文章汇总
动机

效果如上:希望将多个任务训练得到的LoRA组合起来,效果比单独一个任务得到的LoRA效果更好。
愿景:那未来我们每个人都贡献出自己训练出来的LoRA,之后通过LoRAHub简单组合起来,就可以得到适用于多任务且功能强大的LoRA。
解决办法
组成办法:
每个LoRA结构为
m
i
=
A
i
B
i
,
i
=
1
,
.
.
.
,
N
m_i=A_iB_i,i=1,...,N
mi=AiBi,i=1,...,N,组合后的LoRA模块
m
^
\hat m
m^可得:
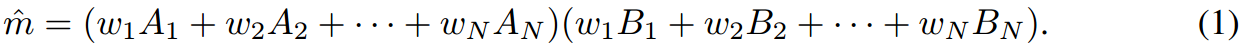
权重如何得到?
理论上,不同的LoRA
m
i
m_i
mi对不同下游的任务的重要程度是不同,所以如何合理地对LoRA
m
i
m_i
mi授予相应的权重就很重要了。
作者采用了无梯度的种群的随机优化算法——协方差矩阵自适应进化策略(CMA-ES)。(作者在论文上没介绍,我翻阅了文献发觉很劝退┭┮﹏┭┮,希望得到好心人指导(*❦ω❦))
优化目标是最小化
L
+
α
⋅
∑
i
=
1
N
∣
w
i
∣
L+\alpha\cdot\sum^N_{i=1}|w_i|
L+α⋅∑i=1N∣wi∣,其中
α
\alpha
α作为超参数。
摘要
低秩适应(Low-rank adaptations,LoRA)通常用于为新任务微调大型语言模型(LLM)。本文研究了跨任务泛化的LoRA可组合性,并介绍了LoraHub,这是一个简单的框架,用于有目的地组装在不同给定任务上训练的LoRA模块,目的是在未知任务上实现自适应性能。只需新任务中的几个示例,LoraHub就可以流畅地组合多个LoRA模块,从而消除了对人工专业知识和假设的需求。值得注意的是,该组合既不需要额外的模型参数,也不需要梯度。Big-Bench Hard基准测试的实证结果表明,LoraHub虽然没有超越上下文学习的性能,但通过在推理过程中显著减少每个示例的令牌数量,在小样本学习场景中提供了显著的性能效率权衡。值得注意的是,当与不同的演示示例配对时,LoraHub与上下文学习相比建立了更好的上限,显示了其未来发展的潜力。我们的愿景是建立一个LoRA模块的平台,使用户能够分享他们训练有素的LoRA模块。这种协作方法促进了LoRA模块在新任务中的无缝应用,有助于形成自适应生态系统。我们的代码可在https://github.com/sail-sg/lorahub上获得,所有预训练的LoRA模块都在https://huggingface.co/lorahub上发布。
1.介绍
自然语言处理(NLP)的最新进展在很大程度上是由大型语言模型(LLM)推动的,如OpenAI GPT (Brown等人,2020)、FLAN-T5 (Chung等人,2022)和LLaMA (Touvron等人,2023)。这些模型展示了不同NLP任务的顶级性能。然而,它们巨大的参数大小在微调期间带来了计算效率和内存使用方面的问题。为了缓解这些挑战,低秩适应(Low-Rank Adaptation, LoRA) (Hu et al ., 2022)已经成为一种参数高效的微调技术(Lester et al ., 2021;他等人,2022;An et al, 2022)。通过减少内存需求和计算成本,它加快了LLM的训练。LoRA通过冻结基本模型参数(即LLM)和训练轻量级模块来实现这一点,该模块定期在目标任务上提供高性能。
