💻博主现有专栏:
C51单片机(STC89C516),c语言,c++,离散数学,算法设计与分析,数据结构,Python,Java基础,MySQL,linux,基于HTML5的网页设计及应用,Rust(官方文档重点总结),jQuery,前端vue.js,Javaweb开发,设计模式、Python机器学习等
🥏主页链接:Y小夜-CSDN博客
目录
🎯本文目的
🎯成绩预测决策树模型
🎃内容
🎃代码解析
🎯不同参数的决策树算法和随机森林算法
🎃内容
🎃代码解析
🎯心脏病数据集寻找最佳max_features参数。
🎃内容
🎃代码解析
🎯总结
🎯本文目的
- (一)理解决策树的基本原理
- (二)能够使用sklearn.datasets制作分类数据集
- (三)能够使用sklearn库进行决策树模型的训练和预测
- (四)掌握随机森林的简单原理
- (五)能够使用sklearn库进行随机森林的训练和预测
🎯成绩预测决策树模型
🎃内容
如下表的所示训练集数据和验证集数据,其中“性别”、“机器学习作业”是属性特征,“成绩高”是标记。
表 1 训练集数据
编号
性别
机器学习作业
成绩高
1
男
喜欢
优秀
2
女
喜欢
优秀
3
男
不喜欢
普通
4
男
不喜欢
普通
5
女
不喜欢
优秀
表 2 测试集数据
编号
性别
机器学习作业
成绩高
6
男
喜欢
优秀
7
女
喜欢
普通
8
男
不喜欢
普通
9
女
不喜欢
普通
要求:
(数据集中, “性别”特征,用0表示女,1表示男, “喜欢”机器学习作业特征中,1表示喜欢,0表示不喜欢 , “成绩高”列,表示最后分类的标签,1表示成绩“优秀”,0表示成绩“普通”)
- 创建决策树模型,并使用训练集数据对模型进行训练。
- 查看并输出模型在测试集上的准确率?
- 使用tree.plot_tree()函数图形化显示训练好的决策树。
- 决策树模型的参数criterion默认值为“gini”,表示使用的是CART算法,可以尝试设置criterion = 'entropy',让模型使用ID3算法,观察一下训练的模型是否相同。
🎃代码解析
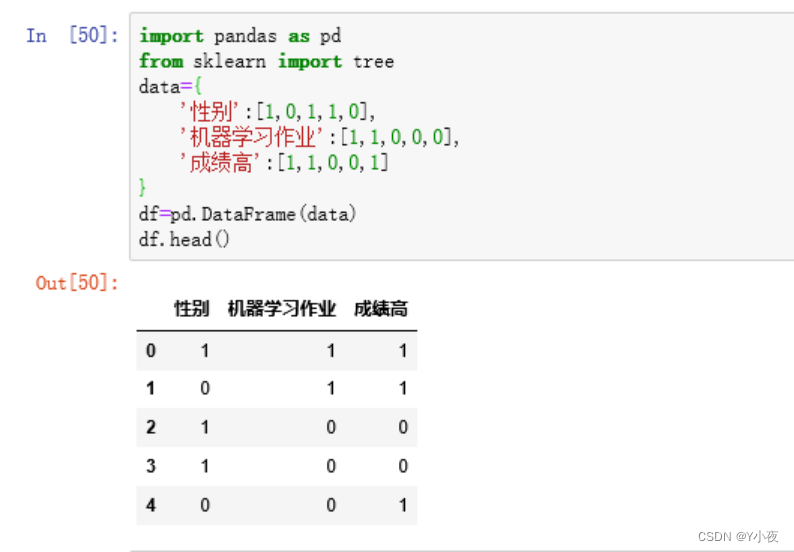
import pandas as pd from sklearn import tree data={ '性别':[1,0,1,1,0], '机器学习作业':[1,1,0,0,0], '成绩高':[1,1,0,0,1] } df=pd.DataFrame(data) df.head()
这段代码创建了一个包含性别、机器学习作业和成绩高三个特征的数据集,并将其存储在一个Pandas DataFrame中。这个DataFrame对象可以用于实现一些机器学习的功能,例如:
- 分析性别、机器学习作业和成绩高之间的关系。
- 使用决策树算法训练一个模型,以预测成绩高是否与性别和机器学习作业有关。
- 可以进行特征工程,如标准化或归一化,然后用于其他机器学习模型的训练和预测。
x=df.drop('成绩高',axis=1) y=df['成绩高'] clf=tree.DecisionTreeClassifier(max_depth=2) clf.fit(x,y)
数据分割:
x = df.drop('成绩高', axis=1): 从 DataFrame 中去掉'成绩高'这一列,将其余的列作为特征。这将得到包含"性别"和"机器学习作业"的特征数据。y = df['成绩高']: 提取'成绩高'这一列,作为目标变量。创建决策树模型:
clf = tree.DecisionTreeClassifier(max_depth=2): 创建一个决策树分类器,最大深度为2。这意味着决策树最多可以有两个分支。较小的最大深度可以避免过拟合,但也可能导致模型欠拟合。训练模型:
