- easy-rl PDF版本 笔记整理 P5、P10 - P12
- joyrl 比对 补充 P11 - P13
- OpenAI 文档整理 ⭐ https://spinningup.openai.com/en/latest/index.html


最新版PDF下载
地址:https://github.com/datawhalechina/easy-rl/releases
国内地址(推荐国内读者使用):
链接: https://pan.baidu.com/s/1isqQnpVRWbb3yh83Vs0kbw 提取码: us6a
easy-rl 在线版本链接 (用于 copy 代码)
参考链接 2:https://datawhalechina.github.io/joyrl-book/
其它:
【勘误记录 链接】
——————
5、深度强化学习基础 ⭐️
开源内容:https://linklearner.com/learn/summary/11
——————————

图片来源
近端策略优化(proximal policy optimization,PPO)
同策略:要学习的智能体 和 与环境交互的智能体 是相同的。
异策略:要学习的智能体 和 与环境交互的智能体 不相同
策略梯度: 需要很多时间采样数据
同策略 ⟹ 重要性采样 ~~~\overset{重要性采样}{\Longrightarrow}~~~ ⟹重要性采样 异策略
PPO: 避免两个分布相差太多。 同策略算法
1、本来的优化项
J
(
θ
,
θ
′
)
J(\theta,\theta^\prime)
J(θ,θ′)
2、约束项:
θ
\theta
θ 和
θ
′
\theta^\prime
θ′ 输出动作的 KL 散度 (
θ
\theta
θ 和
θ
′
\theta^\prime
θ′ 越相似越好)
PPO 有一个前身:信任区域策略优化(trust region policy optimization,TRPO)
TRPO 很难处理,因为它把 KL 散度约束当作一个额外的约束,没有放在目标函数里,所以很难计算。因此我们一般就用 PPO,而不使用 TRPO 。PPO 与 TRPO 的性能差不多,但 PPO 在实现上比 TRPO 容易得多。
KL 散度:动作的距离。执行某个动作的概率分布 的距离。
PPO 算法有两个主要的变种:近端策略优化惩罚(PPO-penalty)和近端策略优化裁剪(PPO-clip)。
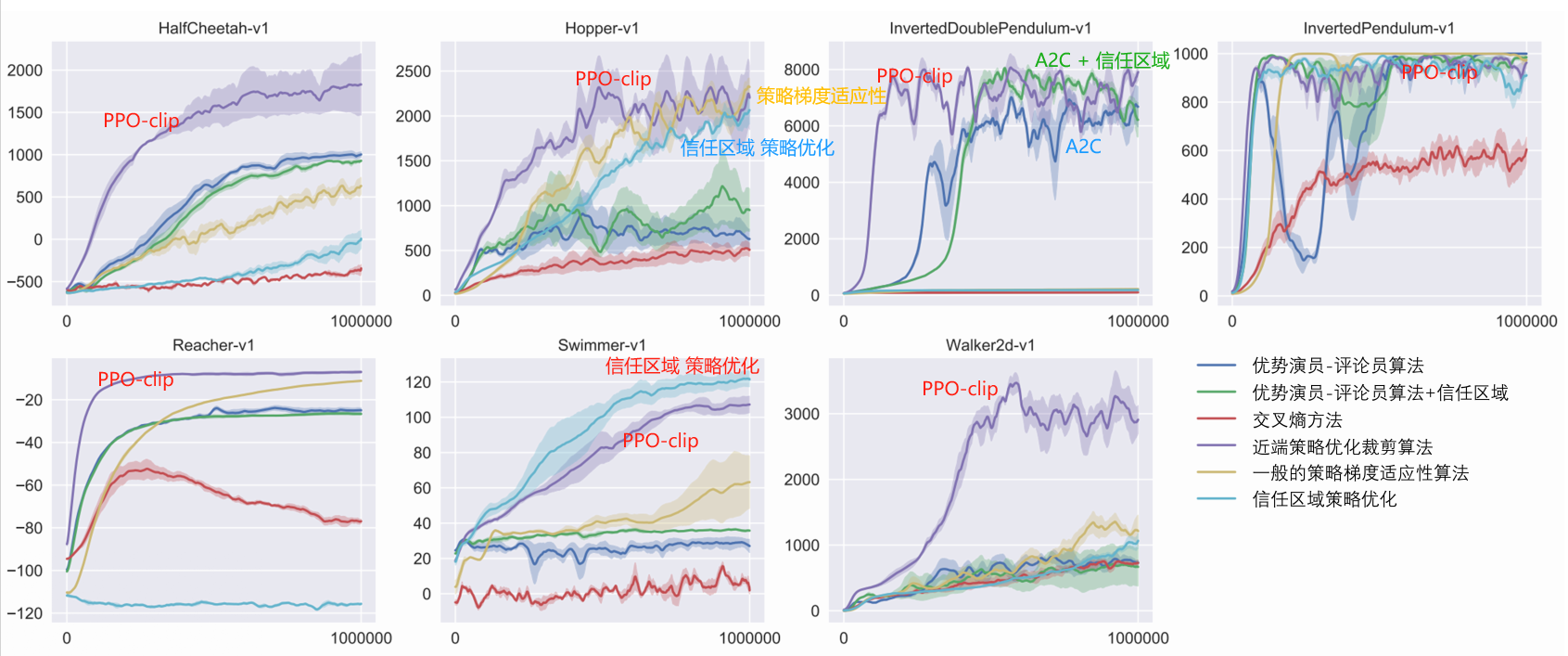
——————————
P10 稀疏奖励 问题
1、设计奖励。 需要领域知识
把 最终奖励 分配到 每个相关动作上, 如何呢?
