这个范
围,也不会报错。起始偏移量 小于0 则会当做 0 ,终止偏移量 大于
“长度-1” 会被当成 ”长度-1” 。例如:
b = [10,20,30,40]
print(b[0:30])

1.3.5.列表的排序
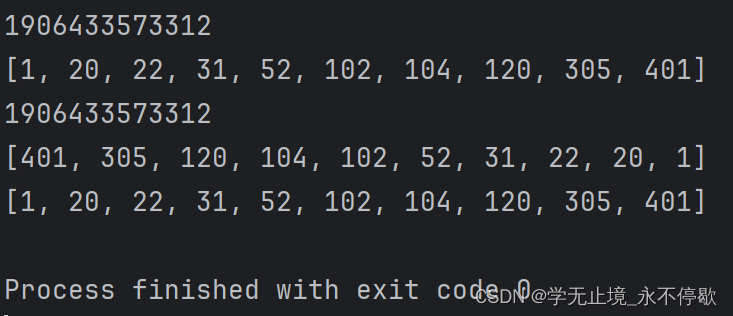
sort
sort函数排序的时候,不会创建新的对象
a =[20,31,22,102,401,305,52,104,120,1]
print(id(a))
a.sort() # 升序
print(a)
print(id(a))
a.sort(reverse=True) # 降序
print(a)
a.sort(reverse=False)# 升序
print(a)
sorted
我们也可以通过内置函数sorted()进行排序,这个方法返回新列表,
不对原列表做修改。
a =[20,31,22,102,401,305,52,104,120,1]
b = sorted(a)
print(a == b)
print(b) # 升序
c = sorted(a,reverse=True) # 降序
print(c)
d = sorted(a,reverse=False) # 升序
print(d)

reserved()返回迭代器
内置函数reversed()也支持进行逆序排列,与列表对象reverse()方
法不同的是,内置函数reversed()不对原列表做任何修改,只是返
回一个逆序排列的迭代器对象。
a =[20,31,22,102,401,305,52,104,120,1]
c =reversed(a)
print(c)
print(list(c))

我们打印输出c发现提示是:list_reverseiterator。也就是一个迭代
对象。同时,我们使用list©进行输出,发现只能使用一次。第一次
输出了元素,第二次为空。那是因为迭代对象在第一次时已经遍历
结束了,第二次不能再使用。
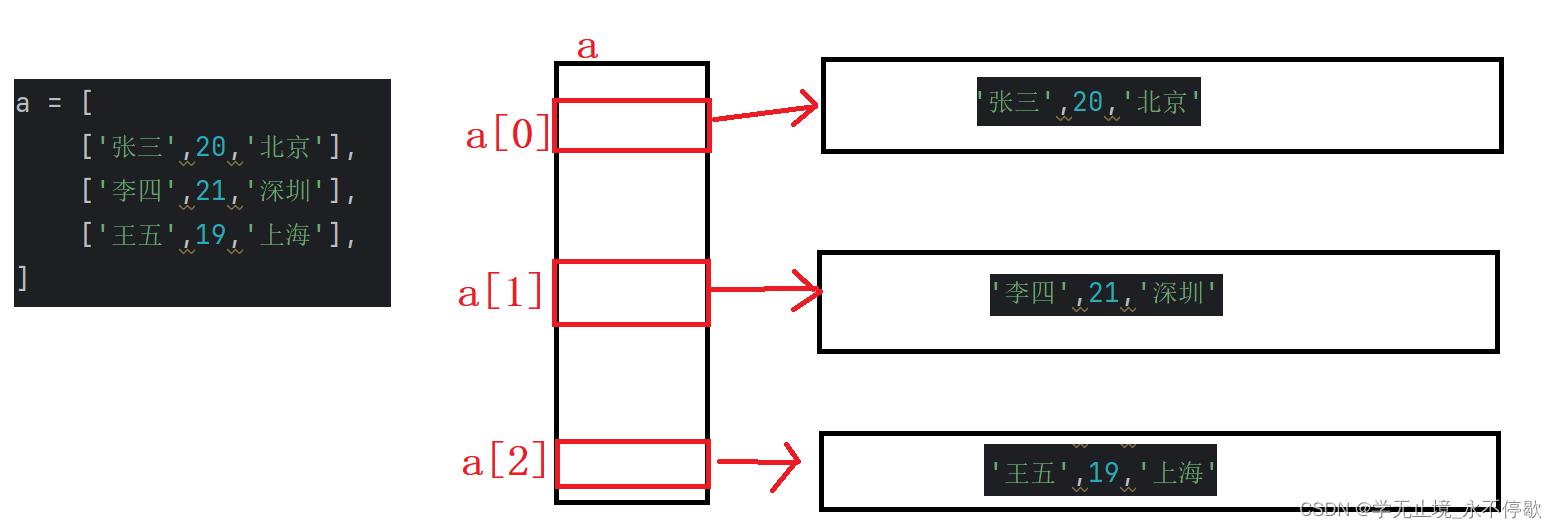
1.4.二维列表
像数组一样,列表也存在二维的,甚至是多维的
a = [
['张三',20,'北京'],
['李四',21,'深圳'],
['王五',19,'上海'],
]
for i in range(3):
for j in range(3):
print(a[i][j],end='\t')
print()
2.元组
2.1.元组的简介
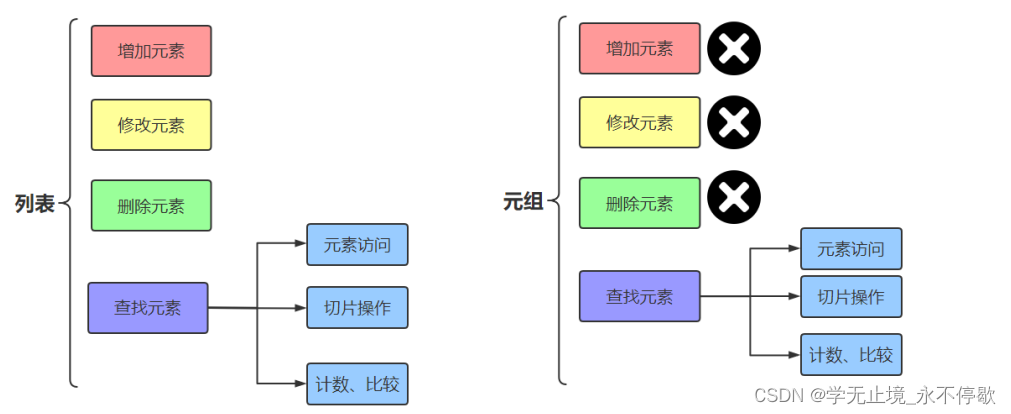
列表属于可变序列,可以任意修改列表中的元素。
元组属于不可变序列,不能修改元组中的元素。
因此,元组没有增加元素、修改元素、删除元素相关的方法。
因此,我们只需学元组的创建和删除,元素的访问和计数即可。元组支持如下操作:
1 索引访问
2 切片操作
3 连接操作
4 成员关系操作
5 比较运算操作
