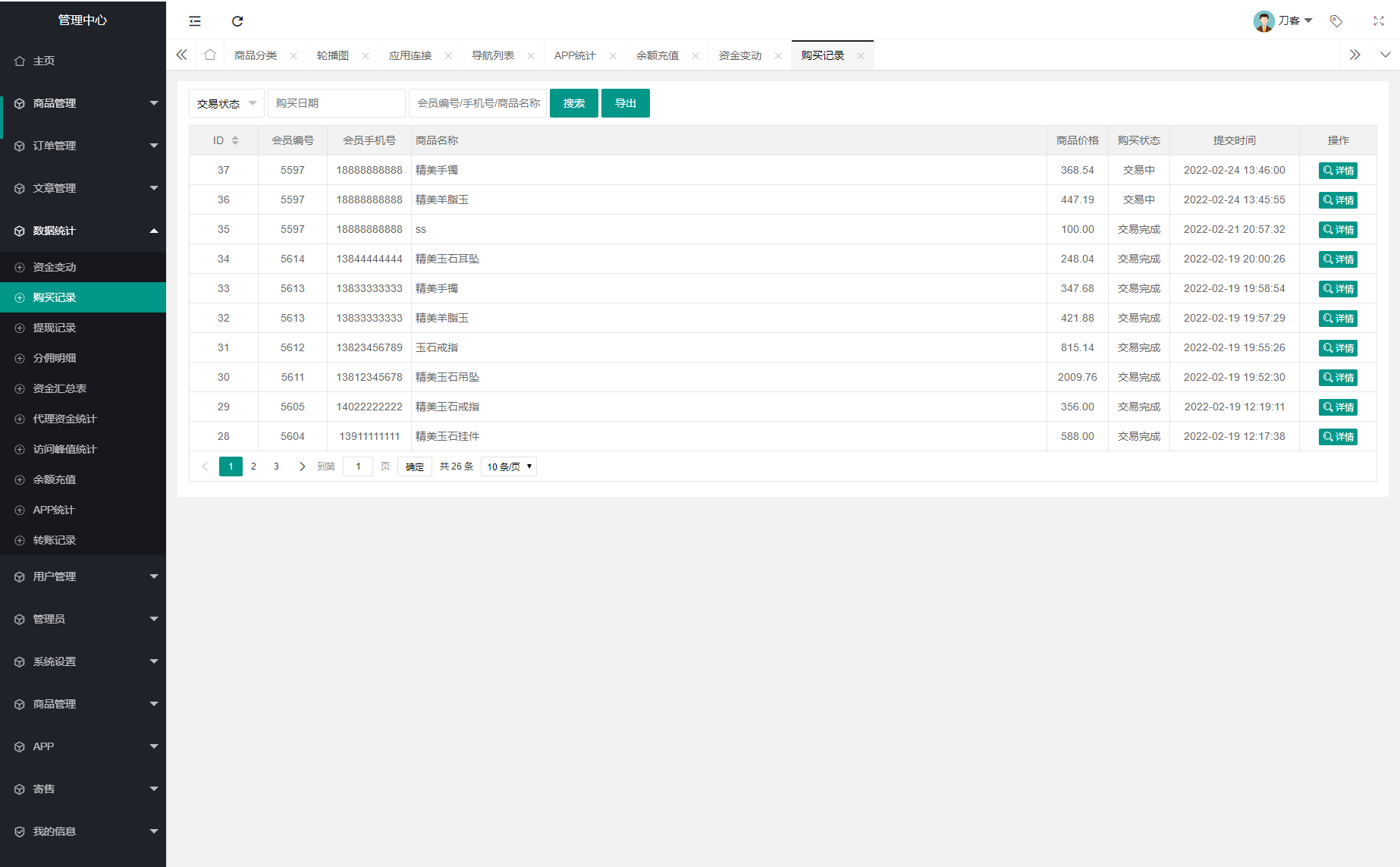
文章汇总


式中,
y
s
y^s
ys表示源域数据的one-hot ground-truth,
K
K
K为类数,
w
i
w_i
wi和
z
~
s
\tilde{z}_s
z~s分别表示源域经过提示调优的最终文本表示和最终图像表示的第
i
i
i类。
同理,为了进一步利用目标领域的数据,我们使用伪标签来训练这些未标记的数据。为了提高这些伪标签的可靠性,我们设置了一个固定的阈值
τ
\tau
τ。如果CLIP预测的给定图像的最大概率
τ
p
\tau_p
τp低于该阈值,则丢弃伪标签。同样,我们采用对比损失函数:

其中
I
(
⋅
)
\mathbb{I}(\cdot)
I(⋅)为指示函数,
y
~
t
\tilde{y}^t
y~t为目标域数据的one-hot ground-truth,
z
~
t
\tilde{z}^t
z~t为目标域经过提示调优后的最终图像表示(有IFT那个模块生成)。
如何构建特征库。
通过访问源域和目标域的数据,我们可以从两个域获得文本特征和图像特征。基于CLIP强大的Zero-shot inference能力,我们可以构建鲁棒准确的特征库。首先,我们用Zero-shot inference CLIP的预测为源域中的图像生成置信度分数(即最大概率)。类似地,我们为目标域中的每个图像生成置信度分数和相应的伪标签。具体来说,最大置信度得分的指标就是图像的伪标签。我们为源域和目标域选择在每个类别中置信度得分最高的图像的视觉特征,并构建一个K-way C-shot源域特征库和目标域特征库,其中K表示类别数量,C表示每个类别的样本数量。然后分别得到每一类的质心特征作为最终的源域特征库
z
s
c
z_{sc}
zsc和目标域特征库
z
t
c
z_{tc}
ztc。
IFT流程如下:

IFT利用特征库引导图像获得自增强和跨域特征,如图2(右)所示。我们首先使用一个权值共享的投影层
f
p
r
e
f_{pre}
fpre,即一个三层多层感知器,将图像特征
z
^
\hat z
z^、源域特征库
z
s
c
z_{sc}
zsc、目标域特征库
z
t
c
z_{tc}
ztc转化为查询、键和值,可以表示为:

我们使图像特征关注源域和目标域特征库,从而得到增强的图像特征。这些特征然后被另一个重量共享投影仪转换
f
p
o
s
t
f_{post}
fpost。注意整个过程可表述为:
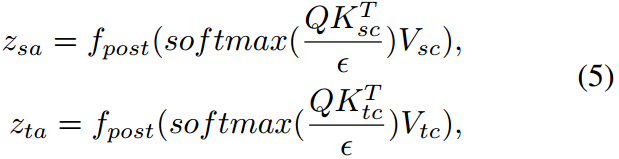
