文献介绍

文献题目: Systematic comparison of sequencing-based spatial transcriptomic methods
研究团队: 田鲁亦(广州实验室)、刘晓东(西湖大学)
发表时间: 2024-07-04
发表期刊: Nature Methods
影响因子: 36.1
DOI: 10.1038/s41592-024-02325-3
摘要
基于测序的空间转录组学(sST)的最新发展通过促进转录组规模的空间基因表达测量促进了重要进展。尽管取得了这些进展,但目前仍缺乏对不同平台进行全面的基准测试。技术和数据集之间现有的差异给制定标准化评估指标带来了挑战。在这项研究中,作者建立了一组具有明确组织学结构特征的参考组织和区域,并使用它们生成数据来比较 11 种 sST 方法。作者强调分子扩散作为不同方法和组织中的可变参数,显着影响有效分辨率。此外,作者观察到空间转录组数据表现出独特的属性,而不仅仅是向单细胞数据添加空间轴,包括增强捕获图案化稀有细胞状态以及特定 markers 的能力,尽管受到包括测序深度和分辨率在内的多种因素的影响。作者的研究协助生物学家选择 sST 平台,有助于就评估标准达成共识,并为未来的基准测试工作建立一个框架,该框架可以用作空间转录组分析计算工具的开发和基准测试的金标准。
前言
高通量测序技术的出现彻底改变了转录组学,为基因表达的复杂性提供了无与伦比的见解。单细胞 RNA 测序 (scRNA-seq) 在剖析细胞异质性方面发挥了重要作用,但在捕获理解组织结构、细胞相互作用和功能状态所必需的空间背景方面存在不足。为了解决这一限制,sST 已成为一种关键方法,可以实现全面的转录组分析,同时保留组织内的空间信息。
尽管 sST 技术取得了快速进步,但该领域仍处于早期阶段。基于成像的空间转录组学有着悠久的历史,并且已经与 SpaceTX 联盟启动了协作基准测试工作。然而,尚未对 sST 进行系统的基准研究。先前的研究已经建立了比较单细胞转录组和表观基因组方法的框架,强调了标准化评估标准和参考组织用于技术验证的必要性,因为模拟的单细胞和空间数据可能不可靠。虽然 sST 技术具有共同的特征,例如在 scRNA-seq 中使用类似于细胞条形码的空间 DNA 条形码,但这些方法在空间分辨率和空间条形码寡核苷酸阵列的制备等方面存在显着差异。这种可变性给方法选择带来了挑战,并使通用评估标准的建立变得复杂。
在本研究中,作者通过对 11 种 sST 方法进行系统比较来解决这一关键差距。使用一组参考组织,包括小鼠胚胎眼、小鼠大脑海马区和小鼠嗅球,作者生成了用于 sST 基准测试的跨平台数据,称为 cadasSTre。该数据集使作者能够评估每种技术在空间分辨率、捕获效率和分子扩散方面的性能。作者更新了 scPipe,以实现 sST 数据的预处理和下采样,以进一步最大限度地减少变异性并促进未来技术的结合。作者的分析表明,不同 sST 技术生成的数据在下游应用中表现出不同的能力,例如聚类、区域注释和细胞间通信。值得注意的是,作者还强调了 sST 数据中的基因检测偏差。
本研究有多种目的:(1) 指导研究人员针对其特定的生物学问题选择适当的 sST 方法,(2) 为未来的基准测试工作建立一个框架,(3) 有助于在这个快速发展的领域中评估标准的标准化。此外,作者的工作旨在为评估用于空间转录组数据分析的计算工具提供基础。
研究结果
1. 对参考组织和实验设计进行基准测试
作者基于不同的空间索引策略系统地对空间转录组学 (sST) 方法进行了基准测试,包括 microarray (probe-based and polyA-based 10X Genomics Visium, DynaSpatial)、 bead-based approaches (HDST, BMKMANU S1000, Slide-seq V2, Curio Seeker (which is the commercialized version of Slide-seq at Curio Bioscience), Slide-tag)、polony- or nanoball-based technologies (Stereo-seq, PIXEL-seq, Salus)、microfluidics (DBiT-seq)。每种 sST 方法的详细信息列于 Tables 1 and 2 以及 Supplementary Table 1 中。
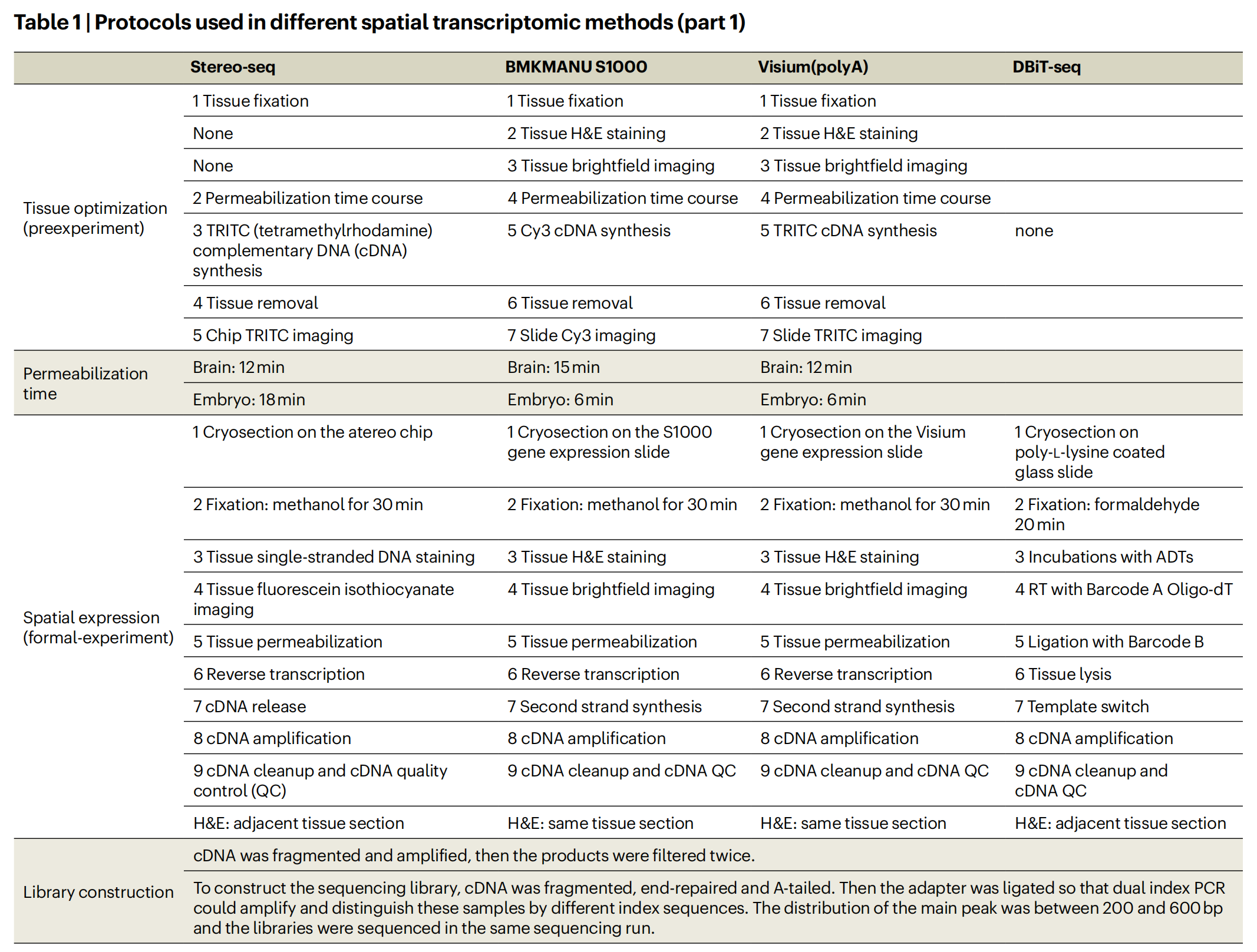
