磐维数据库简介
“中国移动磐维数据库”(ChinaMobileDB),简称“磐维数据库”(PanWeiDB)。是中国移动信息技术中心首个基于中国本土开源数据库打造的面向ICT基础设施的自研数据库产品。
其产品内核能力基于华为 OpenGauss 开源软件,并进一步提升了系统稳定性。
磐维数据库 V1.0 基于 openGauss 3.0 研发,在2022年12月29日,openGauss Summit 2022大议上正式发布。
磐维数据库 V2.0 基于 openGauss 5.0 研发,在2023年12月28日,openGauss Summit 2023大会上重磅发布。
磐维数据库2.0,具有高性能、高可靠、高安全、高兼容等特点,能够为集中式、分布式、云原生、一体机等多种应用场景提供强大支撑。
1.磐维数据库查询结果按列展示
磐维数据库中如何实现查询结果按列展示?类似与MySQL数据库的\G效果,可以使用\x命令,以扩展方式显示查询结果
[omm@pw01 data]$ gsql -d postgres
gsql ((PanWeiDB 2.0.0 (Build0)) compiled at 2024-01-05 17:19:18 commit 9fbca90 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
postgres=# \x
Expanded display is on.
postgres=# \l
List of databases
-[ RECORD 1 ]-----+------------
Name | panweidb
Owner | omm
Encoding | UTF8
Collate | C
Ctype | C
Access privileges |
-[ RECORD 2 ]-----+------------
Name | postgres
Owner | omm
Encoding | UTF8
Collate | C
Ctype | C
Access privileges |
-[ RECORD 3 ]-----+------------
Name | template0
Owner | omm
Encoding | UTF8
Collate | C
Ctype | C
Access privileges | =c/omm
| omm=CTc/omm
-[ RECORD 4 ]-----+------------
Name | template1
Owner | omm
Encoding | UTF8
Collate | C
Ctype | C
Access privileges | =c/omm
| omm=CTc/omm
postgres=# select * from pg_user limit 1;
-[ RECORD 1 ]----+-------------
usename | pwaudit
usesysid | 34
usecreatedb | f
usesuper | f
usecatupd | f
userepl | f
passwd | ********
valbegin |
valuntil |
respool | default_pool
parent | 0
spacelimit |
useconfig |
nodegroup |
tempspacelimit |
spillspacelimit |
usemonitoradmin | f
useoperatoradmin | f
usepolicyadmin | f
postgres=#
postgres=# \x
Expanded display is off.
postgres=# 2.gsql常用命令介绍
本文介绍磐维数据库里后台psql工具在一些常用场景下的快捷使用命令。
2.1 使用-r便捷编辑模式
[omm@pw01 data]$ gsql -d postgres -r
gsql ((PanWeiDB 2.0.0 (Build0)) compiled at 2024-01-05 17:19:18 commit 9fbca90 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
postgres=# 
否则当输入出错时,不能直接使用删除键。

2.2 快速编辑SQL并执行
元命令\e自动打开上次的查询进行编辑,编辑完成之后立刻执行
[omm@pw01 data]$ gsql -d postgres -r
gsql ((PanWeiDB 2.0.0 (Build0)) compiled at 2024-01-05 17:19:18 commit 9fbca90 last mr )
Non-SSL connection (SSL connection is recommended when requiring high-security)
Type "help" for help.
postgres=# select * from pg_users limit 1;
ERROR: relation "pg_users" does not exist on dn_6001_6002_6003
LINE 1: select * from pg_users limit 1;
^
postgres=# \e
select * from pg_users limit 1;
~
上面使用\e直接在上一个SQL语句里进行编辑修改,然后wq保存退出编辑模式之后,自动执行新SQL语句。
2.3 定制客户端提示符
客户端提示符变量,我们可以定制PROMPT1(等待新命令时的提示符),.gsqlrc文件可以进行下面的设置:
\set PROMPT1 '%`date +%H:%M:%S` (%n@%M:%>)%/%R%#%x'
postgres=# \set PROMPT1 '%`date +%H:%M:%S` (%n@%M:%>)%/%R%#%x'
17:40:30 (omm@local:/database/panweidb/tmp:17700)postgres=#
17:40:32 (omm@local:/database/panweidb/tmp:17700)postgres=#select * from dual;
dummy
-------
X
(1 row)
17:40:50 (omm@local:/database/panweidb/tmp:17700)postgres=#
PROMPT1变量可以定制操作系统的命令,例如显示时间。
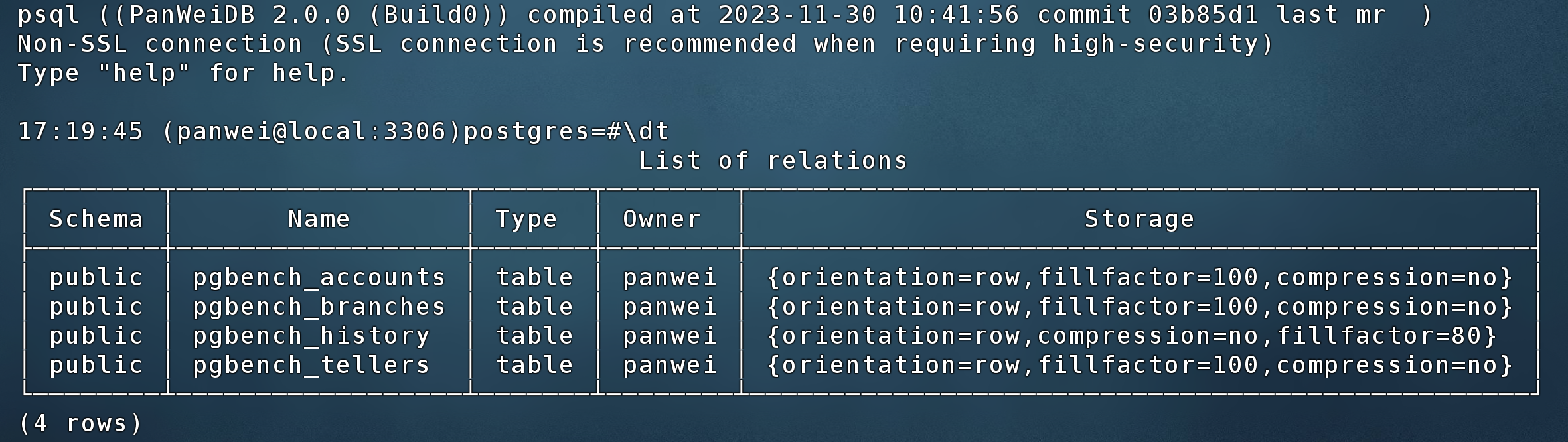
2.4 使用边框美化查询结果
在.gsqlrc文件增加下面的设置,可以对查询结果设置边框,美化输出。
\pset border 2
\pset linestyle unicode
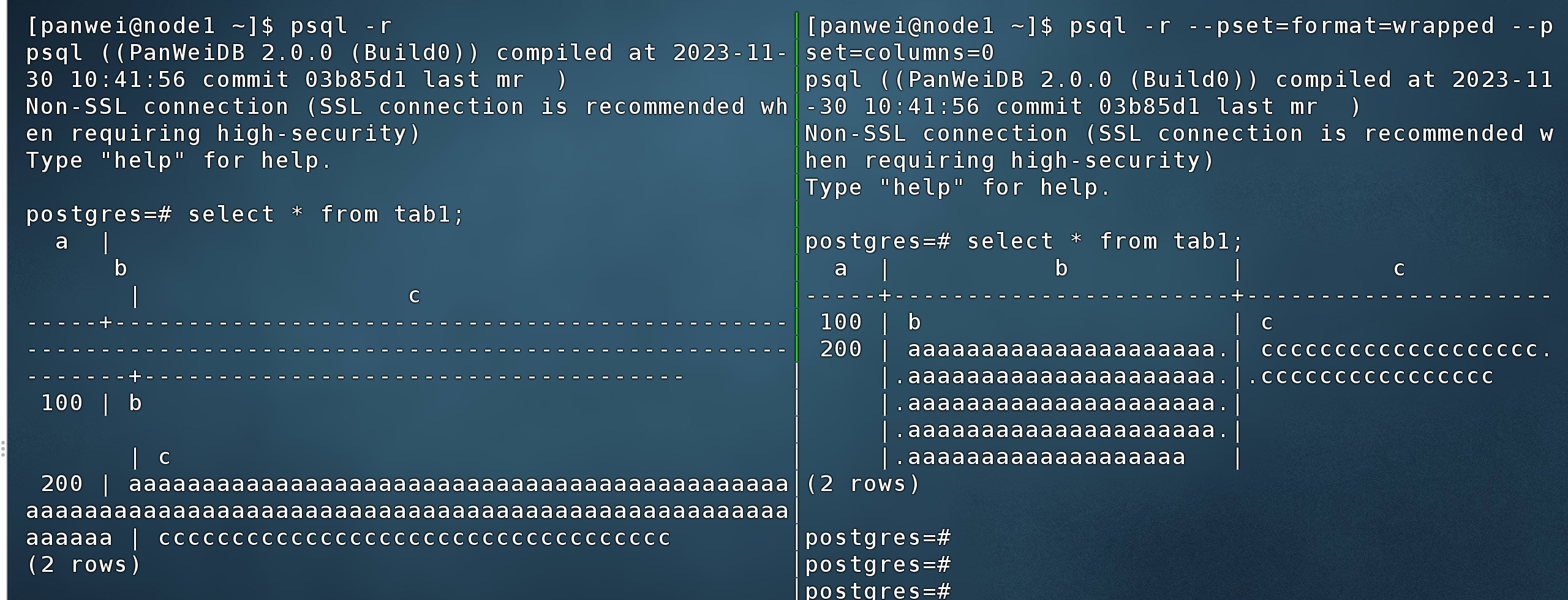
2.5 查询结果自动适配屏幕宽度
在psql里面使用如下pset命令
pset format wrapped \pset columns 0 或者psql选项里加这两个设置$ psql -r --pset=format=wrapped --pset=columns=0
2.6 输出不同的查询格式
文本紧凑模式
[omm@pw01 data]$ psql -qtA -c "select * from pg_user limit 2;"
pwaudit|34|0|0|0|0|********|||default_pool|0||||||0|0|0
pwsso|35|0|0|0|0|********|||default_pool|0||||||0|0|0