其中,
ϵ
\epsilon
ϵ表示尺度值,
T
T
T表示转置运算。然后,我们将一个加范数模块与原始的视觉特征结合起来,可以表示为:
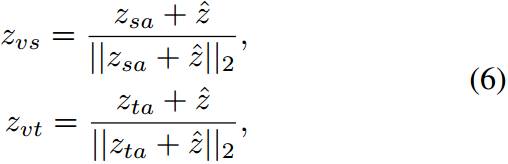
其中
∥
⋅
∥
2
\|\cdot\|_2
∥⋅∥2表示2范数。则最终的增广图像表示
z
^
\hat z
z^可表示为
β
1
z
v
s
+
β
2
z
v
t
\beta_1z_{vs}+\beta_2z_{vt}
β1zvs+β2zvt。
然后利用对比损失函数对源域和目标域的图像表示和特征库进行对齐,可以表示为:

其中
h
h
h表示IFT模块,
h
(
z
^
s
)
h(\hat z^s)
h(z^s)表示源域的增广图像表示。
与基分支相似,我们利用目标域的数据,得到目标域
z
^
t
\hat z^t
z^t的增广图像表示。则采用对比损失函数:

总损失如下:

摘要
最近,尽管大型预训练视觉语言模型(VLMs)在广泛的下游任务上取得了前所未有的成功,但现实世界的无监督域自适应(UDA)问题仍然没有得到很好的探索。因此,在本文中,我们首先通过实验证明了无监督训练的VLMs可以显著降低源域和目标域之间的分布差异,从而提高UDA的性能。然而,直接在下游UDA任务上部署这种模型的一个主要挑战是提示工程,这需要对齐源领域和目标领域的领域知识,因为UDA的性能受到良好的领域不变表示的严重影响。我们进一步提出了一种基于提示的分布对齐方法,将领域知识整合到提示学习中。具体而言,PDA采用两分支提示范式,即基础分支和对齐分支。基分支专注于将与类相关的表示集成到提示符中,确保不同类之间的区分。为了进一步减少域差异,在对齐分支中,我们分别为源域和目标域构建了特征库,并提出了图像引导特征调优(IFT),使输入关注特征库,有效地将自增强和跨域特征集成到模型中。这样,这两个分支可以相互促进,以增强VLMs对UDA的适应性。我们在三个基准上进行了广泛的实验,以证明我们提出的PDA达到了最先进的性能。代码可在https://github.com/BaiShuanghao/Prompt-basedDistribution-Alignment上获得。
1.介绍