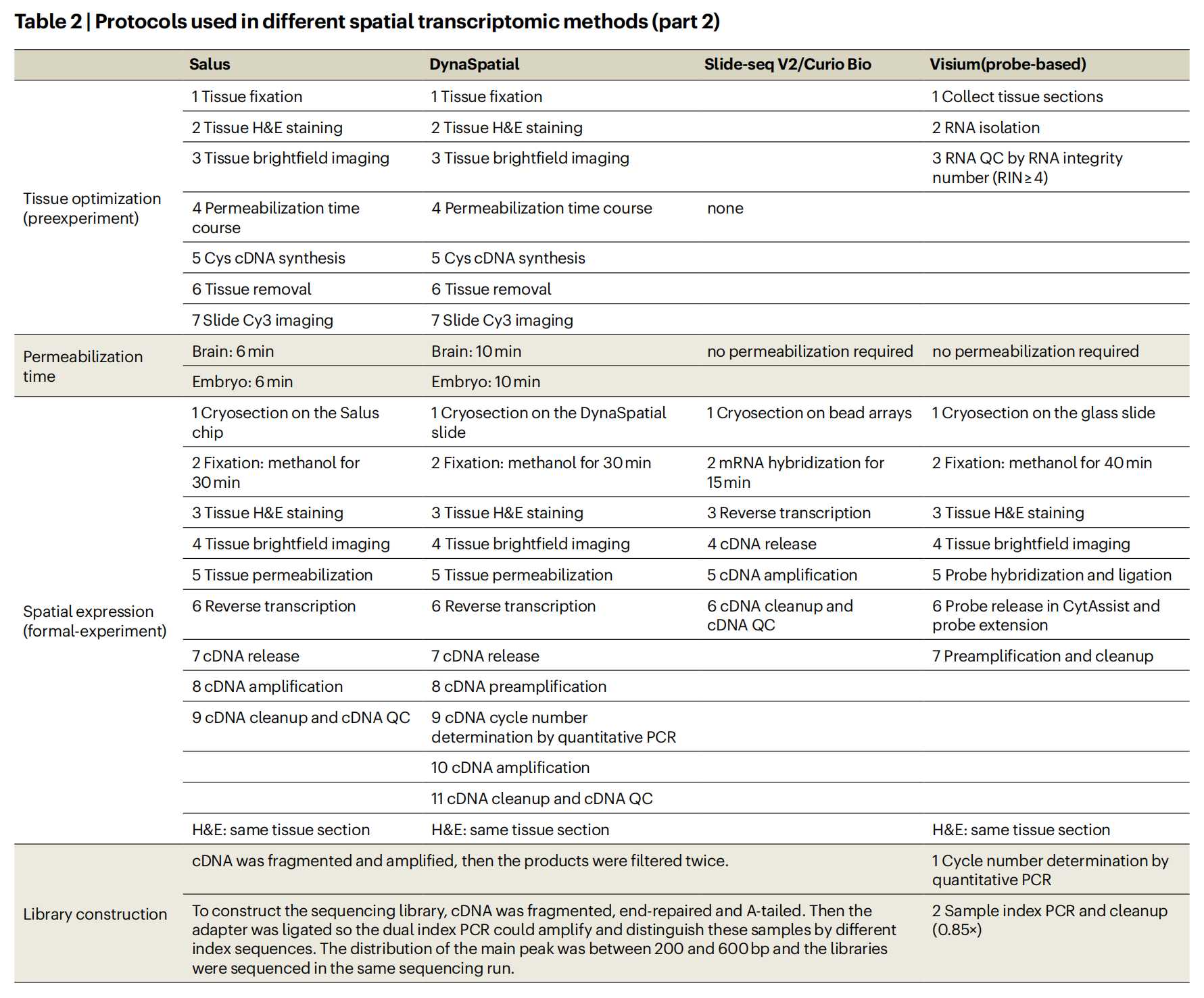
作者选择成年小鼠大脑、E12.5 小鼠胚胎和成年小鼠嗅球作为参考组织,因为它们的形态特征相对明确。例如,成年小鼠海马体表现出一致的厚度,并包含诸如 cornu ammonis (CA)1、CA2、CA3、dentate gyrus (DG) 等区域,每个区域都具有不同的表达谱。胚胎中的 E12.5 小鼠眼睛表现出已知的结构,其晶状体被神经元视网膜细胞包围,而小鼠嗅球具有与各种神经元类型清晰的层分离。这些组织具有已知的形态模式和异质表达谱,可作为 sST 基准研究的理想参考样本(Fig. 1a)。Supplementary Table 2 中给出了 cadasSTre 中数据集的摘要。用于获取感兴趣区域的详细方案已经建立,并可在 Methods 部分中找到,以促进其他研究人员的重现性。作者在苏木精和伊红(H&E)图像中观察到不同方法之间高度一致的组织形态,如 Supplementary Figs. 1–5 所示。这验证了标准组织处理和切片程序能够在不同的实验中产生一致的结果。总的来说,作者系统地评估了三种组织类型的 35 项实验中的 11 种 sST 方法。
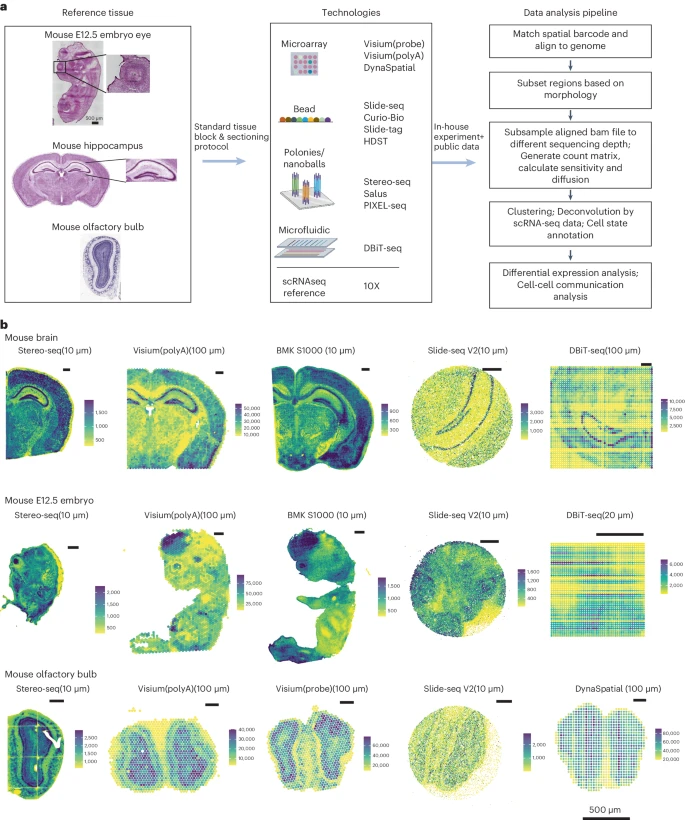
a. 实验设计涉及参考组织的使用,以及按不同空间索引策略分类的技术。
b. 显示了使用每个参考组织平台生成的数据集在空间维度上的总计数的可视化。用于创建绘图的中心到中心的距离与每个 sST 方法的名称一起显示。比例尺,500 μm。
正如摘要流程(Fig. 1a,右侧面板)中所述,作者接下来构建了一个标准基准测试流程,以实现 sST 方法的同质数据处理并以公平的方式进行比较。最初,生成空间条形码及其相应位置,以及每个空间位置的表达谱。
Figure 1b 和 Supplementary Fig. 6 概述了各种组织类型中每种 sST 方法的每个 spot 的总计数。在样品中观察到清晰的组织图案。总计数的概括以不同的 spot 尺寸和 spot 中心之间的距离呈现。Supplementary Fig. 7 清楚地描述了这些差异。在 Fig. 1b 中,作者标记了 spot 中心之间的距离,因为作者相信该指标比使用 spot 尺寸更好地代表了平台的物理分辨率。Stereo-seq、BMKMANU S1000 和 Salus 的 spot 中心之间的距离小于 10μm,其中的 spots 被分成 10μm 大小的 spots 以进行可视化。作者观察到 Stereo-seq、Visium、BMKMANU S1000 和 Salus 成功捕获了几乎整个右脑和整个 E12.5 胚胎。在这些方法中,Stereo-seq 表现出了最高的捕获能力。其常规阵列尺寸为 1 cm,最大尺寸可达 13.2 cm。相比之下,Slide-seq V2 由于捕获大小有限,只能捕获部分组织(Supplementary Fig. 7b–d)。对于 DBiT-seq,捕获尺寸根据微流体通道的宽度而变化。
随后,作者选择性地保留了已知形态区域内的读数,包括小鼠大脑中的海马体和 E12.5 胚胎中的眼睛。然后,作者进行下采样以解决测序深度和测序成本的变化。下采样的目的是将不同方法标准化为相同的测序读数总数,以实现测序成本的等效。然后生成具有下采样数据和完整数据的计数矩阵,用于灵敏度和扩散计算,然后进行细胞状态注释、标记基因检测和细胞间通讯分析。
2. 分子捕获效率
作者从成年小鼠大脑和 E12.5 小鼠胚胎中获得了海马和眼组织,如 Fig. 2a 所示。这是通过根据总 counts 的空间分布和 H&E 图像提供的形态信息指示的组织模式手动描绘边界来完成的。通过选择相同的区域,作者确保对 sST 样本性能的比较不会受到组织内不同位置的影响,因为来自组织不同部分的 counts 数可能会表现出变化。
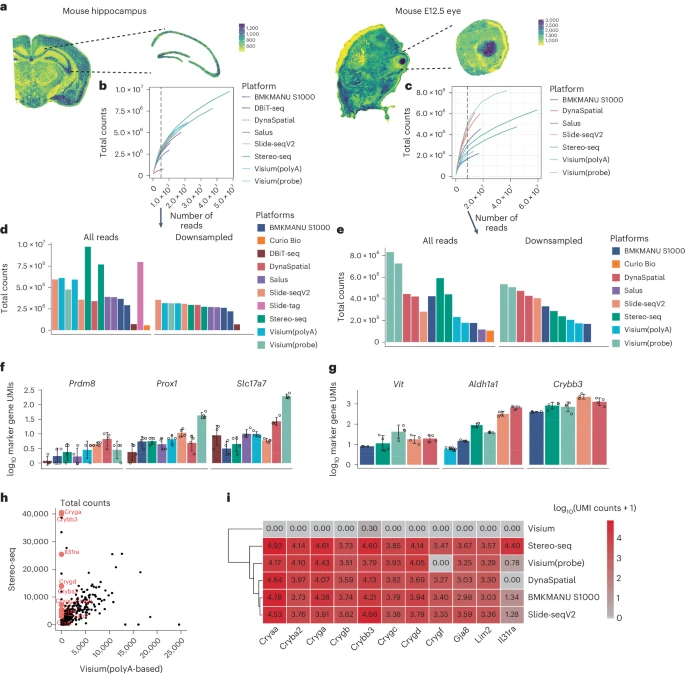
a. 示意图,说明从完全处理的成年小鼠海马和 E12.5 小鼠眼睛样本中提取具有已知形态的区域。总 UMI counts 表示为每个平台的逐步下采样测序深度的函数。
b-c. 数据源自小鼠海马体 (b) 和 E12.5 小鼠眼部 (c) 区域。垂直黑色虚线标记用于生成后续下采样数据的 read count。
d. 使用小鼠海马体的所有 reads 和下采样数据计算选定区域的总 UMI counts。
e. 使用 E12.5 小鼠眼睛的所有 reads 和下采样数据计算选定区域的总 UMI counts。