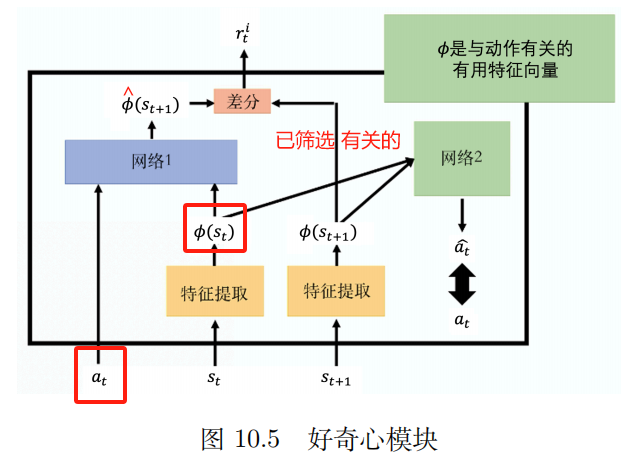
2、好奇心
内在好奇心模块(intrinsic curiosity module,ICM)
输入:
a
t
,
s
t
a_t,s_t
at,st
输出:
s
^
t
+
1
\hat s_{t+1}
s^t+1
网络的预测值
s
^
t
+
1
\hat s_{t+1}
s^t+1 与真实值
s
t
+
1
s_{t+1}
st+1 越不相似,
r
t
i
r_t^i
rti 越大
r t i r_t^i rti : 未来的状态越难以被预测,动作的奖励越大。鼓励 冒险 和 探索。
- 指标过于单一,可能 只学到无用的
特征提取器 (feature extractor)
网络 2:
输入: 向量
ϕ
(
s
t
)
{\bm \phi}(s_{t})
ϕ(st) 和
ϕ
(
s
t
+
1
)
{\bm \phi}(s_{t+1})
ϕ(st+1)
预测动作 a ^ \hat a a^ 与 真正动作 越接近越好。
3、课程学习
简单 ——> 困难
逆课程学习(reverse curriculum learning):
从最终最理想的状态 [我们称之为黄金状态(gold state)] 开始,依次去寻找距离黄金状态最近的状态作为想让智能体达到的阶段性的“理想”状态。当然,我们会在此过程中有意地去掉一些极端的状态,即太简单、太难的状态。
4、分层强化学习(hierarchical reinforcement learning,HRL)
将智能体的策略分为高层次策略和低层次策略,高层次策略根据当前状态决定如何执行低层次策略。
————————
P11 模仿学习
不清楚 奖励 的场景
模仿学习(imitation learning,IL)
示范学习(learning from demonstration)
学徒学习(apprenticeship learning)
观察学习(learning by watching)
有明确的奖励:棋类游戏、电玩
无法给出明确的奖励: 聊天机器人
收集专家示范:人类开车的记录、人的对话
反推,专家是因为什么样的奖励函数才会采取这些行为。
逆强化学习是先找出奖励函数,找出奖励函数以后,再用强化学习找出最优演员。
第三人称视角模仿学习(third person imitation learning)技术
————————
P12 深度确定性策略梯度(deep deterministic policy gradient,DDPG)
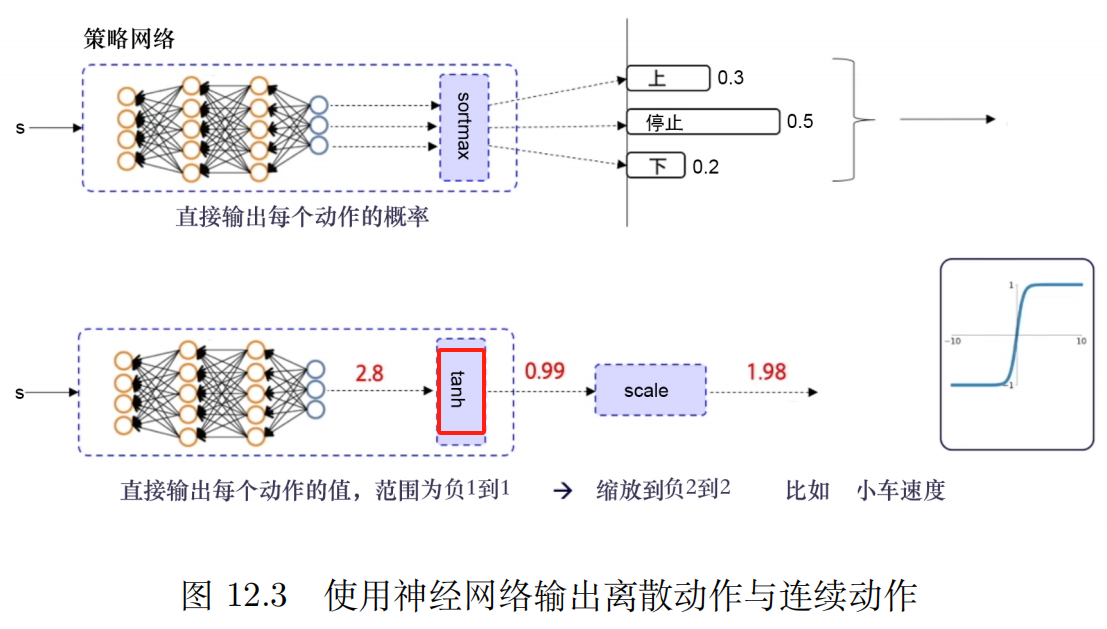
使用了经验回放 异策略
消融实验 【控制变量法】分析每一个约束条件对于对战结果的影响。
joyrl:
DDPG_连续
在需要确定性策略且连续动作空间的前提下,这类算法将是比较稳定的基线算法
连续动作空间 的 DQN
深度确定性策略梯度算法 (deep deterministic policy gradient, DDPG)
经验回放机制可以减少样本之间的相关性,提高样本的有效利用率,并且增加训练的稳定性。
缺点:
1、无法用于 离散动作空间
2、高度依赖超参数
3、高度敏感的初始条件。 影响算法的收敛性和性能
4、易陷入局部最优。
- 由于采用了确定性策略,可能会导致算法陷入局部最优,难以找到全局最优策略。为了增加探索性,需要采取一些措施,如加入噪声策略或使用其他的探索方法。
软更新的好处是更加平滑缓慢,可以避免因权重更新过于迅速而导致的震荡,同时降低训练发散的风险。
双延迟 确定性策略梯度算法 (twin delayed DDPG, TD3)
双延迟确定性策略梯度算法
三点改进:双 Q 网络、延迟更新、躁声正则
双 Q 网络:两个 Q 网络, 取 Q 值较小的。 应对 Q 值的过估计问题, 提高算法的稳定性 和 收敛性。
延迟更新:让 actor 的更新频率低于 critic 的更新频率
- 三思而后行
噪声更像是一种正则化的方式,使得值函数更新更加平滑
OpenAI Gym 库_摆杆直立 Pendulum_TD3
OpenAI 关于 TD3 的文档界面链接
TD3 论文PDF 链接
PPO_连续/离散动作空间 【OpenAI 201708】
强化学习中最为泛用的 PPO 算法
离散 + 连续
快速稳定, 调参简单
基线算法
遇事不决 PPO
在实践中一般用 clip 约束,因为它更简单,计算成本较低,而且效果也更好。
off-policy 算法由于可以利用历史经验,一般使用经验回放来存储和重复利用之前的经验,数据利用效率较高。
PPO 是 on-policy 算法
- 虽然 重要性采样部分 使用了 旧的 actor 采样的样本,但我们并没有直接使用这些样本去更新策略,而是使用重要性采样先将数据分布不同导致的误差进行了修正,即使两者样本分布之间的差异尽可能地缩小。换句话说,就可以理解为重要性采样之后的样本虽然是由旧策略采样得到的,但可以近似为从更新后的策略中得到的,即我们要优化的 actor 和采样的 actor 是同一个。
——————————————————
—— OpenAI 文档_PPO
OpenAI 文档
论文 arXiv 界面链接: Proximal Policy Optimization Algorithms
PPO: on-policy 算法、适用于 离散或 连续动作空间。可能局部最优
PPO 的动机与 TRPO 一样:如何利用现有的数据在策略上采取最大可能的改进 step,而不会改动过大而意外导致性能崩溃?
