1. Java中的原始数据类型都有哪些,它们的大小及对应的封装类是什么?
- boolean
boolean数据类型非true即false。这个数据类型表示1 bit,但是它的大小并没有精确定义。
《Java虚拟机规范》中如是说:“虽然定义了boolean这种数据类型,但是只对它提供了非常有限的支持。在Java虚拟机中没有任何供boolean值专用的字节码指令,Java语言表达式所操作的boolean值,在编译之后都使用Java虚拟机中的int数据类型来代替,而boolean数组将会被编码成Java虚拟机的byte数组,每个元素boolean元素占8位”。这样我们可以得出boolean类型单独使用是4个字节,在数组中又是1个字节。那虚拟机为什么要用int来代替boolean呢?为什么不用byte或short,这样不是更节省内存空间吗?实际上,使用int的原因是,对于当下32位的CPU来说,一次进行32位的数据交换更加高效。
综上,我们可以知道:官方文档对boolean类型没有给出精确的定义,《Java虚拟机规范》给出了“单独时使用4个字节,boolean数组时1个字节”的定义,具体还要看虚拟机实现是否按照规范来,所以1个字节、4个字节都是有可能的。这其实是一种时空权衡。
boolean类型的封装类是Boolean。 - byte——1 byte——Byte
- short——2 bytes——Short
- int——4 bytes——Integer
- long——8 bytes——Long
- float——4 bytes——Float
- double——8 bytes——Double
- char——2 bytes——Character
2. 谈一谈”==“与”equals()"的区别。
对象类型不同
equals():是超类Object中的方法。
==:是操作符。
比较的对象不同
equals():equals是Object中的方法,在Object中equals方法实际"ruturn (this==obj)",用到的还是"==",说明如果对象不重写equals方法,实际该对象的equals和"=="作用是一样的,都是比较的地址值(因为"=="比较的就是地址值),但是大部分类都会重写父类的equals方法,用来检测两个对象是否相等,即两个对象的内容是否相等,例如String就重写了equals方法,用来比较两个字符串内容是否相同。
==:用于比较引用和比较基本数据类型时具有不同的功能,比较引用数据类型时,如果该对象没有重写equals方法,则比较的是地址值,如果重写了,就按重写的规则来比较两个对象;基本数据类型只能用"=="比较两个值是否相同,不能用equals(因为基本数据类型不是类,不存在方法)。
运行速度不同
equals():没有==运行速度快。
==:运行速度比equals()快,因为==只是比较引用。
3. Java中的四种引用及其应用场景是什么?
-
强引用: 通常我们使用new操作符创建一个对象时所返回的引用即为强引用
-
软引用: 若一个对象只能通过软引用到达,那么这个对象在内存不足时会被回收,可用于图片缓存中,内存不足时系统会自动回收不再使用的Bitmap
-
弱引用: 若一个对象只能通过弱引用到达,那么它就会被回收(即使内存充足),同样可用于图片缓存中,这时候只要Bitmap不再使用就会被回收
-
虚引用: 虚引用是Java中最“弱”的引用,通过它甚至无法获取被引用的对象,它存在的唯一作用就是当它指向的对象回收时,它本身会被加入到引用队列中,这样我们可以知道它指向的对象何时被销毁。
-
(1byte=8bit,Bit-map的基本思想就是用一个bit位来标记某个元素对应的Value,而Key即是该元素)
4. object中定义了哪些方法?
clone(), equals(), hashCode(), toString(), notify(), notifyAll(), wait(), finalize(), getClass()