f. 小鼠海马中各个 50 × 50 μm 区域 (n = 4) 的 marker genes 的 UMI counts 总和,以及平均值和标准差。
g. E12.5 小鼠眼中各个 50 × 50 μm 区域(n = 4)的 marker genes 的 UMI counts 总和,以及平均值和标准差。
h. 比较 Visium(polyA)(x 轴)和 Stereo-seq(y 轴)之间检测到的基因的总 UMI counts。每个点代表一个基因,以黑色显示。在 Stereo-seq 中显示表达处于第 90 个百分位但在 Visium(polyA) 中处于第 10 个百分位的基因以红色突出显示并标有其基因符号。
i. 热图显示 log10 转换的基因表达,这些基因在 E12.5 小鼠眼睛中没有被 Visium(polyA) 捕获,但被 Stereo-seq 捕获。
通过两种方式评估分子捕获效率。在选定的区域中,我们要么(1)使用该区域的所有 reads,要么(2)对数据进行下采样,以便不同的样本具有相同数量的测序 reads,作者在后续结果中将其称为“downsampled data”。
根据下采样结果(Fig. 2b,c 和 Supplementary Fig. 8),从 3 亿 reads (Visium) 到 40 亿 reads (Stereo-seq) 的测序运行均未达到饱和。这一观察结果表明,sST 数据需要相当多的 reads 才能获得最佳性能,并有可能提高灵敏度。
接下来,作者通过对选定区域内的总 counts 进行求和来比较每种 sST 方法的灵敏度。与其他平台相比,Stereo-seq 在小鼠海马和眼睛的同一区域有更多的测序 reads,导致使用所有 reads 时的总 counts 相对较高(Fig. 2d,e,左图)。尽管测序深度只有 Stereo-seq 的一半,但 Visium(probe)在小鼠眼中呈现出最高的总 counts。这可能是由于基于探针的方法具有更好的 read 捕获效率,以及使用探针时过度量化的唯一分子标识符 (UMI) counts 的潜在影响。
然而,当控制测序深度的影响时,Slide-seq V2 数据在小鼠眼中表现出比其他平台更高的灵敏度,而在海马体中,probe-based Visium、DynaSpatial、Slide-seq V2 显示出更高的灵敏度。该观察结果与饱和图结果一致(Fig. 2b,c),其中总 count 与饱和图中所选测序深度的斜率正相关(Fig. 2d,e,右图)。此外,当将下采样结果与使用所有 reads 获得的结果进行比较时,在 Stereo-seq 数据中,对 counts 数量和每个 spot 特征之间关系的影响更为明显(Supplementary Fig. 9)。
为了对所选 sST 方法之间的敏感性差异进行更详细的评估,作者继续使用下采样数据测量已知在特定区域表达的 marker genes 的 RNA 含量。在海马的 CA3 中,作者比较了 50 × 50 μm 区域内的 Prdm8、Prox1、Slc17a7 的 counts 总和(根据所应用的 sST 方法中最大的物理分辨率值进行选择)。作者的研究结果表明,这些 marker genes 的表达模式在某种程度上反映了总 count 结果,其中 Visium(probe)、Slide-seq V2、DynaSpatial 在海马中表现出最高的敏感性(Fig. 2f)。以 E12.5 小鼠眼睛为例,作者比较了 50××50μm 区域内 Vit、Crybb3(晶状体)和 Aldh1a1(神经元视网膜)的 counts 总和。类似地,Visium(probe)、DynaSpatial、Slide-seq V2 表现出最高的灵敏度,而 Visium(polyA) 在预期表达的区域中没有生成那么多的 marker genes counts(Fig. 2g)。通过成对比较,作者确定了在所有 sST 方法中晶状体中一致表达的基因,除了 Visium(polyA) 生成的数据(Fig. 2h 和 Supplementary Fig. 10a),包括 Crybb3 和 Cryaa(Fig. 2i)。这种不一致似乎并非归因于预处理流程和基因注释(Supplementary Fig. 10b),表明 Visium(polyA) 对晶状体存在系统性基因特异性偏差。在试图将这种偏差与各种基因属性(包括基因生物型、长度和鸟嘌呤胞嘧啶(GC)含量百分比)联系起来时,作者发现这些在 Visium(polyA) 中表现出低表达的偏差基因主要是蛋白质编码。此外,在 GC 含量或基因长度方面没有检测到显着偏差(Supplementary Fig. 11)。