无监督域自适应(UDA)旨在通过使用标记的源域和未标记的目标域来提高预训练模型在目标域的泛化性能(Wilson and Cook 2020;Zhu等2023年)。已经提出了许多方法来解决UDA问题,主要包括对抗性训练(Ganin和Lempitsky 2015;Rangwani et al 2022)和度量学习(Saito et al 2018;唐、陈、贾2020;张,Wang, and Gai 2020)。然而,通过领域对齐来缓解分布可能会无意中导致语义信息的丢失,这是因为语义和领域信息的纠缠性(Tang, Chen, and Jia 2020;Ge等人2022;Zhang, Huang, and Wang 2022)。
最近,像CLIP (Radford et al . 2021)这样的大型视觉语言模型(VLMs)在各种下游任务中表现出了令人印象深刻的泛化性能。通过分离视觉和语义表示,可以避免语义信息的丢失,提高UDA的性能。鉴于此,我们进行了一项实证实验,以证明VLMs对UDA问题的适用性。具体来说,我们评估了单模模型视觉变压器(ViT) (Dosovitskiy等人2021)和带有手工制作提示的zero-shot CLIP的性能。在图1中,尽管CLIP的源特征
r
(
I
s
)
r(I_s)
r(Is)和目标特征
r
(
I
t
)
r(I_t)
r(It)的紧密度与监督训练的ViT相似。,但最大平均差异(MMD)和KL散度(KL)最小,从而提高了目标域(Acc)的精度。这表明CLIP有可能将UDA的域差异最小化,从而受益于多模态相互作用。

图1:Office-Home的度量比较。值越高越好。
r
r
r度量特征的紧度(即类内
L
2
L_2
L2距离和类间
L
2
L_2
L2距离
L
2
i
n
t
e
r
L^{inter}_2
L2inter)。MMD和KL散度度量域差异。
T
,
I
s
T,I_s
T,Is和
I
t
I_t
It分别表示源域和目标域的文本特征和图像特征。该方法具有最易识别的文本特征、最紧凑的图像特征、最小的域差异和最佳的准确率。
为了进一步使VLM适应下游UDA任务,最有效的范例之一是提示调优。当前最先进的提示调优方法,如CoOp (Zhou等)2022b)和MaPLe (Khattak et al . 2023)在一些特定的下游任务上表现出了优越的性能。CoOp方法采用软提示学习合适的文本提示,MaPLe进一步引入视觉语言提示,确保相互协同。如图1所示,我们观察到1)与CLIP相比,MaPLe朝着对齐域迈出了一步,其较低的KL散度和MMD证明了这一点,这表明提示调优可以帮助最小化域移位。2) MaPLe的图像特征更加紧凑,提示调整可以进一步提高CLIP模型的判别能力。尽管如此,这些提示调优方法(如CoOp或MaPLe)可能不足以完全解决域转移问题,因为这些方法主要关注提示的位置,而可能无法直接解决域转移的潜在原因。因此,我们认为提示不仅要注重其设计,而且要通过将领域知识融入提示中来适应不同的领域。
