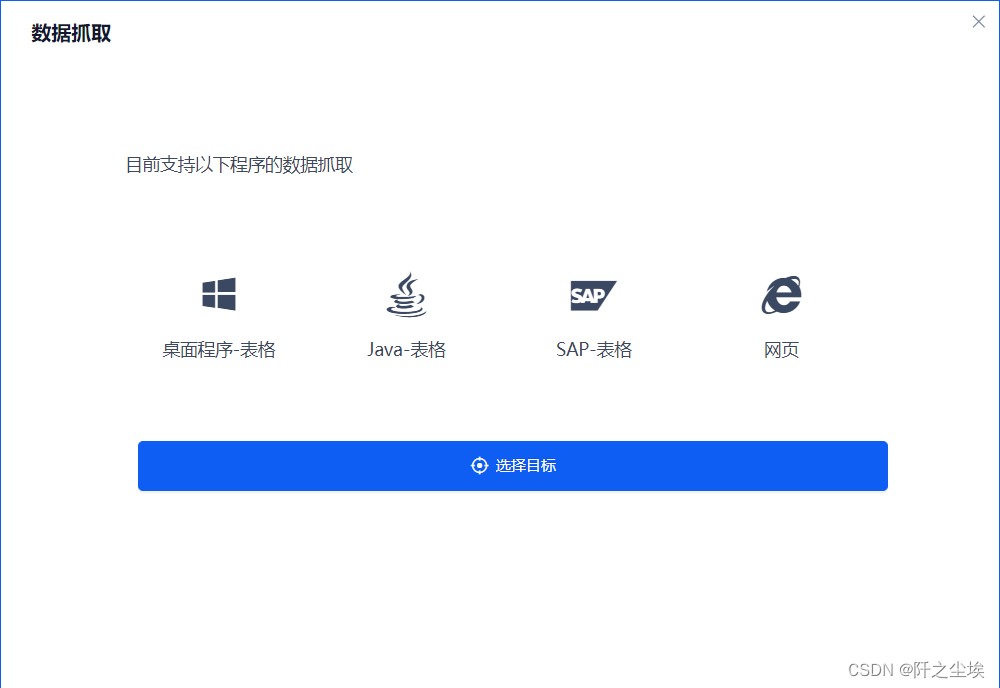
参考:数据获取和处理_UiBot开发者指南
Python爬虫要对网页文件结构有一定了解,而且写程序一点一点把数据弄出来也很麻烦。
但是Uibot爬取数据是很简单的。
全部流程不过几步,本次爬取某东手机商品的信息:
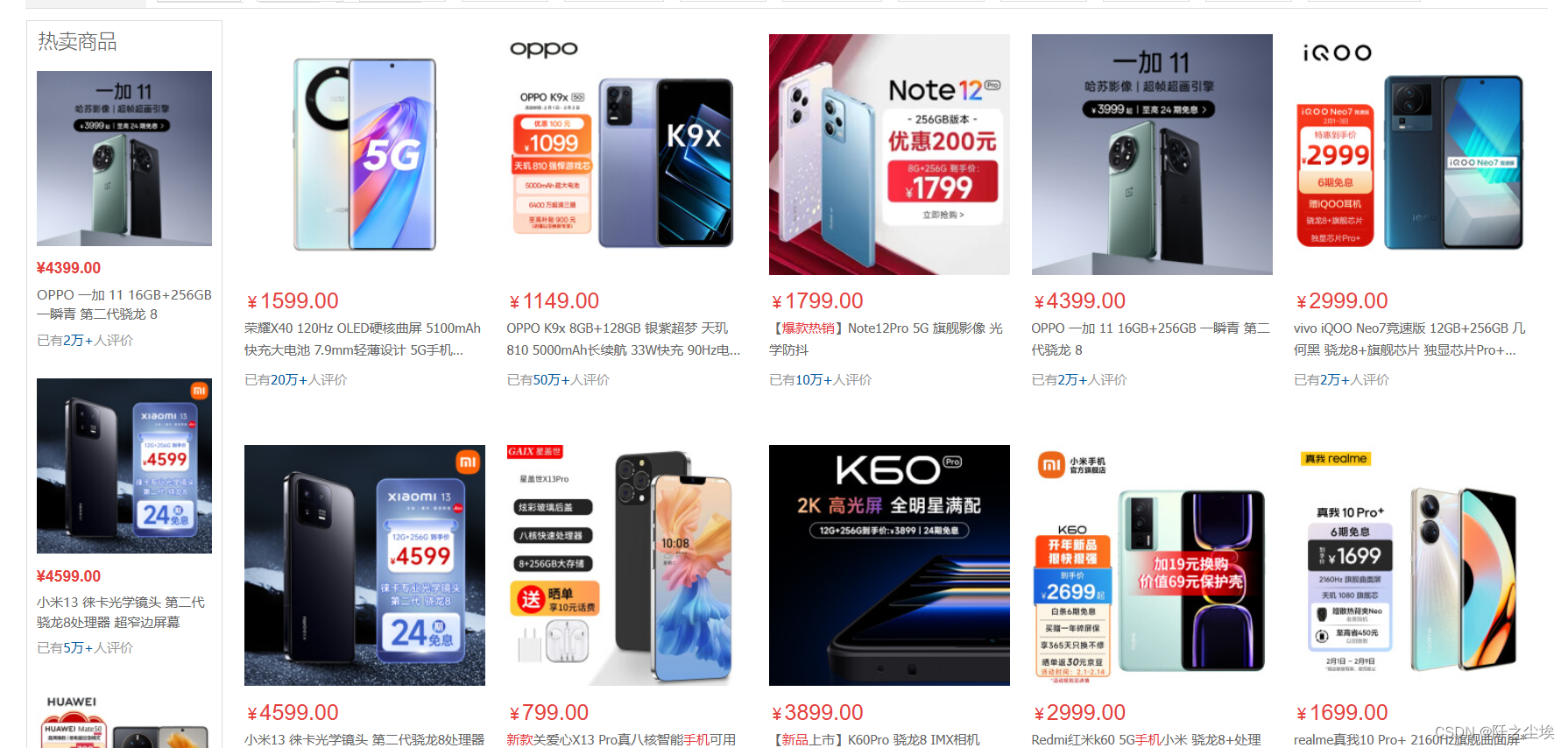
电商数据爬取
网页长这样,随便什么某宝某东搜索商品都有,链接:手机 - 商品搜索 - 京东热卖 (jd.com)
打开UIbot,选择数据抓取:
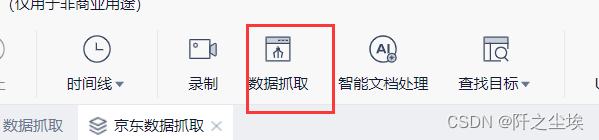
然后会让你选目标:
注意在Uibot6.1版本,需要电脑显示比例为100%才能用,没有100%他会提示你修改了后重启。
注意重启是重启整个Uibot。
然后就是选择你要爬取的元素,我这里选取商品价格和名称:
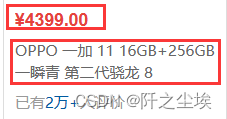
然后再选一次,跟着流程走就行。可以选择翻页,把翻页按钮放上去就行:

然后就生成了一条命令:

运行后数据在arrayData里面,可以测试打印看看。
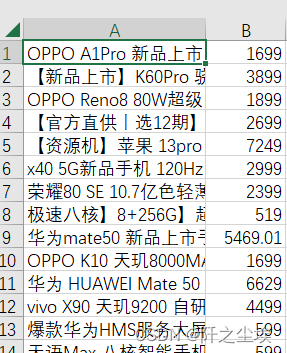
我后面又打开了一个EXCEL表,然后写入,报存,关闭。整体命令为:

然后路径下就会多一个excel表,效果还不错:
期刊等级查询
这个流程可以运用于任何网页,需要密码登陆的也行。比如我爬虫我们学校的期刊分级列表,也是一模一样的流程:
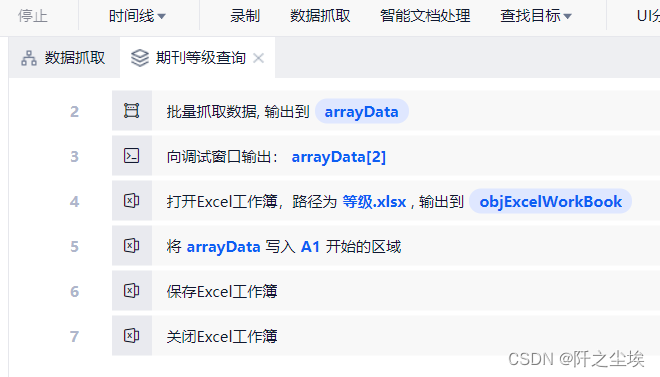
得到结果表:
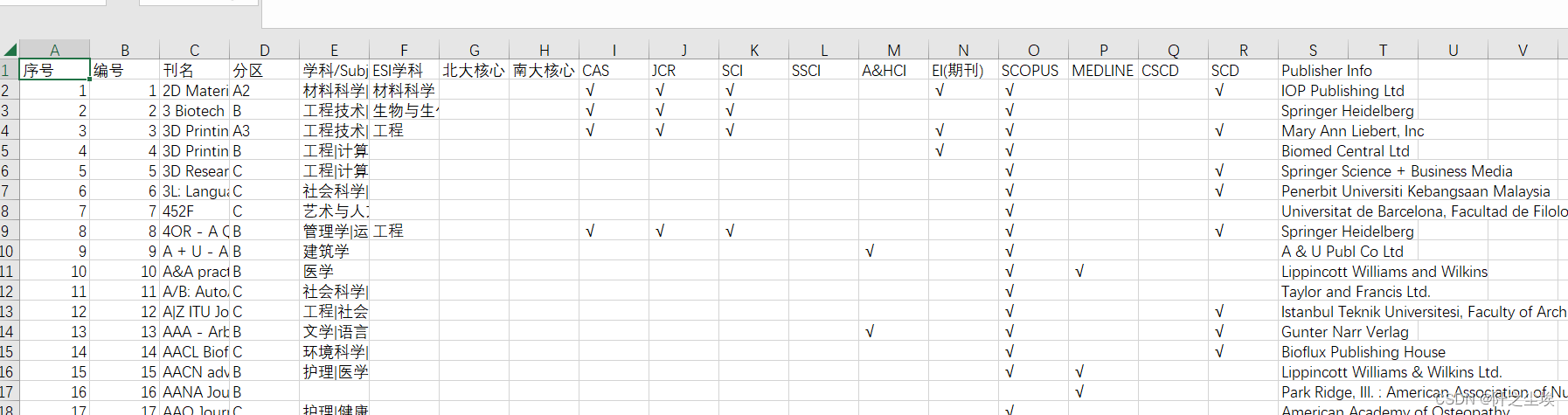
效果很好,而且很迅速,我早就想爬这个表了,方便自己找期刊,但是Python爬虫,首先需要能登陆这个网页,然后还要一层层找元素,太麻烦。
现在用Uibot就很快开发了这个爬虫程序,并且实现了,虽然它运行时间有点久...