飞桨目前为开发者提供了涵盖多种领域的模型套件,开发者可以使用这些套件基于自身数据集快速完成深度学习模型的训练。但在实际产业部署环境下,开发者在部署模型到不同硬件和不同场景时面临以下三个痛点问题。

-
碎片化。在部署过程中,由于深度学习框架、硬件与平台的多样化,开源社区以及各硬件厂商存在大量分散的工具链,很难通过一款产品,同时满足开发者在服务端、移动端和边缘端,以及服务化场景部署的需求。
-
成本高。这与部署工具链碎片化的现状相关。开发者在不同推理引擎、不同硬件上部署的流程、代码API形态和体验都不尽相同,这带来了很高的学习成本。
-
速度慢。部署中最大的问题是如何将模型在特定的硬件上实现高性能的优化。尽管当前模型套件提供各种轻量级的模型,或开源社区各类推理引擎不断优化模型的推理速度。但在实际部署中,开发者更关注的是模型端到端的优化,包括预处理加速、模型压缩、量化等等。而目前的推理产品都缺少这种端到端的体验。
因此飞桨全新发布新一代部署产品——FastDeploy部署工具,为产业实践中需要推理部署的开发者提供最优解。

-
目前FastDeploy底层包含了飞桨的推理引擎、开源社区硬件厂商的推理引擎,结合飞桨统一硬件适配技术可以满足开发者将模型部署到主流AI硬件的需求。
-
模型压缩与转换工具使得开发者通过统一的部署API实现多框架模型的推理,同时,飞桨自研的PaddleSlim为大家提供更易用、性能更强的模型自动化压缩功能。
-
而在统一的部署API之上,我们还提供了丰富的多场景部署工程,满足开发者对于服务端、移动端、网页端的端到端部署需求。
FastDeploy三大特点
作为全场景高性能部署工具,FastDeploy致力于打造三个特点,与上述提及的三个痛点相对应,分别是全场景、简单易用和极致高效。

全场景
全场景是指FastDeploy的多端多引擎加速部署、多框架模型支持和多硬件部署能力。
多端部署
FastDeploy支持模型在多种推理引擎上部署,底层的推理后端,包括服务端Paddle Inference、移动端和边缘端的Paddle Lite以及网页前端的Paddle.js,并且在上层提供统一的多端部署API。这里以PaddleDetection的PP-YOLOE模型部署为例,用户只需要一行代码,便可实现在不同推理引擎后端间的灵活切换。
