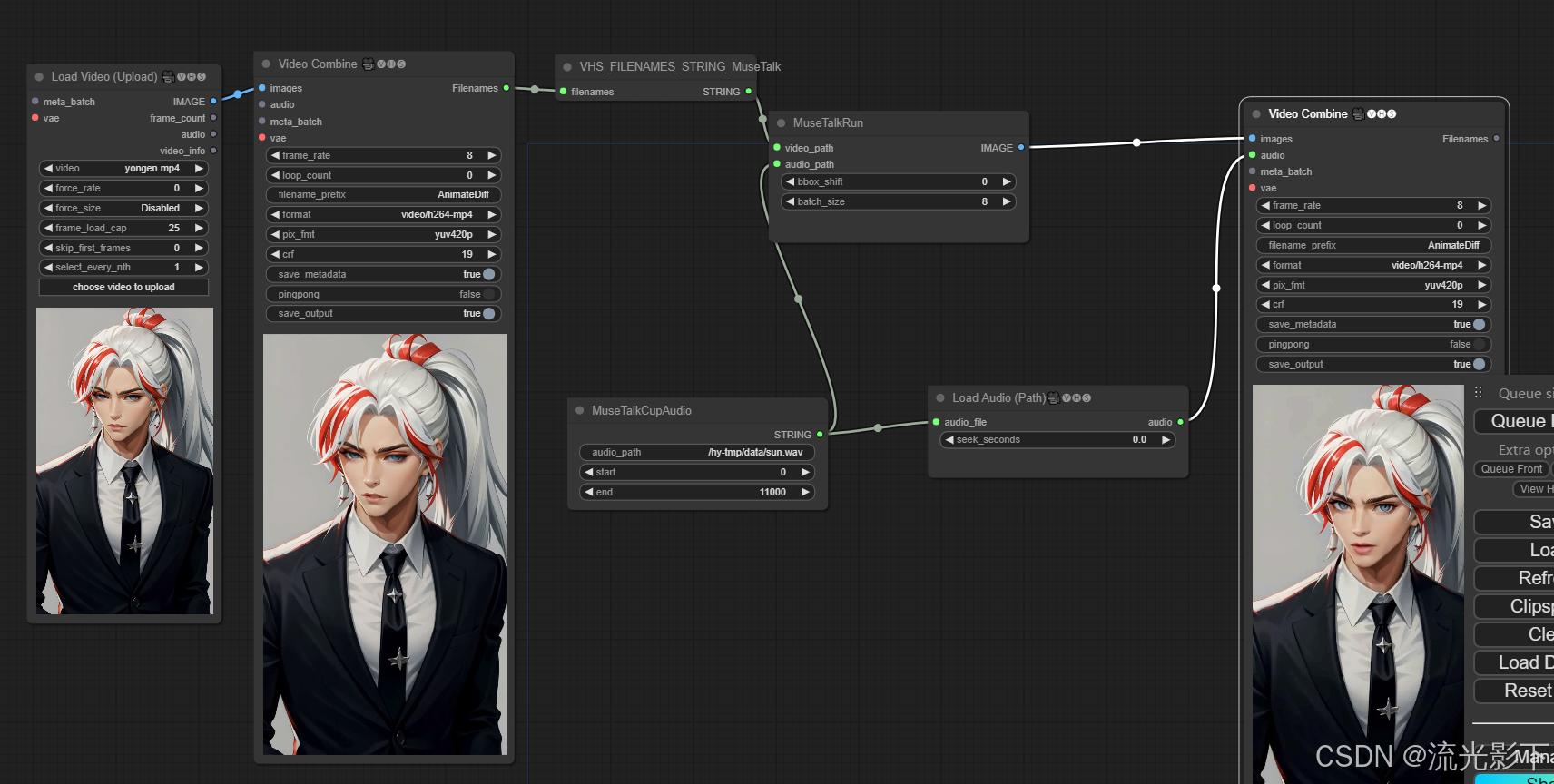
今天给大家分享的是国内顶级期刊中国工业经济2023年发布的最新期刊《政策赋能、数字生态与企业数字化转型——基于国家大数据综合试验区的准自然实验》文章中所使用到的数据集——国家大数据综合试验区政策数据集以及工具变量数据,该文章基于2009-2019年中国上市企业面板数据,以国家大数据综合试验区为准自然实验,从数字生态视角考察国家大数据综合试验区政策对企业数字化转型升级的影响。研究发现大数据试验区对企业的数字化转型起着促进作用,特别是对企业底层数字技术运用的促进作用更加明显,并且从政府数字补贴、数字发展环境以及数字化企业和人力资本集聚的数字知识溢出三个方面探讨了大数据试验区政策对企业数字化转型的传导机制,并进行了一系列异质性分析,最终得出结论,并给出相应的政策建议。该文章在分析的过程中使用到了国家大数据综合试验区政策以及工具变量数据,我们对这两部分数据进行了整理,并进行了适当的拓展,数据获取请关注公众号“明天科技屋”,打开公众号文章获取文末数字关键词并回复,在该数据发布24小时之内可以通过分享获得。
一、论文讲解

