测试任务:将以前完成的所有的脚本统一改写为unitest框架方式

1、需求原型
1.1 框架目录结构
V1.0:一般的设计思路分为配置层、脚本层、数据层、结果层,如下图所示

V 2.0:加入驱动层testdriver
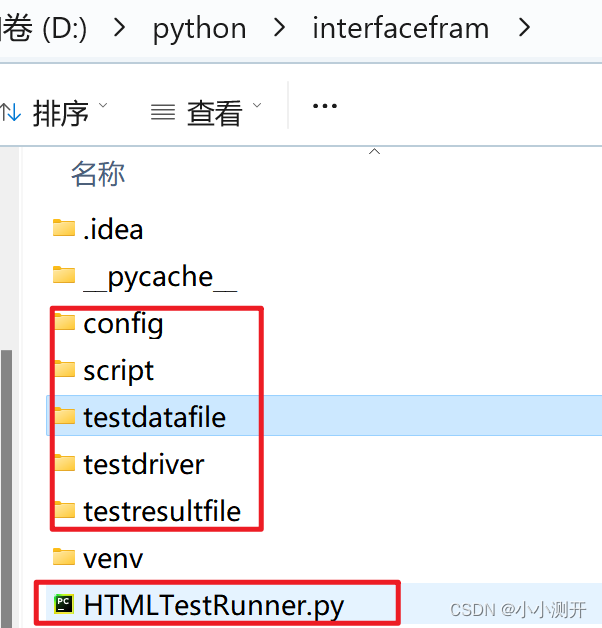
1.2 框架各层需要完成的工作
1、配置层:config
设计配置文件.csv:由配置文件来控制此次测试执行,以及需要调用哪些测试脚本。
2、脚本层:script
ind_interface:存放独立接口测试脚本、一个类中有一个测试方法、完成一个接口的测试。
mul_interface:存放接口联调测试脚本、一个类中有多个测试方法、完成接口联调的测试。
注意:脚本文件的名称有一定的规范性。
3、测试数据文件层:testdatafile
ind_interface:存放独立接口测试脚本对应的测试数据文件
mul_interface:存放接口联调测试脚本对应的测试数据文件
注意:数据文件的命名 ind_、 mul_
4、测试报告文件层:testresultfile
fram_result:测试框架报告
ind_interface:存放独立接口测试报告文档
mul_interface:存放联调接口测试报告文档
注意:报告文件命名 fram_ 、ind_rep_ 、mul_rep_
5、框架驱动层
存放测试框架的驱动程序
1.3 框架的测试执行过程
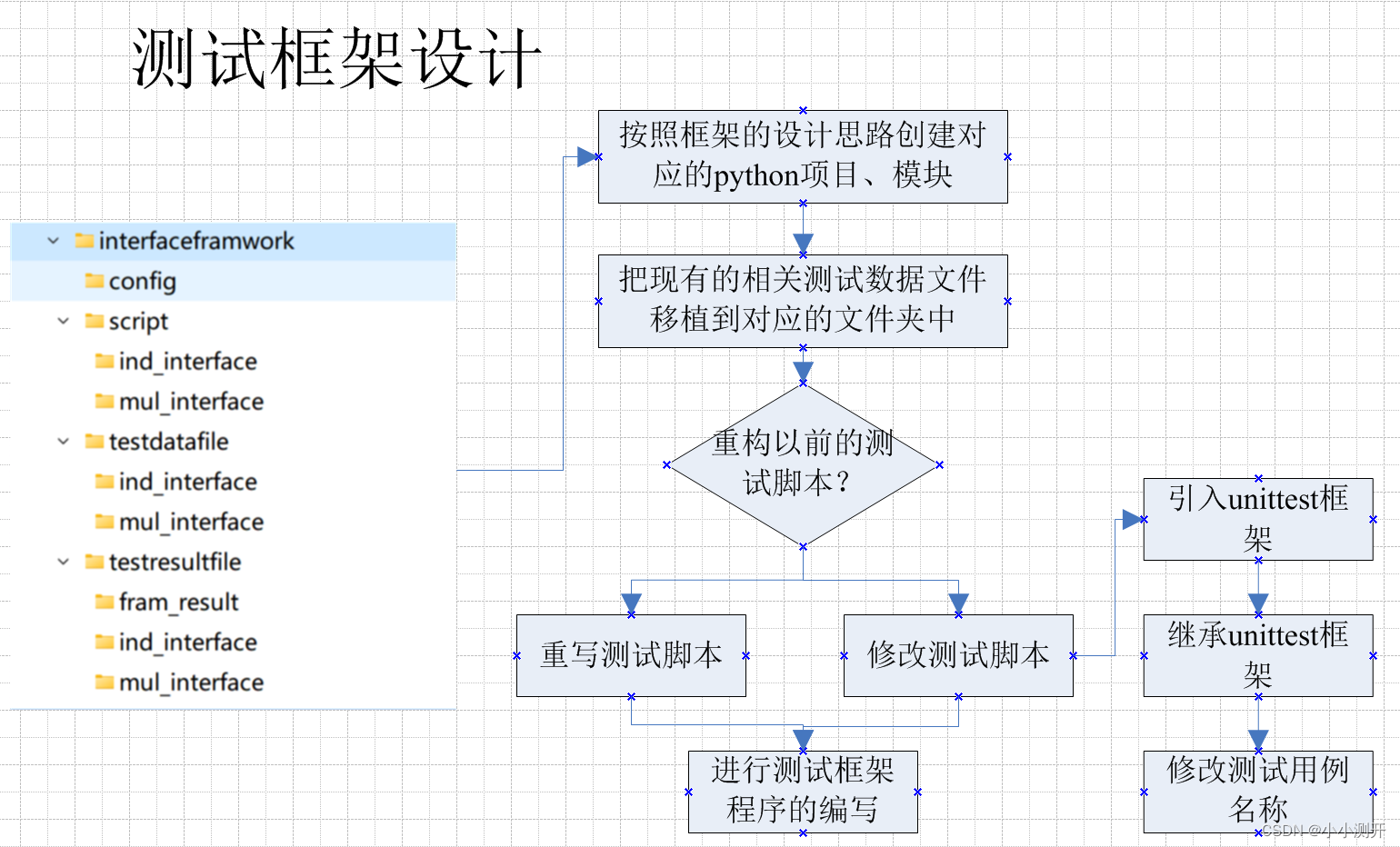
1、由框架驱动层中的框架驱动程序运行。


2、依据配置层相关的设置是否执行及执行顺序,调用对应脚本层的程序,进行执行。
3、相关的脚本运行时,如果需要测试数据,则在数据层进行文件的读取。
4、测试脚本执行结束后,会写明相关的测试报告文件,并存入测试报告层。