为此,我们提出了一种基于提示的分布对齐(PDA,Prompt-based Distribution Alignment)方法。PDA由两个支路组成,即基支路和对准支路。基本分支生成带有提示调优的图像和文本表示,其重点是将与类相关的表示集成到提示中,确保每个领域的不同类之间的区分。UDA的主要目标是最小化图像表示的分布偏移。对齐分支利用图像表示引入领域知识,使领域差异最小化。为此,我们首先构建源域和目标域特征库,并提出图像引导特征调优(IFT),使输入的图像表示关注特征库,从而有效地将自增强和跨域特征集成到模型中。如图1所示,PDA不仅在获得更容易区分的图像和文本表示方面表现出色,而且还有效地缓解了域差异。因此,我们的方法可以保证模型的可分辨性,并有效地捕获源域和目标域的重要特征,从而实现域对齐,使模型更好地适应目标域。我们的主要贡献如下:
•我们首先通过实验验证了VLM在UDA下游任务上的有效性。然后,在此基础上,我们进一步提出了一种基于提示的分布对齐(PDA)方法来将提示调整到目标域。
•提出的PDA包括两个训练分支。首先,基分支确保了不同类之间的区别。其次,对齐分支通过图像引导特征调优获得域不变信息;
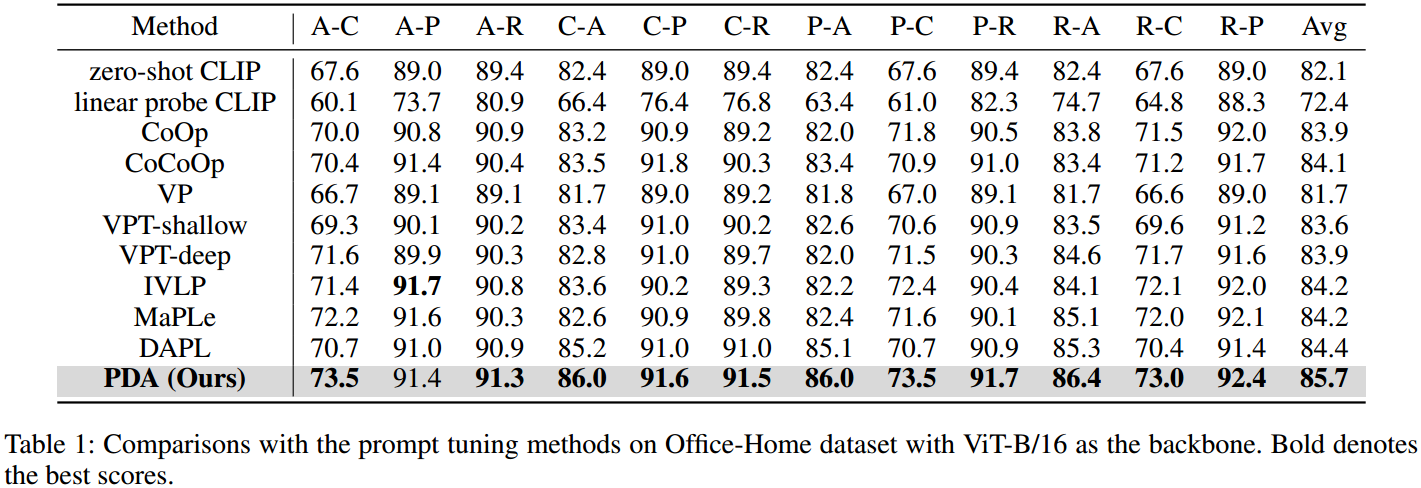
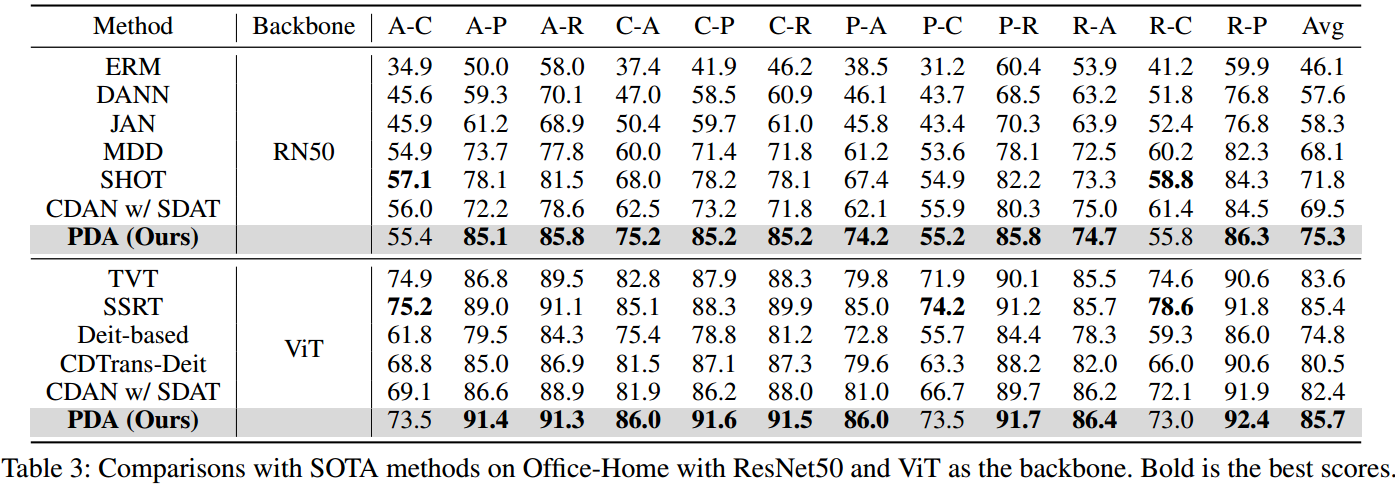
•广泛的实验证明了所提出的PDA的有效性,它在Office-Home, Office-31和VisDA-2017上实现了最先进的性能。
2.相关工作
2.1无监督域自适应
无监督域自适应(UDA)旨在通过学习域不变特征表示来对齐源域和目标域(Zhang等人2023b;Chen, Xiao, and Kuang 2022;Xiao et al . 2022)。一种对齐域的方法是最小化不同域之间的散度。已经提出了许多散度度量,如最大平均差异(MMD) (Long et al . 2015),相关对齐(CORAL) (Sun, Feng, and Saenko 2016)和最大密度散度(MDD) (Zhang et al . 2019)。另一种工作是由对抗性学习的成功所激发的。通过将优化过程建模为极大极小问题(Ganin and Lempitsky 2015;Long等人2018;Rangwani et al . 2022;Xiao et al . 2021),引入了一个域鉴别器来区分来自不同域的样本,目的是训练模型生成可以欺骗域鉴别器的域不变特征。