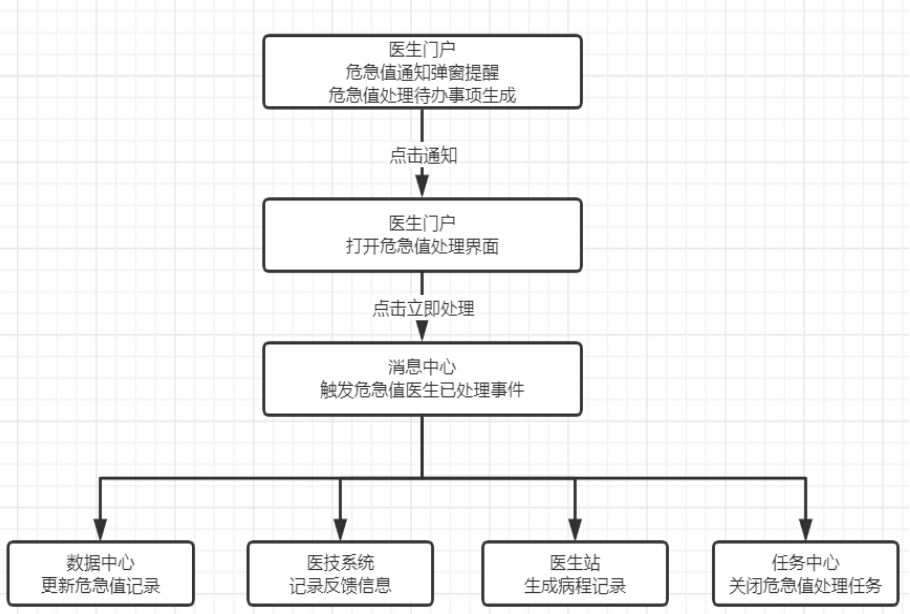
AI 大模型是什么?
维基百科对基础模型的定义是这样的,基础模型是一种大型机器学习模型,通常在大量数据上进行大规模训练(通过自监督学习或半监督学习),以使它可以适应各类下游任务。因此,它需要兼顾参数量大(大型模型),训练数据量大(大量数据大规模训练)和迁移学习能力强(适应多种下游任务)几点才能够叫做基础模型,而不只是参数量大,就能够叫做基础模型,我们在甄别时需要特别注意。
另一个重要的定义就是 AIGC,目前工业界普遍将 AIGC(Artificial Intelligence Generated Content)称为生成式人工智能。
所谓“涌现”,指的是在大模型领域,当模型突破某个规模时,性能显著提升,表现出让人惊艳、意想不到的能力。
所谓思维链(Chain-of-thought,CoT)指的是通过一系列有逻辑关系的思考步骤,形成一个完整的思考,进而得出答案的过程。
大模型的“大”是一个相对概念,是一个持续的过程。更大规模的训练数据需要模型具备更强的记忆、理解和表达能力。而为了拥有更强的记忆、理解和表达能力,模型则需要更大的参数量,也就是更大的模型。
生成式 AI 大模型的兴起
不仅仅是由于模型规模变大,而是多个因素相互作用形成的。
首先,在近年的技术发展中,大型语言模型,特别是以 GPT 3.0 为代表的大模型,展现出了出色的涌现、思维链和上下文学习的能力,不再停留在“人工智障”的阶段,极大地提升了自然语言理解和生成的能力,然而,这只是其中的一个必要条件。
第二个必要条件是跨模态建模能力的发展。这让同一个模型能像人类一样同时理解和处理 Excel、PPT、PDF、图像和视频等多种形式的数据。加持了这样的能力,算法生成的信息量从此发生质变,生成式人工智能发挥作用的舞台就更多了。
第三个必要条件是生成式模型的交互方式。生成式 AI 产品巧妙地利用了人类的惰性,通过新的交互方式,大大提高了产品的渗透率。这使得人们不断地使用 ChatGPT,并逐渐产生了依赖。这也成为了当前 AI 大模型产业,迅速发展的关键点。
然而,所有这些前提条件的实现,都依赖于存储和计算能力的持续发展,“孩子”身体的发育,使模型能够容纳和记忆更大规模的数据。不过,以上只是生成式 AI 大模型兴起的一些必要条件,但其全面走红还涉及到资本和产业发展的需求等多个因素的综合效果。

任务规划(Planning)
这种方法可以让 LLM 对自己的想法进行调整和反思,最经典的方法是 ReAct,他有三个概念:
Thought:表示让大语言模型思考,目前需要做哪些行为,行为的对象是谁,它要采取的行为是不是合理的。
Act:也就是针对目标对象,执行具体的动作,比如调用 API 这样的动作,然后收集环境反馈的信息。
Obs:它代表把外界观察的反馈信息,同步给大语言模型,协助它做出进一步的分析或者决策。
我们可以用这种方法来启发 LLM 工作,比如让它帮你制定工作方案,并持续向它提问,例如:你的执行步骤有哪些潜在隐患和风险、有哪些方法可以降低风险、能否帮助我制定一些安全风险预案等等问题,以确保它生成的内容安全可靠。在这个过程中,你要尽量唤醒 LLM 的相关知识,生成合理的计划,此时思维链技术(CoT)就非常重要了,它可以让 LLM 将任务分解为可解释的步骤。
记忆唤醒(Memory)
无论是在制定计划、使用工具或执行任务的过程中,LLM 都需要外部信息的帮助来辅助进行思考。为了更好地让 LLM 拥有记忆力,我们不妨先参考一下人类是如何记忆的。在神经科学研究中,人类的记忆可分为感觉记忆、短期记忆和长期记忆三种类型。
感觉记忆,是人体接收到外部信号以后,瞬间保留的视觉、听觉、触觉的记忆片段,在 AI 系统中类似于高维嵌入表示,也就是我们常说的 “Embedding”。
短期记忆,是你当前意识中的信息,在 LLM 中类似于提示词(Prompt)中的所有信息。
长期记忆,包含了你能回忆的所有信息,在 LLM 中类似于外部向量存储。
驾驭工具(Tools)
要让 LLM 学会使用工具,首先需要让它认识工具,比如 TALM、Toolformer 和 Gorilla 等方法让 LLM 学会理解 API 的调用注释,这是 Plugin 和 Function 等功能的基础。下图展示了 Gorilla 教会 LLM 使用 API 的全过程。
首先,我们使用大量 API 调用代码和文档作为语料,训练一个可以理解 API 的大语言模型。
然后,AI 系统还将对这些 API 进行向量化操作,将它们存储在向量数据库中作为外部记忆。
随后,当用户发起请求时候,AI 系统会从外部记忆中,获取跟请求相关的 API 交给 LLM。
最后,LLM 组合串联这些 API 形成代码,并执行代码,完成 API 的调用,生成执行结果。

链式调用黏合剂(Langchain)
首先,我们来为你的原型系统搭建一个“调度中心”。这个调度中心将帮助大语言模型(LLM)连接到我们之前学到的各种生态组件,如计划组件、记忆组件和工具组件等等。目前最主流的做法是采用链式调用。链式调用可以让你的编码更高效,只需少量代码,就能让用户、LLM 和组件之间进行复杂的互动。