在对小鼠嗅球的研究中,注释后,作者考虑了总 counts 密度不同的层,评估了所选 sST 方法的灵敏度。值得注意的是,PIXEL-seq 表现出最高的灵敏度,而 HDST 在 10μm 物理分辨率下表现出最低的灵敏度(Supplementary Fig. 12)。对于分辨率为 100μm 的方法,与眼睛和海马体的结果一致,DynaSpatial 和 Visium(probe) 表现出更高的灵敏度。
此外,作者将 Slide-tag 纳入灵敏度比较中,与其他平台相比,它在小鼠海马体中显示出第二高的总 counts。与 Stereo-seq 和 BMKMANU S1000 相比,在 20μm 的分辨率水平下,Slide-tag 产生的总 counts 要高得多。作者观察到不同细胞类型在 UMAP 以及 marker gene 表达方面有更好的分离(Supplementary Fig. 13)。这表明其他技术的数据存在扩散问题,无法代表真实的单细胞表达谱。
3. 分子横向扩散
除了单位面积的分子捕获灵敏度之外,另一个重要的质量参数是 mRNA 检测的空间精度。为了评估这种准确性,作者使用了两种分析方法来测量分子横向扩散:(1) 绘制所选区域中特定基因的强度分布图,以及 (2) 量化所选区域中强度的半峰左宽度 (LWHM) 之间的距离,重点关注组织学结构,其中所选基因的表达应表现出显着差异,在该区域的一部分中显示高表达,而在其余部分中显示最低表达或无表达。这些分析是使用所有 reads 生成的 count 数据进行的。
在对嗅球的评估中,作者选择 Slc17a7 作为 marker gene,因为它在形成不同层的 mitral 和 tufted 细胞以及位于肾小球层基底的谷氨酸能神经元中特异性表达。作者通过 Allen Brain Atlas 的原位杂交证实了 Slc17a7 在这些位置的表达。在此分析中,作者的重点是 Slc17a7 在 mitral 和 tufted 细胞中的表达。正如每个 sST 数据集中 Slc17a7 的表达图所示(Fig. 3a,左图和 Supplementary Fig. 14a),作者专门选择了 Slc17a7 在中间表达的区域(n = 6)。作者的观察基于强度图和 LWHM 测量,通过 Stereo-seq 揭示了嗅球中 Slc17a7 的显着横向扩散。值得注意的是,Slide-seq V1.5 和 PIXEL-seq 对这种扩散表现出相对更好的控制(Fig. 3b-d,左图)。在多个层的缩小视图中比较分辨率较低的方法,并显示出不同的扩散性能,Visium(polyA) 更清晰地保留了嗅球中跨层 Slc17a7 表达的两个峰,而 DynaSpatial 几乎没有提供分离的表达峰(Supplementary Fig. 14b,c)。
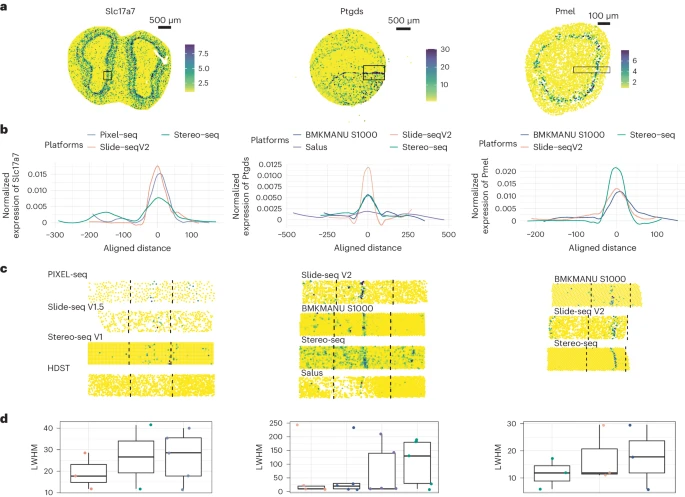
a. 表达 markers 包括小鼠嗅球中的 Slc17a7(左)、小鼠大脑中的 Ptgds(中)和 E12.5 眼中的 Pmel(右)。这些图基于原始 count 值。黑框表示用于扩散计算的选定区域。
b. 上述 marker genes(来自 a)的表达水平沿嗅球中 50μm、大脑中 500μm 和眼睛中 300μm 每 10μm 聚集,如 a 所示。UMI counts 是跨模式的平均值,针对每个平台进行标准化,并以密度图形式呈现,曲线下面积设置为 1(详细信息见 Methods)。
c. 提供了所选模式内如上所述(来自 a)的 marker genes 的表达水平,黑色虚线描绘了用于扩散计算的边界。
d. 然后计算每个模态中每个基因(来自 a)的轮廓的半峰左宽度(LWHM),并显示在箱线图中。每个点代表给定模态的 LWHM(嗅球和大脑 n = 6,眼睛 n = 3)。删除了无法计算 LWHM 的模态。方框表示四分位数范围,即第 25 个百分位数和第 75 个百分位数之间的范围,以及中值;须线表示 1.5 倍四分位数范围内的最大值和最小值。