[omm@pw01 data]$ 文本紧凑模式,使用多字符分隔符@@
[omm@pw01 data]$ psql -qtA -F '@@' -c "select * from pg_user limit 2;"
pwaudit@@34@@0@@0@@0@@0@@********@@@@@@default_pool@@0@@@@@@@@@@@@0@@0@@0
pwsso@@35@@0@@0@@0@@0@@********@@@@@@default_pool@@0@@@@@@@@@@@@0@@0@@0
[omm@pw01 data]$ HTML格式
[omm@pw01 data]$ psql -qtH -c "select * from pg_user limit 2;"
<table border="1">
<tr valign="top">
<td align="left">pwaudit</td>
<td align="right">34</td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">********</td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left">default_pool</td>
<td align="right">0</td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">0</td>
</tr>
<tr valign="top">
<td align="left">pwsso</td>
<td align="right">35</td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">********</td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left">default_pool</td>
<td align="right">0</td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left"> </td>
<td align="left">0</td>
<td align="left">0</td>
<td align="left">0</td>
</tr>
</table>
[omm@pw01 data]$ 2.7查看元命令的query语句
使用-E或者–echo-hidden查看db的执行语句
$ psql -E -c "\l"
[omm@pw01 data]$ psql -E -c "\l"
********* QUERY **********
SELECT d.datname as "Name",
pg_catalog.pg_get_userbyid(d.datdba) as "Owner",
pg_catalog.pg_encoding_to_char(d.encoding) as "Encoding",
d.datcollate as "Collate",
d.datctype as "Ctype",
pg_catalog.array_to_string(d.datacl, E'\n') AS "Access privileges"
FROM pg_catalog.pg_database d
ORDER BY 1;
**************************
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
-----------+-------+----------+---------+-------+-------------------
panweidb | omm | UTF8 | C | C |
postgres | omm | UTF8 | C | C |
template0 | omm | UTF8 | C | C | =c/omm +
| | | | | omm=CTc/omm
template1 | omm | UTF8 | C | C | =c/omm +
| | | | | omm=CTc/omm
(4 rows)
[omm@pw01 data]$ 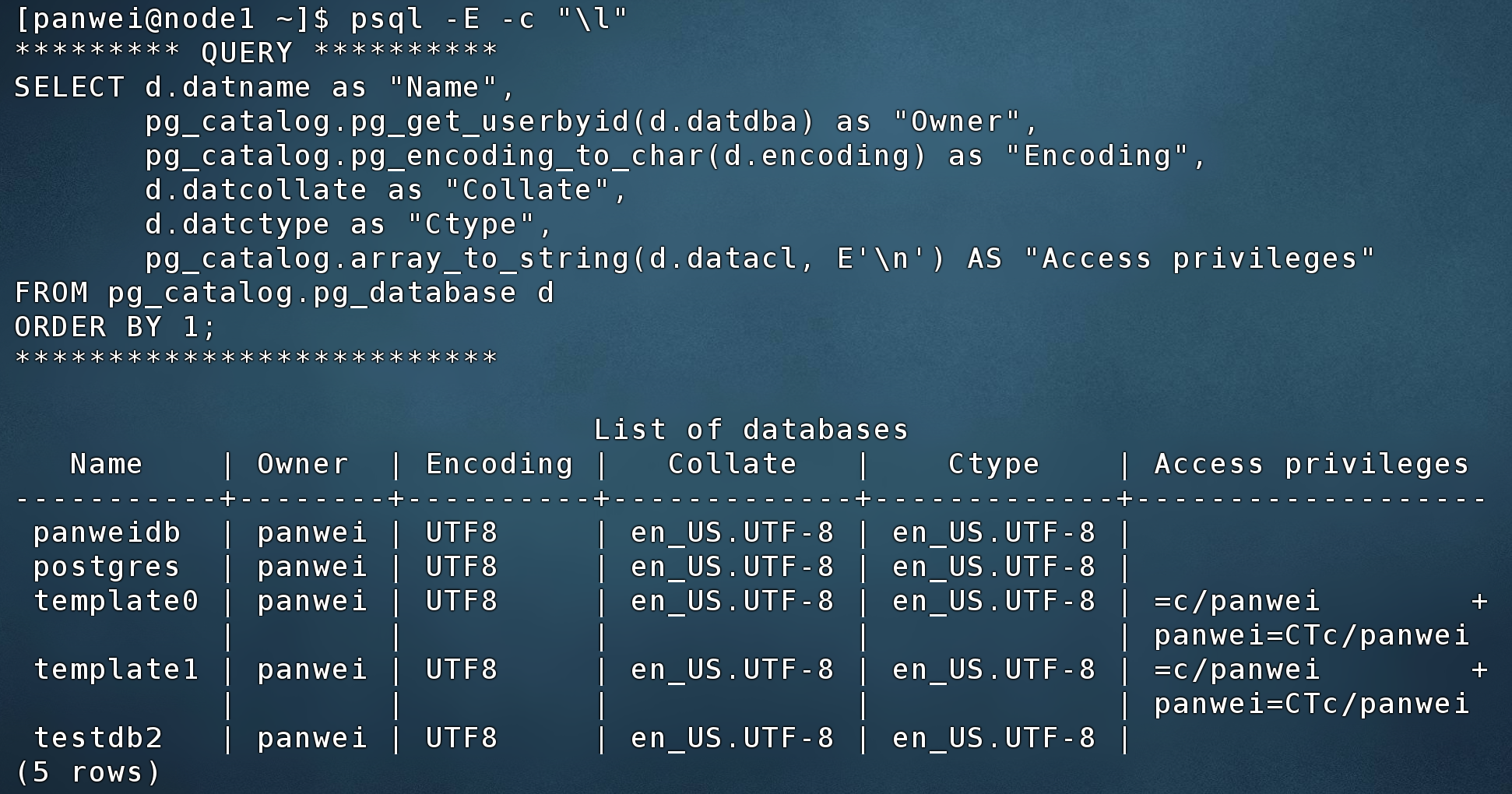
查看自定义函数函数列表
$ psql -E -c "\df"
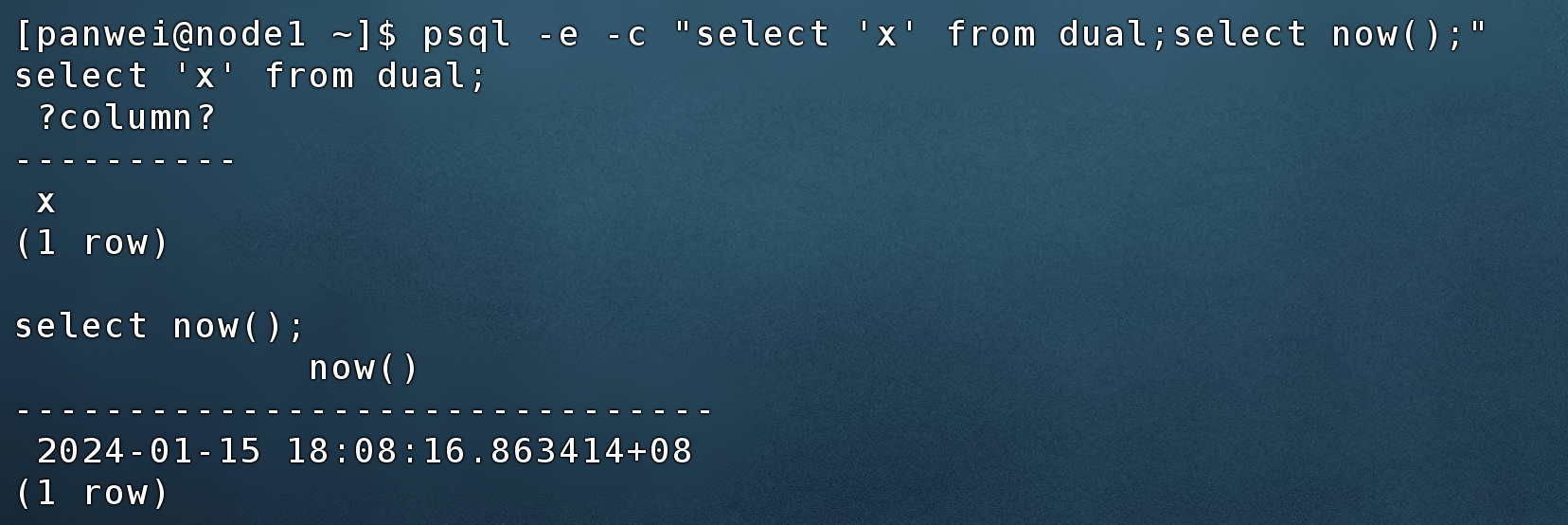
2.8 同时显示query语句及结果
使用-e,–echo-queries回显语句
$ psql -e -c "select 'x' from dual;select now();"
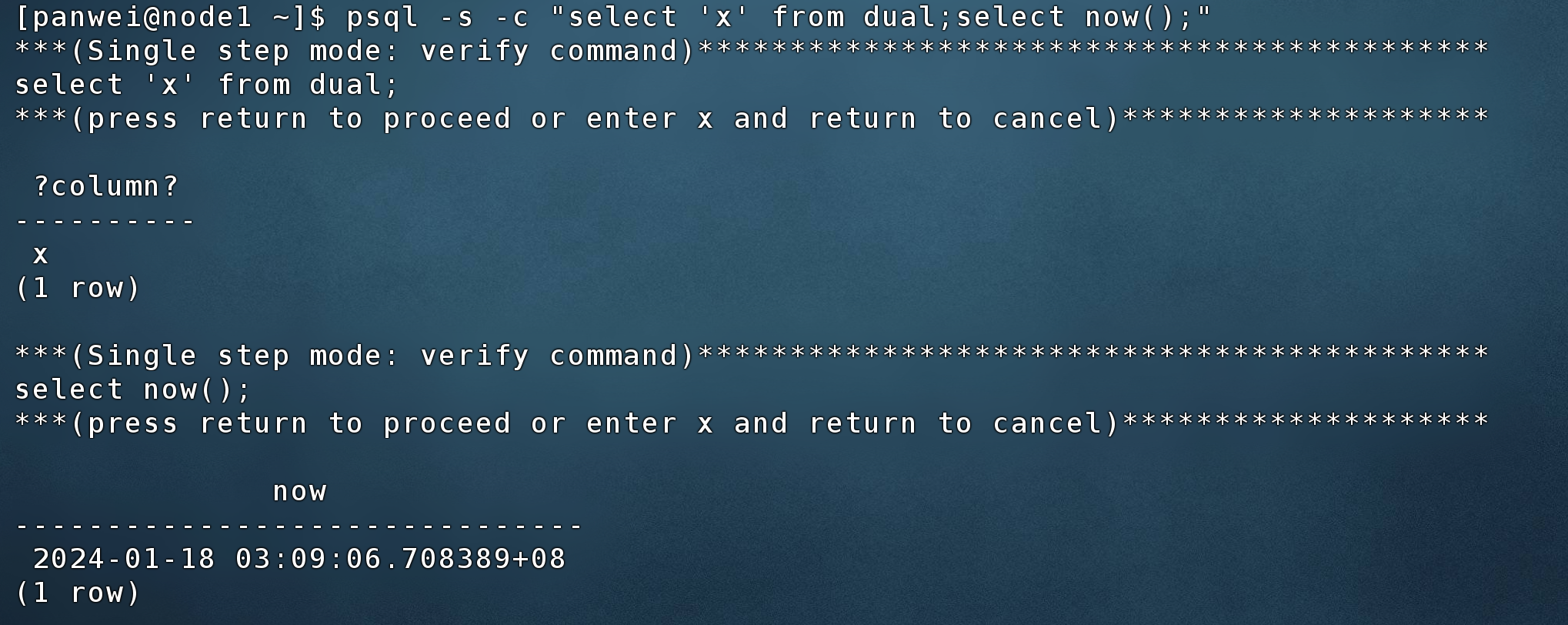
2.9 单步调试
使用-s,–single-step单步调试
$ psql -s -c "select 'x' from dual;select now();"
3.常用gsql的元命令
3.1 查看客户端工具版权信息:\copyright

3.2 查看当前登录信息:\conninfo
![]()
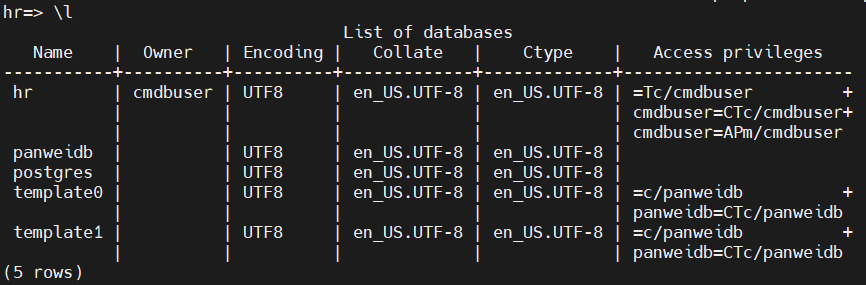
3.3 查看有哪些数据库:\l
3.4 查看有哪些数据表:\dt

3.5 \d查看表定义
postgres=# \dt
List of relations
Schema | Name | Type | Owner
--------+--------------------------+-------+----------
public | cloud_sql_static | table | postgres
public | cloud_subscriber_devices | table | postgres
public | cloud_subscribers | table | postgres
public | cloud_table_static | table | postgres
public | sxacc-device-types | table | postgres
public | sxacc-devices | table | postgres
(6 rows)
postgres=# \d cloud_table_static
Table "public.cloud_table_static"
Column | Type | Modifiers
---------------------+--------------------------+-----------
relname | character varying(255) |
seq_scan | bigint |
seq_tup_read | bigint |
idx_scan | bigint |
idx_tup_fetch | bigint |
n_tup_ins | bigint |
n_tup_upd | bigint |
n_tup_del | bigint |
n_tup_hot_upd | bigint |
n_live_tup | bigint |
n_dead_tup | bigint |
n_mod_since_analyze | bigint |
last_vacuum | timestamp with time zone |
last_autovacuum | timestamp with time zone |
last_analyze | timestamp with time zone |