TRPO 试图用一种复杂的二阶方法来解决这个问题,PPO 则是一种一阶方法,它使用了一些其他技巧来保持新策略与旧策略的接近。
PPO方法的实现要简单得多,而且从经验上看,其执行效果至少与 TRPO 一样好。
PPO 有两种主要的变体:PPO-Penalty 和 PPO-Clip。
- PPO-Penalty 近似地解决了像 TRPO 这样的 KL 约束更新,但在目标函数中惩罚了 KL-divergence,而不是使其成为硬约束,并在训练过程中自动调整惩罚系数,使其适当缩放。
- PPO-Clip 在目标函数中没有 KL-divergence,也没有约束。而是依靠对目标函数的特定裁剪来去除 新策略远离旧策略 的激励。
PPO-Clip (OpenAl 使用的主要变体)。

PPO-Clip 算法伪码

算法: PPO-Clip
1:输入:初始策略参数 θ 0 \theta_0 θ0,初始值函数参数 ϕ 0 \phi_0 ϕ0
2: f o r k = 0 , 1 , 2 , … d o {\bf for} ~ k=0,1,2,\dots~ {\bf do} for k=0,1,2,… do:
3: ~~~~~~ 通过在环境中运行策略 π k = π ( θ k ) \pi_k=\pi(\theta_k) πk=π(θk) 收集轨迹集 D k = { τ i } {\cal D}_k=\{\tau_i\} Dk={τi}
4: ~~~~~~ 计算奖励 (rewards-to-go) R ^ t \hat R_t~~~~~ R^t ▢ R ^ t \hat R_t R^t 的计算规则
5: ~~~~~~ 计算优势估计,基于当前值函数 V ϕ k V_{\phi_k} Vϕk 的 A ^ t \hat A_t A^t (使用任何优势估计方法) ~~~~~ ▢ 当前有哪些优势估计方法?
6: ~~~~~~ 通过最大化 PPO-Clip 目标函数 更新策略:
~~~~~~~~~~~
θ k + 1 = arg max θ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T min ( π θ ( a t ∣ s t ) π θ k ( a t ∣ s t ) A π θ k ( s t , a t ) , g ( ϵ , A π θ k ( s t , a t ) ) ) ~~~~~~~~~~~\theta_{k+1}=\arg\max\limits_\theta\frac{1}{|{\cal D}_k|T}\sum\limits_{\tau\in{\cal D}_k}\sum\limits_{t=0}^T\min\Big(\frac{\pi_{\theta} (a_t|s_t)}{\pi_{\theta_k}(a_t|s_t)}A^{\pi_{\theta_k}}(s_t,a_t),g(\epsilon,A^{\pi_{\theta_k}}(s_t,a_t))\Big) θk+1=argθmax∣Dk∣T1τ∈Dk∑t=0∑Tmin(πθk(at∣st)πθ(at∣st)Aπθk(st,at),g(ϵ,Aπθk(st,at))) ~~~~~ ▢ 策略更新公式 如何确定?
~~~~~~~~~~~
~~~~~~~~~~~ π θ k \pi_{\theta_k} πθk:更新前的策略参数向量。 重要性采样。从旧的策略采样。
~~~~~~~~~~~
~~~~~~~~~~~ 一般 随机梯度上升 + Adam
7: ~~~~~~ 均方误差回归 拟合 值函数:
~~~~~~~~~~~
ϕ k + 1 = arg min ϕ 1 ∣ D k ∣ T ∑ τ ∈ D k ∑ t = 0 T ( V ϕ ( s t ) − R ^ t ) 2 ~~~~~~~~~~~\phi_{k+1}=\arg \min\limits_\phi\frac{1}{|{\cal D}_k|T}\sum\limits_{\tau\in{\cal D}_k}\sum\limits_{t=0}^T\Big(V_\phi(s_t)-\hat R_t\Big)^2 ϕk+1=argϕmin∣Dk∣T1τ∈Dk∑t=0∑T(Vϕ(st)−R^t)2
~~~~~~~~~~~
~~~~~~~~~~~ 一般 梯度下降
8: e n d f o r \bf end ~for end for
~~~~~~~~~~~~
$\dots$
…
~~~\dots
…
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A A < 0 g(\epsilon,A)=\left\{\begin{aligned}&(1+\epsilon)A ~~~~&A\geq0\\ &(1-\epsilon)A&A<0\end{aligned}\right. g(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

论文里的优势估计:
A ^ t = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) ⏟ R ^ t ? ? ? \hat A_t=-V(s_t)+\underbrace{r_t+\gamma r_{t+1}+\cdots+\gamma^{T-t+1}r_{T-1}+\gamma^{T-t}V(s_T)}_{\textcolor{blue}{\hat R_t???}} A^t=−V(st)+R^t??? rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)

令
Δ
t
=
r
t
+
γ
V
(
s
t
+
1
)
−
V
(
s
t
)
\Delta_t =r_t+\gamma V(s_{t+1})-V(s_t)
Δt=rt+γV(st+1)−V(st)
则
r
t
=
Δ
t
−
γ
V
(
s
t
+
1
)
+
V
(
s
t
)
r_t=\Delta_t - \gamma V(s_{t+1})+V(s_t)
rt=Δt−γV(st+1)+V(st)
代入 A ^ t \hat A_t A^t 表达式
A ^ t = − V ( s t ) + r t + γ r t + 1 + γ 2 r t + 2 + ⋯ + γ T − t r T − 2 + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( s t ) + r t + γ r t + 1 + ⋯ + γ T − t + 1 r T − 1 + γ T − t V ( s T ) = − V ( s t ) + Δ t − γ V ( s t + 1 ) + V ( s t ) + γ ( Δ t + 1 − γ V ( s t + 2 ) + V ( s t + 1 ) ) + γ 2 ( Δ t + 2 − γ V ( s t + 3 ) + V ( s t + 1 ) ) + ⋯ + γ T − t ( Δ T − t − γ V ( s T − t + 1 ) + V ( s T − t ) ) + γ T − t + 1 ( Δ T − 1 − γ V ( s T ) + V ( s T − 1 ) ) + γ T − t V ( s T ) = Δ t + γ Δ t + 1 + γ 2 Δ t + 