最近,笔者在阅读这篇文章时很好奇,为什么使用看起来高大上的shuffle算法之后,并没有造成优化反而有了负优化,想到了一个可以优化的地方:在最后针对一个warp进行处理时,当前block中不在第一个warp中的线程会进行很多额外的处理:首先是对线程内部寄存器的读写,然后是一些处理,于是有了如下的更改:
可以看到,通过使用double y = 0,减少了对无关线程的寄存器读写量和计算量,但是此优化也并没有达到warp内同步算法的结果,详细内容看下图:

还差0.05ms(不同评测机上结果可能不同)
猜测是shuffle内部的某些机制造成了延迟,不过这个只有在看到源码时才能具体分析。
详细代码已上传Gitee。
【CUDA】shuffle算法的一个优化
news2026/2/14 17:38:11
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1907986.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

【Linux】进程间通信——匿名管道
为什么要进行进程间通信? 1.数据传输:一个进程需要将它的数据发送给另一个进程,比如我们有两个进程,一个负责获取数据,另一个负责处理数据,这时第一个进程就要将获取到的数据交给第二个进程 2.资源共享&…


4.Python4:requests
1.requests爬虫原理
(1)requests是一个python的第三方库,主要用于发送http请求
2.正则表达式 #正则表达式
import re,requests
str1aceace
#A(.*?)B,匹配A和B之间的值
print(re.findall(a(.*?)e,str1))import re,requests
str2hello com…


微信视频号及直播回放下载工具
最近需要下载微信视频号中的视频,找一圈,终于找到了,,免费,没广告 软件叫做:爱享素材下载器。 是一款开源的、完全免费的工具。
第1步:下载安装包
下载地址: https://github.com/p…

jmeter+ant+jenkins搭建 接口自动化测试平台
平台搭建
(1)录制jmeter脚本
(2)将jmeter的安装目录下的G:\jmeter\apache-jmeter-5.1.1\extras中,将 ”ant-jmeter-1.1.1.jar”文件放到 ant的lib目录下
(3)配置jmeter的xml配置文件…


【第22章】MyBatis-PlusSQL分析与打印
文章目录 前言一、p6spy简介二、示例工程1. 依赖引入2. 配置 三、Spring Boot集成1. 依赖2. 配置3. 注意事项 四、实战1. 依赖2. 配置(spy.properties)3. 配置类4. 测试类5. 结果 总结 前言
MyBatis-Plus提供了SQL分析与打印的功能,通过集成p6spy组件,可…

电脑找回彻底删除文件?四个实测效果的方法【一键找回】
电脑数据删除了还能恢复吗?可以的,只要我们及时撤销上一步删除操作,还是有几率找回彻底删除文件。 当我们的电脑文件被彻底删除后,尽管恢复的成功率可能受到多种因素的影响,但仍有几种方法可以尝试找回这些文件。本文整…