虽然先前的研究针对的是LoRA促进的效率提高,但缺乏对LoRA模块固有的模块化和可组合性的研究。通常,以前的方法训练LoRA模块专门处理单个任务。然而,LoRA模块固有的模块化提出了一个有趣的研究问题:是否有可能组合LoRA模块以有效的方式推广到新的任务?在本文中,我们挖掘了LoRA模块化在广泛任务泛化方面的潜力,超越了单任务训练,精心组合LoRA模块,以在未知任务上获得可扩展的性能。至关重要的是,我们的方法能够自动组装LoRA模块,消除对手动设计或人工专业知识的依赖。仅使用来自新任务的少量示例(例如,5),我们的方法就可以自主地组成兼容的LoRA模块,而无需人工干预。我们不假设在特定任务上训练的LoRA模块可以组合在一起,允许灵活地合并任何模块,只要它们符合规范(例如,使用相同的LLM)。由于我们的方法利用了几个可用的LoRA模块,我们将其称为LoraHub,并将我们的学习方法表示为LoraHub学习。
为了验证我们提出的方法的效率,我们使用广泛认可的BBH基准测试我们的方法,FLAN-T5 (Chung et al ., 2022)作为基础LLM。结果强调了通过少量的LoraHub学习过程,LoRA模块组成对于不熟悉的任务的有效性。值得注意的是,我们的方法实现了与上下文中少数镜头学习密切匹配的平均性能,同时展示了优越的上限,特别是在使用不同的演示示例时。此外,与上下文学习相比,我们的方法大大降低了推理成本,消除了LLM对示例作为输入的要求。在推理过程中,由于每个示例的令牌更少,我们的方法显著降低了计算开销并实现了更快的响应。它与更广泛的研究趋势相一致,最近的研究正在积极探索减少输入令牌数量的方法(Zhou等人,2023;Ge等,2023;Chevalier等,2023;蒋等,2023a;Li et al ., 2023;Jiang et al ., 2023b)。我们的学习过程也以其计算效率而闻名,使用无梯度方法获得LoRA模块的系数,并且只需要少量的推理步骤来处理未见任务。例如,当应用于BBH中的新任务时,我们的方法可以在不到一分钟的时间内使用单个A100卡提供卓越的性能。
重要的是,LoraHub学习可以用一台只有cpu的机器来完成,只需要熟练地处理LLM推理。在我们追求人工智能民主化的过程中,我们设想建立LoRA平台,这是向前迈出的重要一步。该平台将作为一个市场,用户可以无缝地共享和访问各种应用程序的训练有素的LoRA模块。LoRA提供商可以灵活地在平台上自由共享或销售其模块,而不会损害数据隐私。配备CPU功能的用户可以利用其他人通过自动分发和组合算法提供的训练有素的LoRA模块。该平台不仅培养了具有无数功能的可重用LoRA模块的存储库,而且还为协作AI开发奠定了基础。它使社区能够通过动态LoRA组合来共同丰富LLM的功能。
3.方法
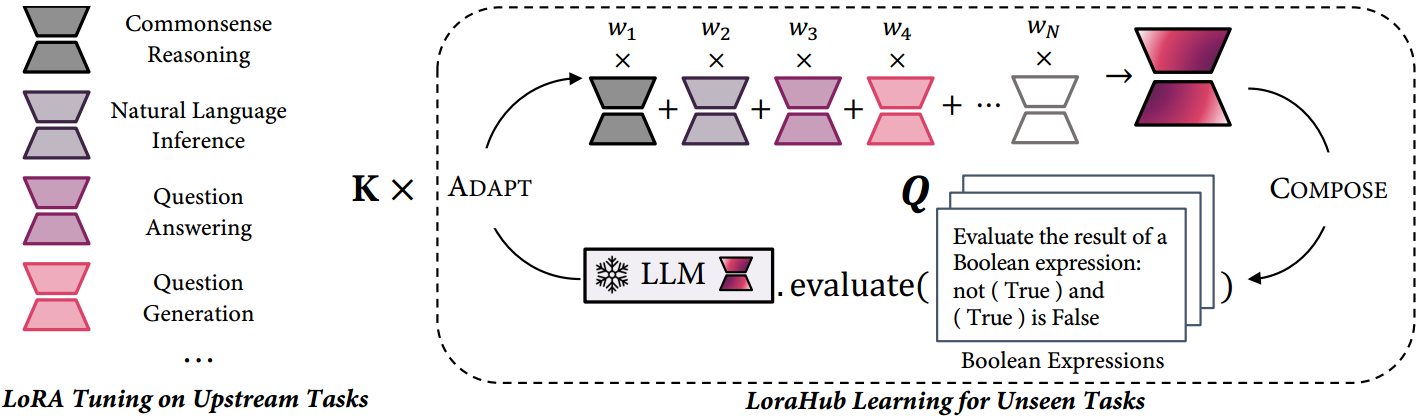
在本节中,我们概述了我们提出的方法。然后详细解释LoRA调优过程。最后,介绍了LoraHub的学习过程,包括COMPOSE阶段和ADAPT阶段。
图2:我们的方法包含两个阶段:COMPOSE阶段和ADAPT阶段。在COMPOSE阶段,现有的LoRA模块被集成为一个统一的模块,使用一组系数,记为
w
w
w。在ADAPT阶段,组合的LoRA模块对未见任务中的几个示例进行评估。随后,采用无梯度算法对
w
w
w进行细化。在执行K次迭代后,产生一个高度适应的组合LoRA模块,该模块可以与LLM合并以执行预期的任务。
3.1方法概述
