文章目录
- 1 RNN 的定义
- 2 RNN 输入 input, h_0
- 3 RNN 输出 output, h_n
- 4 多层
- 5 小试牛刀
学习参考来自
- pytorch中nn.RNN()总结
- RNN for Image Classification(RNN图片分类–MNIST数据集)
- pytorch使用-nn.RNN
1 RNN 的定义
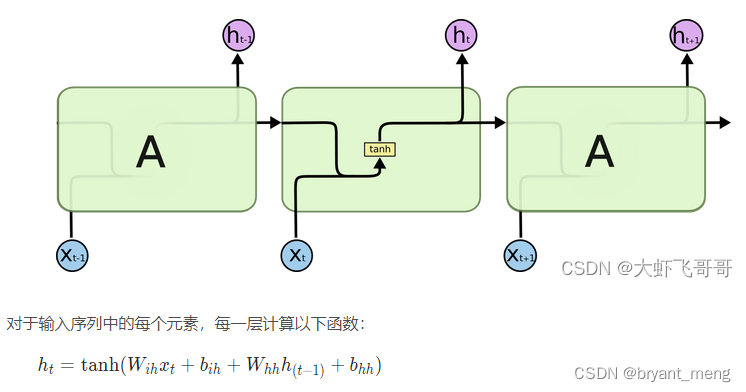
nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity=tanh, bias=True, batch_first=False, dropout=0, bidirectional=False)
参数说明
- input_size输入特征的维度, 一般 rnn 中输入的是词向量,那么 input_size 就等于一个词向量的维度
- hidden_size隐藏层神经元个数,或者也叫输出的维度(因为rnn输出为各个时间步上的隐藏状态)
- num_layers网络的层数
- nonlinearity激活函数
- bias是否使用偏置
- batch_first输入数据的形式,默认是 False,就是这样形式,(seq(num_step), batch, input_dim),也就是将序列长度放在第一位,batch 放在第二位
- dropout是否应用dropout, 默认不使用,如若使用将其设置成一个0-1的数字即可
- birdirectional是否使用双向的 rnn,默认是 False
2 RNN 输入 input, h_0
input 形状: 当设置 batch_first = False 时, ( L , N , H i n ) (L , N , H_{ i n}) (L,N,Hin) —— [时间步数, 批量大小, 特征维度]
当设置 batch_first = True时, ( N , L , H i n ) (N , L , H_{ i n}) (N,L,Hin)
当输入只有两个维度且 batch_size 为 1 时 :( L , H i n ) (L, H_{in})(L,H in ) 时,需要调用 torch.unsqueeze() 增加维度。
h_0 形状: ( D ∗ n u m _ l a y e r s , N , H o u t ) ( D ∗ n u m \_ l a y e r s , N , H _{o u t} ) (D∗num_layers,N,Hout), D 代表单向 RNN 还是双向 RNN。

3 RNN 输出 output, h_n
output 形状:当设置 batch_first = False 时,
(
L
,
N
,
D
∗
H
o
u
t
)
(L, N, D * H_{out})
(L,N,D∗Hout)—— [时间步数, 批量大小, 隐藏单元个数];
当设置 batch_first = True 时,
(
N
,
L
,
D
∗
H
o
u
t
)
(N, L, D * H_{out})
(N,L,D∗Hout)。
h_n 形状:
(
D
∗
num_layers
,
N
,
H
o
u
t
)
(D * \text{num\_layers}, N, H_{out})
(D∗num_layers,N,Hout)
4 多层
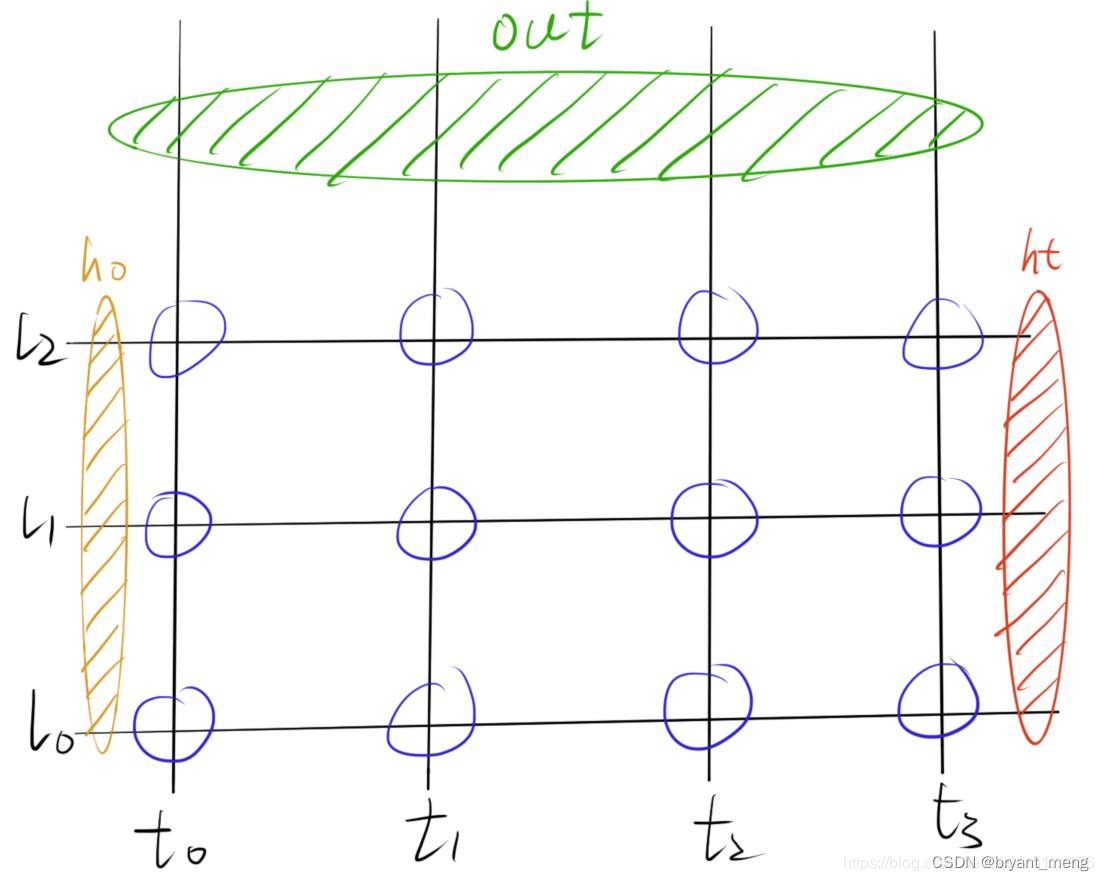
5 小试牛刀
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import numpy as np
import matplotlib.pyplot as plt
# -------------
# MNIST dataset
# -------------
batch_size = 128
train_dataset = torchvision.datasets.MNIST(root='./',
train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = torchvision.datasets.MNIST(root='./',
train=False,
transform=transforms.ToTensor())
# Data loader
train_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False)
# ---------------------
# Exploring the dataset
# ---------------------
# function to show an image
def imshow(img):
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
# get some random training images
dataiter = iter(train_loader)
images, labels = dataiter.next()
if 1:
# show image
imshow(torchvision.utils.make_grid(images, nrow=15))
plt.show()
# ----------
# parameters
# ----------
N_STEPS = 28
N_INPUTS = 28 # 输入数据的维度
N_NEURONS = 150 # RNN中间的特征的大小
N_OUTPUT = 10 # 输出数据的维度(分类的个数)
N_EPHOCS = 10 # epoch的大小
N_LAYERS = 3
# ------
# models
# ------
class ImageRNN(nn.Module):
def __init__(self, batch_size, n_inputs, n_neurons, n_outputs, n_layers):
