本文来源公众号“程序员学长”,仅用于学术分享,侵权删,干货满满。
原文链接:快速学习一个算法,GAN
GAN 如何工作?
GAN 由两个部分组成:生成器(Generator)和判别器(Discriminator)。这两个部分通过一种对抗的过程来相互改进和优化。
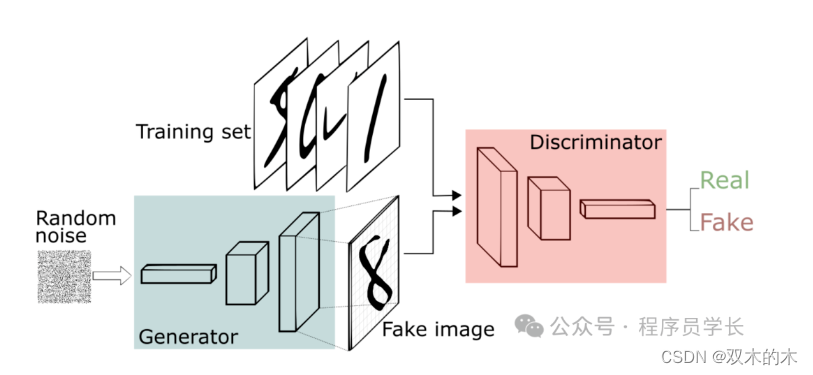
生成器(Generator)
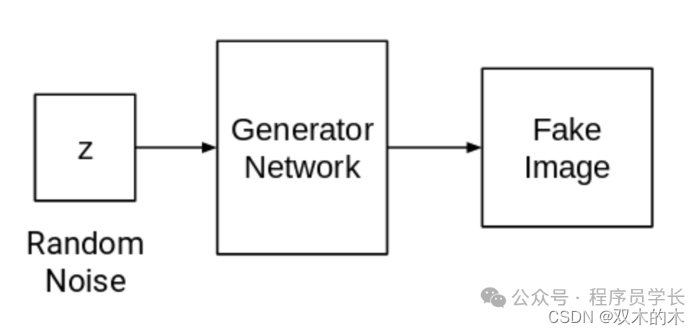
生成器的任务是接收一个随机噪声向量,并将其转换为看起来尽可能真实的数据。它通常使用一个深度神经网络来实现,从随机噪声中生成类似于训练数据的样本。
生成器的目标是生成的样本能够骗过判别器,使判别器认为生成的数据是真实的。
判别器(Discriminator)
判别器是一个二分类模型,它的任务是区分真实数据和生成器生成的假数据。
判别器接收一个数据样本,并输出一个概率值,表示该样本是真实数据的概率。
判别器的目标是尽可能准确地将真实数据与生成数据区分开来。
对抗过程
GAN 的训练过程可以被看作是生成器和判别器之间的博弈。具体来说,生成器试图生成逼真的数据以欺骗判别器,而判别器则试图更好地识别生成的假数据。
这个过程可以描述为一个最小最大化的优化问题。

鉴别器 D 想要最大化目标函数,使得 D(x) 接近于 1,D(G(z)) 接近于 0。这意味着鉴别器应该将训练集中的所有图像识别为真实 (1),将所有生成的图像识别为假 (0)。
生成器 (G) 想要最小化目标函数,使得 D(G(z)) 为 1。这意味着生成器试图生成被鉴别器网络分类为 1 的图像。
训练步骤
-
初始化生成器和判别器的参数
-
判别器训练
-
从真实数据集中采样一个 mini-batch 的真实数据。
-
从生成器的噪声分布中采样一个 mini-batch 的噪声,并生成假数据。
-
更新判别器的参数,使其能够更好地区分真实数据和生成数据。