如图2所示,我们最初在各种上游任务上训练LoRA模块。具体来说,对于 N N N个不同的上游任务,我们分别训练 N N N个LoRA模块,对于任务 τ i ∈ T \tau_i \in T τi∈T,每个模块表示为mi。随后,对于新任务 τ i ′ ∉ T \tau_i' \notin T τi′∈/T,如图2所示的布尔表达式,我们利用其示例 Q Q Q来引导LoraHub的学习过程。LoraHub学习封装了两个主要阶段:COMPOSE阶段和ADAPT阶段。在COMPOSE阶段,使用 { w 1 , w 2 , . . . , w N } \{w_1,w_2,...,w_N\} {w1,w2,...,wN}将所有可用的LoRA模块组合成单个集成模块 m ^ \hat m m^。每个 w i w_i wi都是一个标量值,可以取正值或负值,并且可以通过不同的方式进行组合。在ADAPT阶段,将合并后的LoRA模块 m ^ \hat m m^与LLM M θ M_{\theta} Mθ合并,并对其在新任务 τ ′ \tau' τ′的少量样本上的性能进行了评估。随后部署无梯度算法来更新 w w w,增强 m ^ \hat m m^在少量样本 Q Q Q上的性能(例如,损失)。最后,迭代 K K K步后,将性能最佳的LoRA模块应用于LLM M θ M_{\theta} Mθ,得到最终的LLM M ϕ = LoRA ( M θ , m ^ ) M_{\phi}=\text{LoRA}(M_{\theta},\hat m) Mϕ=LoRA(Mθ,m^)。这将作为未见任务 τ ′ \tau' τ′的有效调整模型,然后将部署它,不再更新它。
3.2上游任务的LoRA调优
LoRA通过将LLM(记为 W 0 ∈ R d × k W_0\in R^{d\times k} W0∈Rd×k)的关注权矩阵更新分解为低秩矩阵的过程,有效地减少了可训练参数的数量。更具体地说,LoRA以 W 0 + δ W 0 + A B , A ∈ R d × r , B ∈ R r × k W_0+\delta W_0+AB,A\in R^{d\times r},B\in R^{r\times k} W0+δW0+AB,A∈Rd×r,B∈Rr×k的形式展示了更新后的权重矩阵,其中 A ∈ R d × r A\in R^{d\times r} A∈Rd×r和 B ∈ R r × k B\in R^{r\times k} B∈Rr×k是秩为 r r r的可训练低秩矩阵,其维数明显小于 d d d和 k k k。在这种情况下, A B AB AB定义了LoRA模块 m m m,如前面所述。通过利用低秩分解,LoRA大大减少了微调期间调整LLMs权重所需的可训练参数的数量。
3.3 Compose:按元素组合LoRA模块
在COMPOSE阶段,我们实现了一个元素方法来组合LoRA模块。该流程对LoRA模块的相应参数进行整合,要求被合并模块的等级r相同,以使其结构正确对齐。令
m
i
=
A
i
B
i
m_i=A_iB_i
mi=AiBi,则组合后的LoRA模块
m
^
\hat m
m^可得:
值得注意的是,正如我们在第5节中所展示的,一次组合太多的LoRA模块会以指数方式扩展搜索空间,这可能会破坏LoraHub学习过程的稳定性,并妨碍最佳性能。为了缓解这种情况,我们采用随机选择来修剪候选空间,未来可以探索更先进的预滤波算法。
3.4 ADAPT:通过无梯度方法进行权重优化
在ADAPT阶段,我们的目标是修改系数
w
w
w,以提高模型对来自未知任务的示例的性能。人们可能会考虑使用梯度下降来优化
w
w
w,遵循标准的反向传播方法。然而,这种方法需要为所有LoRA模块构建一个超网络,类似于可微架构搜索方法(Zhang et al, 2019)。构建这些超级网络需要大量的GPU内存和时间,这是一个挑战。考虑
w
w
w由相对较少的参数组成,我们选择无梯度方法进行优化,而不是梯度下降。
受先前工作(Sun et al, 2022)的启发,我们利用黑盒优化技术来找到最优
w
w
w。优化过程由交叉熵损失引导,设定目标来定位最佳集
{
w
1
,
w
2
,
.