super(ImageRNN, self).__init__()
self.batch_size = batch_size # 输入的时候batch_size, 128
self.n_inputs = n_inputs # 输入的维度, 28
self.n_outputs = n_outputs # 分类的大小 10
self.n_neurons = n_neurons # RNN中输出的维度 150
self.n_layers = n_layers # RNN中的层数 3
self.basic_rnn = nn.RNN(self.n_inputs, self.n_neurons, num_layers=self.n_layers)
self.FC = nn.Linear(self.n_neurons, self.n_outputs)
def init_hidden(self):
# (num_layers, batch_size, n_neurons)
# initialize hidden weights with zero values
# 这个是net的memory, 初始化memory为0
return (torch.zeros(self.n_layers, self.batch_size, self.n_neurons).to(device))
def forward(self, x): # torch.Size([128, 28, 28])
# transforms x to dimensions : n_step × batch_size × n_inputs
x = x.permute(1, 0, 2) # 需要把n_step放在第一个, torch.Size([28, 128, 28])
self.batch_size = x.size(1) # 每次需要重新计算batch_size, 因为可能会出现不能完整方下一个batch的情况 128
self.hidden = self.init_hidden() # 初始化hidden state torch.Size([3, 128, 150])
rnn_out, self.hidden = self.basic_rnn(x, self.hidden) # 前向传播 torch.Size([28, 128, 150]), torch.Size([3, 128, 150])
out = self.FC(rnn_out[-1]) # 求出每一类的概率 torch.Size([128, 150])->torch.Size([128, 10])
return out.view(-1, self.n_outputs) # 最终输出大小 : batch_size X n_output torch.Size([128, 10])
# --------------------
# Device configuration
# --------------------
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# ------------------------------------
# Test the model(输入一张图片查看输出)
# ------------------------------------
# 定义模型
model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
print(model)
"""
ImageRNN(
(basic_rnn): RNN(28, 150, num_layers=3)
(FC): Linear(in_features=150, out_features=10, bias=True)
)
"""
# 初始化模型的weight
model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
# 定义数据
dataiter = iter(train_loader)
images, labels = dataiter.next()
model.hidden = model.init_hidden()
logits = model(images.view(-1, 28, 28).to(device))
print(logits[0:2])
"""
tensor([[-0.2846, -0.1503, -0.1593, 0.5478, 0.6827, 0.3489, -0.2989, 0.4575,
-0.2426, -0.0464],
[-0.6708, -0.3025, -0.0205, 0.2242, 0.8470, 0.2654, -0.0381, 0.6646,
-0.4479, 0.2523]], device='cuda:0', grad_fn=<SliceBackward>)
"""
# 产生对角线是1的矩阵
torch.eye(n=5, m=5, out=None)
"""
tensor([[1., 0., 0., 0., 0.],
[0., 1., 0., 0., 0.],
[0., 0., 1., 0., 0.],
[0., 0., 0., 1., 0.],
[0., 0., 0., 0., 1.]])
"""
# --------
# Training
# --------
model = ImageRNN(batch_size, N_INPUTS, N_NEURONS, N_OUTPUT, N_LAYERS).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 初始化模型的weight
model.basic_rnn.weight_hh_l0.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l1.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