6 计数:元组长度len()、最大值max()、最小值min()、求和sum()等
2.2.元组的创建
2.2.1.使用()创建元组
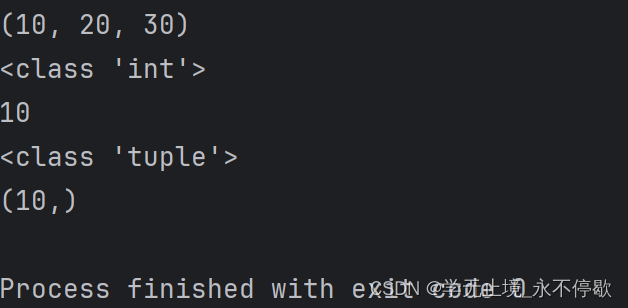
如果元组中只有一个成员变量,例如想存10,那么就要写成(10,),必须有逗号。
a = (10,20,30)
print(a)
b = (10)
c = (10,)
print(type(b))
print(b)
print(type(c))
print(c)
2.2.2.tuple()方法
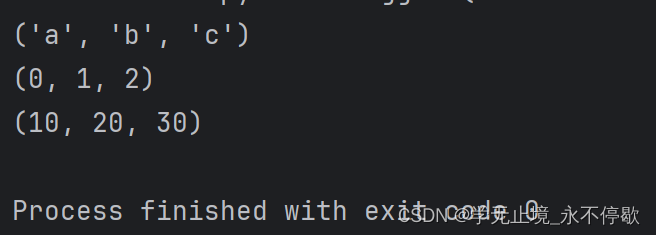
tuple()中是可迭代对象
a = tuple('abc')
b = tuple(range(3))
c = tuple([10,20,30])
print(a)
print(b)
print(c)
2.3.元组的元素访问和计数
2.3.1.元组的元素不能修改
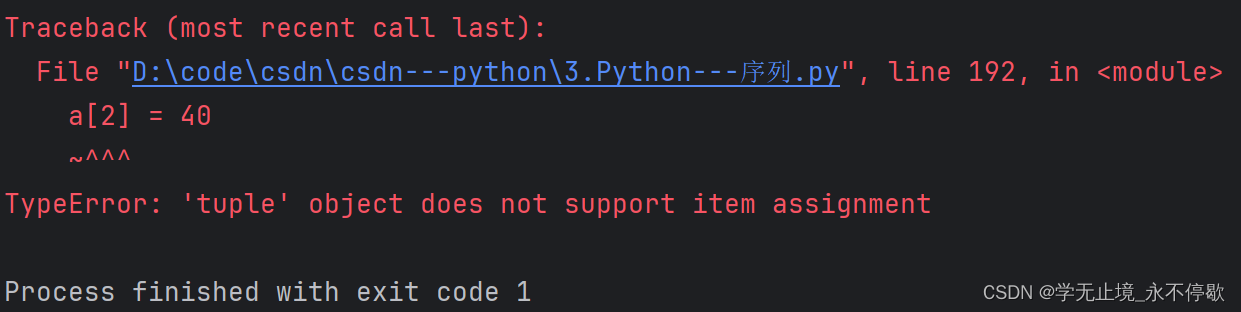
a = (10,20,30)
a[2] = 40
print(a)
2.元组的元素访问、index()、count()、切片等操作,和列表一样
2.3.3. 元组的排序
列表关于排序的方法list.sorted()是修改原列表对象,元组没有该方法。如果要对元组排序,只能使用内置函数sorted(tupleObj),并生成新的列表对象。
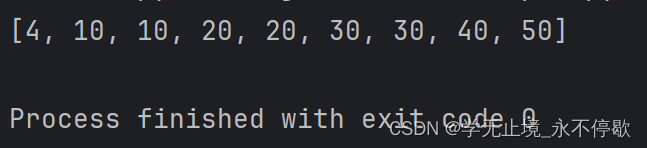
a = (10,30,20,4,30,20,10,40,50)
b = sorted(a)
print(b)
2.4.zip()
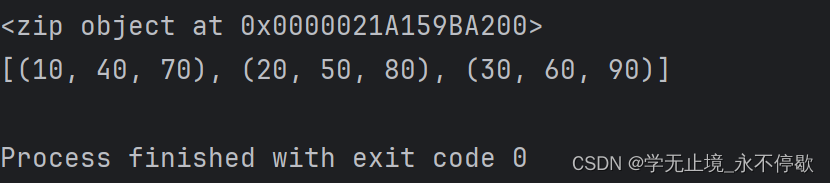
zip(列表1,列表2,…)将多个列表对应位置的元素组合成为元组,并返回这个zip对象。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同
a= [10,20,30]
b = [40,50,60]
c = [70,80,90,100]
d = zip(a,b,c)
print(d) #zip object
e = list(d)
print(e)
2.5.生成器推导式创建元组
- 从形式上看,生成器推导式与列表推导式类似,只是生成器推导式使用小括号。
- 列表推导式直接生成列表对象,生成器推导式生成的不是列表也不是元组,而是一个生成器对象。
- 我们可以通过生成器对象,转化成列表或者元组。也可以使用生成器对象的 _ next _() 方法进行遍历,或者直接作为迭代器对象来使用。不管什么方式使用,元素访问结束后,如果需要重新访问其中的元素,必须重新创建该生成器对象。
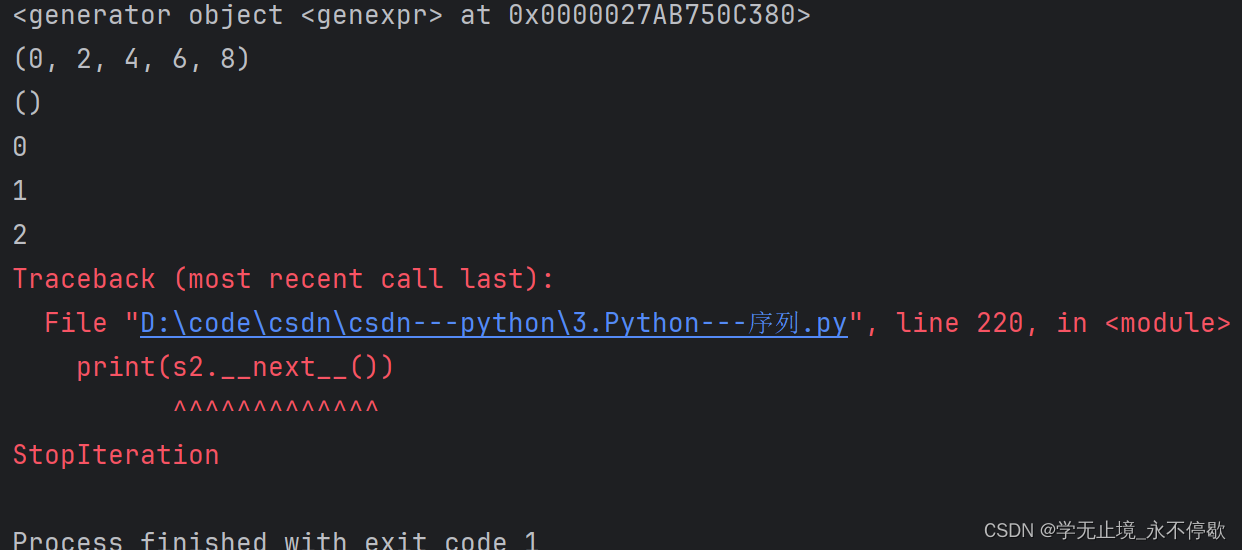
s = (x*2 for x in range(5))