.
.
,
w
N
}
\{w_1,w_2,...,w_N\}
{w1,w2,...,wN},减少了少量样本
Q
Q
Q上的损失
L
L
L。此外,我们采用L1正则化来惩罚
w
w
w的绝对值之和,有助于防止获得极值。因此,LoraHub的最终目标是最小化
L
+
α
⋅
∑
i
=
1
N
∣
w
i
∣
L+\alpha\cdot\sum^N_{i=1}|w_i|
L+α⋅∑i=1N∣wi∣,其中
α
\alpha
α作为超参数。
在无梯度方法方面,我们利用了组合优化方法Shiwa (Liu et al ., 2020)。Shiwa提供了多种算法,并根据不同的情况选择最适合的优化算法。在大多数即将到来的实验设置中,我们主要采用协方差矩阵自适应进化策略(CMA-ES) (Hansen & Ostermeier, 1996)。CMA-ES作为一种基于种群的随机优化算法,在解决广泛的优化挑战方面具有通用性。它动态地调整搜索分布,该分布由协方差矩阵定义。在每次迭代中,CMA-ES系统地更新该分布的均值和协方差,以优化目标函数。在我们的应用程序中,我们使用该算法来塑造
w
w
w的搜索空间。最终,我们使用它来识别最优的
w
w
w,通过评估它们在一个看不见的任务中的少数几个例子上的性能。
(疑点:协方差矩阵自适应进化策略(CMA-ES))
5.实验分析
在本节中,我们将彻底检查我们提出的方法的特点,并揭示几个有见地的发现。如果没有指定,我们使用FLAN-T5-large进行所有分析。
哪些LoRA模块对BBH任务最有效?
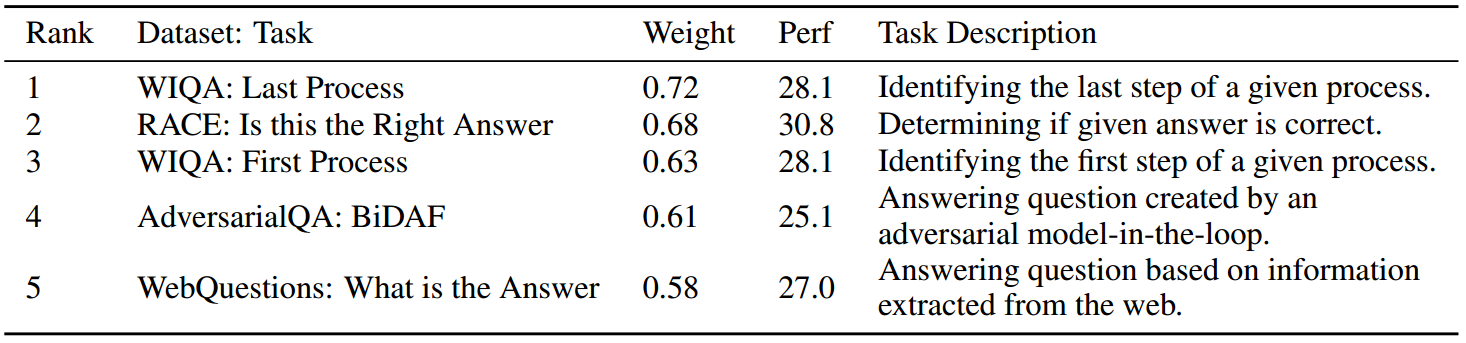
表2:对BBH任务最有利的5个LoRA模块及其关联的上游任务、所有BBH任务的平均权重值和平均性能。
我们假设LoRA模块的合并可以包含来自各种特定任务的技能和见解。为了评估这一点,我们检查了单个LoRA模块在BBH基准的所有任务中的影响程度。我们通过计算平均绝对权重来衡量每个孤立任务的影响。表2所示的前五个模块具有重大影响,正如它们的最大平均权重所示,这表明它们在跨任务转移方面明显更有效。值得注意的是,前五大模块的一个共同特征是,它们与需要阅读理解和推理技能的任务有关,这些特征表明了更高的认知复杂性。然而,值得注意的是,没有一个模块在所有BBH任务中表现出一致的改进,这反映在它们在所有BBH任务中的平均性能上,与原始FLAN-T5-large相比,除了Rank 2外,没有显示出显著的改进。结果强调了在LoraHub中组合不同模块的优势。
无梯度优化方法的有效性如何?