1.4 最终目标
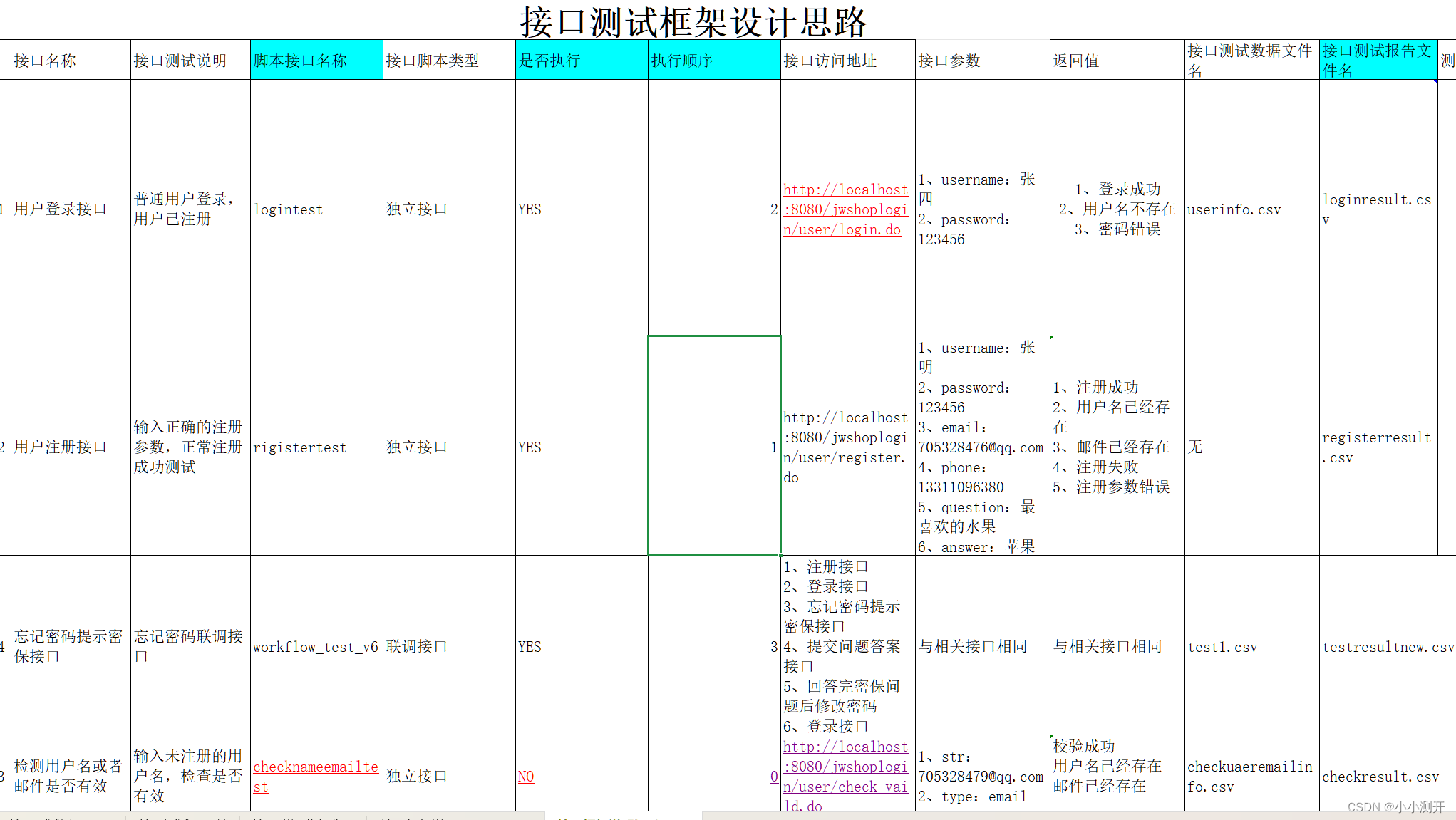
2、测试框架前期准备
1、依据框架需求搭建框架项目及模块
2、接口测试数据文件向框架转移
3、框架脚本的研发
3.1 重构测试脚本
更新用户信息接口测试,在框架对应的分层下创建新的python文件,注意符合命名规范,test_updateuser
3.1.1 更新用户信息接口V1.0
V1.0版本
S1:导入unittest
S2:定义一个类,继承unittest
S3:传入固定的接口测试数据(一组)
S4:assert进行判断

# 对更新用户信息的脚本进行测试,使用unittest框架技术,V1.0版本,传入一组固定的测试数据,进行接口测试
# 接口说明:
# 接口访问地址: http://localhost:8080/jwshoplogin/user/update_information.do
# 接口传入参数:1、email: 2、phone:3、answer: 4、question:
# 接口预期返回结果:
# 1、email已存在, 请更换email再尝试更新 2、更新个人信息成功 3、更新个人信息失败"
#*****************************************************************************
# 脚本实现:
# 导入相关类库
import unittest
import requests
# 定义测试类,继承unittest框架
class test_updateuser(unittest.TestCase):
# 通过setup方法实现登录接口的调用
def setUp(self):
url="http://localhost:8080/jwshoplogin/user/login.do"
userinfo={"username":"程勇4",
"password":"123456"}
response=requests.post(url,data=userinfo)
self.sessionID=dict(response.cookies)['JSESSIONID']
print(self.sessionID)
# V1.0版本,传入一组固定的测试数据,进行接口测试
def test_case1(self):
# 传入指定的接口测试数据
url="http://localhost:8080/jwshoplogin/user/update_information.do"
userinfo={"email":"1234561@qq.com",
"phone":"13311095555",
"question": "苹果",
"answer":"最喜欢的水果"
}
session={"JSESSIONID":self.sessionID}
# 进行接口调用
response=requests.post(url,data=userinfo,cookies=session).text
print(response)
self.assertIn("更新个人信息成功",response)
def tearDown(self):
pass
if __name__ == '__main__':
unittest.main()3.1.2 更新用户信息接口V2.0
S1:是否需要测试数据文件
对测试数据文件进行设计
测试用例的设计
更新接口测试分析
正常
只更新一个数据
1、只更新email
email不冲突
2、只更新phone
3、只更新answer
4、只更新问题question
更新更多数据
更新2组数据
更新email和phone
email不冲突
更新question和answer
更新...