- 使用Paddle Inference部署:
import fastdeploy as fd
import cv2
im = cv2.imread("test.jpg")
# 通过RuntimeOption配置后端
option = fd.RuntimeOption()
option.use_paddle_infer_backend()
# 加载飞桨PPYOLOE检测模型
model = fd.vision.detection.PPYOLOE(“model.pdmodel”,
“model.pdiparams”,
“infer_cfg.yml”,
runtime option=option)
result = model.predict(im)- 使用OpenVINO部署:
import fastdeploy as fd
import cv2
im = cv2.imread("test.jpg")
# 通过RuntimeOption配置后端
option = fd.RuntimeOption()
option.use_openvino_backend()
# 加载飞桨PPYOLOE检测模型
model = fd.vision.detection.PPYOLOE(“model.pdmodel”,
“model.pdiparams”,
“infer_cfg.yml”,
runtime option=option)
result = model.predict(im)多框架支持
在多框架模型部署的支持上,FastDeploy集成了X2Paddle和Paddle2ONNX两款模型转换工具。截至目前,飞桨的转换工具支持多种深度学习框架及ONNX的交换格式。在百度公司内部以及开源社区,我们支持了不同领域300多种模型的转换,目前也在根据用户的需求持续迭代。
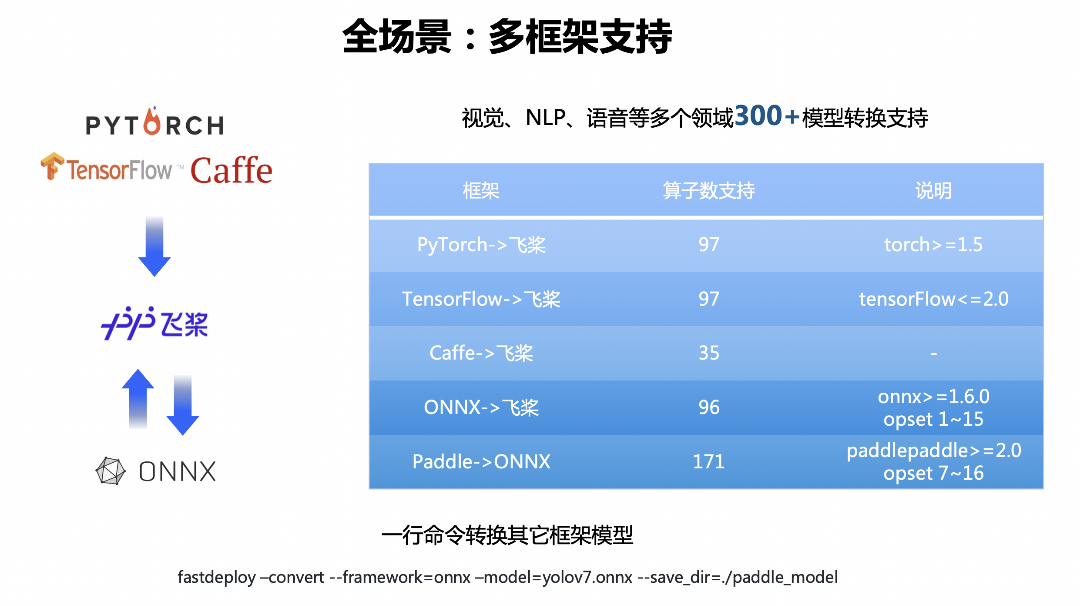
在FastDeploy1.0正式版本中,飞桨统一了模型转换的功能入口。开发者只需要一行命令就可以完成其他深度学习框架到飞桨的转换,以及飞桨模型与ONNX交换格式的互转,帮助开发者使用FastDeploy快速体验飞桨的模型压缩,以及推理引擎端到端的优化效果。
多硬件适配