last_autoanalyze | timestamp with time zone |
vacuum_count | bigint |
autovacuum_count | bigint |
analyze_count | bigint |
autoanalyze_count | bigint |
import_date | timestamp with time zone |
postgres=#3.6 查看表/索引占用空间大小
给测试表test插入500万数据:
postgres=# create table test(id int primary key, name varchar(100));
CREATE TABLE
postgres=# insert into test(id,name) select n,n||'_francs' from generate_series(1,5000000) n;
INSERT 0 5000000
postgres=# \di+ test_pkey
List of relations
Schema | Name | Type | Owner | Table | Size | Description
--------+-----------+-------+----------+-------+--------+-------------
public | test_pkey | index | postgres | test | 107 MB |
(1 row)
postgres=# \dt+ test
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+--------+-------------
public | test | table | postgres | 249 MB |
(1 row)3.7 切换数据库:\c 数据库名

3.8 切换目录
cd 如果不带参数,则切换到当前用户的主目录。\! pwd用来显示当前工作路径(叹号后有空格)
postgres=# \! pwd
/home/postgres
postgres=# \!pwd
Invalid command \!pwd. Try \? for help.
postgres=# \cd /pgtbs
postgres=# \! pwd
/pgtbs
postgres=#
3.9 显示执行时间(\timing on | off)
mydb=> \timing on
Timing is on.
mydb=> select id,name from t1 limit 10;3.10 退出命令行客户端:\q
[omm@panwei ~]$ gsql -d escspdb -r
gsql ((PanWeiDB 2.0.0 (Build0)) compiled at 2024-01-05 17:19:18 commit 9fbca90 last mr )
非SSL连接(安全性要求高时,建议使用SSL连接)
输入 "help" 来获取帮助信息。
escspdb=# \q
[omm@panwei ~]$ 3.11 其他
\db 列出表空间信息
\du 列出用户、角色
\dt 列出数据库表
\di 列出索引
\dx 列出插件
\df 列出函数
\dv 列出view
\i FILE 执行文件中的命令
\h [NAME] sql命令的help信息
使用psql执行sql命令,-c :指定psql执行一个给定的命令字符串command
psql -c '\x' -c 'SELECT * FROM pg_user;'
使用psql执行sql文件,-f :从文件filename而不是标准输入中读取命令
[postgres@pgserver12 ~]$ cat test.sql
select now();
select current_date;
select 1;
[postgres@pgserver12 ~]$ psql -f test.sql
把所有查询输出放到文件filename中。这等效于命令\o。
[postgres@pgserver12 ~]$ psql -o /tmp/2.log
4.死锁
4.1 如何统计死锁的条数:
postgres=# select datname,deadlocks from pg_stat_database;
datname | deadlocks
-----------+-----------
template1 | 0
template0 | 0
panweidb | 0
postgres | 0
(4 rows)
postgres=# 4.2 如何找到导致死锁的sql
方法1、通过报错找到对应的sql:
select * from pg_stat_activity where datname = 'db01';
select datname,pid,query,connection_info from pg_stat_activity where pid='47183102150400' or pid='47183356102400';以上的两个pid,是从死锁的报错中获取的。
方法2、直接去pg_log日志里,检索deadlock detected,下边有执行死锁的sql。
5.杀死会话
对于磐维CMDB数据库的会话查杀,建议优先使用pg_terminate_backend函数,如果查杀失败,需要使用更强力的命令时,可以使用kill -9或者kill命令查杀客户端进程。
在执行查杀的会话窗口中,查询pg_stat_activity获取连接会话的PID
select datid,pid,state,query from pg_stat_activity;
postgres=# select datid,pid,state,query from pg_stat_activity;
datid | pid | state | query
-------+----------------+--------+-----------------------------------------------------
20538 | 47456966424320 | idle |
20538 | 47456949643008 | idle |
20538 | 47457226524416 | idle | show default_transaction_read_only;
20538 | 47457377584896 | active | select datid,pid,state,query from pg_stat_activity;
(4 rows)
postgres=# 使用pg_terminate_backend杀会话
select * from pg_terminate_backend(47440526968576);
postgres=# select * from pg_terminate_backend(47440526968576);
WARNING: PID 47440526968576 is not a gaussdb server thread
pg_terminate_backend
----------------------
f
(1 row)
postgres=# 查杀会话举例:
--先查会话的pid
postgres=# select datid,pid,state,query from pg_stat_activity where query like '%pw_version%';
datid | pid | state | query