随着变压器模型的出现,TVT (Yang et al . 2023)提出了一种自适应模块来获得可转移和可判别的特征,CDTrans (Xu et al . 2022)利用交叉关注模块的鲁棒性,提出了一种跨域变压器来直接对特征进行校准。与这些主流的单模态UDA方法不同,我们专注于利用视觉语言模型固有的可转移性,由于多模态交互,视觉语言模型显示出有希望的领域对齐能力。
2.2视觉语言模型
预训练的视觉语言模型(VLMs)通过各种预训练任务学习图像-文本相关性,例如掩膜语言建模(Kim, Son, and Kim 2021),掩膜语言建模(Tan and Bansal 2019),图像文本匹配(Huang et al 2021)和对比学习(Jia et al 2021;张等2022a;Chen et al . 2021)。尽管这些模型在包括零热和少量视觉识别在内的广泛任务中取得了前所未有的成功,但将它们有效地适应下游任务仍然是一个艰巨的挑战。已经提出了许多工作,通过引入额外的特征适配器来增强下游任务的泛化能力(Gao等人2021;张等2023a;Bai et al . 2024)、注意力(Guo et al . 2023)、缓存模型(Zhang et al . 2022b)等。提示学习范式最初用于自然语言处理(NLP)领域,也被集成到VLMs中,成为在各种下游任务中微调VLMs的最有效方法之一。在这项工作中,我们遵循提示学习方法的路线,提出了一种基于提示的分布对齐方法,以提高CLIP的可转移性,以解决UDA问题。
2.3视觉语言模型的提示微调
提示微调是参数高效调谐的重要组成部分之一,其目的是通过输入组合(Pfeiffer等)只学习少量的参数2023;Zhu et al . 2023b),同时保持大模型固定。CoOp (Zhou et al . 2022b)首次在VLM中引入了软提示,证明了合适的文本提示可以提高图像识别性能。CoCoOp (Zhou et al .2022a)通过集成轻量级神经网络对CoOp进行扩展,为单个图像动态生成提示,以处理提示的过拟合问题。VPT (Jia et al 2022)在变压器模型中使用一些视觉提示实现了令人印象深刻的结果。此外,MaPLe (Khattak et al . 2023)将文本和视觉提示结合到CLIP中,以改善文本和图像表示之间的对齐。为了利用UDA(无监督域自适应)提示调优的有效性,我们引入了一个由基分支和对齐分支组成的双分支训练范式。基础分支利用提示调优来增强CLIP模型的可辨别性。对于对齐分支,我们设计了一个图像引导的特征调优来减轻域差异。