为了让大语言模型能够实现与人类友好的多轮对话,我们需要额外引入两个组件。第一个是 ConversationBufferMemory,它将帮助 LLM 记录我们的对话过程。第二个是 ConversationChain,它会帮我们管理整个会话过程,通过调取 BufferMemory 中的对话信息,让无状态的 LLM 了解我们的对话上下文。同时,ConversationChain 还会通过补充一些“提示语”,确保 LLM 知道它在与人类进行交流。
from langchain.llms import OpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
import os
os.environ["OPENAI_API_KEY"] = '...'
llm = OpenAI(temperature=0)
mem = ConversationBufferMemory()
# Here it is by default set to "AI"
conversation = ConversationChain(llm=llm, verbose=True, memory=mem)
conversation.predict(input="Hi there!")
零代码快速搭建(Flowise)
在学习更高级的用法之前,先给你一个学习加速包,让你“无痛”地进行下面的过程。这个加速包叫做 Flowise,用于零代码搭建 LLM 应用平台。通过使用它,你可以在一分钟内搭建起刚才的应用。
领域知识库(Embedding & 向量检索引擎)
这类模型有两个标准动作。第一是让 LLM 做好考前“冲刺训练”也就是领域微调,它的训练成本较高,我们会在第四章中讲解这个方法。第二是为模型增加外部记忆,在提示词中引入一些领域知识,帮助模型提升回答质量。先使用第二种方法:具体制作步骤是这样的。
对团队的技术文档进行切片,生成语义向量(Embedding),存入向量数据库作为外部记忆。
根据同事所提问题中的内容,检索向量数据库,获取技术文档的内容片段。
把文档片段和同事的问题一并交给大语言模型(LLM),让它理解文档内容,并针对问题形成恰当回答,返回给同事。
接下来,我们继续使用 Flowise 实现这个项目,你只需要依次加入以下组件。
1、Folder with Files 组件,负责将相关知识文档上传。
2、Recursive Character Text Splitter 组件,用来给上传的文档内容做断句切片。
3、OpenAI Embeddings 组件负责将断句后的内容切片映射成高维 Embedding。
4、In-Memory Vector Store 组件用来将 Embedding 存入数据库中,供给 LLM 作为外部记忆。
5、Conversational Retrieval QA Chain 组件则会根据问题,获得外部知识,在 LLM 思考形成回答后返回给用户问题答案。
自主可控 LLM 底座(LocalAI)
OpenAI API 的开源替代方案——LocalAI,它可以将唾手可得的开源 LLM,封装成 OpenAI API 相同的接口形式,为你的应用提供服务。下面我们开始搭建这个底座,首先执行以下指令,部署 LocalAI 的代码:
$ git clone https://github.com/go-skynet/LocalAI
$ cd LocalAI
更高、更快、更强(Llama)
其实你可以使用“更大”的模型来提升效果,比如 Meta 开源的 Llama 系列模型。Llama 是 Meta AI 公司于 2023 年 2 月发布的大型语言模型系列,Llama-2 已经非常接近 GPT-3.5 的水平,而且可以免费商用。
首先,如下面的代码所示,我们去 HuggingFace 下载 Llama-2 最新的 ggml 版本。这里我们使用 7B 通用版本来进行演示。
$ wget -c "https://huggingface.co/TheBloke/Llama-2-7B-chat-GGML/resolve/main/llama-2-7b-chat.ggmlv3.q4_0.bin" ./models
下载了模型之后,我们根据以下指令,启动 LocalAI 来快速测试一下模型,确保模型文件没有问题。
$ docker-compose up -d
$ curl -v http://localhost:8080/v1/models
{"object":"list","data":[{"id":"llama-2-7b-chat.ggmlv3.q4_0.bin","object":"model"}]}
最后,我们回到 Flowise 的界面,将模型名称修改为 llama-2-7b-chat.ggmlv3.q4_0.bin。再次测试聊天机器人,它是不是变得更加聪明了?如果需要更大的模型,你可以按需下载。Local AI 已经在底层支持了 llama.cpp,所以 ggml 格式的模型基本都可以适配。你还可以尝试常用的量化方法,但要注意你的 GPU 是否支持。