2 + ⋯ + γ T − t Δ T − t + γ T − t + 1 Δ T − 1 \begin{aligned}\hat A_t&=-V(s_t)+r_t+\gamma r_{t+1}+\gamma^2 r_{t+2}+\cdots+\gamma^{T-t}r_{T-2}+\gamma^{T-t+1}r_{T-1}+\gamma^{T-t}V(s_T)\\ &=-V(s_t)+r_t+\gamma r_{t+1}+\cdots+\gamma^{T-t+1}r_{T-1}+\gamma^{T-t}V(s_T)\\ &=-V(s_t)+\\ & ~~~~~~~\Delta_t - \gamma V(s_{t+1})+V(s_t)+\\ & ~~~~~~~\gamma (\Delta_{t+1} - \gamma V(s_{t+2})+V(s_{t+1}))+\\ & ~~~~~~~\gamma^2(\Delta_{t+2} - \gamma V(s_{t+3})+V(s_{t+1}))+\\ & ~~~~~~~\cdots+\\ & ~~~~~~~\gamma^{T-t}(\Delta_{T-t} - \gamma V(s_{T-t+1})+V(s_{T-t}))+\\ & ~~~~~~~\gamma^{T-t+1}(\Delta_{T-1} - \gamma V(s_T)+V(s_{T-1}))+\\ & ~~~~~~~\gamma^{T-t}V(s_T)\\ &=\Delta_t+\gamma\Delta_{t+1}+\gamma^2\Delta_{t+2}+\cdots+\gamma^{T-t}\Delta_{T-t}+\gamma^{T-t+1}\Delta_{T-1}\end{aligned} A^t=−V(st)+rt+γrt+1+γ2rt+2+⋯+γT−trT−2+γT−t+1rT−1+γT−tV(sT)=−V(st)+rt+γrt+1+⋯+γT−t+1rT−1+γT−tV(sT)=−V(st)+ Δt−γV(st+1)+V(st)+ γ(Δt+1−γV(st+2)+V(st+1))+ γ2(Δt+2−γV(st+3)+V(st+1))+ ⋯+ γT−t(ΔT−t−γV(sT−t+1)+V(sT−t))+ γT−t+1(ΔT−1−γV(sT)+V(sT−1))+ γT−tV(sT)=Δt+γΔt+1+γ2Δt+2+⋯+γT−tΔT−t+γT−t+1ΔT−1

通过消除 策略大幅改变的诱因,clipping 起到了正则化的作用。超参数 ϵ \epsilon ϵ 对应于新策略与旧策略之间的距离。
这种 clipping 最终仍有可能得到一个与旧策略相去甚远的新策略,在这里的实现中,我们使用了一个特别简单的方法:提前停止。如果新策略与旧策略的平均 KL -散度超过一个阈值,我们就停止执行梯度步骤。
PPO 目标函数简单推导 链接
PPO-Clip 的目标函数为:
~
L θ k C L I P ( θ ) = E s , a ∼ θ k [ min ( π θ ( a ∣ s ) π θ k ( a ∣ s ) A θ k ( s , a ) , c l i p ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ , 1 + ϵ ) A θ k ( s , a ) ) ] L^{\rm CLIP}_{\theta_k}(\theta)=\underset{s, a\sim\theta_k}{\rm E}\Bigg[\min\Bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}A^{\theta_k}(s, a), {\rm clip}\Big(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)},1-\epsilon, 1+\epsilon\Big)A^{\theta_k}(s, a)\Bigg)\Bigg] LθkCLIP(θ)=s,a∼θkE[min(πθk(a∣s)πθ(a∣s)Aθk(s,a),clip(πθk(a∣s)πθ(a∣s),1−ϵ,1+ϵ)Aθk(s,a))]
~
$\underset{s, a\sim\theta_k}{\rm E}$E s , a ∼ θ k ~~~\underset{s, a\sim\theta_k}{\rm E} s,a∼θkE
~
第 k k k 次迭代 的策略参数 θ k \theta_k θk, ϵ \epsilon ϵ 为 小的超参数。
设 ϵ ∈ ( 0 , 1 ) \epsilon\in(0,1) ϵ∈(0,1), 定义
F ( r , A , ϵ ) ≐ min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) F(r,A,\epsilon)\doteq\min\Bigg(rA,{\rm clip}(r,1-\epsilon,1+\epsilon)A\Bigg) F(r,A,ϵ)≐min(rA,clip(r,1−ϵ,1+ϵ)A)
当 A ≥ 0 A\geq0 A≥0
F ( r , A , ϵ ) = min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) = A min ( r , c l i p ( r , 1 − ϵ , 1 + ϵ ) ) = A min ( r , { 1 + ϵ r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { min ( r , 1 + ϵ ) r ≥ 1 + ϵ min ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) min ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { 1 + ϵ r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) r r ≤ 1 − ϵ } 根据右侧的范围 = A min ( r , 1 + ϵ ) = min ( r A , ( 1 + ϵ ) A ) \begin{aligned}F(r,A,\epsilon)&=\min\Bigg(rA,{\rm clip}(r,1-\epsilon,1+\epsilon)A\Bigg)\\ &=A\min\Bigg(r,{\rm clip}(r,1-\epsilon,1+\epsilon)\Bigg)\\ &=A\min\Bigg(r,\left\{\begin{aligned}&1+\epsilon~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &1-\epsilon &r\leq1-\epsilon\\ \end{aligned}\right\}\Bigg)\\ &=A\left\{\begin{aligned}&\min(r,1+\epsilon)~~&r\geq1+\epsilon\\ &\min(r,r) &r\in(1-\epsilon,1+\epsilon)\\ &\min(r,1-\epsilon) &r\leq1-\epsilon\\ \end{aligned}\right\}\\ &=A\left\{\begin{aligned}&1+\epsilon~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &r &r\leq1-\epsilon\\ \end{aligned}\right\}~~~~~\textcolor{blue}{根据右侧的范围}\\ &=A\min(r, 1+\epsilon)\\ &=\min\Bigg(rA, (1+\epsilon)A\Bigg) \end{aligned} F(r,A,ϵ)=min(rA,clip(r,1−ϵ,1+ϵ)A)=Amin(r,clip(r,1−ϵ,1+ϵ))=Amin(r,⎩ ⎨ ⎧1+ϵ r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧min(r,1+ϵ) min(r,r)min(r,1−ϵ)r≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧1+ϵ rrr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫ 根据右侧的范围=Amin(r,1+ϵ)=min(rA,(1+ϵ)A)
~
当 A < 0 A<0 A<0
F ( r , A , ϵ ) = min ( r A , c l i p ( r , 1 − ϵ , 1 + ϵ ) A ) = A max ( r , c l i p ( r , 1 − ϵ , 1 + ϵ ) ) = A max ( r , { 1 + ϵ r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } ) = A { max ( r , 1 + ϵ ) r ≥ 1 + ϵ max ( r , r ) r ∈ ( 1 − ϵ , 1 + ϵ ) max ( r , 1 − ϵ ) r ≤ 1 − ϵ } = A { r r ≥ 1 + ϵ r r ∈ ( 1 − ϵ , 1 + ϵ ) 1 − ϵ r ≤ 1 − ϵ } 根据右侧的范围 = A max ( r , 1 − ϵ ) = min ( r A , ( 1 − ϵ ) A ) \begin{aligned}F(r,A,\epsilon)&=\min\Bigg(rA,{\rm clip}(r,1-\epsilon,1+\epsilon)A\Bigg)\\ &=A\textcolor{blue}{\max}\Bigg(r,{\rm clip}(r,1-\epsilon,1+\epsilon)\Bigg)\\ &=A\max\Bigg(r,\left\{\begin{aligned}&1+\epsilon~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &1-\epsilon &r\leq1-\epsilon\\ \end{aligned}\right\}\Bigg)\\ &=A\left\{\begin{aligned}&\max(r,1+\epsilon)~~&r\geq1+\epsilon\\ &\max(r,r) &r\in(1-\epsilon,1+\epsilon)\\ &\max(r,1-\epsilon) &r\leq1-\epsilon\\ \end{aligned}\right\}\\ &=A\left\{\begin{aligned}&r~~&r\geq1+\epsilon\\ &r &r\in(1-\epsilon,1+\epsilon)\\ &1-\epsilon &r\leq1-\epsilon\\ \end{aligned}\right\}~~~~~\textcolor{blue}{根据右侧的范围}\\ &=A\max(r, 1-\epsilon)\\ &=\textcolor{blue}{\min}\Bigg(rA,(1-\epsilon)A\Bigg) \end{aligned} F(r,A,ϵ)=min(rA,clip(r,1−ϵ,1+ϵ)A)=Amax(r,clip(r,1−ϵ,1+ϵ))=Amax(r,⎩ ⎨ ⎧1+ϵ r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫)=A⎩ ⎨ ⎧max(r,1+ϵ) max(r,r)max(r,1−ϵ)r≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫=A⎩ ⎨ ⎧r r1−ϵr≥1+ϵr∈(1−ϵ,1+ϵ)r≤1−ϵ⎭ ⎬ ⎫ 根据右侧的范围=Amax(r,1−ϵ)=min(rA,(1−ϵ)A)
~
综上:可定义 g ( ϵ , A ) g(\epsilon,A) g(ϵ,A)
g ( ϵ , A ) = { ( 1 + ϵ ) A A ≥ 0 ( 1 − ϵ ) A A < 0 g(\epsilon,A)=\left\{\begin{aligned}&(1+\epsilon)A ~~~~&A\geq0\\ &(1-\epsilon)A&A<0\end{aligned}\right. g(ϵ,A)={(1+ϵ)A (1−ϵ)AA≥0A<0

为什么这样定义就可以让 新策略 不至于 离 旧策略 过远?
重要性采样方法有效 要求 新策略
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s) 和 旧策略
π
θ
k
(
a
∣
s
)
\pi_{\theta_k}(a|s)
πθk(a∣s) 两个分布不能差距过大
1、当 advantage 优势为正
L
(
s
,
a
,
θ
k
,
θ
)
=
min
(
π
θ
(
a
∣
s
)
π
θ
k
(
a
∣
s
)
,
1
+
ϵ
)
A
π
θ
k
(
s
,
a
)
L(s,a,\theta_k, \theta)=\min\Bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}, 1+\epsilon\Bigg)A^{\pi_{\theta_k}}(s, a)
L(s,a,θk,θ)=min(πθk(a∣s)πθ(a∣s),1+ϵ)Aπθk(s,a)
优势函数: 发现某个 状态-动作对 奖励多 ——> 增大 该 状态-动作对 的权重。
当 状态-行动对
(
s
,
a
)
(s, a)
(s,a) 的优势是正的,则如果行动
a
a
a 更有可能执行,即如果
π
θ
(
a
∣
s
)
\pi_\theta(a|s)
πθ(a∣s) 增加,目标就会增加。
该项中的 min 限制了 目标函数只能增大到某个值
一旦
π
θ
(
a
∣
s
)
>
(
1
+
ϵ
)
π
θ
k
(
a
∣
s
)
\pi_\theta(a|s)>(1+\epsilon)\pi_{\theta_k}(a|s)
πθ(a∣s)>(1+ϵ)πθk(a∣s), min 触发,限制该项值为
(
1
+
ϵ
)
π
θ
k
(
a
∣
s
)
(1+\epsilon)\pi_{\theta_k}(a|s)
(1+ϵ)πθk(a∣s)。
the new policy does not benefit by going far away from the old policy.