白帽工具箱:DVWA中CSRF攻击与防御的入门指南
🌟🌌 欢迎来到知识与创意的殿堂 — 远见阁小民的世界!🚀 🌟🧭 在这里,我们一起探索技术的奥秘,一起在知识的海洋中遨游。 🌟🧭 在这里,每个错误都…
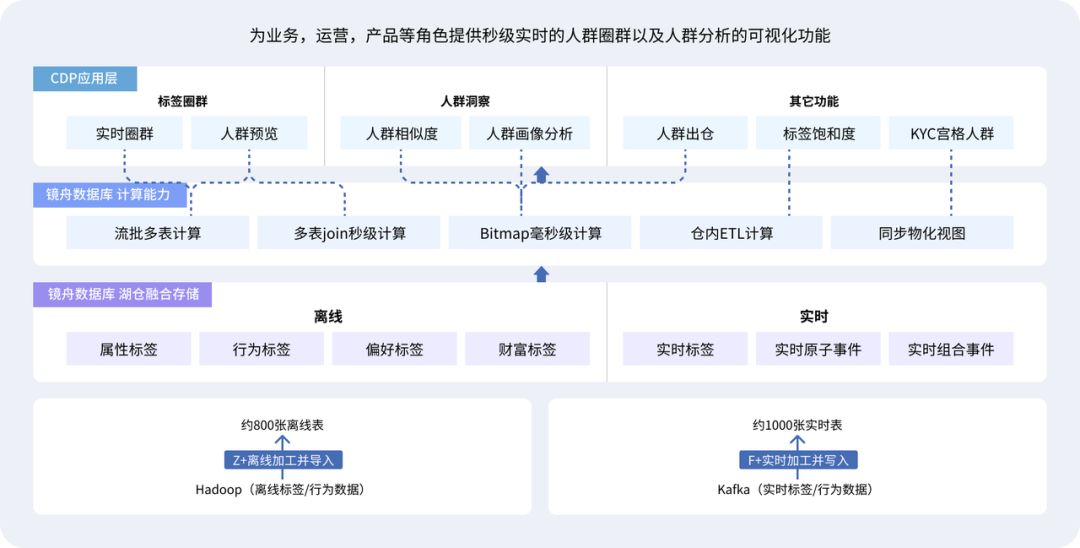
镜舟科技:国产数据库角逐金融赛道,开年斩获数家银行订单
在国产数据库领域,镜舟科技正迅速崛起,成为一匹瞩目的基础数据技术黑马。
开年伊始,镜舟科技便成功斩获中信银行、南京银行、某股份制银行、某头部民营银行、某大型综合类券商以及某消费金融公司等多家金融企业订单,其锚定需求匹…

最优化方法 运筹学【】
1.无约束
常用公式 线搜索准则:求步长
精确线搜索(argmin) 最速下降:sd:线性收敛
2.算法
SD
dk:付梯度-g
newton dk:Gkd-g
二阶收敛,步长为1 阻尼牛顿:步长用先搜…

HBuilder X 小白日记03-用css制作简单的交互动画
:hover选择器,用于选择鼠标指针浮动在上面的元素。
:hover选择器可用于所有元素,不只是链接 :link选择器 设置指向未被访问页面的链接的样式
:visited选择器 用于设置指向已被访问的页面的链接
:active选择器 用于活动链接

【Java14】构造器
Java中的构造器在创建对象(实例)的时候执行初始化。Java类必须包含一个或一个以上的构造器。 Java中的构造器类似C中的构造函数。 Java中对象(object)的默认初始化规则是:
数值型变量初始化为0;布尔型变量…
记录一次Nginx的使用过程
一、Docker安装配置nginx
1.拉取镜像
docker pull nginx2.创建挂载目录 启动前需要先创建Nginx外部挂载目录文件夹 主要有三个目录 conf:配置文件目录log:日志文件目录html:项目文件目录(这里可以存放web文件) 创建挂…

智能视频监控中心 - 详细介绍
目录
一、概述
(一)定义
(二)作用
1、系统安全性
2、整体管理效率
3、数据支持决策
4、促进企业集团化和智慧城市发展
二、原理和组成
(一)原理
(二)组网图
(…

MATLAB常用的插值方法
在数学建模中,我们拿到的数据经常会有缺失值,在缺失值不是很多的情况下,我们在数据预处理阶段会采用插值方法来将数据补齐,之后再开始我们的建模。
目录
1.Matlab 实现分段线性插值
2.拉格朗日插值多项式
3.牛顿(…

OSCNET+ 代码复现
项目github 已有,开个博客大家如果复现有问题可以随时在下面留言
github :GitHub - hongwang01/OSCNet: 【MICCAI 2022, TMI 2023】Orientation-Shared Convolution Representation Model
1、从github 下载项目并解压 2、下载数据集 当然自己用肯定是自…

C语言实现顺序表字符型数据排序
实现直接插入、冒泡、直接选择排序算法。
#include <stdio.h>
#include <stdlib.h>typedef char InfoType;#define n 10 //假设的文件长度,即待排序的记录数目
typedef char KeyType; //假设的关键字类型
typedef struct { //记录类型KeyType…

超详细版阿里云控制台环境配置+数据库配置
一、登录阿里云控制台
登录阿里云控制台,找到实例,切到阿里云服务器所在地址 🍭不知道自己的服务器地址在哪边也没有关系,随便选择一个,查询不到记录的话会有以下提示,可以根据提示进行切换(适…