model.basic_rnn.weight_hh_l2.data = torch.eye(n=N_NEURONS, m=N_NEURONS, out=None).to(device)
def get_accuracy(logit, target, batch_size):
"""最后用来计算模型的准确率
"""
corrects = (torch.max(logit, 1)[1].view(target.size()).data == target.data).sum()
accuracy = 100.0 * corrects/batch_size
return accuracy.item()
# ---------
# 开始训练
# ---------
for epoch in range(N_EPHOCS):
train_running_loss = 0.0
train_acc = 0.0
model.train()
# trainging round
for i, data in enumerate(train_loader):
optimizer.zero_grad()
# reset hidden states
model.hidden = model.init_hidden()
# get inputs
inputs, labels = data
inputs = inputs.view(-1, 28, 28).to(device)
labels = labels.to(device)
# forward+backward+optimize
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_running_loss = train_running_loss + loss.detach().item()
train_acc = train_acc + get_accuracy(outputs, labels, batch_size)
model.eval()
print('Epoch : {:0>2d} | Loss : {:<6.4f} | Train Accuracy : {:<6.2f}%'.format(epoch, train_running_loss/i, train_acc/i))
# ----------------------------------------
# Computer accuracy on the testing dataset
# ----------------------------------------
test_acc = 0.0
for i,data in enumerate(test_loader,0):
inputs, labels = data
labels = labels.to(device)
inputs = inputs.view(-1,28,28).to(device)
outputs = model(inputs)
thisBatchAcc = get_accuracy(outputs, labels, batch_size)
print("Batch:{:0>2d}, Accuracy : {:<6.4f}%".format(i,thisBatchAcc))
test_acc = test_acc + thisBatchAcc
print('============平均准确率===========')
print('Test Accuracy : {:<6.4f}%'.format(test_acc/i))
"""
Epoch : 00 | Loss : 0.6336 | Train Accuracy : 79.32 %
Epoch : 01 | Loss : 0.2363 | Train Accuracy : 93.00 %
Epoch : 02 | Loss : 0.1852 | Train Accuracy : 94.63 %
Epoch : 03 | Loss : 0.1516 | Train Accuracy : 95.69 %
Epoch : 04 | Loss : 0.1338 | Train Accuracy : 96.13 %
Epoch : 05 | Loss : 0.1198 | Train Accuracy : 96.67 %
Epoch : 06 | Loss : 0.1254 | Train Accuracy : 96.46 %
Epoch : 07 | Loss : 0.1128 | Train Accuracy : 96.88 %
Epoch : 08 | Loss : 0.1059 | Train Accuracy : 97.09 %
Epoch : 09 | Loss : 0.1048 | Train Accuracy : 97.10 %
Batch:00, Accuracy : 98.4375%
Batch:01, Accuracy : 98.4375%
Batch:02, Accuracy : 95.3125%
Batch:03, Accuracy : 98.4375%
Batch:04, Accuracy : 96.8750%
Batch:05, Accuracy : 93.7500%
Batch:06, Accuracy : 97.6562%
Batch:07, Accuracy : 95.3125%
Batch:08, Accuracy : 94.5312%
Batch:09, Accuracy : 92.9688%
Batch:10, Accuracy : 96.0938%
Batch:11, Accuracy : 96.0938%
Batch:12, Accuracy : 97.6562%
Batch:13, Accuracy : 96.8750%
Batch:14, Accuracy : 96.0938%
Batch:15, Accuracy : 95.3125%
Batch:16, Accuracy : 95.3125%