该文章是以中国上市企业为研究对象,以国家大数据综合试验区开展准自然实验,采用双重差分模型考察了大数据试验区设立对企业数字化转型发展的影响,并且从不同层次企业数字化技术分析了大数据政策对企业不同层次数字化水平的影响效应,同时采用多种稳健性检验方法对基准结果结论进行检验,结果依然可靠,并且以数字生态视角从政府数字补贴、数字发展环境以及数字知识溢出三个方面进行了传到极致检验,在异质性分析方面,从所有制性质、企业规模、行业数字化程度、行业要素密集程度以及企业初始数字化水平多角度进行异质性分析,同时金融发展水平、数字基础条件以及制度环境三个方面进行调节效应检验,最终得出结论,给出相应的建议。
(一)模型设定
本文使用了双重差分法考察了大数据试验区设立对企业数字化转型发展的影响,具体模型设定如下:
其中,下标i、j、t分别表示企业、城市和年份。被解释变量表示企业i在t年的数字化水平。
为城市j是否属于大数据试验区的虚拟变量,取值为1表示是,取值为0代表否;
为大数据试验区政策实施前后的虚拟变量,2016年之前为0,2016年之后为1。
表示可能影响企业数字化水平的企业层面随时间变化的控制变量,包括净资产收益率、企业收入、企业总资产、企业年龄、董事长和总经理是否兼任、会计师事务所审计意见、资本密集度、第一大股东持股比例、现金流强度、账面市值比和资产负债率。
表示城市层面的控制变量,包括人均GDP、人口规模、高校数量、外商直接投资额和产业结构(第二产业增加值比重和第三产业增加值比重)。
为企业固定效应,
为时间固定效应,
为随机扰动项。
(二)数据来源与处理
国家大数据综合试验区数据来源于中国政府网,企业数据来自国泰安数据库,样本为2009-2019年沪深A股上市企业数据。
(三)实证分析
1.基准回归
2.不同层次数字化水平检验
将企业数字化水平划分为“底层技术运用”水平和“数字技术应用”水平,考察大数据综合试验区政策对不同层次数字化水平影响
3.机制分析
从政府数字补贴、数字发展环境以及数字知识溢出三个方面考察了大数据综合试验区对企业数字化水平的传导机制。
(四)进一步分析
1.异质性分析
从所有制性质、企业规模、行业数字化程度、行业要素密集度以及企业初始化数字水平多角度考察了大数据综合试验区政策对企业数字化水平的影响。
2.调节效应检验
从金融发展水平、数字基础条件以及制度环境三个方面今天了调节效应分析
(五)结论与启示
期刊征文部分没有提到稳健性检验内容,这部分内容在附录里面,主要也是正常的稳健性检验内容,大家感兴趣可以自行查看,接下来给大家分享我们收集整理的数据集。
二、重要数据
改文章是以企业为研究对象,样本区间为2009-2019年,我们收集整理了国家大数据综合试验区名单,并且在样本区间进来了拓展,得到了2008年-2022年国家大数据综合试验区地级市实施数据,同时论文在进行稳健性检验事使用到了工具变量数据,我们也进行了收集整理,方便大家研究。
(一)国家大数据综合试验区地级市面板数据
国家大数据综合试验区在8个地区不同时间实施,包括城市群、省份以及地级市等地区,我们收集整理了不同地区实施的相关信息,并且将数据保存在“原始数据表”中,大家可以直观了解原始数据,充分相信数据的准确性,其中,京津冀地区包括北京、天津和湖北,珠江三角洲参考论文的处理方式,将整个广东省划分为处理组,我们对原始数据进行了转换,最终得到了2008年到2022年的国家大数据综合试验区200个地级市实施的面板数据,政策实施虚拟变量保存在DID列中,数据保存在“面板数据”表中,数据展示如下:

(二)工具变量数据
论文中选用了地质条件作为政策的工具变量,具体到实际数据为2004-2015年各省7级以上地震次数,该变量能够很好地满足工具变量的有效性,指标越大说明该地区的地质稳定性越差,设立大数据试验区的概率也越低,数据来源于中国统计年鉴,我们对该数据进行了收集整理,并保存在“工具变量”表中,具体数据展示如下:

在实际使用过程中,作者使用了地质稳定性指标与上面提到的post指标乘积作为bigdata*post的工具变量,我们将原始数据按照作者的使用方法进行了转换,并将工具变量数据和政策实施面板数据进行了拼接,这样大家使用起来非常方便,数据保存在“面板数据”表中的工具变量列中,数据展示如下:

以上就是本次分享的全部内容,大家可以看到我们对分享的数据是十分认真和用心的,并且站在使用者的角度考虑,所以大家完全可以相信数据的质量,最后,数据在发布时间起24小时内通过关键词指示操作即可免费获取,关注公众号“明天科技屋”并回复数字关键词了解数据获取方式,该数据由明天科技屋一手整理,版权归明天科技屋所有,未经允许,不得用于商业盈利,否则将追随法律责任!!!