-------+----------------+--------+-------------------------------------------------------------------------------------
20538 | 47922937857792 | active | select datid,pid,state,query from pg_stat_activity where query like '%pw_version%';
20538 | 47922981963520 | idle | select * from pw_version();
(2 rows)
--基于上一步查到的pid杀会话
postgres=# select * from pg_terminate_backend(47922981963520);
pg_terminate_backend
----------------------
t
(1 row)
--再次查询,会话已消失
postgres=# select datid,pid,state,query from pg_stat_activity where query like '%pw_version%';
datid | pid | state | query
-------+----------------+--------+-------------------------------------------------------------------------------------
20538 | 47922937857792 | active | select datid,pid,state,query from pg_stat_activity where query like '%pw_version%';
(1 row)6.sql执行计划
SQL执行计划概述:
SQL执行计划是一个节点树,显示磐维数据库执行一条SQL语句时执行的详细步骤。每一个步骤为一个数据库运算符。
使用EXPLAIN命令可以查看优化器为每个查询生成的具体执行计划。EXPLAIN给每个执行节点都输出一行,显示基本的节点类型和优化器为执行这个节点预计的开销值。具体用法如下:
- EXPLAIN statement:只生成执行计划,不实际执行。其中statement代表SQL语句。
- EXPLAIN ANALYZE statement:生成执行计划,进行执行,并显示执行的概要信息。显示中加入了实际的运行时间统计,包括在每个规划节点内部花掉的总时间(以毫秒计)和它实际返回的行数。
- EXPLAIN PERFORMANCE statement:生成执行计划,进行执行,并显示执行期间的全部信息。
escspdb=# explain select business_id from cert where business_id >100000;
QUERY PLAN
---------------------------------------------------------
Seq Scan on cert (cost=0.00..395.90 rows=620 width=23)
Filter: ((business_id)::bigint > 100000)
(2 行记录)
escspdb=#
escspdb=# EXPLAIN ANALYZE select business_id from cert where business_id ='Test_20230720_009';
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------
[Bypass]
Index Only Scan using cert_pkey on cert (cost=0.00..8.27 rows=1 width=23) (actual time=0.059..0.059 rows=1 loops=1)
Index Cond: (business_id = 'Test_20230720_009'::text)
Heap Fetches: 1
Total runtime: 0.105 ms
(5 行记录)
escspdb=#
escspdb=# EXPLAIN PERFORMANCE select business_id from cert where business_id ='Test_20230720_009';
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
[Bypass]
Index Only Scan using cert_pkey on escsp.cert (cost=0.00..8.27 rows=1 width=23) (actual time=0.026..0.027 rows=1 loops=1)
Output: business_id
Index Cond: (cert.business_id = 'Test_20230720_009'::text)
Heap Fetches: 1
(Buffers: shared hit=3)
(CPU: ex c/r=43646396419570728, ex row=1, ex cyc=43646396419570728, inc cyc=43646396419570728)
Total runtime: 0.110 ms
(8 行记录)
escspdb=# 7.数据库日志收集
gs_collector --begin-time="BEGINTIME" --end-time="ENDTIME" [-h HOSTNAME |
-f HOSTFILE] [--keyword=KEYWORD] [--speed-limit=SPEED] [-o OUTPUT] [-l LO
GFILE] [-C CONFIGFILE]
示例:gs_collector --begin-time="20240707 14:00" --end-time="20240707 19:00"
说明:不加-h参数时,收集的是集群中所有节点的信息
[omm@pw01 data]$ gs_collector --begin-time="20240707 14:00" --end-time="20240707 19:00"
Successfully parsed the configuration file.
create Dir.
Successfully create dir.
do system check interval 0 : count 1
Collecting OS information.
The cmd is source /home/omm/.bashrc; python3 '/database/panweidb/tool/script/local/LocalCollect.py' -t system_check -U omm -l /database/panweidb/log/omm/om/gs_local.log -C '{#TypeName#: #System#, #Content#: #ps,ioStat,netFlow,spaceUsage,cpuInfo,memInfo,disk,#, #Interval#: #0#, #Count#: #1#}'
Failed to collect OS information.
do database check interval 0 : count 1
Collecting catalog statistics.
Successfully collected catalog statistics.
do log check interval 0 : count 1