为了评估我们的无梯度优化方法在正确识别给定下游任务最合适的LoRA模块方面的有效性,我们使用WikiTableQuestions (Pasupat & Liang, 2015) (WTQ)数据集进行了实证研究。我们战略性地将一个专门在WTQ数据集上训练的LoRA模块包含到我们的LoRA候选模块池中,该模块最初源于Flan Collection独有的任务。随后,我们将WTQ指定为目标下游任务,并按照LoraHub学习中使用的方法计算权重。最终,特定于wtq的LoRA模块获得了最高的权重,这说明该算法成功地将其识别为最相关的模块。此外,组合LoRA模块比WTQ LoRA模块显示出边际优势。这强调了无梯度优化方法能够熟练地为未知任务选择最优的上游LoRA模块的主张。
LoraHub能在非指令调优模型上很好地工作吗?
在之前的调查中,我们主要关注的是通过指令调优训练的具有zero-shot能力的模型。然而,对于像T5这样没有zero-shot能力的模型,训练对参数的影响更大,目前尚不清楚LoraHub是否仍然可以有效地管理和改进它们。我们的实验表明,尽管这些模型的表现比FLANT5差,但LoraHub学习仍然可以使它们有效地泛化到看不见的任务。详见附录B。
LoRA模块的秩是否会影响LoraHub学习的性能?
参数秩在LoRA框架中起着至关重要的作用,直接影响LoRA调优过程中使用的可训练参数的数量。这引发了一个有趣的问题秩的变化是否会影响在LoraHub学习中观察到的结果?我们的分析表明,对于FLAN-T5,排名的选择影响最小。然而,对于T5来说,它仍然有一定的影响。实证结果表明,与秩4或64相比,秩为16在不同的运行中始终表现出卓越的性能,无论是在平均值还是最优值方面。其他结果见附录B。
更多的LoRA模块会带来更好的结果吗?
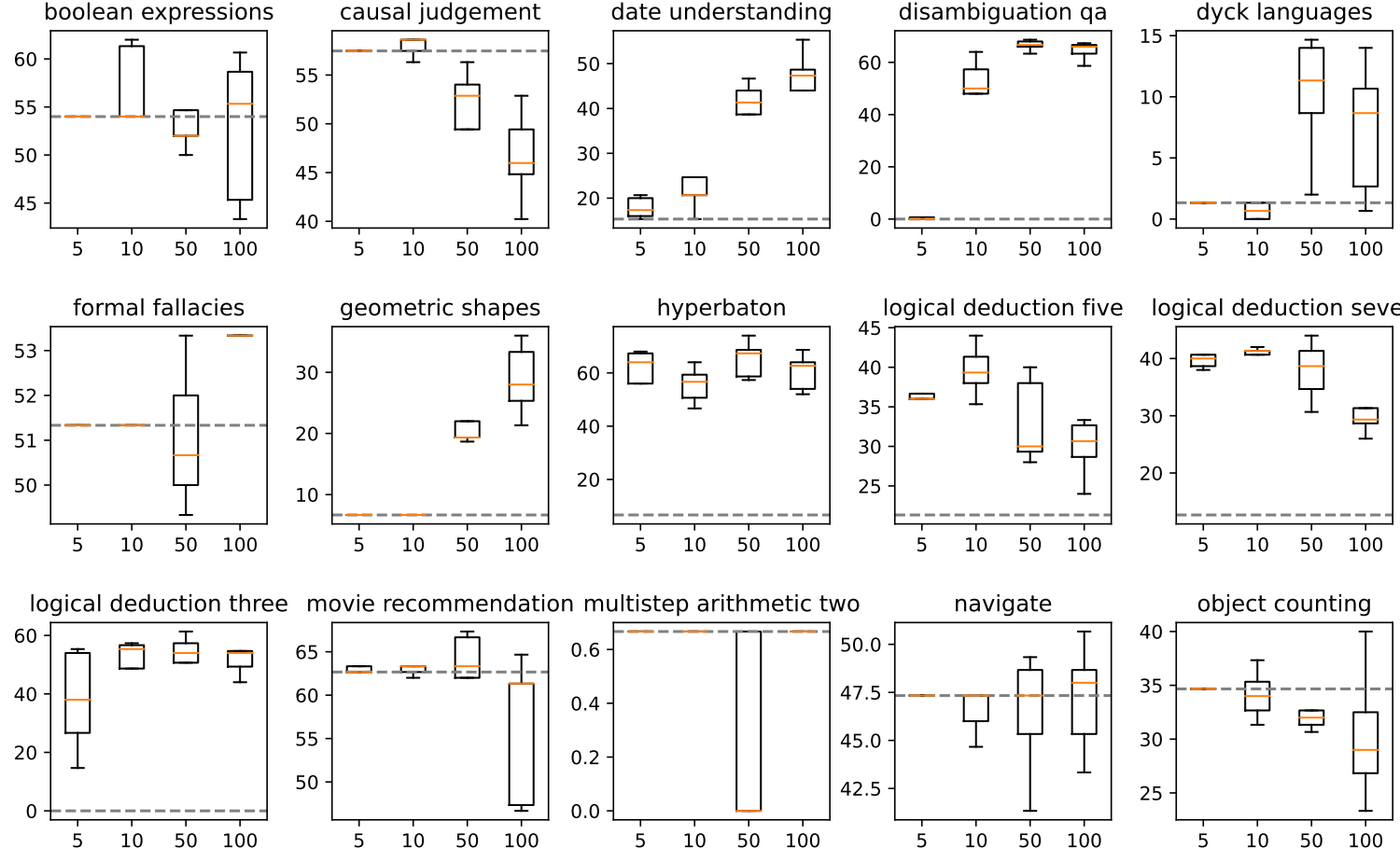
图3:LoRA模块数量对BBH中15个任务的影响,每个框分别从5次单独运行中获得。横轴表示在LoraHub学习中需要组成的LoRA模块的数量。
在我们的主要实验中,我们随机选择了20个LoRA模块进行LoraHub学习。因此,我们进行了实验来研究使用不同数量的LoRA模块的效果。结果表明,随着LoRA模块数量的增加,性能差异也会增加。然而,最大可实现性能也有所提高。更多方差分析和详细结果见附录G。
