github字库地址:https://github.com/tesseract-ocr/tessdata

一、tesseract-ocr字库训练
1、配置 jdk 环境变量
步骤(略)
2、安装 tesseract-ocr 并配置环境变量
下载地址:https://digi.bib.uni-mannheim.de/tesseract/

配置环境变量:系统变量path添加 C:\Program Files (x86)\Tesseract-OCR; D:\Tesseract-OCR(对应自己的tesseract安装目录)
3、下载jTessBoxEditor2.0工具
下载地址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
下载完成后,解压缩并双击 jTessBoxEditor.jar 即可启动
 4、下载Tess4J-3.4.8
4、下载Tess4J-3.4.8
地址: https://sourceforge.net/projects/tess4j/files/tess4j/
解压即可得到 tessdata训练库
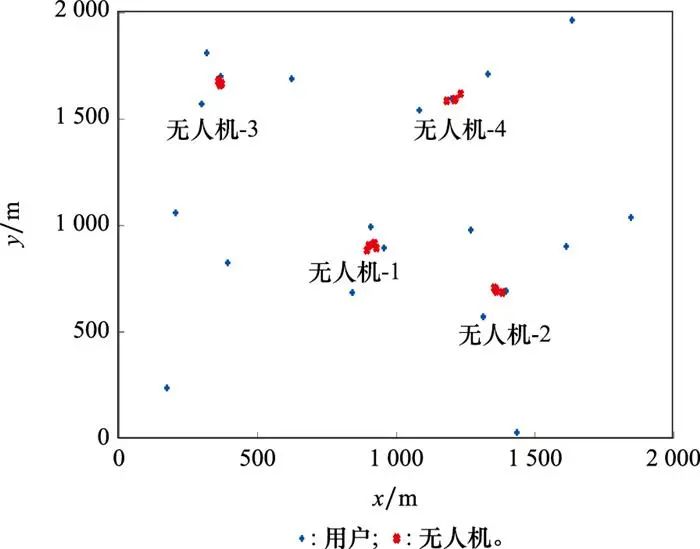
5、准备样本图片

6、使用jTessBoxEditor生成训练样本的的合并tif图片
(1)打开jTessBoxEditor,选择Tools->Merge TIFF,进入训练样本所在文件夹,选中要参与训练的样本图片:

(2)点击 “打开” 后弹出保存对话框,选择保存在当前路径下,文件命名为 “zwp.test.exp0.tif” ,格式只有一种 “TIFF” 可选。


tif命名规则:[lang].[fontname].exp[num].tif
- lang = 语言
- fontname = 字体
- num = 自定义数字
7、使用tesseract生成.box文件:
在生成的 mjorcen.normal.exp0.tif 文件所在目录下打开命令行
执行如下命令 : tesseract mjorcen.normal.exp0.tif mjorcen.normal.exp0 batch.nochop makebox

8、使用jTessBoxEditor矫正.box文件的错误:
打开 jTessBoxEditor ,点击Box Editor ->Open ,打开 mjorcen.normal.exp0.tif,会自动关联到“mjorcen.normal.exp0.box”文件,这两文件要求在同一目录下,调整完点击“save”保存修改。

*修改文字是乱码*
👉 解决方法: jtessboxeditor的setting ---> Font 里改字体为宋体,regular就可以了。

*修改文字必须是白底黑字,要不然训练时会出现错误*
9.创建 一个 font_properties文件(该文件无后缀名)
- 手工新建一个名为font_properties的文本文件

- 内容 :test 0 0 0 0 0
- 表示字体test的粗体、倾斜等共计5个属性。
- 这里内容中的“test”必须与生成的 .box 文件中的fontname = 字体 ,一致。
10、使用tesseract生成.tr训练文件:
执行下面命令,执行完之后,会在当前目录生成zwp.test.exp0.tr文件。
执行如下命令: tesseract mjorcen.normal.exp0.tif mjorcen.normal.exp0 nobatch box.train

8.生成字符集文件:
执行下面命令:执行完之后会在当前目录生成一个名为“unicharset”的文件。
执行命令: unicharset_extractor mjorcen.normal.exp0.box

9、生成shape文件:
执行下面命令,执行完之后,会生成 shapetable 和 zwp.unicharset 两个文件。
执行命令:
shapeclustering -F font_properties -U unicharset -O zwp.unicharset mjorcen.normal.exp0.tr

10、生成聚字符特征文件:
执行下面命令,会生成 inttemp、pffmtable、shapetable和zwp.unicharset四个文件。
执行命令: mftraining -F font_properties -U unicharset -O zwp.unicharset mjorcen.normal.exp0.tr

11、生成字符正常化特征文件:
执行下面命令,会生成 normproto 文件。
执行命令: cntraining mjorcen.normal.exp0.tr

12、文件重命名:
重新命名inttemp、pffmtable、shapetable和normproto这四个文件的名字为[lang].xxx。
这里修改为mjorcen.inttemp、mjorcen.pffmtable、mjorcen.shapetable和mjorcen.normproto
执行下面命令:
rename normproto mjorcen.normproto
rename inttemp mjorcen.inttemp
rename pffmtable mjorcen.pffmtable
rename shapetable mjorcen.shapetable
13、合并训练文件:
执行下面命令,会生成zwp.traineddata文件。
执行命令: combine_tessdata mjorcen.

Log输出中的Offset 1、3、4、5、13这些项不是-1,表示新的语言包生成成功。
将生成的“zwp.traineddata”语言包文件复制到Tesseract-OCR 安装目录下的tessdata文件夹中,就可以使用训练生成的语言包进行图像文字识别了。
二、Java代码测试
1.pom.xml文件添加maven 依赖
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.4.0</version>
<exclusions>
<exclusion>
<groupId>com.sun.jna</groupId>
<artifactId>jna</artifactId>
</exclusion>
</exclusions>
</dependency>2.测试代码
public void testOCR()throws Exception {
//图片路径
File imageFile =new File("D:\\xx.png");
//训练库的路径(tessdata)
instance.setDatapath("C:\\tessdata");
//语言库(mjorcen)
instance.setLanguage("mjorcen");
// 文字识别
String result =instance.doOCR(imageFile);
//
System.out.println(result);
}3.输出结果