 飞桨硬件适配统一方案
飞桨硬件适配统一方案
在多硬件适配上,FastDeploy基于飞桨硬件适配统一方案进行扩展,实现最大化AI模型部署通路。
在最新版本中,FastDeploy和英特尔、英伟达、瑞芯微和GraphCore等硬件厂商完成了硬件适配。期待更多硬件生态伙伴使用FastDeploy拓展更多领域,完成更多模型的端到端推理部署。

简单易用
FastDeploy提供主流产业场景和SOTA模型端到端的部署,以及多端部署的统一开发体验。
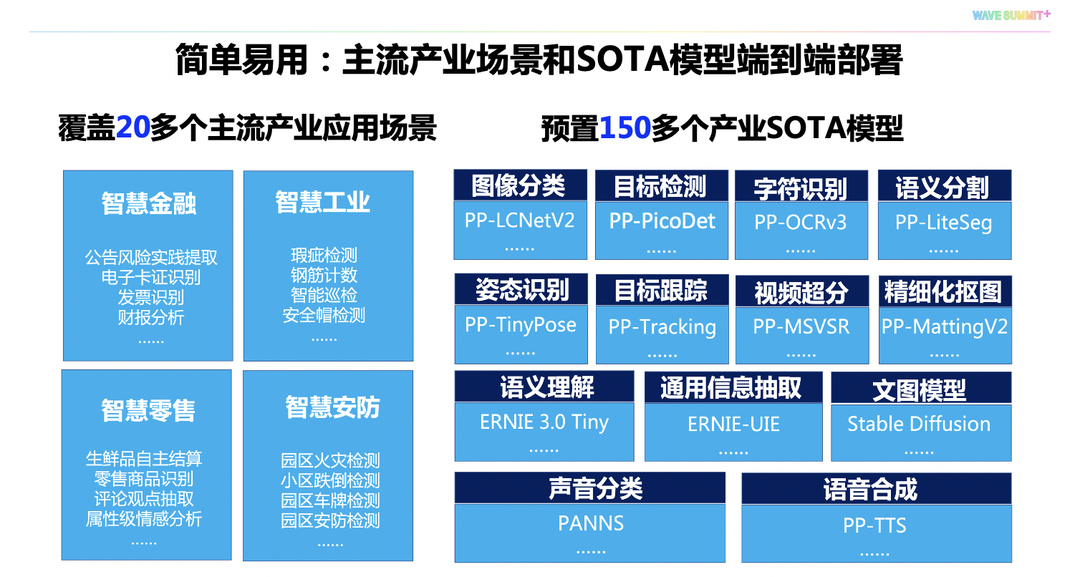
在FastDeploy的部署套件中,飞桨提供覆盖20多个主流AI场景,以及150多个SOTA产业模型的端到端部署示例,让开发者从场景入手,快速通过自行训练或预训练模型完成部署工作。
- Python部署:
import fastdeploy.vision as vision
model = vision.detection.PPYOLOE(“model.pdmodel”,
“model.pdiparams”,
“infer_cfg.yml”)
result = model.predict(im)
- C++部署:
#include “fastdeploy/vision.h”
namespace vision = fastdeploy::vision;
int main(int argc, char* argv[]) {
...
auto model = vision::detection::PPYOLOE(“model.pdmodel”,
”model.pdiparams”,
”infer_cfg.yml”)
vision::DetectionResult result;
model.Predict(image, &result);
...在开发体验上,FastDeploy从统一的角度设计了部署的API,确保在不同端和不同开发语言下,开发者能够拥有统一的开发体验,并且使用尽可能少的代码实现模型端到端的高性能推理。



此外,飞桨联动EasyEdge提供了10多个端到端的部署工程Demo,帮助开发者快速体验AI模型效果,满足开发者产业使用中快速集成需求。同时EasyEdge提供了更易用的开发平台,便于开发者体验。