clf.fit(x, y): 使用特征数据x和目标数据y来训练决策树分类器。这个步骤完成后,模型将会根据给定的特征来预测目标变量。在这个例子中,模型被训练来预测“成绩高”是否与“性别”和“机器学习作业”相关。经过训练后,可以使用这个模型来预测新的数据样本中的"成绩高"状态。
data1={ '性别':[1,0,1,0], '机器学习作业':[1,1,0,0], '成绩高':[1,0,0,0] } df1=pd.DataFrame(data1) x1=df1.drop('成绩高',axis=1) y1=df1['成绩高'] clf.score(x1,y1)
- 创建了一个新的 DataFrame
df1,包含了与之前相同的特征:'性别'和'机器学习作业',以及新的目标变量 '成绩高'。- 提取了特征和目标变量,分别存储在
x1和y1中。- 使用
clf.score(x1, y1)方法计算了模型在新数据集上的准确率。
tree.plot_tree(clf)
clf是你的决策树模型,x是特征数据。这段代码将绘制出决策树的结构,并使用特征名和类别名进行标注。你可以运行这段代码来查看决策树的结构。
clf2=tree.DecisionTreeClassifier(max_depth=2,criterion = 'entropy') clf2.fit(x,y) tree.plot_tree(clf2)
创建了一个新的决策树分类器
clf2,并指定了最大深度为2以及使用信息熵(entropy)作为分裂标准。现在,你可以使用tree.plot_tree()函数来可视化这个新的决策树模型。





🎯不同参数的决策树算法和随机森林算法
🎃内容
(1)生成一个简单的数据集。
(2)尝试用不同参数的决策树算法进行试验。
(3)尝试用不同参数的随机森林进行试验,查看随机森林的预测准确率是否更高
🎃代码解析
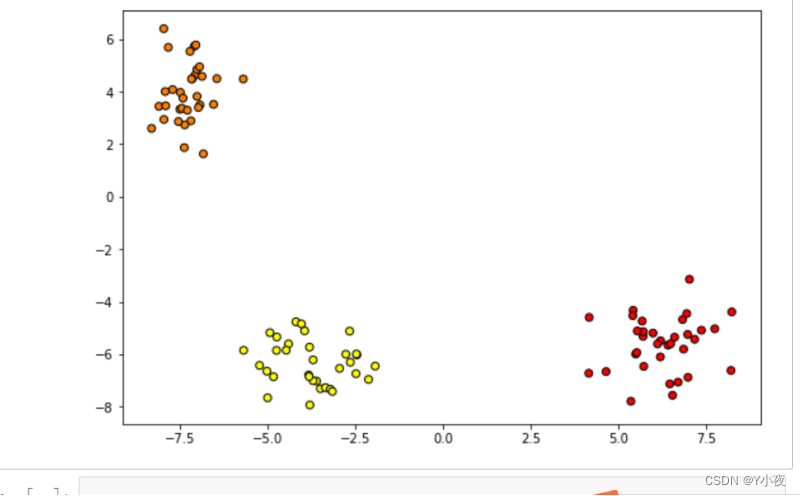
from sklearn.datasets import make_blobs x,y=make_blobs(n_samples=100,centers=3,n_features=2) x.shape import matplotlib.pyplot as plt plt.figure(figsize=(9,6)) plt.scatter(x[:,0],x[:,1],c=y,cmap='autumn',edgecolors='k')
使用了
make_blobs函数生成了一个包含100个样本,2个特征和3个聚类中心的数据集。接下来,你绘制了这个数据集的散点图,其中不同颜色的点表示不同的聚类。这样的可视化有助于直观地理解数据的分布和聚类情况。
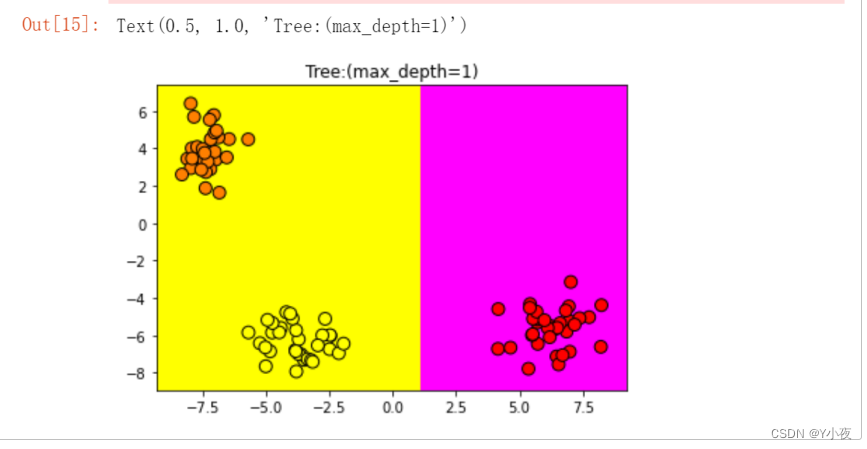
max_depth=1时:
from sklearn import tree import numpy as np clf1=tree.DecisionTreeClassifier(max_depth=1) clf1.fit(x,y) x_min,x_max=x[:,0].min()-1,x[:,0].max()+1 y_min,y_max=x[:,1].min()-1,x[:,1].max()+1 xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02)) z=clf1.predict(np.c_[xx.ravel(),yy.ravel()]) z=z.reshape(xx.shape) plt.pcolormesh(xx,yy,z,cmap='spring') plt.scatter(x[:,0],x[:,1],c=y,cmap='autumn',edgecolors='k',s=80) plt.xlim(xx.min(),xx.max()) plt.ylim(yy.min(),yy.max()) plt.title("Tree:(max_depth=1)")