-
-
生成器训练
-
从噪声分布中采样一个 mini-batch 的噪声,并生成假数据。
-
更新生成器的参数,使其生成的数据更能够欺骗判别器。
-
-
重复上述过程,直到生成器生成的数据足够逼真,判别器无法准确区分真实数据和生成数据。
GAN 在图像生成、图像修复、超分辨率、风格迁移、数据增强等领域有广泛应用。例如,通过 GAN,可以生成高分辨率的图像,将低分辨率图像转换为高分辨率图像,或者将某种风格的图像转换为另一种风格的图像。
案例分享
下面是使用 GAN 来生成图像的案例。这里我们以手写数字识别数据集为例进行说明。
1.读取数据集
from __future__ import print_function, division
from keras.datasets import mnist
from keras.layers import Input, Dense, Reshape, Flatten, Dropout
from keras.layers import BatchNormalization, Activation, ZeroPadding2D
from keras.layers import LeakyReLU
from keras.layers import UpSampling2D, Conv2D
from keras.models import Sequential, Model
from keras.optimizers import Adam, SGD
import matplotlib.pyplot as plt
import sys
import numpy as np
num_rows = 28
num_cols = 28
num_channels = 1
input_shape = (num_rows, num_cols, num_channels)
z_size = 100
batch_size = 32
(train_ims, _), (_, _) = mnist.load_data()
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))2.定义生成器
生成器 (D) 在 GAN 中扮演着至关重要的角色,因为它负责生成能够欺骗鉴别器的真实图像。
它是 GAN 中图像形成的主要组件。
在本文中,我们为生成器使用了一种特定的架构,该架构包含一个完全连接 (FC) 层并采用 Leaky ReLU 激活。然而,值得注意的是,生成器的最后一层使用 TanH 激活而不是 LeakyReLU。
def build_generator():
gen_model = Sequential()
gen_model.add(Dense(256, input_dim=z_size))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(512))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(1024))
gen_model.add(LeakyReLU(alpha=0.2))
gen_model.add(BatchNormalization(momentum=0.8))
gen_model.add(Dense(np.prod(input_shape), activation='tanh'))
gen_model.add(Reshape(input_shape))
gen_noise = Input(shape=(z_size,))
gen_img = gen_model(gen_noise)
return Model(gen_noise, gen_img)3.定义鉴别器
在生成对抗网络 (GAN) 中,鉴别器 (D) 通过评估真实性和可能性来执行区分真实图像和生成图像的关键任务。
此组件可以看作是一个二元分类问题。
为了解决此任务,我们可以采用一个简化的网络架构,该架构由全连接层 (FC)、Leaky ReLU 激活和 Dropout 层组成。值得一提的是,鉴别器的最后一层包括 FC 层,后跟 Sigmoid 激活。Sigmoid 激活函数产生所需的分类概率。
def build_discriminator():
disc_model = Sequential()
disc_model.add(Flatten(input_shape=input_shape))
disc_model.add(Dense(512))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(256))
disc_model.add(LeakyReLU(alpha=0.2))
disc_model.add(Dense(1, activation='sigmoid'))
disc_img = Input(shape=input_shape)
validity = disc_model(disc_img)
return Model(disc_img, validity)4.计算损失函数
我们可以使用二元交叉熵损失来实现生成器和鉴别器。
# discriminator
disc= build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
z = Input(shape=(z_size,))
# generator
img = generator(z)
disc.trainable = False
validity = disc(img)
# combined model
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')5.优化损失
def intialize_model():
disc= build_discriminator()
disc.compile(loss='binary_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
generator = build_generator()
z = Input(shape=(z_size,))
img = generator(z)
disc.trainable = False
validity = disc(img)
combined = Model(z, validity)
combined.compile(loss='binary_crossentropy', optimizer='sgd')
return disc, generator, combined6. 模型训练
def train(epochs, batch_size=128, sample_interval=50):
# load images
(train_ims, _), (_, _) = mnist.load_data()
# preprocess
train_ims = train_ims / 127.5 - 1.
train_ims = np.expand_dims(train_ims, axis=3)
valid = np.ones((batch_size, 1))
fake = np.zeros((batch_size, 1))
# training loop
for epoch in range(epochs):
batch_index = np.random.randint(0, train_ims.shape[0], batch_size)
imgs = train_ims[batch_index]
# create noise
noise = np.random.normal(0, 1, (batch_size, z_size))
# predict using a Generator
gen_imgs = gen.predict(noise)
# calculate loss functions
real_disc_loss = disc.train_on_batch(imgs, valid)
fake_disc_loss = disc.train_on_batch(gen_imgs, fake)
disc_loss_total = 0.5 * np.add(real_disc_loss, fake_disc_loss)
noise = np.random.normal(0, 1, (batch_size, z_size))
g_loss = full_model.train_on_batch(noise, valid)
# save outputs every few epochs
if epoch % sample_interval == 0:
one_batch(epoch)7.生成手写数字
使用 MNIST 数据集,我们可以创建一个实用函数,使生成器为一组图像生成预测。
此函数生成随机声音,将其提供给生成器,运行它以显示生成的图像并将其保存在特殊文件夹中。建议定期运行此实用函数,例如每 200 个周期运行一次,以监控网络进度。
def one_batch(epoch):
r, c = 5, 5
noise_model = np.random.normal(0, 1, (r * c, z_size))
gen_images = gen.predict(noise_model)
# Rescale images 0 - 1
gen_images = gen_images*(0.5) + 0.5
fig, axs = plt.subplots(r, c)
cnt = 0
for i in range(r):
for j in range(c):
axs[i,j].imshow(gen_images[cnt, :,:,0], cmap='gray')
axs[i,j].axis('off')
cnt += 1
fig.savefig("images/%d.png" % epoch)
plt.close()在我们的实验中,我们使用 32 的批次大小对 GAN 进行了大约 10,000 个时期的训练。
为了跟踪训练的进度,我们每 200 个时期保存一次生成的图像,并将它们存储在名为 “images” 的指定文件夹中。
disc, gen, full_model = intialize_model()
train(epochs=10000, batch_size=32, sample_interval=200)现在,我们来检查一下不同阶段的 GAN 模拟结果。
初始化、5000 个 epoch 以及 10000 个 epoch 的最终结果。
最初,我们以随机噪声作为生成器的输入。

经过 5000 个时期的训练后,我们可以观察到生成的图形开始类似于 MNIST 数据集。

经过 10,000 个时期的训练后,我们获得以下输出。

可以看到,这些生成的图像与手写数字数据已经非常相似了。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。












![[激光原理与应用-109]:南京科耐激光-激光焊接-焊中检测-智能制程监测系统IPM介绍 - 12 - 焊接工艺之影响焊接效果的因素](https://i-blog.csdnimg.cn/direct/090756fef633402a80d0b6f2414d1c9b.png)



![[GHCTF 2024 新生赛]ezzz_unserialize](https://img-blog.csdnimg.cn/img_convert/473c5921f287dc6e9469bfde25d833dd.png)