print(s)
b = tuple(s)
print(b)
c = tuple(s)
print(c)
s2 = (x for x in range(3))
print(s2.__next__())
print(s2.__next__())
print(s2.__next__())
print(s2.__next__())
2.6.元组总结
1 元组的核心特点是:不可变序列。
2 元组的访问和处理速度比列表快。
3 与整数和字符串一样,元组可以作为字典的键,列表则永远不能作为字典的键使用。
3.字典
3.1.字典的简介
字典是“键值对”的无序可变序列,字典中的每个元素都是一个“键值对”,包含:“键对象”和“值对象”。可以通过“键对象”实现快速获取、删除、更新对应的“值对象”。

一个典型的字典的定义方式:
a = {‘name’:‘gaoqi’, ‘age’:18, ‘job’:‘programmer’}
列表中我们通过“下标数
字”找到对应的对象。字典中通过“键对象”找
到对应的“值对象”。
1 “键”是任意的不可变数据,比如:整数、浮点数、字符串、元组。
2 但是:列表、字典、集合这些可变对象,不能作为“键”。
3 并且“键”不可重复。
4 “值”可以是任意的数据,并且可重复
3.2.字典的创建
- 我们可以通过{}、dict()来创建字典对象。
a = {'name':'smy','age':18,'gender':'male'}
b = dict(name = 'smy',age = 18 , gender = 'male')
c =dict([('name','smy'),('age',20)])
print(a)
print(b)
print(c)
- 通过zip()创建字典对象
k = ['name','age','gender']
v = ['smy',20,'male']
d = dict(zip(k,v))
- 通过fromkeys创建值为空的字典
f = dict.fromkeys(['name','age','job'])
print(f) #结果:{'name': None, 'age':None, 'job': None}
3.3.字典元素的访问
为了测试各种访问方法,我们这里设定一个字典对象:
a = {‘name’:‘zhangsan’,‘age’:18,‘gender’:‘male’}
1 通过 [键] 获得“值”。若键不存在,则抛出异常。
a = {'name':'zhangsan','age':18,'gender':'male'}
print(a['name'])
2 通过get()方法获得“值”。❤推荐使用。优点是:指定键不存在,
返回None;也可以设定指定键不存在时默认返回的对象。推荐
使用get()获取“值对象”
a = {'name':'zhangsan','age':18,'gender':'male'}
b = a.get('name')