更新3组数据
更新email和phone和question
更新全部数据
1、email
email不冲突
2、phone
3、answer
4、question
异常
1、未登录更新
2、邮箱冲突
3、电话的长度不正确
4、问题为空
5、答案为空
S2:把数据文件中的内容传入脚本
# V2.0 通过csv文件进行更新测试数据的读取
# 接口说明:
# 接口访问地址: http://localhost:8080/jwshoplogin/user/update_information.do
# 接口传入参数:1、email: 2、phone:3、answer: 4、question:
# 接口预期返回结果:
# 1、email已存在, 请更换email再尝试更新 2、更新个人信息成功 3、更新个人信息失败"
#*****************************************************************************
# 脚本实现:
# 导入相关类库
import os
import unittest
import requests
import csv
# 定义测试类,继承unittest框架
class test_updateuser_V2(unittest.TestCase):
# 通过setup方法实现登录接口的调用
def setUp(self):
# # 从csv测试数据文件中读取url和登录测试数据
path=os.getcwd()
print(path)
# p1=os.path.abspath(os.path.dirname(path)+os.path.sep+".")
# print(p1)
p2 = os.path.abspath(os.path.dirname(path) + os.path.sep + "..")
self.fpath=p2+"\\testdatafile\\ind_interface\\test_updateuser_V21.csv"
# print(fpath)
userinfo={}
file1=open(self.fpath,'r')
table=csv.reader(file1)
for row in table:
print(row[0])
url=row[0]
userinfo[row[3]]=row[4]
userinfo[row[5]]=row[6]
print(userinfo)
break # 读完一行就退出
response=requests.post(url,data=userinfo)
self.sessionID=dict(response.cookies)['JSESSIONID']
print(self.sessionID)
# V2.0版本,读取指定的测试数据文件中对应的内容,进行接口测试
def test_case1(self):
# 打开对应的文件
file1=open(self.fpath,'r')
# 如何从指定行开始读取
table=csv.reader(file1)
userinfo={}
num=0
for row in table:
num=num+1
if num>1:
url=row[0]
expresult=row[2]
j=int(row[1])
for i in range(3,j*2+3,2):
userinfo[row[i]]=row[i+1]
print(userinfo)
session={"JSESSIONID":self.sessionID}
print(session)
response=requests.post(url,data=userinfo,cookies=session).text
print(response)
userinfo={}
self.assertIn("更新个人信息成功",response)
if __name__ == '__main__':
unittest.main()
工作小结:需要注意的事项
1、文件位置的读取
import os
获取当前路径
path=os.getcwd()
获取上一级路径
p1=os.path.abspath(os.path.dirname(path)+os.path.sep+".")
获取前两级路径
p2 = os.path.abspath(os.path.dirname(path) + os.path.sep + "..")
