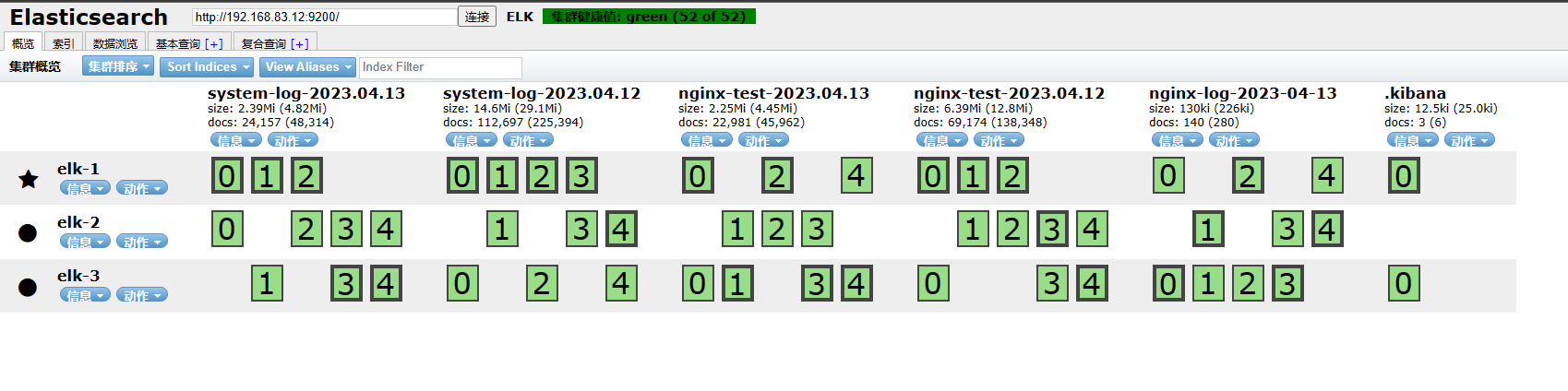
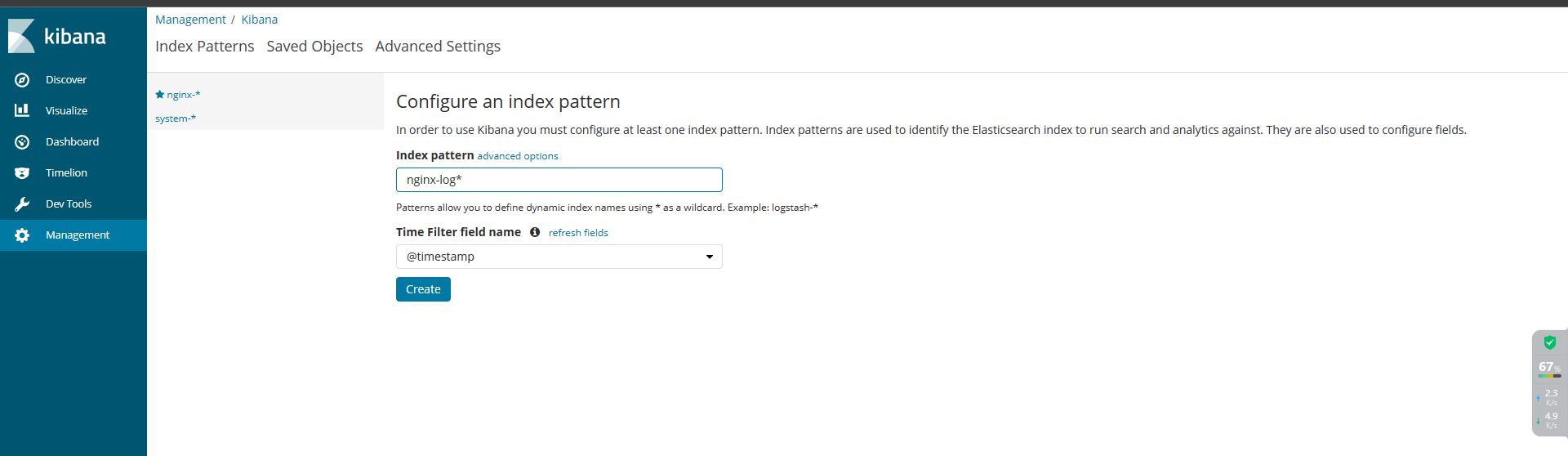
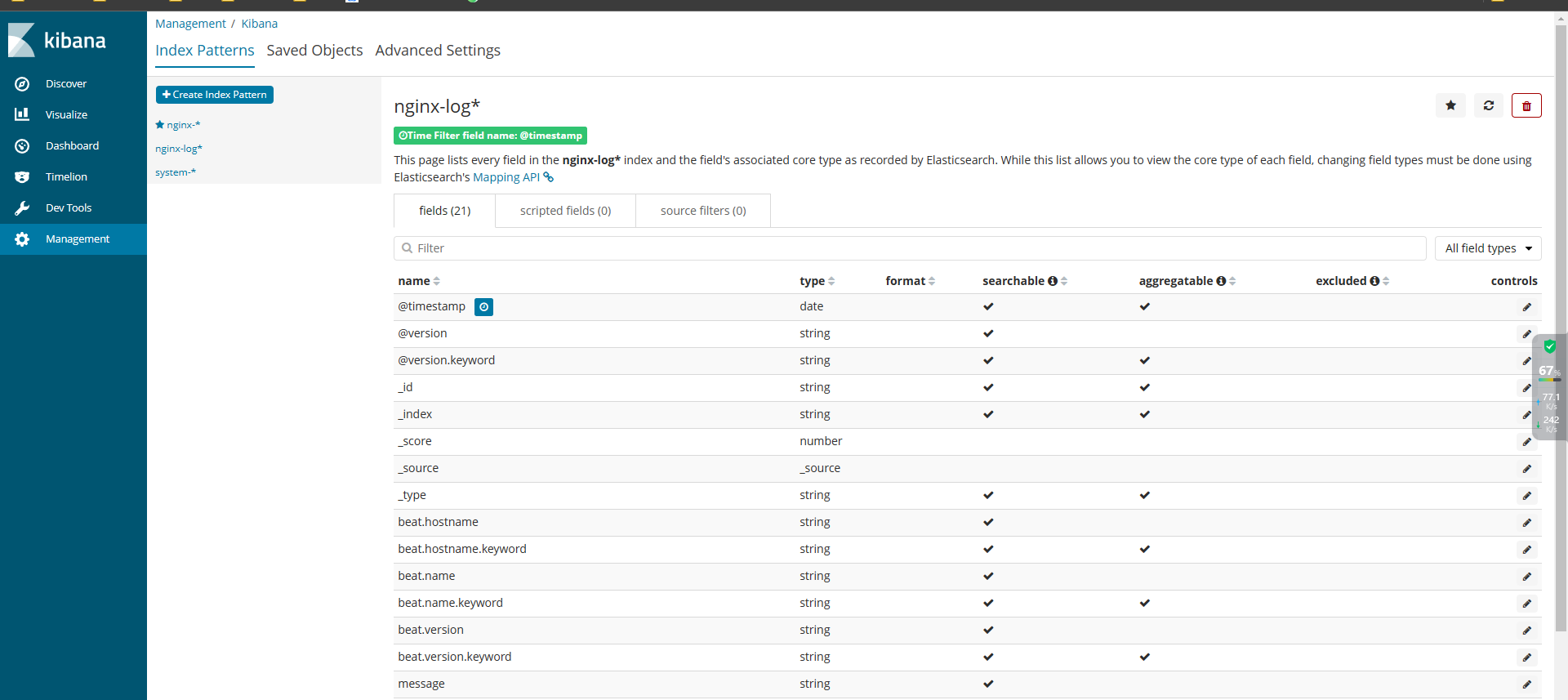
本实验基于ELFK已经搭好的情况下 ELK日志分析
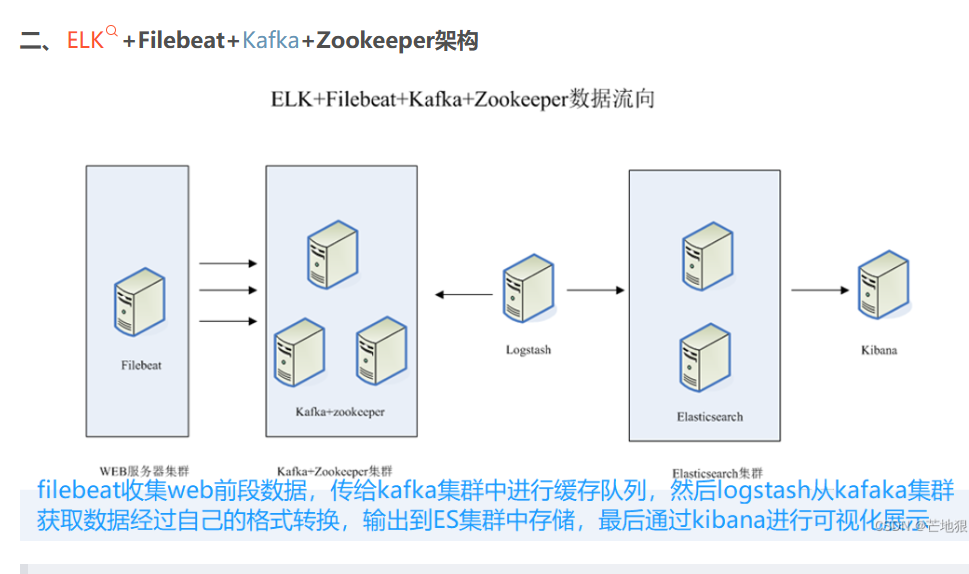
架构解析
第一层、数据采集层
数据采集层位于最左边的业务服务器集群上,在每个业务服务器上面安装了filebeat做日志收集,然后把采集到的原始日志发送到Kafka+zookeeper集群上。
第二层、消息队列层
原始日志发送到Kafka+zookeeper集群上后,会进行集中存储,此时,filbeat是消息的生产者,存储的消息可以随时被消费。
第三层、数据分析层
Logstash作为消费者,会去Kafka+zookeeper集群节点实时拉取原始日志,然后将获取到的原始日志根据规则进行分析、清洗、过滤,最后将清洗好的日志转发至Elasticsearch集群。
第四层、数据持久化存储
Elasticsearch集群在接收到logstash发送过来的数据后,执行写磁盘,建索引库等操作,最后将结构化的数据存储到Elasticsearch集群上。
第五层、数据查询、展示层
Kibana是一个可视化的数据展示平台,当有数据检索请求时,它从Elasticsearch集群上读取数据,然后进行可视化出图和多维度分析。
搭建ELK+Filebeat+Kafka+Zookeeper
zIP: 所属集群: 端口:
192.168.83.11 Elasticsearch+Kibana+kafka+zookeeper+nginx反向代理 9100 9200 5601 9092 3288 8080 都可以安装filebeat
192.168.83.12 Elasticsearch+Logstash+kafka+zookeeper+filebeat+nginx反向代理 9100 9200 9600 9092 3288 随机 8080
192.168.83.13 Elasticsearch+kafka+zookeeper+nginx反向代理 z 9100 9200 9092 3288
root@elk2 ~]# netstat -antp |grep filebeat
tcp 1 0 192.168.83.12:40348 192.168.83.11:9092 CLOSE_WAIT 6975/filebeat
tcp 0 0 192.168.83.12:51220 192.168.83.12:9092 ESTABLISHED 6975/filebeat
1.3台机子安装zookeeper
wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz --no-check-certificate
1.1 解压安装zookeeper软件包
cd /opt
上传apache-zookeeper-3.8.0-bin.tar.gz包
tar zxf apache-zookeeper-3.8.0-bin.tar.gz 解包
mv apache-zookeeper-3.8.0-bin /usr/local/zookeeper-3.8.0 #将解压的目录剪切到/usr/local/
cd /usr/local/zookeeper-3.8.0/conf/
cp zoo_sample.cfg zoo.cfg 备份复制模板配置文件为zoo.cfg
1.2 修改Zookeeper配置配置文件
cd /usr/local/zookeeper-3.8.0/conf #进入zookeeper配置文件汇总
ls 后可以看到zoo_sample.cfg模板配置文件