Collecting Log files.
Successfully collected Log files.
do Config check 0:1
Collecting Config files.
Successfully collected Config files.
Collecting files.
Successfully collected files.
All results are stored in /database/panweidb/log/omm/collector_20240707_190115.tar.gz.
[omm@pw01 data]$ 8.创建用户和数据库
需求描述
库名:pwejb
用户名:pwejb
端口:17700
密码:1qlIk8L2aaWW
客户端白名单:192.168.122.231
a.创建用户USER
CREATE USER pwejb IDENTIFIED BY '1qlIk8L2aaWW';
grant all privileges to pwejb;
b. 使用如下命令创建一个新的表空间pwejb_tbs,并将表空间pwejb_tbs授权给用户pwejb
CREATE TABLESPACE pwejb_tbs OWNER pwejb RELATIVE LOCATION 'tablespace/pwejb_tbs1';
c. 使用如下命令创建一个新的数据库pwejb,放在使用pwejb_tbs表空间中,使用UTF8编码,兼容性为B
CREATE DATABASE pwejb WITH TABLESPACE = pwejb_tbs ENCODING='UTF8';
d.使用以下命令为数据库设置默认的模式搜索路径。
ALTER DATABASE pwejb SET search_path TO pa_catalog,public;
grant all privileges on database pwejb to pwejb;
e.使用如下命令修改数据库表空间
ALTER DATABASE pwejb SET TABLESPACE pwejb_tbs;
f.在数据库本地测试数据库连接
gsql -d pwejb -U pwejb -W '1qlIk8L2aaWW' -r
g.添加客户端白名单,允许192.168.122.231远程访问磐维数据库
gs_guc reload -N all -I all -h 'host all all 192.168.122.231/24 sha256'
h.通过客户端连接数据库
gsql -h IP -p 17700 -d pwejb -U pwejb -r9.修改数据库密码有效期
数据库用户的密码都有密码有效期(password_effect_time),当达到密码到期提醒天数
(password_notify_time)时,系统会在用户登录数据库时提示用户修改密码。
postgres=# show password_effect_time;
password_effect_time
----------------------
90
(1 row)
postgres=# show password_notify_time;
password_notify_time
----------------------
7
(1 row)
-- 修改用户密码有效期时间为36500(集群内所有节点执行)
alter system set password_effect_time to 36500;
-- 用户密码有效期查询校验(集群内所有节点查询确认)
select b.usename,a.passwordtime,a.passwordtime+numtodsinterval(to_number((select setting from pg_settings where name='password_effect_time')),'DAY') as passwordexpiredtime from
(select roloid,max(passwordtime) as passwordtime from pg_catalog.pg_auth_history group by roloid) a
right join
(select usename,usesysid from pg_user) b
on a.roloid=b.usesysid;
usename | passwordtime | passwordexpiredtime
---------+-------------------------------+-------------------------------
omm | 2024-07-07 17:03:19.04627+08 | 2124-06-13 17:03:19.04627+08
pwadmin | 2024-07-07 17:03:19.063156+08 | 2124-06-13 17:03:19.063156+08
pwsso | 2024-07-07 17:03:19.079373+08 | 2124-06-13 17:03:19.079373+08
pwaudit | 2024-07-07 17:03:19.095594+08 | 2124-06-13 17:03:19.095594+08
(4 rows)
postgres=#
-- 用户密码有效期查询校验(集群内所有节点查询确认)
show password_effect_time;
10.数据库添加白名单
gs_guc reload -N all -I all -h 'host all all 192.168.122.230/24 sha256'
--以上命令执行完成之后,会在3台主机的pg_hba.conf增加如下内容。
[omm@pw01 data]$ cat /database/panweidb/data/pg_hba.conf|grep 230
host all all 192.168.122.230/24 sha256
[omm@pw01 data]$ 11.查看数据库大小(降序)
select datname,pg_size_pretty(pg_database_size(datname)) as dbsize from pg_database order by 2 desc;
escspdb=# select datname,pg_size_pretty(pg_database_size(datname)) as dbsize from pg_database order by 2 desc;
datname | dbsize
----------------+---------
testzaq | 9015 MB
caoss | 60 MB
template1 | 24 MB
panweidb | 24 MB
template0 | 24 MB
(5 行记录)
escspdb=# 13.查看表大小(降序)
select tableowner,schemaname,tablename,pg_size_pretty(pg_table_size(schemaname||'.'||tablename)) as table_size from pg_tables order by pg_table_size(schemaname||'.'||tablename) desc;
escspdb=# select tableowner,schemaname,tablename,pg_size_pretty(pg_table_size(schemaname||'.'||tablename)) as table_size from pg_tables order by pg_table_size(schemaname||'.'||tablename) desc;