极致高效
FastDeploy的极致高效,包括模型无损量化压缩、推理部署软硬协同加速和模型端到端全流程的部署性能优化。
无损量化压缩,软硬协同加速
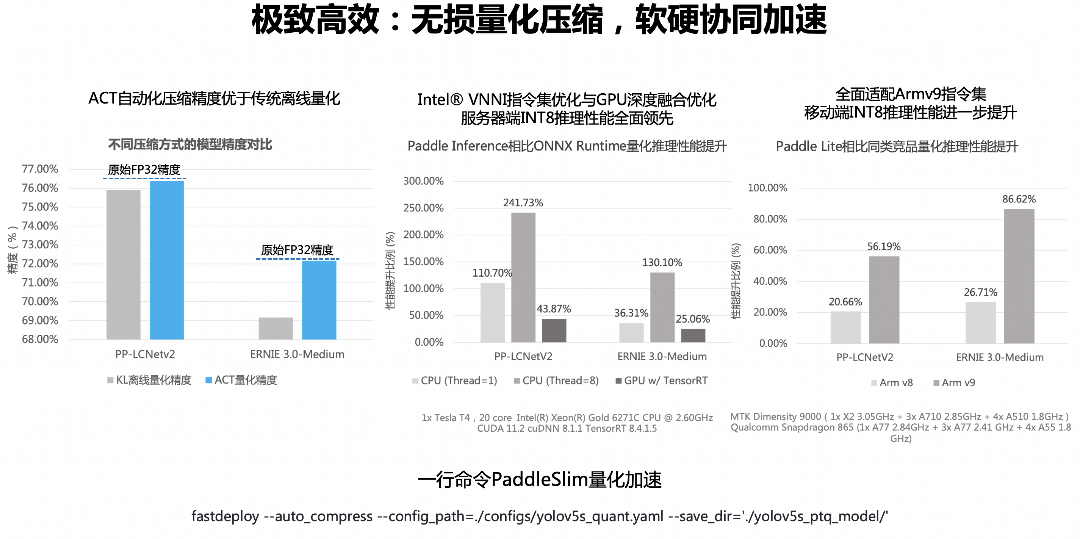
FastDeploy集成了飞桨压缩和推理的特色,实现了自动化压缩与推理引擎深度联动,为开发者提供更高效的量化推理部署体验。以PP-LCNetV2和ERNIE 3.0模型为例,传统的KL离线量化会明显降低模型压缩后的精度,但在FastDeploy的最新版本中,飞桨通过集成PaddleSlim最新的ACT自动压缩技术,实现模型几乎无损的压缩功能。
如果压缩后的模型想达到更高的推理性能,需要后端推理引擎的软硬件协同优化工作。基于最新版本的Paddle Inference,在CPU上通过英特尔VNNI指令集以及GPU上深度融合和优化,性能全面领先ONNX Runtime。在移动端上,Paddle Lite对ARM v9指令集进行了全面适配,INT8推理性能相对比同类的产品有更大幅度的性能提升。
端到端全流程优化
但也正如上文提到,模型推理只是端到端部署中的一个环节,所以FastDeploy在端到端的全流程部署上做了大量优化工作,并且对于此前飞桨的CV模型部署代码进行了全面优化升级。
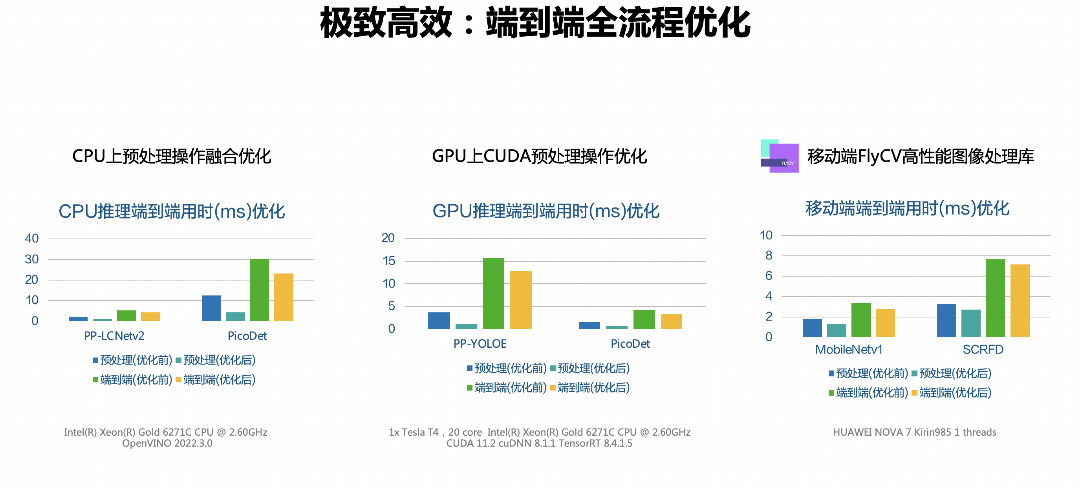
在CPU上,对预处理操作进行融合,减少数据预处理过程中内存创建、拷贝和计算量。在GPU上,飞桨引入了自定义的CUDA预处理算子优化,实现了服务端上模型端到端部署性能的大幅提升。在移动端,飞桨与百度视觉技术部合作,通过百度在业务实践中自研打磨的高性能图像预处理库FlyCV,显著提升图像数据预处理的性能。
总体而言,本次全新发布的FastDeploy部署套件可以满足开发者全场景的高性能部署需求,大幅提升在AI产业部署中的开发效率。FastDeploy的目标和使命是让开发者简单高效地将AI模型部署到任何场景。目前,开源项目仍在高效迭代中,每月都会有新版本和新部署功能升级发布。欢迎大家点击阅读原文或访问下方链接关注。
-
FastDeploy开源项目地址
https://github.com/PaddlePaddle/FastDeploy