cp zoo_sample.cfg zoo.cfg 复制模板配置文件为zoo.cfg
mkdir -p /usr/local/zookeeper-3.8.0/data
mkdir -p dataLogDir=/usr/local/zookeeper-3.8.0/1ogs
vim zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/usr/local/zookeeper-3.8.0/data
dataLogDir=/usr/local/zookeeper-3.8.0/1ogs
# the port at which the clients will connect
clientPort=2181
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpHost=0.0.0.0
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
server.1=192.168.83.11:3188:3288
server.2=192.168.83.12:3188:3288
server.3=192.168.83.13:3188:3288
scp zoo.cfg elk2:/usr/local/zookeeper-3.8.0/conf/zoo.cfg
scp zoo.cfg elk3:/usr/local/zookeeper-3.8.0/conf/zoo.cfg
1.3 设置myid号以及启动脚本 到这里就不要设置同步了,下面的操作,做好一台机器一台机器的配置。
echo 1 >/usr/local/zookeeper-3.8.0/data/myid
# node1上配置
echo 2 >/usr/local/zookeeper-3.8.0/data/myid
#node2上配置
echo 3 >/usr/local/zookeeper-3.8.0/data/myid
#node3上配置
1.4 两种启动zookeeper的方法
cd /usr/local/zookeeper-3.8.0/bin
ls
./zkServer.sh start #启动 一次性启动三台,,才可以看状态
./zkServer.sh status #查看状态
[root@elk1 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.8.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
[root@elk2 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.8.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: leader
[root@elk3 bin]# ./zkServer.sh status
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper-3.8.0/bin/../conf/zoo.cfg
Client port found: 2181. Client address: localhost. Client SSL: false.
Mode: follower
1.5脚本启动 推荐
第2种启动
3台节点需要执行的脚本
#//配置启动脚本,脚本在开启启动执行的目录中创建
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.8.0'
case $1 in
start)