print(b)
c = a.get('job','不存在')
print(c)
3 列出所有的键值对
a = {'name':'zhangsan','age':18,'gender':'male'}
d = a.items()
print(d)
4 列出所有的键,列出所有的值
a = {'name':'zhangsan','age':18,'gender':'male'}
k = a.keys()
v = a.values()
print(k)
print(v)
5 len() 键值对的个数
a = {'name':'zhangsan','age':18,'gender':'male'}
num = len(a)
print(num)
6 检测一个“键”是否在字典中
a = {'name':'zhangsan','age':18,'gender':'male'}
print('name' in a)
3.4.字典元素添加、修改、删除
- 给字典新增“键值对”。如果“键”已经存在,则覆盖旧的键值对;如果“键”不存在,则新增“键值对”
a = {'name':'zhangsan','age':18,'gender':'male'}
a['city'] = 'Luoyang'
print(a)
a['age'] = 19
print(a)
- 使用 update() 将新字典中所有键值对全部添加到旧字典对象上。如果 key 有重复,则直接覆盖
a = {'name':'zhangsan','age':18,'gender':'male'}
b = {'name':'Lisi','age':20,'city':'Luoyang','salary':20000}
a.update(b)
print(a)
- 字典中元素的删除,可以使用 del() 方法;或者 clear() 删除所有键值对; pop() 删除指定键值对,并返回对应的“值对象”
a = {'name':'zhangsan','age':18,'gender':'male'}
del(a['name'])
b = a.pop('age')
print(a)
print(b)
- popitem() :随机删除和返回该键值对。字典是“无序可变序列”,因此没有第一个元素、最后一个元素的概念; popitem 弹出随机的项,因为字典并没有"最后的元素"或者其他有关顺序的概念。若想一个接一个地移除并处理项,这个方法就非常有效(因为不用首先获取键的列表)
a = {'name':'zhangsan','age':18,'gender':'male'}
a.popitem()
a.popitem()
a.popitem()
print(a)
3.5.序列解包
序列解包可以用于元组、列表、字典。序列解包可以让我们方便的对多个变量赋值
x,y,z = (10,20,30)
(a,b,c) = (20,30,40)