3 Preliminaries
3.1无监督域适应
UDA侧重于利用源域的标记数据和目标域的未标记数据来提高模型的泛化性能。形式上,给定源域的标记数据集 D S = { x i s , y i s } i = 1 n s D_S=\{x^s_i,y_i^s\}^{n_s}_{i=1} DS={xis,yis}i=1ns,未标记数据集 D t = { x j t } j = 1 n t D_t=\{x^t_j\}^{n_t}_{j=1} Dt={xjt}j=1nt,其中 n s n_s ns和 n t n_t nt分别表示源域和目标域的样本大小。注意,两个域的数据是从两个不同的分布中采样的,我们假设这两个域共享相同的标签空间。我们将输入空间表示为 X X X,将标签集表示为 Y Y Y。有一个从图像到标签的映射 M : { X } → Y M:\{X\}\rightarrow Y M:{X}→Y。在这项工作中,我们将提示符 V V V合并到输入中,因此从图像和提示符到标签的映射可以重新表述为 M : { X , V } → Y M:\{X,V\}\rightarrow Y M:{X,V}→Y。我们的目标是缓解 D S D_S DS和 D t D_t Dt之间的领域差异问题,并学习一个可以促进知识从源领域转移到目标领域的广义提示 P P P。
3.2回顾提示学习
对比语言-图像预训练(CLIP)模型由图像编码器和文本编码器组成,分别对图像和相应的自然语言描述进行编码。
Zero-shot inference。预训练的CLIP模型适应于具有手工提示的下游任务,而不是对模型进行微调。文本总是手动设计为“a photo of a [CLASS]”([CLASS]是类标记)。使用图像表示
z
z
z与对应第
i
i
i类的文本表示
w
i
w_i
wi之间的余弦相似度
s
i
m
(
w
i
,
z
)
sim(w_i,z)
sim(wi,z)计算图像-文本匹配分数。图像表示从具有输入图像的图像编码器中派生,而文本表示
w
i
w_i
wi使用与第
i
i
i类关联的提示描述从文本编码器中提取。图像属于第
i
i
i类的概率可表示为:

式中
t
t
t为温度参数,
K
K
K为类数,
s
i
m
sim
sim为余弦相似度。
文本提示调优。避免了人工提示工程,增强了CLIP的传递能力。CoOp (Zhou et al . 2022b)引入了一组
M
M
M个连续可学习上下文向量
v
=
[
v
1
,
v
2
,
.
