Spark SQL函数定义
1、窗口函数
回顾之前学习过的窗口函数:
分析函数 over(partition by xxx order by xxx [asc|desc] [rows between xxx and xxx]) 分析函数可以大致分成如下3类: 1- 第一类: 聚合函数 sum() count() avg() max() min() 2- 第二类: 排序函数 row_number() rank() dense_rank() 3- 第三类: 其他函数 ntile() first_value() last_value() lead() lag() 三个排序函数的区别? row_number(): 巧记 1234 特点: 唯一且连续 rank(): 巧记 1224 特点: 并列不连续 dense_rank(): 巧记 1223 特点: 并列且连续
在Spark SQL中使用窗口函数案例:
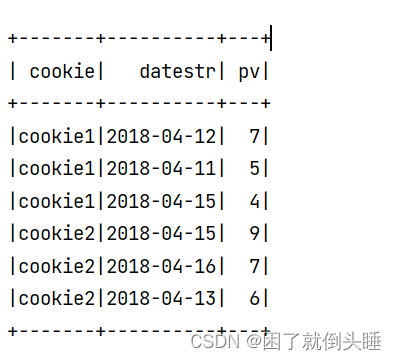
已知数据如下:
cookie1,2018-04-10,1 cookie1,2018-04-11,5 cookie1,2018-04-12,7 cookie1,2018-04-13,3 cookie1,2018-04-14,2 cookie1,2018-04-15,4 cookie1,2018-04-16,4 cookie2,2018-04-10,2 cookie2,2018-04-11,3 cookie2,2018-04-12,5 cookie2,2018-04-13,6 cookie2,2018-04-14,3 cookie2,2018-04-15,9 cookie2,2018-04-16,7
需求: 要求找出每个cookie中pv排在前3位的数据,也就是分组取TOPN问题
# 导包
import os
from pyspark.sql import SparkSession,functions as F,Window as W
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
# 2.数据输入
df = spark.read.csv(
path='file:///export/data/spark_project/spark_sql/data/cookie.txt',
sep=',',
schema='cookie string,datestr string,pv int'
)
# 3.数据处理(切分,转换,分组聚合)
# 4.数据输出
etldf = df.dropDuplicates().dropna()
# SQL方式
etldf.createTempView('cookie_logs')
spark.sql(
"""
select cookie,datestr,pv
from (
select cookie,datestr,pv,
dense_rank() over(partition by cookie order by pv desc) as rn
from cookie_logs
) temp where rn <=3
"""
).show()
# DSL方式
etldf.select(
'cookie', 'datestr', 'pv',
F.dense_rank().over( W.partitionBy('cookie').orderBy(F.desc('pv')) ).alias('rn')
).where('rn <=3').select('cookie', 'datestr', 'pv').show()
# 5.关闭资源
spark.stop()
运行结果截图:
2、自定义函数背景
2.1 回顾函数分类标准:
SQL函数,主要分为以下三大类:
-
UDF函数:普通函数
-
特点:一对一,输入一个得到一个
-
例如:split() ...
-
-
UDAF函数:聚合函数
-
特点:多对一,输入多个得到一个
-
例如:sum() avg() count() min() max() ...
-
-
UDTF函数:表生成函数
-
特点:一对多,输入一个得到多个
-
例如:explode() ...
-
在SQL中提供的所有的内置函数,都是属于以上三类中某一类函数
2.2 自定义函数背景
思考:有这么多的内置函数,为啥还需要自定义函数呢?