在对大脑的分析中,作者选择 Ptgds 作为 marker gene,因为它已通过原位杂交证实在血管细胞内的特定位置特异性表达(Supplementary Fig. 15a,b)。通过检查 Ptgds 的表达图及其密度图以及 LWHM 测量值,作者注意到 Stereo-seq 数据集中存在严重的横向扩散。相比之下,Slide-seq V2、随后是 BMKMANU S1000 对此类横向扩散问题表现出更好的控制(Fig. 3a-d, middle panel, and Supplementary Fig. 15c)。作者通过对下采样 Stereo-seq 数据进行扩散分析进一步验证了这些观察结果,确认尽管与其他 sST 数据集相比测序深度较低,但横向扩散的挑战仍然存在(Supplementary Fig. 15d–f)。这表明下采样无法解决 Stereo-seq 数据的横向扩散问题。此外,作者深入研究了 Sst 的表达模式,该基因主要在小鼠皮质内稀疏分布的 SST 神经元中表达。作者的分析发现,当使用 Stereo-seq 进行评估时,Sst 基因表达在每个 cluster 内表现出更分散的分布。假设 Sst 神经元在不同样本的细胞体中具有相似的大小,则较大的方差表明更多的扩散。这一观察结果证实了作者早期与不同技术的扩散模式相关的发现(Supplementary Fig. 16)。
为了检查眼组织,作者选择 Pmel 作为 marker gene,因为它在黑色素细胞中特异性表达,黑色素细胞包围晶状体并形成圆形图案。在这种情况下,Stereo-seq 展示了对横向扩散的最佳控制,其次是 Slide-seq V2(Fig. 3a-d, right panel, and Supplementary Fig. 17)。这一观察结果与作者在其他两种组织类型中的发现形成对比,表明组织类型对扩散过程有相当大的影响。另一个因素是透化时间,作者证明它对扩散模式和 mRNA 捕获有很大影响(Supplementary Figs. 1-5)。
4. 跨技术的聚类和细胞注释
接下来,作者应用选定的 sST 方法来深入了解生物问题,其中较高的捕获灵敏度和良好控制的扩散非常重要。作者选择了 E12.5 小鼠眼睛,该眼睛以其独特的结构而闻名,其特点是晶状体被视网膜包围,然后是黑素细胞。
4.1 通过聚类结果注释区域
有了眼部区域内一般细胞状态的基本知识,作者的下一个目标是使用各种聚类方法对选定的 sST 平台捕获的 spots 进行注释。作者的目的是确定是否能够在所有样本中一致地识别出更详细和连贯的细胞子集。
由此产生的细胞亚群注释不仅可以作为评估本研究中使用的方法的基准,而且还为 E12.5 小鼠发育中的眼睛内细胞状态的复杂性提供了有价值的见解。
在深入研究比较分析之前,Fig. 4a 展示了作者预期在 E12.5 小鼠眼内观察到的细胞亚群的发现。在该组织中,预期的形态结构从最内部的空间展开,容纳晶状体和晶状体囊泡,它们被神经元视网膜细胞包围,在特定位置形成不同的子集。视网膜神经细胞被黑素细胞包围,喙侧含有角膜间质,尾侧则由上皮细胞组成。这些注释为后续的评价和比较评估提供了基础。
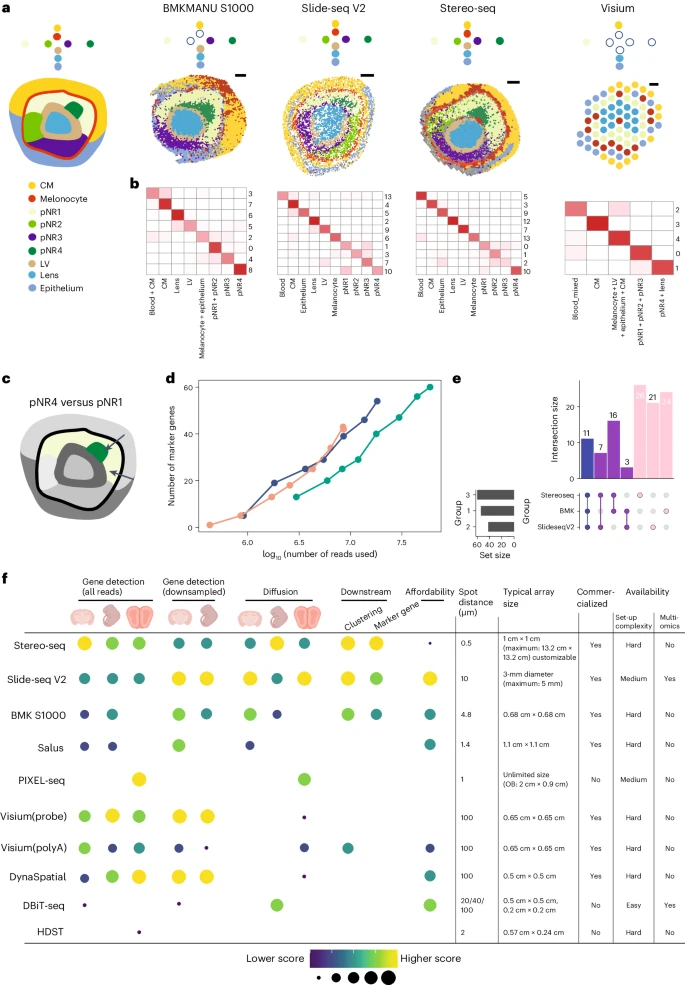
a. 对每个平台生成的表达谱进行处理以获得聚类结果。已知的细胞类型和状态在最左侧的面板中用颜色表示。此外,示意图表示预期的细胞状态,从外部空间到内部空间、从上到下排列。右侧显示聚类结果,其中 spots 按带注释的细胞状态进行颜色编码,描述了可识别的细胞状态。
b. 对来自每个平台的下采样眼睛数据进行聚类,在眼睛区域中跨平台的总 read count 相等。基于所有 reads 的聚类和基于下采样数据的聚类获得的注释之间的对应关系在热图中可视化。此对应关系中的 spots 数显示为 log10 转换并且没有 scaling。
c. marker gene 检测分析中比较的细胞状态概述,突出显示了 pNR4 和 pNR1。
d. 在 pNR4 和 pNR1 之间的比较中,每种 sST 方法使用不同数量的 reads 检测到的 marker gene 的数量。
e. upset 图显示使用 pNR4 和 pNR1 比较的所有 reads 通过不同 sST 方法获得的 marker genes 的交集。所有三个平台之间共享的基因用蓝色表示,两个平台之间共享的基因用紫色表示,独特获得的基因用粉色表示。
f. sST 方法根据其在指定类别中的性能进行排名,性能最高的方法位于顶部。分辨率水平低于 20μm 的方法得到了更高的优先级。右图中概述了所检查的 sST 方法的基本特征。较低的承受能力表明与该方法相关的较高价格。CM,角膜间质; pNR,假定神经视网膜; LV,晶状体囊泡;OB,嗅球。
4.2 聚类结果比较
在聚类结果的对比分析中,作者从两个角度进行评价:
(1)聚类方法:作者系统地使用了三种不同的聚类方法:Seurat(专门考虑转录组图谱)、DR.SC 和 PRECAST(将空间信息与基因表达数据结合在一起)。最近的基准研究报告称,利用空间位置信息的方法在特定数据集中展示了有希望的聚类结果。然而,与仅依赖基因表达数据的方法相比,它们并没有始终如一地超越或表现出更大的稳健性。作者的观察结果与这一结论一致,与其他两种方法相比,Seurat 在检测预期细胞亚群方面始终表现出稳健和稳定的性能,如 Fig. 4a 左图和 Supplementary Fig. 18 所示。
(2)sST 方法:在 sST 平台之间的比较中,作者主要关注 Seurat 生成的结果。作者分别注释了每种 sST 方法的 spots(Fig. 4a and Supplementary Fig. 19)。作者的分析揭示了不同方法一致识别预期细胞亚群的能力的差异。值得注意的是,Slide-seq V2 和 Stereo-seq 数据为全面的子集注释提供了很好的 spots 分离,成功捕获了所有预期的子集。相反,BMKMANU S1000 数据在细胞状态检测方面面临挑战,特别是在识别黑素细胞方面。这种困难可能源于 BMKMANU S1000 数据中观察到的明显横向扩散(如 Fig. 3c,d 右图所示),使得仅依赖表达谱的聚类方法很难保留这种特定的细胞类型。另一方面,分辨率为 100μm 的数据(包括 Visium 和 DynaSpatial)在检测预期细胞亚群时面临某些限制。这些挑战主要归因于物理分辨率相对较低,因此眼部区域可用的 spots 数量有限(每个样本总共约 75 个 spots)。在这些 50 × 50 μm spots 中的每一个中,细胞都是混合的,使得复杂的细胞亚群的识别更具挑战性(Fig. 4a,右图和 Supplementary Fig. 19)。
4.3 下采样对聚类结果的影响
作者观察到测序深度影响空间转录组数据的总 counts(Fig. 2b-e)。鉴于此,作者着手研究测序深度如何影响聚类结果。作者对下采样数据聚类结果的探索涉及两个关键方面:(1)评估了下采样数据和完整数据之间的对应关系。(2)根据以完整数据获得的聚类结果作为以不同比例生成的下采样数据的参考,计算了聚类纯度(ECP)和准确性(ECA)的熵度量,如 Fig. 4b 所示。作者发现下采样数据能够检测完整数据识别的几乎所有细胞子集(Fig. 4b and Supplementary Fig. 20)。然而,当评估不同比例值的 ECP 和 ECA 时,观察到相对较高的值,表明存在明显的不一致程度。这种不一致可能归因于这样一个事实:虽然大多数细胞子集有效地形成了不同的类群,但一部分细胞分为不同的类群,特别是来自不同神经元视网膜细胞子集的细胞之间。这种效应在晶状体和晶状体囊泡以及四个神经元视网膜亚群等群体之间的亚群中尤其明显(Fig. 4b),它们在表达谱上更加相似。
4.4 sST 数据与 snRNA-seq 数据的比较
作者在所有 sST 数据集中一致观察到 Pmel、Crybb3、Atoh7、Enfa5、Aldh1a1、Aldh1a3 的良好模式表达。选择这些基因是因为它们作为特定细胞类型的 markers,例如黑素细胞、晶状体和假定神经视网膜 (pNR)2 和 pNR3(Supplementary Figs. 21 and 22)。然而,某些区域的绝对位置并不完全相同,但它们的相对位置保持一致,例如 Aldh1a3 位于视网膜层的喙部区域,而 Aldh1a1 模式朝向尾部区域(Supplementary Fig. 23)。
此外,作者还获得了以眼睛区域切片作为输入的 snRNA-seq 数据。然而,发现表达上述基因的细胞数量有限,并且这些细胞主要聚集在 UMAP 的下角(Supplementary Fig. 21e)。不幸的是,无法将这个小子集进一步分类为更详细的子组,就像 sST 数据的情况一样。作者还注意到,Crybb3 在 snRNA-seq 数据中的表达值相对低于预期。这与之前的观察一致,即 Crybb3 未发现在 Visium(polyA) 捕获的眼部区域中表达,表明与基于 polyA 的 Visium 技术相关的潜在捕获偏差。