5. ArrayList, LinkedList, Vector的区别是什么?
-
ArrayList: 内部采用数组存储元素,支持高效随机访问,支持动态调整大小
-
LinkedList: 内部采用链表来存储元素,支持快速插入/删除元素,但不支持高效地随机访问
-
Vector: 可以看作线程安全版的ArrayList
6. String, StringBuilder, StringBuffer的区别是什么?
-
String: 不可变的字符序列,若要向其中添加新字符需要创建一个新的String对象,即为定长
-
StringBuilder: 可变字符序列,支持向其中添加新字符(无需创建新对象)
-
StringBuffer: 可以看作线程安全版的StringBuilder
-
StringBuilder和StringBuffer默认长度为16
7.HashMap和HashTable的区别
-
HashTable是线程安全的,而HashMap不是
-
HashMap中允许存在null键和null值,而HashTable中不允许
8.HashMap的实现原理
在jdk1.8之前,HashMap的底层数据结构是数组+链表,也称为哈希表。
jdk1.8以及1.8之后,HashMap的底层数据结构是数组+链表+红黑树,也称为哈希表。
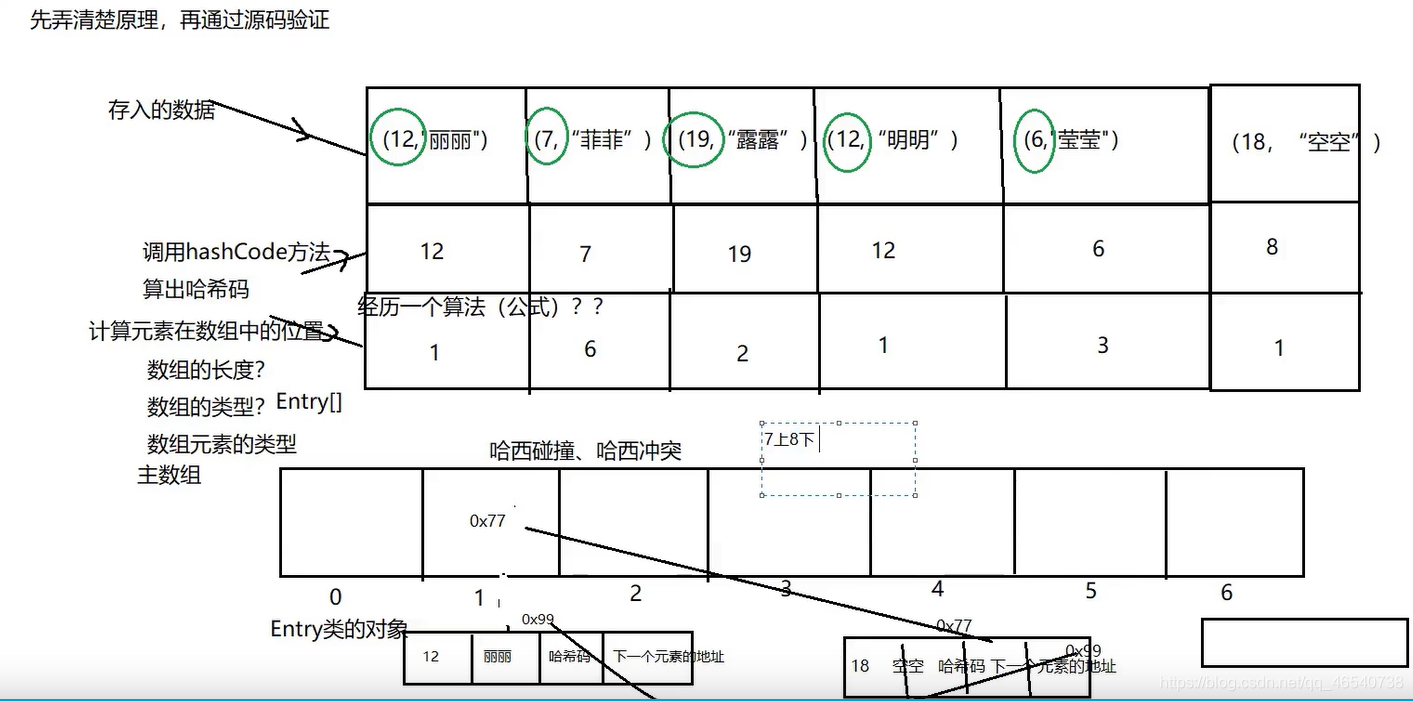
比如现在有一批数据需要插入到HashMap这个集合中,也就是上面那一批数据。要想往集合里插入数据,肯定得现new出一个集合,此时集合的构造器会为我们创建一个数组。因为jdk版本的不太,创建的数组类型也就不一样。
jdk1.8之前构造方法会创造一个长度为16的Entry[] table数组,jdk1.8以及只有不再构造方法的时候创建数组,而是在第一次调用put方法的时候创建一个Node[] table数组,这点类似于ArrayList集合。
如下图所示,当要向HashMap中存入如下这些数据的时候,比如第一组数据“12,丽丽”的时候,首先会调用hash(key)方法计算出以key值为代表的对象的hashCode值,然后再根据某种算法,也就是方法indexFor(hash,length)(这个算法小编暂时也没搞明白,太难了)计算出k-value这个数据的哈希值,即这个数据在底层数组中的存储位置。如果计算出的哈希值对应的数组的索引地址刚好没有储存数据的话,就会直接将当前这个数据存储进去。比如:“12,丽丽”计算的哈希值是1,那么如果数组索引为1的位置没有储存数据的话,就会直接把丽丽这个数据存储进去。后面数据的存储方式就以此类推。
如果要插入的数据计算出的哈希值刚好与之前的某一个相同了,就比如下图中举的例子“12,明明”,刚好计算出的哈希值也是1,这样的话就与前面丽丽的一样了,这种情况我们称为哈希碰撞,也是哈希冲突。后面的“明明”的值就会替换掉“丽丽”的值,但是key值并没有替换,还是“丽丽”的key12。
如果,有一组要插入的数据“18,空空”,根据key计算的hashcode比如是8,但是呢,然后经过某种算法之后计算出的哈希值依旧是1,也就是存储在数组中索引的位置。由于空空计算出的哈希值也是1,那么就会与之前的丽丽、明明发生哈希碰撞,但是他们的key通过hashcode()方法计算出的hashcode不一样,也就不能替换,会在“明明”的前或者后面的位置重新创建一个位置,这样就会形成一种单链表。到底是在原来数据的前面位置插入还是后面插入,HashMap会采用“7上8下的原则”,也就是说,jdk版本是1.7以及之前的话,就会选择在前面插入从而形成链表,jdk1.8之后的话,就会选择在后面插入从而形成链表。这也对应了HashMap的底层为什么是数组+链表的原理了。
9. TreeMap, LinkedHashMap, HashMap的区别是什么?
-
HashMap的底层实现是散列表,因此它内部存储的元素是无序的;
-
TreeMap的底层实现是红黑树,所以它内部的元素的有序的。排序的依据是自然序或者是创建TreeMap时所提供的比较器(Comparator)对象。
-
LinkedHashMap可以看作能够记住插入元素的顺序的HashMap。
10.Collection与Collections的区别是什么?