.
.
,
v
M
]
v=[v^1,v^2,...,v^M]
v=[v1,v2,...,vM],则第
i
i
i类文本提示符
t
i
t^i
ti定义为
t
i
=
[
v
,
c
i
]
t^i = [v,c^i]
ti=[v,ci],其中
c
i
c^i
ci为固定输入令牌嵌入。可学习的上下文向量可以扩展到基于transformer架构的文本编码器的更深层次的transformer层,因此每层输入可以重新表述为
[
v
j
,
c
j
]
j
=
1
J
[v_j,c_j]^J_{j=1}
[vj,cj]j=1J,其中
J
J
J为文本编码器中的transformer层数,
[
⋅
,
⋅
]
[\cdot,\cdot]
[⋅,⋅]表示连接操作。
视觉提示调整。它采用了与文本提示调优类似的范例,其中自动学习输入到图像编码器的每一层的附加上下文向量。对于基于transformer的图像编码器,VPT (Jia et al . 2022)在一系列patch embedding
e
e
e和可学习的类令牌
c
c
c之间插入提示符集合
v
~
\tilde{v}
v~,可设计为
[
v
~
j
,
e
j
,
c
j
]
j
=
1
J
[\tilde{v}_j,e_j,c_j]^J_{j=1}
[v~j,ej,cj]j=1J。
多模态提示协调。文本提示符
v
v
v和可视提示符
v
~
\tilde{v}
v~组合成CLIP。例如,MaPLe (Khattak et al . 2023)通过在两种模式之间共享提示来调整CLIP的视觉和语言分支。
4.方法
受上一节观察结果的启发,我们尝试为UDA设计一种高效且有效的提示调优方法。为了增强提示的可转移性,我们提出了一种基于提示的分布对齐(PDA)方法,其框架如图2所示。我们介绍我们的PDA方法如下。
图2:提出的基于提示的分布对齐(PDA)方法的概述。雪表示冻结的参数,火表示可学习的参数。从左到右,我们分别展示了PDA的详细框架和IFT模块的架构。我们的PDA方法主要采用多模态提示调谐。此外,IFT模块使视觉特征参加源/目标域特征库进行域对齐。
4.1 Prompting for Base Branch

提示的设计。我们主要采用多模式提示模式。对于图像编码器的早期层,使用文本提示符通过投影层生成视觉提示符。这意味着使用文本提示来指导图像的编码过程,使图像在特征空间中具有与给定文本相关的信息,从而实现图像与相关文本信息的对齐。对于图像编码器的后一层,每一层使用一个独立的提示符。这种设计允许每一层独立捕获图像的不同视觉和语义特征,实现更好的图像-文本交互,捕获不同的视觉和语义特征。
损失函数。然后使用对比损失函数对图像和文本表示进行对齐,可以表示为:
式中,
y
s
y^s
ys表示源域数据的one-hot ground-truth,
K
K
K为类数,
w
i
w_i
wi和
z
~
s
\tilde{z}_s
z~s分别表示源域经过提示调优的最终文本表示和最终图像表示的第
i
i
i类。
为了进一步利用目标领域的数据,我们使用伪标签来训练这些未标记的数据,如Ge等人(Ge et al 2022)。伪标签由CLIP模型的预测生成。为了提高这些伪标签的可靠性,我们设置了一个固定的阈值
τ
\tau
τ。如果CLIP预测的给定图像的最大概率
τ
p
\tau_p
τp低于该阈值,则丢弃伪标签。同样,我们采用对比损失函数:
其中
I
(
⋅
)
\mathbb{I}(\cdot)
I(⋅)为指示函数,
y
~
t
\tilde{y}^t
y~t为目标域数据的one-hot ground-truth,
z
~
t
\tilde{z}^t
z~t为目标域经过提示调优后的最终图像表示。
4.2 Pipeline of Alignment Branch