虽然 snRNA-seq 数据可能无法像 sST 方法那样捕获眼部区域那么多的细胞,但它可以作为注释 sST 数据的有用参考数据集。如 Supplementary Fig. 24 所示,使用 Seurat 将 snRNA-seq 数据与 sST 数据整合有助于 sST 数据的注释。例如,它改进了 Stereo-seq 数据中上皮细胞的注释,由于具有混合表达谱的未知细胞类群,该注释相对具有挑战性。使用 snRNA-seq 上皮细胞的投影可以更好地解析该类群(Supplementary Fig. 24a)。此外,投影促进了 BMKMANU S1000 数据中黑素细胞和上皮细胞的分离(Supplementary Fig. 24b)。
另一个值得一提的问题是 sST 技术对血液污染的敏感性,这种污染通常是在组织制备和切片过程中引入的,并且很难避免。作者以 Hba-a1 基因为例来评估血液污染对这些 sST 方法的影响。作者的研究结果显示,Visium、DynaSpatial、BMKMANU S1000 受到血液污染的影响显着,所有 Visium 和 DynaSpatial spots 以及 70% 的 BMKMANU S1000 spots 均表达 Hba-a1。相反,与 snRNA-seq 相比,Stereo-seq 数据表现出相对相似的血液污染水平,并且 Slide-seq V2 的血液污染量最低(Supplementary Fig. 25)。
5. 跨技术的标记基因检测
先前的研究强调了在识别 marker genes 时使用 Wilcoxon 秩和检验的有效性和稳健性。作者在 Seurat 中使用此测试来查找类群之间的 marker genes。对 top marker genes 的分析揭示了这些 markers 选择中的技术特异性偏差。例如,Pax6 是一种转录因子,被称为神经谱系的主要调节因子,尤其是在视网膜中,它在不同技术中表现出不同的表现。具体来说,Stereo-seq 数据仅突出显示 pNR3 类群中的 Pax6,而 Slide-seq V2 和 BMKMANU S1000 数据则描述了整个神经视网膜 (pNR1-4) 中的 Pax6 表达(Supplementary Table 3),与现有文献一致。这一观察强调了技术选择对识别特定细胞类型或细胞类群的 top markers 的影响。同样,在 pNR1 和 pNR2 的神经视网膜祖细胞中的 Hes 基因和 Sox2 的表达中也观察到差异(Supplementary Table 3)。
对下采样数据的聚类结果分析表明,即使测序 reads 较少,仍然可以充分保留一般细胞子集。然而,似乎有一些子集,特别是那些具有相似表达谱的子集,对于清晰分离来说是一个挑战。为了进一步研究下采样的影响,作者将下采样数据中识别的 marker genes 与完整数据集中的 marker genes 进行了比较。作者选择了两对细胞子集来比较表达谱相对相似和差异较大的细胞子集的检测性能。作者在两种情况下进行了 marker gene 检测,以识别 marker genes:(1)pNR4 和 pNR1,它们表现出较高的相似性,以及(2)晶状体和黑素细胞,它们具有较低的相似性(Fig. 4c and Supplementary Fig. 26a)。
作者的观察表明,在两对比较中,marker genes 的数量随着 reads 数量的增加而增加。值得注意的是,随着测序的加深,marker genes 的增加更加明显,如 Fig. 4d 和 Supplementary Fig. 26a 所示。sST 方法中 marker genes 检测性能的排名与 Fig. 2d 中描述的具有相对不同表达谱的细胞亚群之间的比较结果一致。特别是,Slide-seq V2 表现出更高的灵敏度(Supplementary Fig. 26b)。此外,作者的分析发现每个平台都具有比跨技术共享的更多的独特 marker genes(Fig. 4e and Supplementary Fig. 26c)。
随后应用了细胞间通信,但在应用的通信方法中没有发现一致的结果,包括 CellChat、CellPhoneDB v.4 和 sST 方法(Supplementary Fig. 27)。
讨论
评估空间转录组学方法比评估 scRNA-seq 方法更具挑战性。首先,为空间转录组学设计参考组织更加困难。如果我们使用具有清晰细胞类型和基因表达模式的真实组织,位置和 ground truth 就会变得不那么明显,并且受到我们对参考组织的理解的限制,这与 scRNA-seq 不同,在 scRNA-seq 中,人们可以使用细胞系混合物或外周血单核细胞样本来分析获得一致的输入。其次,测量不是在同一单元上进行的。对于 Visium(both polyA-based and probe-based)和 DynaSpatial 等方法,spot 的直径大于 50μm,类似于小批量 RNA 测序。对于 Stereo-seq 等方法,spot 尺寸为亚微米,比单个细胞小得多。