tableowner | schemaname | tablename | table_size
------------+--------------------+-------------------------------+------------
escsp | escsp | operation_info | 448 MB
omm | pg_catalog | pg_attribute | 5552 kB
omm | pg_catalog | pg_rewrite | 3360 kB
escsp | escsp | cert | 2976 kB
omm | pg_catalog | pg_proc | 2520 kB
...14.磐维数据库集群管理组件介绍
磐维数据库作为面向OLTP业务的关系型数据库,在主备集群模式下,如何实现对节点的监控,感知故障,实现自动主备切换,保证集群的高可用,是至关重要的,相信大家也非常感兴趣,下面我们就一起来揭秘磐维数据集群管理组件Cluster Manager。
14.1 集群介绍
Cluster Manager(CM)是磐维数据库集群管理组件,是磐维数据库集群高可用的保障。CM的主要功能有:
-
数据库主备节点状态监控,故障自动主备切换
-
网络通信故障、文件系统故障等故障监控
-
支持集群、节点查询、配置、操作等
此外,还支持自定义资源纳管,如分布式中间件ShardingSphere等。
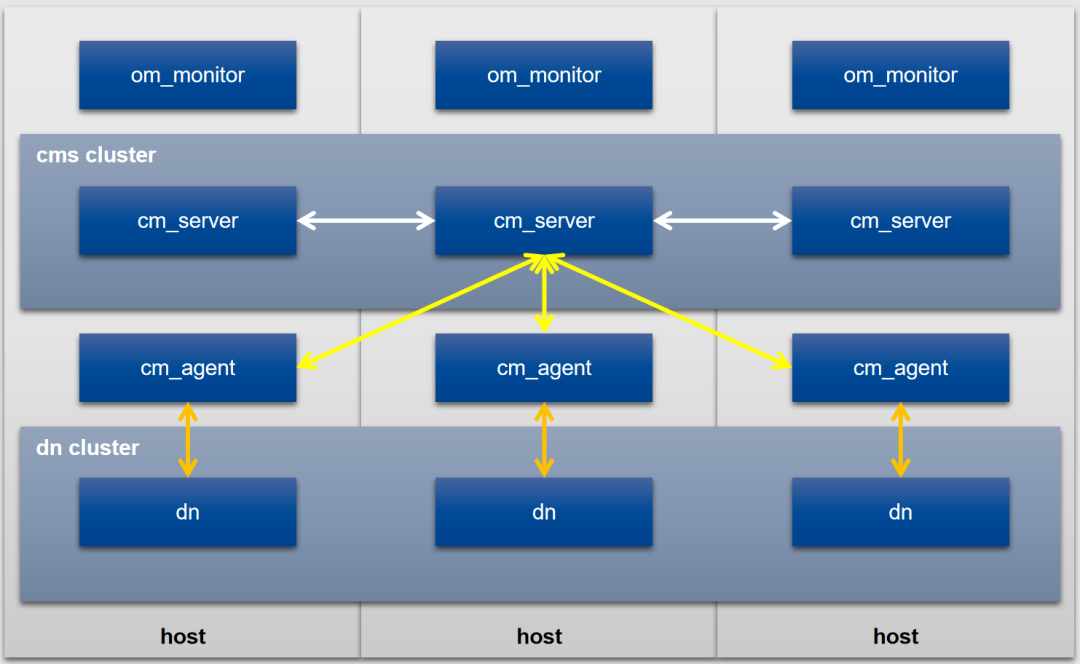
14.1.1 高可用组网
CM组件包含CM Agent(CMA),CM Server(CMS),OM Monitor(CMM)三个核心模块。为保证磐维数据库节点(DN)的高可用,需要满足以下组网条件:
-
每个节点都需要部署CMM、CMA:CMM监控本节点CMA实例;CMA监控本节点的DN、CMS实例,采集信息上报CMS主
-
CMS、DN不需要每个节点都部署
-
CMS、DN实例组成各自的集群
-
CMS集群实个数>=3,基于Quorum协议实现自仲裁,以及DN仲裁,需要保证一半以上实例存活
磐维数据库推荐的高可用部署方案为一主两备,组网如下图所示。除此之外,CM还支持双中心组网方案,并支持优先同中心选主。
14.1.2进程保活机制
CM组件包含cm_server,cm_agent,以及om_monitor三个进程,分别为CMS、CMA,以及CMM模块。磐维数据库(DN)进程为gaussdb。如下图所示:

DN、CMS保活:由CMA来负责
CMA每秒检查一次DN、CMS健康状态。若进程不存在,拉起进程;通过检查DN、CMS进程状态,以及时间阈值内多次查询检测进程是否僵死,并负责杀死僵死进程,重新拉起。
CMA保活:由CMM来负责
CMM每秒检查一次CMA健康状态。若进程不存在,拉起进程;若进程僵死,则杀死僵死进程,重新拉起。
CMM保活:由系统定时任务来兜底
系统定时任务每分钟第0秒执行一次。若进程不存在,下一轮定时任务执行时拉起进程;若进程僵死,则下一轮定时任务执行时杀死僵死进程,再下一轮重新拉起。
![]()
14.2 主要模块及功能
CM组件整体架构,以及模块核心功能如下图所示:

14.2.1 CM Agent
CM Agent在多线程模式下,实现对本地DN、CMS的看护,以及CMS与DN的交互。主要功能如下:
检查保持与CMS主的连接
CMA的ConnCmsPMain线程负责循环检查与CMS主的连接状态,检查的间隔AGENT_RECV_CYCLE为200ms。若连接不存在,则重新建立连接。
检查与所有peer DN的连接
CMA的DNConnectionStatusCheckMain线程负责循环ping所有peer DN节点,检查的间隔由agent_report_interval参数控制,默认为1s。若与所有peer DN节点断连,且本节点为DN主,则上报CMS,并杀死本节点DN,CMS将启动DN仲裁。
检查上报DN的状态
CMA的DNStatusCheckMain线程负责循环检查DN状态,检查的间隔由agent_report_interval参数控制,默认为1s。若进程不存在,则上报CMS,并拉起进程,CMS仲裁模块将启动DN仲裁。
检查上报CMS的状态
CMA同样循环检测本节点CMS状态,每次检查的间隔为1s。若进程不存在,则上报CMS,并拉起进程,CMS HA模块将启动主备自仲裁。若进程出现T状态,则判定为进程僵死,则将僵死情况上报CMS,并杀死进程,重新拉起,CMS HA模块也将启动主备自仲裁。
检测磁盘使用率、磁盘故障
CMA通过在数据、日志路径下创建临时文件,进行读写测试(fopen,fwrite,fread),来检测DN、CMS磁盘故障,若出现失败,则将disc damage状态上报CMS。
检测CPU、MEM、磁盘IO使用率
CMA还负责检测节点cpu、mem,以及所有磁盘io使用是否达阈值。
检测进程僵死
CMA的DNPhonyDeadStatusCheckMain线程负责循环检测DN、CMS进程是否僵死,检测的间隔由agent_phony_dead_check_interval参数控制,默认为10s,其中包含检测时间。
若DN进程出现T、D、Z状态,则判定为进程僵死,将T、Z状态上报CMS,若为T状态,则将检测间隔更新为36s。若非以上状态,则连接数据库,执行查询语句,若执行失败,则判定为进程僵死。当上报次数达到阈值,CMS仲裁模块将启动僵死处理。
向CMS主上报消息
CMA的SendCmsMsgMain线程负责循环将DN、CMS状态上报CMS主,每次上报的间隔为200ms。
处理CMS主下发的命令
CMA同时负责接收并处理CMS下发的命令,根据命令类型,执行对DN的操作。
14.2.2 CM Server
CM Server通过CMA是实现与DN的交互。CMS集群基于Quorum协议,实现对DN集群的仲裁选主,以及自仲裁。核心功能如下:
处理DN节点仲裁
服务线程接收CMA定时上报的DN节点状态,感知DN异常。若为主故障,则启动仲裁,确定候选DN后,启动升主流程。若进程被判定为僵死,则进行僵死处理,若僵死进程为主节点,处理完成后,进入仲裁选主。
处理CMS节点自仲裁
服务线程接收CMA定时上报的CMS节点状态,感知CMS故障,若为主故障,则根据Quorum协议实现CMS集群选主。
处理存储达阈值、磁盘故障
服务线程接收CMA定时上报的DN数据、日志路径磁盘使用情况,循环处理,间隔由datastorage_threshold_check_interval参数控制,默认为10s,每分钟输出检测日志。
当磁盘用量超过只读阈值的80%(只读阈值由datastorage_threshold_value_check控制,默认为85%)时,发送预告警,否则清除预告警。当超过只读阈值时,则向所有DN实例发送只读命令(通过CMA),发送只读告警,否则清除所有DN实例只读命令状态(通过CMA),清除只读告警。
需要注意的是,只读状态为集群级设置,因此集群中任何一个节点磁盘使用达到阈值,集群都会被设置为只读模式,导致写请求返回失败。
15.集群维护
15.1启停数据库集群
--启停整个集群
gs_om -t start
gs_om -t stop
gs_om -t restart
或者
cm_ctl start
cm_ctl stop
[root@pw01 soft]# su - omm
Last login: Sun Jul 7 17:05:04 CST 2024 on pts/0
[omm@pw01 ~]$ cm_ctl stop
cm_ctl: stop cluster.