2、测试数据文件的设计
可以把固定的内容放在前面的列中
把不定项的参数可以放在后面的列中
通过手工加入参数个数。方便进行循环读取
不要用拖拽的方式拷贝数据,防止数据出错
先设计正确的数据,保证脚本调试通过
再设计错误的数据
也可以考虑放在不同的文件
3、从指定的某一行开始读取内容
num=0
for row in table:
追加
num=num+1
例如:我们想从第四行读起
if num>4
从指定的行开始进行读取
3.1.3 更新用户信息接口V3.0
生成HTML格式的测试报告
步骤
1、下载HTML格式的测试报告
步骤
1、下载HTMLTestRunner.py
http://tungwaiyip.info/software/HTMLTestRunner.html
2、拷贝到项目文件夹下
3、导入HTMLReport包
from HTMLTestRunner import HTMLTestRunner
4、生成测试报告的脚本
脚本
做好测试执行前的准备工作
指定要执行的测试用例
S1:以wb(二进制写文件)模式打开测试报告文件
S2:使用HTMLTestRunner方法创建HTML文件
S3:执行测试
S4:关闭文件
工作小结
在main()函数中来生成html的测试报告
1、获取测试报告文件应放置的路径
2、给定具体的测试报告文件名
3、以wb的方式打开文件
4、设置测试套,并添加要 测试的方法
5、生成HTML报告
runner=HTMLTestRunner(stream=file,title="标题",description="描述")
6、调用runner对象执行测试套
runner.run(suite)
7、关闭测试报告文件
# v3.0 创建HTML格式的测试报告文件
# 接口说明:
# 接口访问地址: http://localhost:8080/jwshoplogin/user/update_information.do
# 接口传入参数:1、email: 2、phone:3、answer: 4、question:
# 接口预期返回结果:
# 1、email已存在, 请更换email再尝试更新 2、更新个人信息成功 3、更新个人信息失败"
#*****************************************************************************
# 脚本实现:
# 导入相关类库
import os
import unittest
import requests
import csv
from HTMLTestRunner import HTMLTestRunner
# 定义测试类,继承unittest框架
class test_updateuser_V3(unittest.TestCase):
# 通过setup方法实现登录接口的调用
def setUp(self):
# # 从csv测试数据文件中读取url和登录测试数据
path=os.getcwd()
# print(path)
# p1=os.path.abspath(os.path.dirname(path)+os.path.sep+".")
# print(p1)
p2 = os.path.abspath(os.path.dirname(path) + os.path.sep + "..")
print(p2)
self.fpath=p2+"\\testdatafile\\ind_interface\\test_updateuser_V21.csv"
# print(fpath)
userinfo={}
file1=open(self.fpath,'r')
table=csv.reader(file1)
for row in table:
print(row[0])
url=row[0]
userinfo[row[3]]=row[4]
userinfo[row[5]]=row[6]
print(userinfo)
break
response=requests.post(url,data=userinfo)
self.sessionID=dict(response.cookies)['JSESSIONID']
print(self.sessionID)
def test_case1(self):
# 打开对应的文件
file1=open(self.fpath,'r')
# 如何从指定行开始读取
table=csv.reader(file1)
userinfo={}
num=0
for row in table:
num=num+1
if num>1:
url=row[0]
expresult=row[2]
j=int(row[1])
for i in range(3,j*2+3,2):
userinfo[row[i]]=row[i+1]
print(userinfo)
session={"JSESSIONID":self.sessionID}
print(session)
response=requests.post(url,data=userinfo,cookies=session).text
print(response)
userinfo={}
self.assertIn("更新个人信息成功",response)
if __name__ == '__main__':
# unittest.main()
# 定义测试报告文件
path=os.getcwd()
p2 = os.path.abspath(os.path.dirname(path) + os.path.sep + "..")