[i,j,k] = [1,2,3]
print(x,y,z)
print(a,b,c)
print(i,j,k)
序列解包用于字典时,默认是对“键”进行操作; 如果需要对键值对操作,则需要使用items();如果需要对“值”进行操作,则需要使用values();
s = {'name':'jerry','age':18,'job':'teacher'}
name,age,job=s #默认对键进行操作
print(name) #name
name,age,job=s.items() #对键值对进行操作
print(name)
name,age,job=s.values() #对值进行操作
print(name)
3.6.表格数据使用字典和列表存储和访问
d1 = {'name':'zhangsan','age':20,'city':'beijing','salary':20000}
d2 = {'name':'lisi','age':30,'city':'shenzhen','salary':25000}
d3 = {'name':'wangwu','age':20,'city':"xi'an",'salary':14000}
l = [d1,d2,d3]
#获得第二行的人的薪资
print(l[1].get('salary'))
#打印表中所有的的薪资
for i in range(len(l)):
print(l[i].get('salary'))
#打印表的所有数据
for i in range(len(l)):
print(l[i].get('name'),l[i].get('age'),l[i].get('city'),l[i].get('salary'))
4.集合
4.1.集合创建和删除
集合是无序可变,元素不能重复。实际上,集合底层是字典实现,集合的所有元素都是字典中的“键对象”,因此是不能重复的且唯一的
1.使用{}创建集合对象,并使用add()方法添加元素
a = {20,30,40}
a.add(40)
2.使用set(),将列表、元组等可迭代对象转成集合。如果原来数据存在重复数据,则只保留一个
a = {'a','b','c','a'}
b = set(a)
print(a)# {'a', 'c', 'b'}
3.remove()删除指定元素;clear()清空整个集合
a = {10,20,30,40}
a.remove(30)
print(a)
a.clear()
print(a)
4.2.集合相关操作
像数学中概念一样,Python对集合也提供了并集、交集、差集等运算。我们给出示例
a = {1,3,'xxhh'}
b = {'he','it','xxhh'}
print(a & b)
print(a | b)
print(a - b)
print(a.union(b))
print(a.intersection(b))
print(a.difference(b))

完