使用决策树模型
clf1对数据进行了分类,并绘制了分类结果的决策边界。决策边界被绘制成了色块,不同的颜色表示不同的分类区域。另外,你还绘制了原始数据的散点图,不同颜色的点表示不同的类别。这个图表清晰地展示了决策树模型在最大深度为1时学到的决策边界。由于最大深度限制,决策树只能进行一次分裂,因此决策边界是一条直线。这种可视化方式有助于理解模型的学习情况和对数据的分类效果。
max_depth=2时
from sklearn import tree import numpy as np clf1=tree.DecisionTreeClassifier(max_depth=2) clf1.fit(x,y) x_min,x_max=x[:,0].min()-1,x[:,0].max()+1 y_min,y_max=x[:,1].min()-1,x[:,1].max()+1 xx,yy=np.meshgrid(np.arange(x_min,x_max,0.02),np.arange(y_min,y_max,0.02)) z=clf1.predict(np.c_[xx.ravel(),yy.ravel()]) z=z.reshape(xx.shape) plt.pcolormesh(xx,yy,z,cmap='spring') plt.scatter(x[:,0],x[:,1],c=y,cmap='autumn',edgecolors='k',s=80) plt.xlim(xx.min(),xx.max()) plt.ylim(yy.min(),yy.max()) plt.title("Tree:(max_depth=2)")
from sklearn.ensemble import RandomForestClassifier from sklearn import set_config set_config(print_changed_only=False) x,t=make_blobs(n_samples=100,centers=3,n_features=2,random_state=42) forest= RandomForestClassifier().fit(x,y) Forest
RandomForestClassifier()创建了一个随机森林分类器对象,并使用fit()方法将其拟合到数据集(x, y)上。然后,你将这个分类器赋值给了变量forest。


🎯心脏病数据集寻找最佳max_features参数。
🎃内容
(1)使用本章的心脏病数据集,找到最佳的max_features参数,以及该参数下模型在验证集上的准确率。
🎃代码解析
import pandas as pd heart=pd.read_csv('bank/heart.csv') heart.head()
导入了 pandas 库并使用
read_csv()函数读取了名为 "heart.csv" 的文件,并将其存储在名为heart的 DataFrame 中。然后,你使用head()方法查看了 DataFrame 的前几行数据。
from sklearn import tree clf_tree=tree.DecisionTreeClassifier() from sklearn.model_selection import train_test_split x=heart.drop('target',axis=1) y=heart['target'] x_train,x_test,y_train,y_test=train_test_split(x,y,random_state=0) clf_tree.fit(x_train,y_train) print(clf_tree.score(x_test,y_test))