echo "----------zookeeper启动----------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper停止-----------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
cd /usr/local/zookeeper-3.8.0/bin
在节点1服务操作
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper #加入到系统管理
service zookeeper start 启动服务
service zookeeper status 查看状态后 是 follower
在节点2服务操作
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper #加入到系统管理
service zookeeper start 启动服务
service zookeeper status 查看状态后 是 leader 第二台启动的,他是leader
在节点3服务操作
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper #加入到系统管理
service zookeeper start 启动服务
service zookeeper status 查看状态后 是 follower
2. 安装 kafka(3台机子都要操作)
#下载kafka
cd /opt
wget http://archive.apache.org/dist/kafka/2.7.1/kafka_2.13-2.7.1.tgz
上传kafka_2.13-2.7.1.tgz到/opt
tar zxf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
2.2 修改配置文件
cd /usr/local/kafka/config/
cp server.properties server.properties.bak
vim server.properties
192.168.83.11配置
broker.id=1
listeners=PLAINTEXT://192.168.83.11:9092
zookeeper.connect=192.168.83.11:2181,192.168.83.12:2181,192.168.83.13:2181
192.168.83.13配置
broker.id=2
listeners=PLAINTEXT://192.168.83.12:9092
zookeeper.connect=192.168.83.11:2181,192.168.83.12:2181,192.168.83.13:21810:2181
192.168.83.13配置
broker.id=3
listeners=PLAINTEXT://192.168.83.13:9092
zookeeper.connect=192.168.83.11:2181,192.168.83.12:2181,192.168.83.13:2181
2.3 将相关命令加入到系统环境当中
vim /etc/profile 末行加入
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
source /etc/profile
[root@elk1 config]# scp /etc/profile elk2:/etc/profile
profile 100% 1888 1.4MB/s 00:00
[root@elk1 config]# scp /etc/profile elk3:/etc/profile
profile
2.3 将相关命令加入到系统环境当中
cd /usr/local/kafka/config/
kafka-server-start.sh -daemon server.properties