新策略 不会因远离 旧策略而受益。
2、当 advantage 优势为负
L ( s , a , θ k , θ ) = max ( π θ ( a ∣ s ) π θ k ( a ∣ s ) , 1 − ϵ ) A π θ k ( s , a ) L(s,a,\theta_k, \theta)=\max\Bigg(\frac{\pi_\theta(a|s)}{\pi_{\theta_k}(a|s)}, 1-\epsilon\Bigg)A^{\pi_{\theta_k}}(s, a) L(s,a,θk,θ)=max(πθk(a∣s)πθ(a∣s),1−ϵ)Aπθk(s,a)
当 某个状态-行动对
(
s
,
a
)
(s, a)
(s,a) 的优势是负的,则如果执行行动
a
a
a 的可能性更小 ,即如果
π
θ
(
a
∣
s
)
π_\theta(a|s)
πθ(a∣s) 减小,目标函数就会增加。但是该项中的 max 限制了目标函数可以增加到多少。
一旦
π
θ
(
a
∣
s
)
<
(
1
−
ϵ
)
π
θ
k
(
a
∣
s
)
\pi_\theta(a|s)<(1-\epsilon)\pi_{\theta_k}(a|s)
πθ(a∣s)<(1−ϵ)πθk(a∣s), max 触发,限制该项值为
(
1
−
ϵ
)
π
θ
k
(
a
∣
s
)
(1-\epsilon)\pi_{\theta_k}(a|s)
(1−ϵ)πθk(a∣s)。
再次说明:the new policy does not benefit by going far away from the old policy.
新策略 不会因远离 旧策略而受益。
TD3_仅连续: Twin Delayed Deep Deterministic Policy Gradient 【ICML 2018 (加拿大)麦吉尔大学】

图片来源
OpenAI 文档_TD3
论文链接
虽然 DDPG 有时可以实现出色的性能,但在超参数和其他类型的调优方面,它通常是不稳定的。
一个常见的 DDPG 失败模式是,学习到的 Q 函数开始显著高估 Q 值,然后导致策略中断,因为它利用了 Q 函数中的误差。
双延迟 DDPG (Twin Delayed DDPG, TD3) 是一种通过引入三个关键技巧来解决此问题的算法:
1、截断的双 Q 学习。
- TD3 学习两个 Q 函数而不是一个(因此是 “twin”),并使用两个 Q 值中较小的一个来形成 Bellman 误差损失函数中的目标。
2、策略更新延迟。
- TD3 更新策略(和 目标网络) 的频率低于 Q 函数。论文建议 Q 函数每更新两次, 更新一次策略。
3、目标策略平滑。
- TD3 在目标动作中添加噪声,通过平滑动作变化中的 Q 使策略更难利用 Q 函数的误差。
TD3 是一个 off-policy 算法;只能用于具有连续行动空间的环境。
TD3 算法伪码

算法: TD3
用随机参数 θ 1 , θ 2 , ϕ \theta_1, \theta_2, \phi θ1,θ2,ϕ 初始化 critic 网络 Q θ 1 , Q θ 2 Q_{\theta_1},Q_{\theta_2} Qθ1,Qθ2, 和 actor 网络 π ϕ \pi_\phi πϕ
初始化 目标网络 θ 1 ′ ← θ 1 , θ 2 ′ ← θ 2 , ϕ ′ ← ϕ \theta_1^\prime\leftarrow\theta_1, \theta_2^\prime\leftarrow\theta_2, \phi^\prime\leftarrow \phi θ1′←θ1,θ2′←θ2,ϕ′←ϕ
初始化 回放缓冲集 B \cal B B
f o r t = 1 t o T {\bf for}~t=1 ~{\bf to} ~T for t=1 to T :
~~~~~~ 选择 带探索噪声的动作 a ∼ π ϕ ( s ) + ϵ , ϵ ∼ N ( 0 , σ ) a\sim\pi_\phi(s)+\epsilon,~~\epsilon\sim {\cal N}(0,\sigma) a∼πϕ(s)+ϵ, ϵ∼N(0,σ), 观测 奖励 r r r 和新的状态 s ′ s^\prime s′
~~~~~~ 将 transition 元组 ( s , a , r , s ′ ) (s, a,r, s^\prime) (s,a,r,s′) 存到 B \cal B B 中
~~~~~~ 从 B \cal B B 中抽样 小批次的 N N N 个 transitions ( s , a , r , s ′ ) (s, a, r, s^\prime) (s,a,r,s′)
a ~ ← π ϕ ′ ( s ′ ) + ϵ , ϵ ∼ c l i p ( N ( 0 , σ ~ ) , − c , c ) ~~~~~~\widetilde a\leftarrow \pi_{\phi^\prime}(s^\prime)+\epsilon,~~\epsilon\sim{\rm clip}({\cal N}(0,\widetilde \sigma),-c,c) a ←πϕ′(s′)+ϵ, ϵ∼clip(N(0,σ ),−c,c)
y ← r + γ min i = 1 , 2 Q θ i ′ ( s ′ , a ~ ) ~~~~~~y\leftarrow r+\gamma \min\limits_{i=1,2}Q_{\theta_i^\prime}(s^\prime,\widetilde a) y←r+γi=1,2minQθi′(s′,a )
~~~~~~ 更新 critics θ i ← arg min θ i N − 1 ∑ ( y − Q θ i ( s , a ) ) 2 \theta_i\leftarrow\arg\min\limits_{\theta_i}N^{-1}\sum(y-Q_{\theta_i}(s, a))^2 θi←argθiminN−1∑(y−Qθi(s,a))2
~~~~~~ i f t % d {\bf if}~t~ \% ~d if t % d:
~~~~~~~~~~~ 通过 确定性策略梯度 更新 ϕ \phi ϕ
∇ ϕ J ( ϕ ) = N − 1 ∑ ∇ a Q θ 1 ( s , a ) ∣ a = π ϕ ( s ) ∇ ϕ π ϕ ( s ) ~~~~~~~~~~~~~~~~~\nabla _\phi J(\phi)=N^{-1}\sum\nabla_aQ_{\theta_1}(s, a)|_{a=\pi_\phi(s)}\nabla_\phi\pi_\phi(s) ∇ϕJ(ϕ)=N−1∑∇aQθ1(s,a)∣a=πϕ(s)∇ϕπϕ(s)
~~~~~~~~~~~ 更新 目标网络:
θ i ′ ← τ θ i + ( 1 − τ ) θ i ′ ~~~~~~~~~~~~~~~~~\theta_i^\prime\leftarrow\tau\theta_i+(1-\tau)\theta_i^\prime~~~~~ θi′←τθi+(1−τ)θi′ τ \tau τ: 目标更新率