使用了 scikit-learn 库中的决策树分类器来建立一个模型,并对心脏病数据集进行了训练和评估。
- 首先,你使用
tree.DecisionTreeClassifier()创建了一个决策树分类器对象,并将其赋值给clf_tree变量。- 然后,你从
sklearn.model_selection中导入了train_test_split函数,用于将数据集划分为训练集和测试集。- 接着,你准备了特征和标签数据。特征数据
x是除了目标列之外的所有列,而标签数据y是目标列。- 使用
train_test_split函数将数据集划分为训练集和测试集,并指定了random_state参数以确保结果的可重复性。- 最后,使用训练集训练了决策树分类器,并使用测试集评估了模型的性能,打印了分类器在测试集上的准确率。
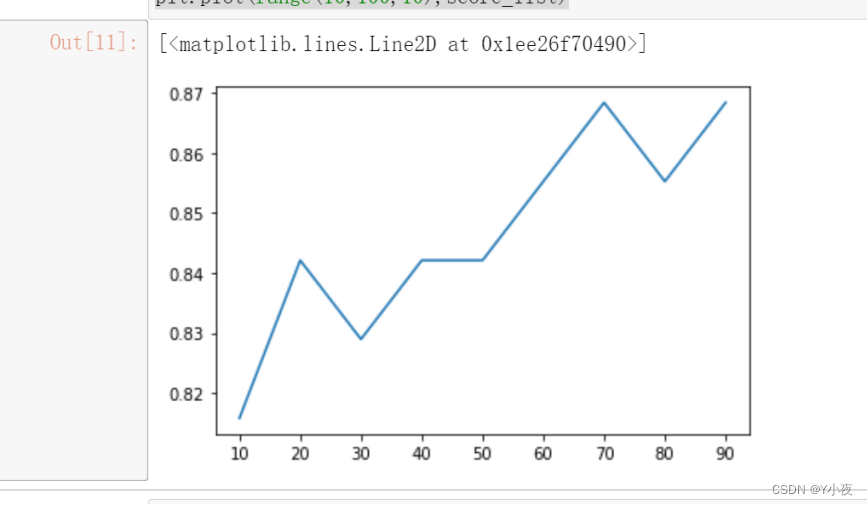
from sklearn.ensemble import RandomForestClassifier import matplotlib.pyplot as plt score_list=[] for i in range(10,100,10): clf_forest=RandomForestClassifier(n_estimators=i,random_state=0) clf_forest.fit(x_train,y_train) score_list.append(clf_forest.score(x_test,y_test)) plt.plot(range(10,100,10),score_list)
使用了随机森林分类器来建立模型,并对不同数量的决策树数量进行了评估,以确定最佳数量的决策树。具体来说,你进行了以下操作:
- 导入了
RandomForestClassifier类和matplotlib.pyplot模块。- 创建了一个空列表
score_list用于存储不同数量决策树的性能评分。- 使用
for循环迭代不同的决策树数量(从 10 到 90,步长为 10)。- 对于每个迭代,使用当前数量的决策树创建随机森林分类器对象,并将其拟合到训练数据集上。
- 计算并存储该模型在测试集上的准确率。
- 最后,使用
plt.plot()函数绘制决策树数量与模型准确率之间的关系。

🎯总结
决策树模型是一种基本且常用的机器学习算法,它通过树状结构来进行分类和回归任务。以下是关于决策树模型的知识点总结:
基本概念:
- 决策树是一种树状结构,其中每个内部节点表示一个特征或属性测试,每个分支代表一个测试结果,每个叶节点代表一个类别标签或回归值。
- 决策树的目标是通过将数据集划分为不同的区域来构建一个可以对新实例进行预测的模型。
构建过程:
- 决策树的构建过程通常采用递归地将数据集划分为子集的方式,直到满足某个停止条件。
- 划分过程通常基于某种度量指标(如信息增益、基尼不纯度等),选择最佳的划分特征。
特征选择:
- 特征选择是决策树算法中的关键步骤,常用的特征选择指标包括信息增益、基尼不纯度、方差等。
剪枝:
- 决策树容易过拟合训练数据,因此需要进行剪枝操作来防止过拟合。剪枝分为预剪枝和后剪枝两种方式。
优缺点:
- 优点包括易于理解和解释、对缺失值不敏感、能够处理不相关特征等。
- 缺点包括容易过拟合、对噪声敏感、不稳定性等。
应用领域:
- 决策树模型广泛应用于分类和回归任务,包括金融、医疗、工业等各个领域。
算法变体:
- 基于决策树模型衍生出了许多变体算法,如随机森林、梯度提升树等,用于进一步提升模型性能。








![C语言学习笔记[22]:分支语句switch](https://i-blog.csdnimg.cn/direct/b38eadadd2d34a45b1c1b375c8a9fd8e.png)