Batch:17, Accuracy : 96.0938%
Batch:18, Accuracy : 96.0938%
Batch:19, Accuracy : 97.6562%
Batch:20, Accuracy : 97.6562%
Batch:21, Accuracy : 98.4375%
Batch:22, Accuracy : 96.0938%
Batch:23, Accuracy : 96.8750%
Batch:24, Accuracy : 97.6562%
Batch:25, Accuracy : 99.2188%
Batch:26, Accuracy : 96.0938%
Batch:27, Accuracy : 94.5312%
Batch:28, Accuracy : 98.4375%
Batch:29, Accuracy : 94.5312%
Batch:30, Accuracy : 96.0938%
Batch:31, Accuracy : 93.7500%
Batch:32, Accuracy : 96.8750%
Batch:33, Accuracy : 96.0938%
Batch:34, Accuracy : 95.3125%
Batch:35, Accuracy : 96.8750%
Batch:36, Accuracy : 97.6562%
Batch:37, Accuracy : 93.7500%
Batch:38, Accuracy : 94.5312%
Batch:39, Accuracy : 100.0000%
Batch:40, Accuracy : 99.2188%
Batch:41, Accuracy : 100.0000%
Batch:42, Accuracy : 98.4375%
Batch:43, Accuracy : 98.4375%
Batch:44, Accuracy : 96.8750%
Batch:45, Accuracy : 99.2188%
Batch:46, Accuracy : 96.0938%
Batch:47, Accuracy : 98.4375%
Batch:48, Accuracy : 97.6562%
Batch:49, Accuracy : 100.0000%
Batch:50, Accuracy : 99.2188%
Batch:51, Accuracy : 91.4062%
Batch:52, Accuracy : 96.8750%
Batch:53, Accuracy : 99.2188%
Batch:54, Accuracy : 99.2188%
Batch:55, Accuracy : 100.0000%
Batch:56, Accuracy : 98.4375%
Batch:57, Accuracy : 98.4375%
Batch:58, Accuracy : 97.6562%
Batch:59, Accuracy : 100.0000%
Batch:60, Accuracy : 99.2188%
Batch:61, Accuracy : 96.0938%
Batch:62, Accuracy : 100.0000%
Batch:63, Accuracy : 97.6562%
Batch:64, Accuracy : 97.6562%
Batch:65, Accuracy : 96.8750%
Batch:66, Accuracy : 98.4375%
Batch:67, Accuracy : 100.0000%
Batch:68, Accuracy : 100.0000%
Batch:69, Accuracy : 100.0000%
Batch:70, Accuracy : 96.8750%
Batch:71, Accuracy : 98.4375%
Batch:72, Accuracy : 100.0000%
Batch:73, Accuracy : 99.2188%
Batch:74, Accuracy : 100.0000%
Batch:75, Accuracy : 96.0938%
Batch:76, Accuracy : 95.3125%
Batch:77, Accuracy : 96.8750%
Batch:78, Accuracy : 12.5000%
============平均准确率===========
Test Accuracy : 97.4559%
# """
# 定义hook
class SaveFeatures():
"""注册hook和移除hook
"""
def __init__(self, module):
self.hook = module.register_forward_hook(self.hook_fn)
def hook_fn(self, module, input, output):
self.features = output
def close(self):
self.hook.remove()
# 绑定到model上
activations = SaveFeatures(model.basic_rnn)
# 定义数据
dataiter = iter(train_loader)
images, labels = dataiter.next()
# 前向传播
model.hidden = model.init_hidden()
logits = model(images.view(-1, 28, 28).to(device))
activations.close() # 移除hook
# 这个是 28(step)*128(batch_size)*150(hidden_size)
print(activations.features[0].shape)
# torch.Size([28, 128, 150])
print(activations.features[0][-1].shape)
# torch.Size([128, 150])