ϕ ′ ← τ ϕ + ( 1 − τ ) ϕ ′ ~~~~~~~~~~~~~~~~~\phi^\prime\leftarrow\tau\phi+(1-\tau)\phi^\prime ϕ′←τϕ+(1−τ)ϕ′
e n d i f ~~~~~~{\bf end ~if} end if
e n d f o r {\bf end ~for} end for
Soft Actor-Critic:SAC_连续/离散动作空间 【Google Brain 最新版本 201906】

图片来源
最大化策略的熵,从而使得策略更加鲁棒。
确定性策略 是指在给定相同状态下,总是选择相同的动作
随机性策略 则是在给定状态下可以选择多种可能的动作
| 确定性策略 | 随机性策略 | |
|---|---|---|
| 定义 | 同样的状态,执行同样的动作 | 同样的状态,可能执行不同的动作 |
| 优点 | 稳定、可重复 | 避免陷入局部最优解,提高全局搜索的能力 |
| 缺点 | 缺乏探索性、易被对手抓到 | 可能会导致策略的收敛速度较慢,影响效率和性能。 |
实际应用中,如果有条件的话,我们会尽量使用随机性策略,诸如 A2C、PPO 等等,因为它更加灵活,更加鲁棒,更加稳定。
最大熵强化学习认为,即使我们目前有了成熟的随机性策略,即 AC 一类的算法,但是还是没有达到最优的随机。因此,它引入了一个信息熵的概念,在最大化累积奖励的同时最大化策略的熵,使得策略更加鲁棒,从而达到最优的随机性策略。
——————————————————
—— OpenAI 文档_SAC
OpenAI 文档_SAC 界面链接
~
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al, 201808 ICML 2018
Soft Actor-Critic Algorithms and Applications, Haarnoja et al, 201901
Learning to Walk via Deep Reinforcement Learning, Haarnoja et al, 201906 RSS2019
Soft Actor Critic (SAC) 以 off-policy 方式优化 随机策略。
DDPG + 随机策略优化
不是 TD3 的直接继承者 (几乎同时发表)。
它包含了 clipped double-Q 技巧,并且由于 SAC 的策略的固有随机性,它也最终受益于目标策略平滑。
SAC 的一个核心特征是 entropy regularization 熵正则化。
该策略被训练为 最大化 期望回报 和 熵 之间的权衡,熵 是 策略随机性 的度量。
这 与探索和利用之间的权衡 有密切的联系:熵的增加导致更多的探索,这可以加速后续的学习。它还可以防止策略过早收敛到一个坏的局部最优。
既可用于连续动作空间,也可用于离散动作空间。
在 熵-正则化 强化学习中,智能体在每个时间步获得与该时间步策略的熵成正比的奖励。
此时 RL 问题描述为:
π ∗ = arg max π E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( s t , a t , s t + 1 ) + α H ( π ( ⋅ ∣ s t ) ) ) ] \pi^*=\arg\max\limits_\pi \underset{\tau\sim\pi}{\rm E}\Big[\sum\limits_{t=0}^\infty\gamma^t\Big(R(s_t,a_t,s_{t+1})\textcolor{blue}{+\alpha H(\pi(·|s_t))}\Big)\Big] π∗=argπmaxτ∼πE[t=0∑∞γt(R(st,at,st+1)+αH(π(⋅∣st)))]
其中
α
>
0
\alpha > 0
α>0 为权衡系数。
包括每个时间步的熵奖励的状态值函数
V
π
V^\pi
Vπ 为:
V π ( s ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( s t , a t , s t + 1 ) + α H ( π ( ⋅ ∣ s t ) ) ) ∣ s 0 = s ] V^\pi(s)=\underset{\tau\sim\pi}{\rm E}\Big[\sum\limits_{t=0}^\infty\gamma^t\Big(R(s_t,a_t,s_{t+1})+\alpha H(\pi(·|s_t))\Big)\Big|s_0=s\Big] Vπ(s)=τ∼πE[t=0∑∞γt(R(st,at,st+1)+αH(π(⋅∣st))) s0=s]
包括除了第一个时间步以外的每个时间步的熵奖励 的 动作值函数 Q π Q^\pi Qπ:
Q π ( s , a ) = E τ ∼ π [ ∑ t = 0 ∞ γ t ( R ( s t , a t , s t + 1 ) + α ∑ t = 1 ∞ H ( π ( ⋅ ∣ s t ) ) ) ∣ s 0 = s , a 0 = a ] Q^\pi(s,a)=\underset{\tau\sim\pi}{\rm E}\Big[\sum\limits_{t=0}^\infty\gamma^t\Big(R(s_t,a_t,s_{t+1})+\alpha \sum\limits_{t=1}^\infty H(\pi(·|s_t))\Big)\Big|s_0=s,a_0=a\Big] Qπ(s,a)=τ∼πE[t=0∑∞γt(R(st,at,st+1)+αt=1∑∞H(π(⋅∣st))) s0=s,a0=a]
- 有些论文 的 Q π Q^\pi Qπ 包含第一个时间步的熵奖励
V π V^\pi Vπ 和 Q π Q^\pi Qπ 间的关系为:
V π ( s ) = E a ∼ π [ Q π ( s , a ) ] + α H ( π ( ⋅ ∣ s ) ) V^\pi(s)=\underset{a\sim\pi}{\rm E}[Q^\pi(s, a)]+\alpha H(\pi(·|s)) Vπ(s)=a∼πE[Qπ(s,a)]+αH(π(⋅∣s))
关于 Q π Q^\pi Qπ 的贝尔曼公式为:
Q π ( s , a ) = E s ′ ∼ P a ′ ∼ π [ R ( s , a , s ′ ) + γ ( Q π ( s ′ , a ′ ) + α H ( π ( ⋅ ∣ s ′ ) ) ) ] = E s ′ ∼ P [ R ( s , a , s ′ ) + γ V π ( s ′ ) ] \begin{aligned}Q^\pi(s, a)&=\underset{s^\prime \sim P \atop a^\prime\sim \pi}{\rm E}[R(s,a,s^\prime)+\gamma\big(Q^\pi(s^\prime,a^\prime)+\alpha H(\pi(·|s^\prime))\big)]\\ &=\underset{s^\prime \sim P}{\rm E}[R(s,a,s^\prime)+\gamma V^\pi(s^\prime)]\end{aligned} Qπ(s,a)=a′∼πs′∼PE[R(s,a,s′)+γ(Qπ(s′,a′)+αH(π(⋅∣s′)))]=s′∼PE[R(s,a,s′)+γVπ(s′)]