对于对齐分支,我们为源域和目标域构建特征库,并提出图像引导特征调优(IFT),使输入关注特征库以实现域对齐。
构建特征库。通过访问源域和目标域的数据,我们可以从两个域获得文本特征和图像特征。基于CLIP强大的Zero-shot inference能力,我们可以构建鲁棒准确的特征库。首先,我们用Zero-shot inference CLIP的预测为源域中的图像生成置信度分数(即最大概率)。类似地,我们为目标域中的每个图像生成置信度分数和相应的伪标签。具体来说,最大置信度得分的指标就是图像的伪标签。我们为源域和目标域选择在每个类别中置信度得分最高的图像的视觉特征,并构建一个K-way C-shot源域特征库和目标域特征库,其中K表示类别数量,C表示每个类别的样本数量。然后分别得到每一类的质心特征作为最终的源域特征库
z
s
c
z_{sc}
zsc和目标域特征库
z
t
c
z_{tc}
ztc。
图像引导特征调整(IFT)。IFT利用特征库引导图像获得自增强和跨域特征,如图2(右)所示。我们首先使用一个权值共享的投影层
f
p
r
e
f_{pre}
fpre,即一个三层多层感知器,将图像特征
z
^
\hat z
z^、源域特征库
z
s
c
z_{sc}
zsc、目标域特征库
z
t
c
z_{tc}
ztc转化为查询、键和值,可以表示为:
我们使图像特征关注源域和目标域特征库,从而得到增强的图像特征。这些特征然后被另一个重量共享投影仪转换
f
p
o
s
t
f_{post}
fpost。注意整个过程可表述为:
其中,
ϵ
\epsilon
ϵ表示尺度值,
T
T
T表示转置运算。然后,我们将一个加范数模块与原始的视觉特征结合起来,可以表示为:
其中
∥
⋅
∥
2
\|\cdot\|_2
∥⋅∥2表示2范数。则最终的增广图像表示
z
^
\hat z
z^可表示为
β
1
z
v
s
+
β
2
z
v
t
\beta_1z_{vs}+\beta_2z_{vt}
β1zvs+β2zvt。
损失函数。然后利用对比损失函数对源域和目标域的图像表示和特征库进行对齐,可以表示为:
其中
h
h
h表示IFT模块,
h
(
z
^
s
)
h(\hat z^s)
h(z^s)表示源域的增广图像表示。
与基分支相似,我们利用目标域的数据,得到目标域
z
^
t
\hat z^t
z^t的增广图像表示。则采用对比损失函数:
因此,我们的PDA方法可以使用总对比损失进行端到端训练:
其中
γ
\gamma
γ是超参数。在测试阶段,我们计算来自基础分支和对齐分支的预测的加权和,从而得到我们模型的最终预测。这两个分支不仅对增强模型的可分辨性,而且对调整源域和目标域之间的分布转移至关重要。
5.实验


如图3所示,我们通过t-SNE将zero-shot CLIP、MaPLe和PDA在三个数据集中的四个任务上提取的图像特征可视化。我们可以观察到,我们的PDA方法可以更好地对齐两个域。
6.结论
在本文中,我们证明了视觉语言模型和VLM的提示调优对于无监督域自适应的有效性。在此基础上,我们将分布对齐引入到提示调优中,提出了一种基于提示的分布对齐方法。这两个分支不仅在提高模型的可分辨性方面起着至关重要的作用,而且在减轻源域和目标域之间的分布转移方面起着至关重要的作用。大量的实验证实了我们提出的方法的有效性,我们的PDA方法在无监督域自适应方面取得了新的最先进的性能。由于学习提示的可转移性,我们可以在未来的工作中进一步探索无监督域适应或其他下游任务的提示对齐。
参考资料
论文下载(AAAI 2024)
https://arxiv.org/abs/2312.09553v2

代码地址
https://github.com/BaiShuanghao/Prompt-based-Distribution-Alignment