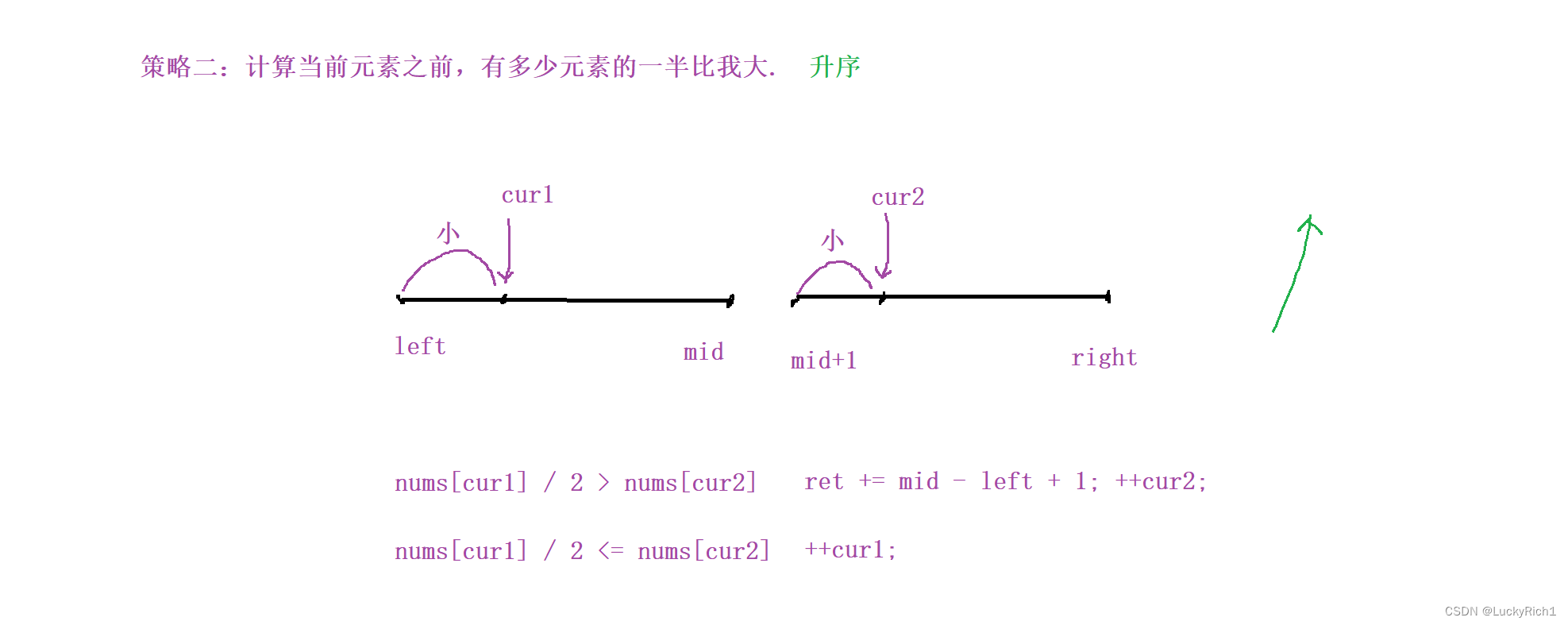
一、基本思想
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有 序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。 归并排序核心步骤:


二、归并排序的特性总结
1. 归并的缺点在于需要O(N)的空间复杂度,归并排序的思考更多的是解决在磁盘中的外排序问题。

2. 时间复杂度:O(N*logN)
3. 空间复杂度:O(N)
4. 稳定性:稳定
三、归并排序
1、递归实现
1.1 实现思想
使用递归方法来实现归并排序,这其中不止包含了递归这个思想,还使用了分治的理念。
其原理就是把待排序数组分成两个子序列,再分别把两个子序列分成其对应的子序列,直到每个子序列都只有唯一的一个数据时就停止递归。然后分别对子序列进行排序,最后将排序好的子序列合并起来。
一个小tip:就是归并排序归并数据的过程中我们需要额外开辟一个空间来存放中间数据,如果在原数组中进行归并的话会造成数据的覆盖或者导致数据错乱!!!
1.2 具体实现
// 时间复杂度O(N*logN) 空间复杂度:O(N)
void _MergeSort(int* a, int* tmp, int begin, int end)
{
if (end <= begin)
{
return;
}
int mid = (begin + end) / 2;
// [begin, mid][mid+1, end]
_MergeSort(a, tmp, begin, mid);
_MergeSort(a, tmp, mid + 1, end);
// 归并到tmp数据组,再拷贝回去
// a->[begin, mid][mid+1, end]->tmp
int begin1 = begin, end1 = mid;
int begin2 = mid + 1, end2 = end;
//尾插tmp数组下标
int index = begin;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//拷贝回原数组
memcpy(a + begin, tmp + begin, (end - begin + 1) * sizeof(int)); //+begin是因为归并的数组下标不一定从0开始
}
//归并排序
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int)*n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
_MergeSort(a, tmp, 0, n - 1);
free(tmp);
}2、 非递归实现
2.1 实现思想
相较于递归实现,非递归实现采用与希尔排序相似的方法。就是使用gap来确定归并区间并进行归并。

2.2 具体实现
//非递归--归并排序(防止下标越界)
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
perror("malloc fail");
return;
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i + gap, end2 = i + 2 * gap - 1;
// 如果第二组不存在,这一组不用归并了
if (begin2 >= n)
{
break;
}
// 如果第二组的右边界越界,修正一下
if (end2 >= n)
{
end2 = n - 1;
}
// [begin1,end1] [begin2,end2] 归并
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
// 拷贝回原数组
memcpy(a + i, tmp + i, (end2 - i) * sizeof(int));
}
gap *= 2;
}
free(tmp);
}2.3 关于非递归实现归并排序的一些细节
在我们要用非递归来实现归并排序时需要注意的是用gap来确定归并区间的界限会不会造成数组越界的问题。
上面这张图是我们用gap来区分归并的区间,这种方法有可能会造成第二个数组全部越界或者第二个数组的end越界。但我们要注意的是第一个数组的开头begin1永远不可能越界,因为begin1 == i,而循环条件中 i < n。

如下图所示:

所以我们就只需要加两个判定条件即可
1、判断begin2是否 >= 数组长度n,如果大于等于就直接跳出循环不用再进行归并
2、判断end2是否 >= 数组长度n,如果大于等于就修正end2,使其 == 数组结束位置 n - 1