组合LoRA模块是否超出了单个模块的优势?
表3:基准BBH中所有任务中各种方法的平均性能。
我们承认在先前的工作中对跨任务性能的调查(Jang等人,2023),该研究深入研究了LoRA的能力,并提出了一种以LoRA模块检索为中心的新方法。为了保证公平的比较,我们进行了一个实验,我们设计了一个基于少量样本产生的损失的LoRA检索机制。具体来说,我们根据这个损失对所有的候选LoRA模块进行排名,并在未见任务的测试集中评估最佳候选模块。如表3所示,LoRA检索的性能令人印象深刻,将其定位为一个强大的基线。但是,与LoraHub相比,LoRA检索的性能相对较差。
7.结论
在这项工作中,我们介绍了LoraHub,这是一个战略框架,用于组合经过不同任务训练的LoRA模块,以便在新任务上实现自适应性能。我们的方法仅使用来自新任务的几个示例就可以实现多个LoRA模块的流畅组合,而不需要额外的模型参数或人工专业知识。在BBH基准上的实证结果表明,LoraHub可以在少数场景下有效地匹配上下文学习的性能,在推理过程中不需要上下文示例。总的来说,我们的工作显示了战略性LoRA可组合性的前景,可以使LLM快速适应各种任务。通过促进LoRA模块的重用和组合,我们可以在最小化培训成本的同时,努力实现更通用和适应性更强的LLM。
参考资料
论文下载
https://arxiv.org/abs/2307.13269

代码地址
https://github.com/sail-sg/lorahub


![[Linux]安装+使用虚拟机](https://i-blog.csdnimg.cn/direct/347538acefaf4e09aa5bb4ed2f84fddf.png)














![Python自动化测试系列[v1.0.0][自动化测试报告]](https://img-blog.csdnimg.cn/20191209211228341.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Rhd2VpX3lhbmcwMDAwMDA=,size_16,color_FFFFFF,t_70)