cm_ctl: stop nodeid: 1
cm_ctl: stop nodeid: 2
cm_ctl: stop nodeid: 3
............
cm_ctl: stop cluster successfully.
[omm@pw01 ~]$
[omm@pw01 ~]$ cm_ctl start
cm_ctl: checking cluster status.
cm_ctl: checking cluster status.
cm_ctl: checking finished in 432 ms.
cm_ctl: start cluster.
cm_ctl: start nodeid: 1
cm_ctl: start nodeid: 2
cm_ctl: start nodeid: 3
................
cm_ctl: start cluster successfully.
[omm@pw01 ~]$ 15.2 查看数据库集群的状态
gs_om -t status --detail
或者
cm_ctl query -Cvid
[omm@pw01 data]$ gs_om -t status --detail
[ CMServer State ]
node node_ip instance state
--------------------------------------------------------------------
1 pw01 192.168.122.142 1 /database/panweidb/cm/cm_server Primary
2 pw02 192.168.122.120 2 /database/panweidb/cm/cm_server Standby
3 pw03 192.168.122.235 3 /database/panweidb/cm/cm_server Standby
[ Cluster State ]
cluster_state : Normal
redistributing : No
balanced : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state
----------------------------------------------------------------------
1 pw01 192.168.122.142 6001 /database/panweidb/data P Standby Normal
2 pw02 192.168.122.120 6002 /database/panweidb/data S Standby Normal
3 pw03 192.168.122.235 6003 /database/panweidb/data S Primary Normal
[omm@pw01 data]$ cm_ctl query -Cvid
[ CMServer State ]
node node_ip instance state
--------------------------------------------------------------------
1 pw01 192.168.122.142 1 /database/panweidb/cm/cm_server Primary
2 pw02 192.168.122.120 2 /database/panweidb/cm/cm_server Standby
3 pw03 192.168.122.235 3 /database/panweidb/cm/cm_server Standby
[ Cluster State ]
cluster_state : Normal
redistributing : No
balanced : No
current_az : AZ_ALL
[ Datanode State ]
node node_ip instance state | node node_ip instance state | node node_ip instance state
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
1 pw01 192.168.122.142 6001 /database/panweidb/data P Standby Normal | 2 pw02 192.168.122.120 6002 /database/panweidb/data S Standby Normal | 3 pw03 192.168.122.235 6003 /database/panweidb/data S Primary Normal
[omm@pw01 data]$ 15.3 启停单节点进程(包括cm和数据库进程)
cm_ctl start -n <nodeid>
cm_ctl stop -n <nodeid>
15.4 启停单节点数据库
gs_ctl start [-D <DATADIR>]
gs_ctl stop [-D <DATADIR>]
gs_ctl restart [-D <DATADIR>]
15.5 查看单节点数据库状态
gs_ctl query [-D <DATADIR>]
[omm@pw01 data]$ gs_ctl query -D /database/panweidb/data
[2024-07-07 18:43:29.792][18929][][gs_ctl]: gs_ctl query ,datadir is /database/panweidb/data
HA state:
local_role : Standby
static_connections : 2
db_state : Normal
detail_information : Normal
Senders info:
No information
Receiver info:
receiver_pid : 2995
local_role : Standby
peer_role : Primary
peer_state : Normal
state : Normal
sender_sent_location : 0/7006F40
sender_write_location : 0/7006F40
sender_flush_location : 0/7006F40
sender_replay_location : 0/7006F40
receiver_received_location : 0/7006F40
receiver_write_location : 0/7006F40
receiver_flush_location : 0/7006F40
receiver_replay_location : 0/7006F40
sync_percent : 100%
channel : 192.168.122.142:42764<--192.168.122.235:17701
[omm@pw01 data]$ 15.6 查看数据库静态配置
gs_om -t view
[omm@pw01 ~]$ gs_om -t view
NodeHeader:
version:301
time:1720342985
nodeCount:3
node:1
============================================================
azName:AZ1
azPriority:1
node :1
nodeName:pw01
ssh channel :
sshChannel 1:192.168.122.142
datanodeCount :1
datanodeInstanceType :primary
datanode 1:
datanodeLocalDataPath :/database/panweidb/data
datanodeXlogPath :
datanodeListenIP 1:192.168.122.142
datanodePort :17700
datanodeLocalHAIP 1:192.168.122.142
datanodeLocalHAPort :17701
dn_replication_num: 3
datanodePeer0DataPath :/database/panweidb/data
datanodePeer0HAIP 1:192.168.122.120
datanodePeer0HAPort :17701
datanodePeer1DataPath :/database/panweidb/data
datanodePeer1HAIP 1:192.168.122.235
datanodePeer1HAPort :17701
============================================================
azName:AZ1
azPriority:1
node :2
nodeName:pw02
ssh channel :
sshChannel 1:192.168.122.120
datanodeCount :1
datanodeInstanceType :standby
datanode 1:
datanodeLocalDataPath :/database/panweidb/data
datanodeXlogPath :
datanodeListenIP 1:192.168.122.120
datanodePort :17700
datanodeLocalHAIP 1:192.168.122.120
datanodeLocalHAPort :17701
dn_replication_num: 3
datanodePeer0DataPath :/database/panweidb/data
datanodePeer0HAIP 1:192.168.122.142
datanodePeer0HAPort :17701
datanodePeer1DataPath :/database/panweidb/data
datanodePeer1HAIP 1:192.168.122.235
datanodePeer1HAPort :17701