filename=p2+"\\testresultfile\\ind_interface\\test_updatauser_report.html"
# 加载测试套
suite=unittest.TestSuite()
suite.addTest(test_updateuser_V3("test_case1"))
# 以wb的方式打开文件
file=open(filename,"wb")
# 调用HTML测试报告的报告生成测试报告
runner=HTMLTestRunner(stream=file,title="更新用户接口测试",description="接口测试报告")
print("测试报告")
runner.run(suite)
file.close()
3.1.4 遇到问题分析
更新用户的接口,需要先进行登录
1、测试场景1:未登录,进行更新
提示:用户未登录
2、 测试场景2:先登录,再进行更新
需要解决的问题
解决方案
方案1
在当前的测试类中,追加一个setup方法
登录的测试脚本写入setup中
用的比较多
方案2:
在当前的测试类中,追加一个新的测试方法
test_case1
完成登录的调用
把原来的更新测试方法改为test_case2
方案3:
在当前的测试类及测试方法中
前面追加一段代码
完成登录的调用
方案4:
另外创建一个脚本文件,来实现登录,通过测试框架进行接口测试联调
3、遇到的问题
即使已经发送了登录请求,在调用更新接口时提示"用户未登录"
问题分析
sessionID
服务器端发送给客户端一个随机的认证号码
方法1:
使用postman工具
先登录
再修改个人信息是否可行
方法2:
通过工具获取JESSIONID
再把相关的JESSION传入代码中
问题:
1、JessionID有时间限制
2、如果关闭tomcat服务重新启动,session自动失效了
3、用工具过去的session ID和登录脚本没有任何关系
方法3
在用户登录之后获取到对应的JESSIONID
dict(response.cookie)["JSESSIONID"]
把这个JESSIONID当成传输参数传递给更新脚本
self.sessionID
要解决的问题
如何在登录后获取对应的JESSIONID
4、设计及实现框架驱动程序
4.1 框架驱动程序V1.0
在配置文件中写入一个测试文件进行执行

S1:设计一个配置文件
脚本名称
脚本所在路径
S2:读取配置文件的内容
S3:找到对应的脚本文件进行调用
工作小结
工作思路
由简到繁
选择一种框架调用模式
defaultloader方式
unittest.defaultTestLoader.discover(路径,pattern=脚本名称)
先用常量值进行脚本的调试
在把常量值改为变量值
逐个替换
不要全部替换
再把变量改为从文件读取
发现问题,添加print语句进行分析
问题:路径不一致
级别关系发生了变化
print(path)
调整脚本中对应的路径级别
# 测试框架驱动程序V1.0版本
# 只是从配置文件中读取一个脚本文件进行调用
import csv
import unittest
if __name__ == '__main__':
# 指定对应的脚本路径,从csv文件中读取相关路径和文件名
file=open("D:\python\interfacefram\config\config1.csv","r")
table=csv.reader(file)
num=0
for row in table:
if num>0:
testdir=row[0]
fname=row[1]
print(testdir,fname)
num=num+1
discover=unittest.defaultTestLoader.discover(testdir,pattern=fname)
# # 定义一个运行对象
runner=unittest.TextTestRunner()
runner.run(discover)4.2 框架驱动程序V2.0
在配置文件中写入两个测试文件进行执行

S1:修改配置文件
S2:进行脚本的修改
# 测试框架驱动程序V2.0版本
# 只是从配置文件中读取两个脚本文件进行调用
import csv
import unittest
if __name__ == '__main__':
# 指定对应的脚本路径,从csv文件中读取相关路径和文件名
file=open("D:\python\interfacefram\config\config2.csv","r")
table=csv.reader(file)
num=0
for row in table:
if num>0:
testdir=row[0]
fname=row[1]
print(testdir,fname)
discover = unittest.defaultTestLoader.discover(testdir, pattern=fname)
# # 定义一个运行对象
runner = unittest.TextTestRunner()
runner.run(discover)
num=num+1
4.3 框架驱动程序V3.0
在配置文件中针对不同的运行状态进行文件的执行
S1:升级改造配置文件
加入一状态列
状态表示
0/1不运行/运行
RUN/NORUN
No/Yes
S2:脚本的调整
加入条件判断

# v3.0 创建HTML格式的测试报告文件
# 接口说明:
# 接口访问地址: http://localhost:8080/jwshoplogin/user/update_information.do
# 接口传入参数:1、email: 2、phone:3、answer: 4、question:
# 接口预期返回结果:
# 1、email已存在, 请更换email再尝试更新 2、更新个人信息成功 3、更新个人信息失败"
#*****************************************************************************
# 脚本实现:
# 导入相关类库
import os
import unittest
import requests
import csv
from HTMLTestRunner import HTMLTestRunner
# 定义测试类,继承unittest框架
class test_updateuser_V3(unittest.TestCase):
# 通过setup方法实现登录接口的调用
def setUp(self):
# # 从csv测试数据文件中读取url和登录测试数据
path=os.getcwd()
# print(path)
# p1=os.path.abspath(os.path.dirname(path)+os.path.sep+".")
# print(p1)
p2 = os.path.abspath(os.path.dirname(path) + os.path.sep + "..")