netstat -antp | grep 9092
2.4Kafka 命令行操作
创建topic
kafka-topics.sh --create --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181 --replication-factor 2 --partitions 3 --topic test
–zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
–replication-factor:定义分区副本数,1 代表单副本,建议为 2
–partitions:定义分区数
–topic:定义 topic 名称
查看当前服务器中的所有 topic
kafka-topics.sh --list --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181
查看某个 topic 的详情
kafka-topics.sh --describe --zookeeper 192.168.121.10:2181,192.168.121.12:2181,192.168.121.14:2181
发布消息
kafka-console-producer.sh --broker-list 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test
消费消息
kafka-console-consumer.sh --bootstrap-server 192.168.121.10:9092,192.168.121.12:9092,192.168.121.14:9092 --topic test --from-beginning
–from-beginning:会把主题中以往所有的数据都读取出来
修改分区数
kafka-topics.sh
--zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --alter --topic test --partitions 6
删除 topic
kafka-topics.sh
--delete --zookeeper 192.168.80.10:2181,192.168.80.11:2181,192.168.80.12:2181 --topic test
3.配置数据采集层filebeat
3.1 定制日志格式
3.1 定制日志格式
[root@elk2 ~]# vim /etc/nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log notice;
pid /var/run/nginx.pid;
events
{
worker_connections 1024;
}
http
{
include /etc/nginx/mime.types;
default_type application/octet-stream;
# log_format main2 '$http_host $remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$upstream_addr" $request_time';
# access_log /var/log/nginx/access.log main2;
log_format json '{"@timestamp":"$time_iso8601",'
'"@version":"1",'
'"client":"$remote_addr",'
'"url":"$uri",'
'"status":"$status",'
'"domain":"$host",'