- Collection是Java集合框架中的基本接口;
- Collections是Java集合框架提供的一个工具类,其中包含了大量用于操作或返回集合的静态方法。
11. 对于“try-catch-finally”,若try语句块中包含“return”语句,finally语句块会执行吗?
会执行。只有两种情况finally块中的语句不会被执行:**
-
调用了System.exit()方法;
-
JVM“崩溃”了。
12.Java中的异常层次结构
我们可以看到Throwable类是异常层级中的基类。
Error类表示内部错误,这类错误使我们无法控制的;
Exception表示异常,RuntimeException及其子类属于未检查异常,这类异常包括ArrayIndexOutOfBoundsException、NullPointerException等,我们应该通过条件判断等方式语句避免未检查异常的发生。
IOException及其子类属于已检查异常,常用于数据的读写,编译器会检查我们是否为所有可能抛出的已检查异常提供了异常处理器,,例如FileNotFoundException。
13.Override, Overload的含义与区别
重写必须继承,重载不用。
重写的方法名,参数数目相同,参数类型兼容,重载的方法名相同,参数列表不同。重写发生在子类和父类之间,重载发生再一个类中
重写的方法修饰符大于等于父类的方法,重载和修饰符无关。
重写不可以抛出父类没有抛出的一般异常,可以抛出运行时异常、
14.接口与抽象类的区别
定义的关键字不同
接口使用关键字 interface 来定义。 抽象类使用关键字 abstract 来定义。
继承或实现的关键字不同
接口使用 implements 关键字定义其具体实现。 抽象类使用 extends 关键字实现继承。
子类扩展数量不同
接口的实现类可以有多个,抽象类的子类只能继承一个父类
属性访问控制符不同
接口中只能是public,抽象类中可以是public、private、protect
静态代码块的使用不同
接口中不能使用静态代码块,抽象类中可以使用静态代码块。
15.简述Java中创建新线程的两种方法
继承Thread类(假设子类为MyThread),并重写run()方法,然后new一个MyThread对象并对其调用start()即可启动新线程。
实现Runnable接口(假设实现类为MyRunnable),而后将MyRunnable对象作为参数传入Thread构造器,在得到的Thread对象上调用start()方法即可。
16. 简述Java中进行线程同步的方法
- 使用synchronized关键字
- 使用ReentrantLock
- 使用原子变量实现线程同步
- 4.ThreadLocal实现线程同步
(ReentrantLock是显示锁,手动开启和关闭锁,别忘记关闭锁;
synchronized 是隐式锁,出了作用域自动释放;
ReentrantLock只有代码块锁,synchronized 有代码块锁和方法锁;
使用 ReentrantLock锁,JVM 将花费较少的时间来调度线程,线程更好,并且具有更好的扩展性(提供更多的子类);
使用顺序:
ReentrantLock> synchronized 同步代码块> synchronized 同步方法)
如果使用ThreadLocal管理变量,则每一个使用该变量的线程都获得该变量的副本,副本之间相互独立,这样每一个线程都可以随意修改自己的变量副本,而不会对其他线程产生影响,从而实现线程同步。
17.ThreadLocal的设计理念与作用
ThreadLocal的作用是提供线程内的局部变量,在多线程环境下访问时能保证各个线程内的ThreadLocal变量各自独立。也就是说,每个线程的ThreadLocal变量是自己专用的,其他线程是访问不到的。
ThreadLocal最常用于以下这个场景:多线程环境下存在对非线程安全对象的并发访问,而且该对象不需要在线程间共享,但是我们不想加锁,这时候可以使用ThreadLocal来使得每个线程都持有一个该对象的副本。
用来存储用户的session、处理数据库的连接或者数据库事务。
ThreadLocal<T>其实是与线程绑定的一个变量。ThreadLocal和Synchonized都用于解决多线程并发访问。
但是ThreadLocal与synchronized有本质的区别:
1、Synchronized用于线程间的数据共享,而ThreadLocal则用于线程间的数据隔离。
2、Synchronized是利用锁的机制,使变量或代码块在某一时该只能被一个线程访问。而ThreadLocal为每一个线程都提供了变量的副本
,使得每个线程在某一时间访问到的并不是同一个对象,这样就隔离了多个线程对数据的数据共享。
而Synchronized却正好相反,它用于在多个线程间通信时能够获得数据共享。






![BUUCTF[GXYCTF2019]Ping Ping Ping 1](https://img-blog.csdnimg.cn/f120e0d6d2bb4e71a8d33c61a9d24158.png)