SAC 同时学习一个策略
π
θ
π_\theta
πθ 和两个
Q
Q
Q 函数
Q
ϕ
1
,
Q
ϕ
2
Q_{\phi_1}, Q_{\phi_2}
Qϕ1,Qϕ2。
目前标准的 SAC 有两种变体:一种使用固定的熵正则化系数
α
\alpha
α,另一种通过在训练过程中改变
α
\alpha
α 来强制熵约束。
OpenAI 的文档使用具有固定熵正则化系数的版本,但实践中通常更喜欢熵约束的变体。
如下图,在 α \alpha α 固定版本中, 除了最后一个图有较明显的优势,其它只是略有优势,基本和 α \alpha α 学习版本持平;而在 α \alpha α 学习版本有优势的中间两图,优势较明显。

图片来源
SACVSTD3:
~
相同点:
1、两个 Q 函数都是通过回归到单个共享目标的 MSBE (Mean Squared Bellman Error) 最小化来学习的。
2、利用目标 Q-网络计算共享目标,并对训练过程中的 Q-网络参数进行 polyak 平均得到 目标 Q-网络。
3、共享目标使用了被截断的双 Q 技巧。
~
不同点:
1、SAC 包含 熵正则化 项
2、SAC 的目标中使用的下一状态 的动作来自当前策略,而不是目标策略。
3、没有明确的目标策略平滑。TD3 训练一个确定性策略,它通过向下一状态的动作添加随机噪声来实现平滑。SAC 训练的是一个随机策略, 来自随机性的噪声足以获得类似的效果。
SAC 算法伪码

算法: Soft Actor-Critic SAC
输入: θ 1 , θ 2 , ϕ \theta_1,\theta_2,\phi~~~~~ θ1,θ2,ϕ 初始化参数
参数初始化:
~~~~~~ 初始化目标网络权重: θ ˉ 1 ← θ 1 , θ ˉ 2 ← θ 2 \bar \theta_1\leftarrow\theta_1, \bar \theta_2\leftarrow\theta_2 θˉ1←θ1,θˉ2←θ2
~~~~~~ 回放池 初始化为空: D ← ∅ {\cal D}\leftarrow\emptyset D←∅
f o r {\bf for} for 每次迭代 d o {\bf do} do :
~~~~~~ f o r {\bf for} for 每个环境 step d o {\bf do} do :
~~~~~~~~~~~ 从策略中抽样动作: a t ∼ π ϕ ( a t ∣ s t ) a_t\sim\pi_\phi(a_t|s_t)~~~~~ at∼πϕ(at∣st) ▢ 这里的 π ϕ ( a t ∣ s t ) \pi_\phi(a_t|s_t) πϕ(at∣st) 如何定义?
~~~~~~~~~~~ 从环境中抽样 transition: s t + 1 ∼ p ( s t + 1 ∣ s t , a t ) s_{t+1}\sim p(s_{t+1}|s_t,a_t) st+1∼p(st+1∣st,at)
~~~~~~~~~~~ 将 transition 存到 回放池: D ← D ∪ { ( s t , a t , r ( s t , a t ) , s t + 1 ) } {\cal D}\leftarrow{\cal D}~\cup~\{(s_t,a_t,r(s_t,a_t),s_{t+1})\} D←D ∪ {(st,at,r(st,at),st+1)}
~~~~~~ e n d f o r {\bf end ~for} end for
~~~~~~ f o r {\bf for} for 每个梯度 step d o {\bf do} do :
~~~~~~~~~~~ 更新 Q Q Q 函数参数: 对于 i ∈ { 1 , 2 } i\in\{1,2\} i∈{1,2}, θ i ← θ i − λ Q ∇ ^ θ i J Q ( θ i ) \theta_i\leftarrow\theta_i-\lambda_Q\hat \nabla_{\theta_i}J_Q(\theta_i)~~~~~ θi←θi−λQ∇^θiJQ(θi) ▢ 这里的 J Q ( θ i ) J_Q(\theta_i) JQ(θi) 如何定义?
~~~~~~~~~~~ 更新 策略权重: ϕ ← ϕ − λ π ∇ ^ ϕ J π ( ϕ ) \phi\leftarrow\phi-\lambda_\pi\hat \nabla_\phi J_\pi (\phi)~~~~~ ϕ←ϕ−λπ∇^ϕJπ(ϕ) ▢ 这里的 J π ( ϕ ) J_\pi (\phi) Jπ(ϕ) 如何定义?
~~~~~~~~~~~ 调温度: α ← α − λ ∇ ^ α J ( α ) \alpha\leftarrow\alpha-\lambda\hat\nabla_\alpha J(\alpha)~~~~~ α←α−λ∇^αJ(α) ▢ 这里的 J ( α ) J(\alpha) J(α) 如何定义?如何理解 这里的 temperature 温度
~~~~~~~~~~~ 更新 目标网络 权重:对于 i ∈ { 1 , 2 } i\in\{1,2\} i∈{1,2}, θ ˉ i ← τ θ i − ( 1 − τ ) θ ˉ i \bar \theta_i\leftarrow \tau \theta_i-(1-\tau)\bar \theta_i~~~~~ θˉi←τθi−(1−τ)θˉi ▢ 如何理解这里的 τ \tau τ? ——> 目标平滑系数
~~~~~~ e n d f o r {\bf end ~for} end for
e n d f o r {\bf end ~for} end for
输出: θ 1 , θ 1 , ϕ \theta_1,\theta_1,\phi~~~~~ θ1,θ1,ϕ 优化好的参数
∇ ^ \hat \nabla ∇^: 随机梯度
$\emptyset$
∅
~~~~\emptyset
∅


Learning to Walk via Deep Reinforcement Learning 中的版本:
~



α
α
α 是温度参数,它决定了熵项与奖励的相对重要性,从而控制了最优策略的随机性。
α
\alpha
α 大: 探索
α
\alpha
α 小: 利用
J ( α ) = E a t ∼ π t [ − α log π t ( a t ∣ s t ) − α H ˉ ] J(\alpha)=\underset{a_t\sim\pi_t}{\mathbb E}[-\alpha\log \pi_t(a_t|s_t)-\alpha\bar{\cal H}] J(α)=at∼πtE[−αlogπt(at∣st)−αHˉ]