'"host":"$server_addr",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"referer": "$http_referer",'
'"ua": "$http_user_agent"'
'}';
access_log /var/log/nginx/access.log json;
sendfile on;
#tcp_nopush on;
keepalive_timeout 65;
#gzip on;
upstream elasticsearch
{
zone elasticsearch 64K;
server 192.168.83.11:9200;
server 192.168.83.12:9200;
server 192.168.83.13:9200;
}
server
{
listen 8080;
server_name localhost;
location /
{
proxy_pass http://elasticsearch;
root html;
index index.html index.htm;
}
}
include /etc/nginx/conf.d/*.conf;
}
3.2安装filebeat
[root@elk2 ~]# wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.0-x86_64.rpm
[root@elk2 ~]# rpm -ivh filebeat-6.0.0-x86_64.rpm
3.3 修改配置文件filebeat.yml
[root@elk2 ~]# vim /etc/filebeat/filebeat.yml
enabled: true
paths:
- /var/log/nginx/*.log
#-------------------------- Elasticsearch output ------------------------------
output.kafka:
# Array of hosts to connect to.
hosts: ["192.168.83.11:9092","192.168.83.12:9092","192.168.83.13:9092"] #145
topic: "nginx-es"
3.4 启动filebeat
[root@elk2 ~]# systemctl restart filebeat
4、所有组件部署完成之后,开始配置部署
4.1 在kafka上创建一个话题nginx-es
kafka-topics.sh --create --zookeeper 192.168.83.11:2181,192.168.83.12:2181,192.168.83.13:2181 --replication-factor 1 --partitions 1 --topic nginx-es
4.2 修改logstash的配置文件
[root@elk2 ~]# vim /etc/logstash/conf.d/nginxlog.conf
input{
kafka{
topics=>"nginx-es"
codec=>"json"
decorate_events=>true
bootstrap_servers=>"192.168.83.11:9092,192.168.83.12:9092,192.168.83.13:9092"
}
}
output {
elasticsearch {
hosts=>["192.168.83.11:9200","192.168.83.12:9200","192.168.83.13:9200"]
index=>'nginx-log-%{+YYYY-MM-dd}'
}
}
重启logstash
systemctl restart logstash
4.3 验证网页