作者精心设计了基准研究来应对这些挑战。作者选择了一组参考组织,其标准如下:(1)组织应来自广泛使用的模式生物,大多数研究机构都可以获得; (2) 组织应具有稳定的细胞类型模式和特定的 marker gene 表达,(3) 参考区域应具有清晰的形态,易于在切片中找到。作者使用参考组织开发了切片方案,以帮助人们在未来重现并生成可比较的数据。对于第二个挑战,作者使用多个基准测试指标和工作流程来比较同一组织区域的不同方法。作者在比较中使用了所有 reads 和下采样数据。实施下采样是为了减轻变化对测序深度和成本的影响,然而,这可能不会使所有方法达到相同的标准,因为达到满意结果所需的 reads 数量可能不同,作者还在分析中使用了所有 reads 作为补充结果。
在这项研究中,作者在 genographix.com 上生成了 cadasSTre,这是一个用于 sST 基准测试的跨平台数据集,可以对 35 个实验中的 11 种 sST 方法进行系统评估。作者比较了从基本指标到下游分析的各个方面的数据,从敏感性和扩散到可聚类性和 marker gene 检测(Fig. 4f)。每个评估步骤中采用的方法的总结可以在 Supplementary Table 4 中找到。作者的结果表明空间转录组学需要更多的测序才能达到饱和,并且本研究中生成的数据远低于饱和水平。Stereo-seq、Slide-tag、Visium(probe) 在原始测序深度下显示出更好的捕获效率,而 Slide-seq V2、Visium(probe)、DynaSpatial 在归一化测序深度下显示出更好的捕获效率。作者在基于 PolyA 的 Visium 平台上发现了意外的基因捕获偏差,其他技术一致捕获的 marker gene 并未出现在 Visium(polyA) 数据中。考虑到 Visium 是使用最广泛的商业平台,进一步验证其对其他组织的基因捕获偏差非常重要。
spot 尺寸已成为替代每种方法分辨率的重要指标。然而,在这项研究中,作者强调扩散是影响实际分辨率的关键因素。作者的透化优化实验,如 Supplementary Figs. 1–5 所示,表明改变透化时间对扩散有重大影响。在优化每种组织类型的透化时间时,不同的技术在不同的组织类型中表现出不同的扩散曲线。尽管某些技术具有亚细胞 spot 尺寸,但与具有真正单细胞分辨率的 Slide-tag 相比,由于灵敏度有限和扩散性高,它们的实际分辨率无法达到相同水平。sST 的进一步发展将受益于增加的扩散控制和改进的测定来确定透化条件和时间。
尽管本研究的目标不是对计算工具进行全面的基准测试,但作者发现为空间数据设计的聚类工具可能不会比单细胞的聚类方法提供更好的性能,这与比较研究一致。作者还发现,源自单细胞参考的细胞注释可能不会产生详细的细胞状态,而源自空间数据的聚类可以提供补充结果,有时可以更好地解决具有空间模式的罕见细胞状态。在注释空间数据时,重要的是要考虑使用和不使用单细胞参考的分析。
总的来说,作者的研究产生了第一个 sST 方法的系统基准测试方案。尽管作者努力展示所有技术中最好的,但有些实验并未完全优化,例如 DBiT-seq 和 Curio Bio,这意味着它们的数据可能无法代表其最佳性能。sST 实验一般需要较多的实验技巧,操作效果也不容忽视。sST 领域正在快速发展,每种技术的性能可能会随着时间的推移而发生变化,因为它们会进一步优化。需要持续评估才能跟上这个快速发展的领域的步伐。空间多组学方法仍处于发展的早期阶段,需要建立新技术。因此,作者将继续使用新数据集维护和更新在线基准测试数据库,所有数据均托管在 genographix.com 上。通过这个平台,研究人员可以访问最新的基准测试数据,贡献他们的发现并与同行合作推进该领域的发展。
注:本文为个人学习笔记,仅供大家参考学习,不得用于任何商业目的。如有侵权,请联系作者删除。

本文由 mdnice 多平台发布
![Python自动化测试系列[v1.0.0][自动化测试报告]](https://img-blog.csdnimg.cn/20191209211228341.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2Rhd2VpX3lhbmcwMDAwMDA=,size_16,color_FFFFFF,t_70)