============================================================
azName:AZ1
azPriority:1
node :3
nodeName:pw03
ssh channel :
sshChannel 1:192.168.122.235
datanodeCount :1
datanodeInstanceType :standby
datanode 1:
datanodeLocalDataPath :/database/panweidb/data
datanodeXlogPath :
datanodeListenIP 1:192.168.122.235
datanodePort :17700
datanodeLocalHAIP 1:192.168.122.235
datanodeLocalHAPort :17701
dn_replication_num: 3
datanodePeer0DataPath :/database/panweidb/data
datanodePeer0HAIP 1:192.168.122.142
datanodePeer0HAPort :17701
datanodePeer1DataPath :/database/panweidb/data
datanodePeer1HAIP 1:192.168.122.120
datanodePeer1HAPort :17701
============================================================
[omm@pw01 ~]$ 15.7 数据库主备切换(主备机均正常时)
主备机均正常的状态下,主备机之间可以通过switchover命令进行角色切换,
cm_ctl switchover -n <nodeid> -D <datadir>
示例:cm_ctl switchover -n 2 -D /data/panweidb/data
--从节点上执行,执行后,从节点变成主节点
gs_ctl switchover -D /opt/huawei/install/data/dn
注意:执行switchover或failover后,需要执行gs_om -t refreshconf 命令记录当前主备机信息。
15.8 数据库主备切换(主机故障时)
主机故障后可以通过failover命令对备机进行升主。
gs_ctl failover [-D DATADIR]
15.9 重建备库
gs_ctl build -b auto -D <datadir>
15.10 数据库节点扩缩容
详情可以参考文档:数据库节点扩缩容
gs_expansion -U omm -G dbgrp -h 192.168.100.14 -X ./clusterconfig.xml
gs_dropnode -U omm -G dbgrp -h 192.168.100.1416.慢sql录制开启和关闭
16.1 慢SQL开启
问题现象:业务适配或者上线前期,性能压测,优化,如何记录业务慢sql。
解决方法:开启数据库慢sql录制开关。
gs_guc reload -Z coordinator -N all -I all -c "log_min_duration_statement =3000" #---- 慢sql录制
gs_guc reload -Z coordinator -N all -I all -c "enable_stmt_track=on"
gs_guc reload -Z coordinator -N all -I all -c "track_stmt_stat_level = 'OFF,L1'" #---- 慢sql执行计划录制
gs_guc reload -Z coordinator -N all -I all -c "track_stmt_details_size = 40960"
gs_guc reload -Z coordinator -N all -I all -c "instr_unique_sql_count = 200000"
gs_guc reload -Z coordinator -N all -I all -c "track_stmt_parameter = 'on'"
开启后:在数据库中查看 select * from dbe_perf.statement_history ; --- 必须在postgres库中,使用超级用户查看。
16.2 慢SQL参数说明
参数详解:
log_min_duration_statement :记录日志的时间
参数说明:当某条语句的持续时间大于或者等于特定的毫秒数时,log_min_duration_statement参数用于控制记录每条完成语句的持续时间。
设置log_min_duration_statement可以很方便地跟踪需要优化的查询语句。对于使用扩展查询协议的客户端,语法分析、绑定、执行每一步所花时间被独立记录。
该参数属于SUSET类型参数,请参考表1中对应设置方法进行设置。
enable_stmt_track:
参数说明:控制是否启用Full /Slow SQL特性。
在x86平台集中式部署下,硬件配置规格为32核CPU/256GB内存,使用Benchmark SQL 5.0工具测试性能,开关此参数性能影响约1.2%。
track_stmt_stat_level :
参数说明:控制语句执行跟踪的级别。
该参数属于USERSET类型参数,请参考表1中对应设置方法进行设置,不区分英文字母大小写。
取值范围:字符型
该参数分为两部分,形式为'full sql stat level, slow sql stat level'
第一部分为全量SQL跟踪级别,取值范围为OFF、L0、L1、L2
第二部分为慢SQL的跟踪级别,取值范围为OFF、L0、L1、L2
track_stmt_details_size :
参数说明:设置单语句可以收集的最大的执行事件的大小(byte)。
该参数属于USERSET类型参数,请参考表1中对应设置方法进行设置。
取值范围:整型,0 ~ 100000000
instr_unique_sql_count :
参数说明:控制系统中unique sql信息实时收集功能。配置为0表示不启用unique sql信息收集功能。
该值由大变小将会清空系统中原有的数据重新统计(备机不支持此能力);从小变大不受影响。
当系统中产生的unique sql条目数量大于instr_unique_sql_count时,若开启了unique sql自动淘汰,则系统会按unique sql的更新时间由远到近自动淘汰一定比例的条目,使得新产生的unique sql信息可以继续被统计。若没有开启自动淘汰,则系统产生的新的unique sql信息将不再被统计。
在x86平台集中式部署下,硬件配置规格为32核CPU/256GB内存,使用Benchmark SQL 5.0工具测试性能,开关此参数性能影响约3%。
track_stmt_parameter:
参数说明:开启track_stmt_parameter后,在statement_history中记录的执行语句不再进行归一化操作,可以显示完整SQL语句信息,辅助DBA进行问题定位。其中对于简单查询,显示完整语句信息;对于PBE语句,显示完整语句信息的同时,追加每个变量数值信息,格式为“query string;parameters:$1=value1,$2=value2,...”。
该参数属于SIGHUP类型参数,请参考表1中对应设置方法进行设置。
16.3 慢SQL解除
问题来了,开启录制sql后,慢sql会逐渐累积,如何清理避免日志过大,影响数据库性能?
方法:
gs_guc reload -Z coordinator -N all -I all -c "track_stmt_retention_time= '3600,604800'" #---- 慢sql清理参数
通过此函数监控查看 statement_history 表大小,当表的增长非常大时,就需要调整track_stmt_retention_time参数,使清理频率加快。
select * from pg_catalog.pg_size_pretty(pg_catalog.pg_table_size('statement_history'));
track_stmt_retention_time
参数说明:组合参数,控制全量/慢SQL记录的保留时间。以60秒为周期读取该参数,并执行清理超过保留时间的记录,仅sysadmin用户可以访问。
该参数属于SIGHUP类型参数,请参考表1中对应设置方法进行设置。
取值范围:字符型
该参数分为两部分,形式为'full sql retention time, slow sql retention time'
full sql retention time为全量SQL保留时间,取值范围为0 ~ 86400
slow sql retention time为慢SQL的保留时间,取值范围为0 ~ 604800
默认值:3600,604800
16.4 慢sql录制开启-执行计划
生产环境中,经常出现某些sql运行特别慢,dba获取到慢sql,单独执行非常的快,无法判断是资源异常导致,还是执行计划与手动执行不一样。
PanweiDB 数据库提供慢sql执行计划录制功能,协助dba 定位问题。
方法:
gs_guc reload -Z coordinator -N all -I all -c "track_stmt_stat_level = 'OFF,L1'" #---- 慢sql执行计划录制
track_stmt_stat_level :
参数说明:控制语句执行跟踪的级别。
该参数属于USERSET类型参数,请参考表1中对应设置方法进行设置,不区分英文字母大小写。
取值范围:字符型
该参数分为两部分,形式为'full sql stat level, slow sql stat level'
第一部分为全量SQL跟踪级别,取值范围为OFF、L0、L1、L2
第二部分为慢SQL的跟踪级别,取值范围为OFF、L0、L1、L2。
慢sql可通过此视图进行查询:在数据库中查看 select * from dbe_perf.statement_history ; --- 必须在postgres库中,使用超级用户查看。