print(p2)
self.fpath=p2+"\\testdatafile\\ind_interface\\test_updateuser_V21.csv"
# print(fpath)
userinfo={}
file1=open(self.fpath,'r')
table=csv.reader(file1)
for row in table:
print(row[0])
url=row[0]
userinfo[row[3]]=row[4]
userinfo[row[5]]=row[6]
print(userinfo)
break
response=requests.post(url,data=userinfo)
self.sessionID=dict(response.cookies)['JSESSIONID']
print(self.sessionID)
def test_case1(self):
# 打开对应的文件
file1=open(self.fpath,'r')
# 如何从指定行开始读取
table=csv.reader(file1)
userinfo={}
num=0
for row in table:
num=num+1
if num>1:
url=row[0]
expresult=row[2]
j=int(row[1])
for i in range(3,j*2+3,2):
userinfo[row[i]]=row[i+1]
print(userinfo)
session={"JSESSIONID":self.sessionID}
print(session)
response=requests.post(url,data=userinfo,cookies=session).text
print(response)
userinfo={}
self.assertIn("更新个人信息成功",response)
if __name__ == '__main__':
# unittest.main()
# 定义测试报告文件
path=os.getcwd()
p2 = os.path.abspath(os.path.dirname(path) + os.path.sep + "..")
filename=p2+"\\testresultfile\\ind_interface\\test_updatauser_report.html"
# 加载测试套
suite=unittest.TestSuite()
suite.addTest(test_updateuser_V3("test_case1"))
# 以wb的方式打开文件
file=open(filename,"wb")
# 调用HTML测试报告的报告生成测试报告
runner=HTMLTestRunner(stream=file,title="更新用户接口测试",description="接口测试报告")
print("测试报告")
runner.run(suite)
file.close()
4.4 框架驱动程序V4.0
按照测试人员指定的顺序来执行相应的测试文件
S1:升级改造配置文件
加入执行顺序
S2:修改脚本
# v4.0 执行任意指定路径下的任意相关命名的python测试脚本
# 脚本实现:
import unittest
import requests
if __name__ == '__main__':
#**********************************************
#以文件的方式来进行框架的执行
#声明文件所在路径
testdir='./'
discover=unittest.defaultTestLoader.discover(testdir,pattern='test_updateser_v1.py')
#声明测试运行对象
runner=unittest.TextTestRunner()
runner.run(discover)4.5 按照测试顺序和是否运行来确定要执行哪些测试V5.0

其实框架难的地方也就是在驱动的处理这。
按照测试顺序和是否运行来确定要执行哪些测试
复杂程序的编写思路
分解任务,逐个击破
逐步合并,分段调试
脚本设计思路
突破点
python提供的数据字典的排序
脚本名
脚本路径
执行顺序
是相关的一组数据,不是无关的
import operator
sorted(数据字典,key=operator.itemgetter(下标或标签))

试验1
给定一些字典的具体数据
dic={"testA":3,"testC":1,"testB:4,"testD:2}
dicn=sorted(dic.items(),key=operator.itemgetter(1))
print(dicn)
for fn in dicn:
print(fn[0])
排序算法是否可行
试验2
把csv配置文件的一行内容导入到字典中
代码部分实现
file=open("D:\python\interfacefram\config\config4.csv","r")
table=csv.reader(file)
dic={}
listd=[]
line=0
for row in table:
if line>0:
跳过第一行
#把文件中读取的数据放入字典
dic={}
每读一行,字典清空一次
dic[row[1]]=row[0]
dic["num"]=int(row[3])
文件执行顺序
print("dicn",dicn)
试验3
把csv配置文件的多行内容导入到字典列表中
listd=[]
line=line+1
if dic!={}:
listd.append(dic)
dicn=sorted(listd,key=operator.itemgetter("num"))

试验4
检验读取顺序是否正确,能否正确执行