为了扩充函数功能。在实际使用中,并不能保证所有的操作函数都已经提前的内置好了。很多基于业务处理的功能,其实并没有提供对应的函数,提供的函数更多是以公共功能函数。此时需要进行自定义,来扩充新的功能函数
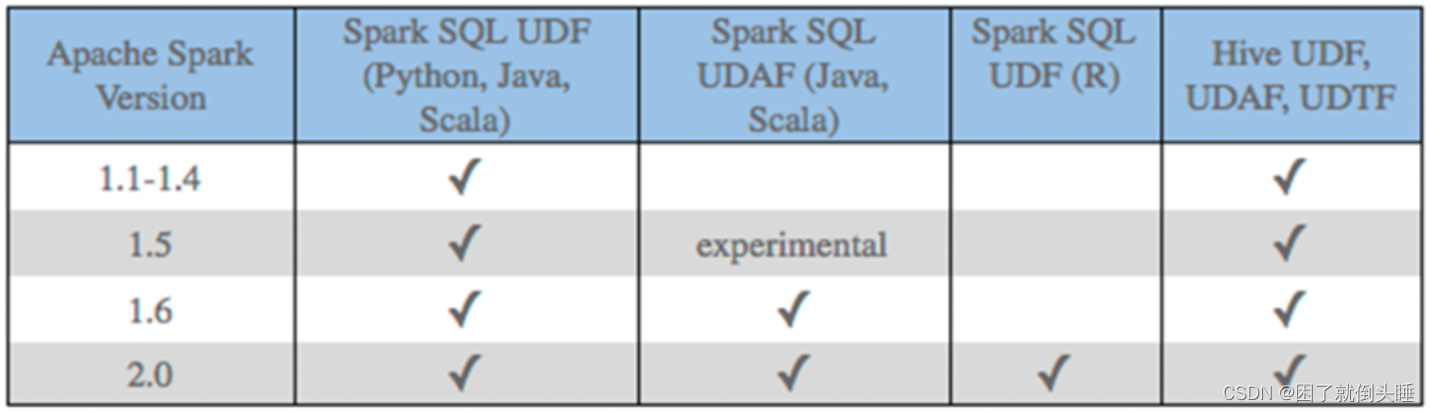
在Spark SQL中,针对Python语言,对于自定义函数,原生支持的并不是特别好。目前原生仅支持自定义UDF函数,而无法自定义UDAF函数和UDTF函数。
在1.6版本后,Java 和scala语言支持自定义UDAF函数,但Python并不支持。
1- SparkSQL原生的时候,Python只能开发UDF函数 2- SparkSQL借助其他第三方组件(Arrow,pandas...),Python可以开发UDF、UDAF函数,同时也提升效率
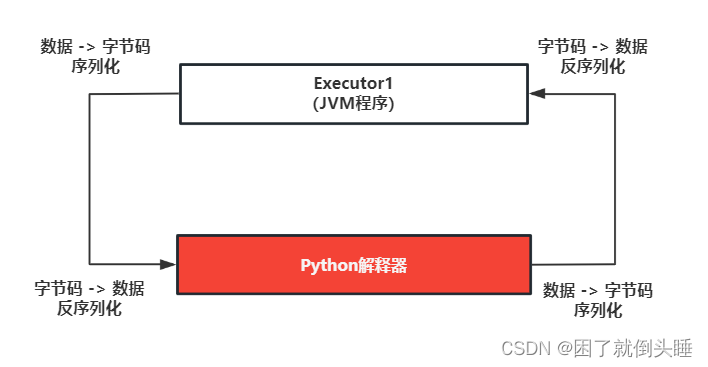
Spark SQL原生UDF函数存在的问题:大量的序列化和反序列
虽然Python支持自定义UDF函数,但是其效率并不是特别的高效。因为在使用的时候,传递一行处理一行,返回一行的方式。这样会带来非常大的序列化的开销的问题,导致原生UDF函数效率不好 早期解决方案: 基于Java/Scala来编写自定义UDF函数,然后基于python调用即可 目前主要的解决方案: 引入Arrow框架,可以基于内存来完成数据传输工作,可以大大的降低了序列化的开销,提供传输的效率,解决原生的问题。同时还可以基于pandas的自定义函数,利用pandas的函数优势完成各种处理操作





![暑假提升(3)[平衡二叉树之二--红黑树]](https://i-blog.csdnimg.cn/direct/f2964426c2cb4148ab29f5b79a4d5d4d.png)