for i in range(0,line-1):
n=0
for content in dicn[i].items():
if n==0:
fname=content[0]
fdir=content[1]
print("fname",fname,"fdir",fdir)
# 调用脚本程序进行执行
discover = unittest.defaultTestLoader.discover(fdir, pattern=fname)
# # 定义一个运行对象
runner = unittest.TextTestRunner()
runner.run(discover)
n=n+1
试验5
加入对状态的判断
解决问题1
把状态内容也要追加到字典列表中
dic["state"]=row[2]
解决问题2
在确定执行前,把状态要取出来
从字典列表中取出
代码
if n==2:
state=content[1]
# print("state",state)
if state=="Yes":
# 调用脚本程序进行执行
print("最终运行的程序",fname)
discover = unittest.defaultTestLoader.discover(fdir, pattern=fname)
# # 定义一个运行对象
runner = unittest.TextTestRunner()
runner.run(discover)
列表字典
[{"testa":"d:\\sdfs","num":3,"state":"Yes"},{"testa":"d:\\sdfs","num":1,"state":"Yes"},{"testa":"d:\\sdfs","num":2,"state":"Yes"}]
# V5.0版本 把所有配置文件中的内容全部进行读取
#***********************************V5.0驱动脚本程序*******************************************************
import unittest
import csv
import operator
if __name__ == '__main__':
# 打开对应的配置文件进行读取
# 以只读方式打卡
file=open("D:\python\interfacefram\config\config4.csv","r")
table=csv.reader(file)
dic={}
listd=[]
# line=len(open("D:\python\interfacefram\config\config4.csv").readlines())
line=0
print(line)
for row in table:
print(row[0])
if line>0:
# 把文件中读取的数据放入字典
dic={}
dic[row[1]]=row[0]
dic["num"]=int(row[3])
#把脚本运行状态加入字典数据
dic["state"]=row[2]
print("dic",dic)
line=line+1
if dic!={}:
listd.append(dic)
# print(listd)
print("n行数=",line)
dicn=sorted(listd,key=operator.itemgetter("num"))
print("dicn",dicn)
for i in range(0,line-1):
n=0
for content in dicn[i].items():
if n==0:
print("content",content)
fname=content[0]
fdir=content[1]
print("fname",fname,"fdir",fdir)
if n==2:
print("content2", content)
state=content[1]
# print("state",state)
if state=="Yes":
# 调用脚本程序进行执行
print("最终运行的程序",fname)
discover = unittest.defaultTestLoader.discover(fdir, pattern=fname)
# # 定义一个运行对象
runner = unittest.TextTestRunner()
runner.run(discover)
n=n+15、接口测试的总结
5.1 自主框架总体框图设计

5.2 接口测试的得与失
1、从独立接口测试脚本->接口联调测试脚本->接口测试框架都是独立研发的,不仅该项目可以用,也可以移植复用到其他项目中。
2、测试框架的技术不仅可以用于接口测试,其他以python+unittest+自动化测试的项目都可以继续沿用,具有较强的通用性。
3、一定程度上降低了由于界面或需求不断变更而造成的测试脚本修改或返工。
4、接口测试开展的有些晚,建议今后的接口测试最好安排在接口代码完成后就可以开始。
5、接口测试的相关设计文档还不是很完备,建议进行完善,避免测试的误解和返工。
6、接口测试的联调设计需要产品和开发的配合,确保设计的联调流程和实际应用相一致。
5.3 接口测试工作流程总结
S1:解读接口设计,形成接口测试文档。
S2:使用postman工具快速学习接口并进行首轮接口冒烟测试。
S3:独立接口测试脚本的设计及研发。
S4:接口联调脚本的设计及研发。
S5:测试框架的设计及研发。
S6:接口测试工作的改进及优化
愿每个测试都能成为测试开发,提高职业技能,成为前1%的存在,为社会创造更大的价值,为公司节约更多的成本,为自己和家庭谋求更高的收入,所有人不受职业年龄限制,越老越吃香,直至财富自由;愿测试技术越来越进步,软件质量进一步得到提高,效率提高。愿祖国更加美好,人民更加幸福。多喜乐,常安宁。
拨云见日终有时,学无止境勤可达。