前言:
在前面我们学习了Liunx的基本指令和权限相关知识,还有基本工具的使用,有了以上的基础知识我们本章将正式接触Linux操作系统。
目录
- 1.冯诺依曼体系结构
- 1.1 内存存在的意义
- 1.2 程序加载到内存的含义
- 1.3 程序的预加载:
- 2 .认识进程
- 2 .1 如何理解管理
- 2 .2 什么叫是进程:(初步理解)
- 2 .2.1 PCB
- 2.3 简单认识操作系统
- 2.3 .1 操作系统如何提供服务
- 2.4 查看进程
- 2. 4 .1 第一种查看进程的方式:
- 2. 4 .2 第二种查看进程的方式:
- 2.5 对进程的当前工作路径的理解
- 3 .进程的系统调用
- 3 .1 父进程与子进程
- 3 .2 fork函数创建子进程
- 3 .2 .1 **fork函数的返回值:**
- 3 .2 .2 fork函数两个返回值的原因:
- 4 .进程的状态
- 4 .1 运行状态(R)
- 4 .2 死亡状态(X dead)
- 4 .3 阻塞状态(s)
- 4 .4 深度睡眠状态(D)
- 4 .5 僵尸状态(Z)
- 4 .5.1 模拟僵尸进程
- 4 .5.2 长时间僵尸的危害
- 4 .6 暂停状态(T/t)
- 5 .进程状态的整体总结
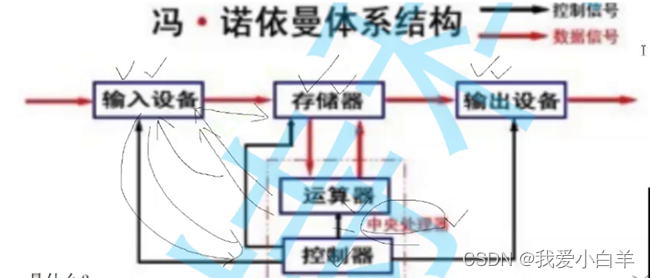
1.冯诺依曼体系结构
我们常见的计算机,如笔记本。我们不常见的计算机,如服务器,大部分都遵守冯诺依曼体系。
-
这里的存储器: 就是内存,不是磁盘!
-
CPU(运算器+控制器)
-
运算器:算术运算,逻辑运算
-
控制器:CPU是可以响应外部事件。比如:拷贝数据到内存
-
输入设备: 键盘,话筒,摄像头,磁盘,网卡……
-
输出设备: 显示器,音响,磁盘,网卡,显卡……
补充内容:
- CPU读取数据(数据+代码),都是要从内存中读取,站在数据的角度,我们认为CPU不和外设直接交互。
- CPU要处理数据,需要先将外设中的数据,加载到内存,站在数据的角度,外设直接只和内存打交道。
程序要运行,必须先被加载到内存中
1.1 内存存在的意义
为什么要有内存?
a. 技术角度:
存储速度的差别: 寄存器的存取速度 > cpu的运算速度 > L1 ~ L3Cache(各种缓存Cache) > 内存 >> 外设(磁盘) >> 光盘磁带
b. 数据角度:
外设不和CPU直接交互,而是和内存交互,CPU也是如此
c. 成本角度:
造价: 寄存器 >> 内存 >> 磁盘(外设)
如果冯诺依曼体系结构中没有内存的话:
-
那么整个体系的效率是很低下,因为是由最慢的设备决定的。
-
计算CPU速度够快,但是还是要等外设,这既是著名的木桶原理。
-
内存的意义:
有存储器的存在,让软件的存在具有了更大的意义,开机的时候,就是将操作系统加载到存储器当中。
内存对应的最大意义:使用较低的钱的成本,能够获得较高的性能。
- 补充:
- 中央处理器CPU也会和外设有交互,协调数据流向。
- 中央处理器CPU只是个具有运算和控制能力的体现木偶,真正让中央处理器去完成计算和某些控制的是整个计算机的大脑,叫做软件,最具有代表性的就是操作系统,是操作系统来控制CPU的。
1.2 程序加载到内存的含义
- 在我们之前学习编程语言例如:C/C++时,我们都听过这样一句话:编译好之后的软件/程序,要运行,必须先加载到内存
- 为什么呢?
答案就是由体系结构(冯·诺依曼体系结构)决定的
具体解释:
C/C+编译好的程序就必须从磁盘加载到内存要让CPU能够读取。
我们编译好的程序是个文件是在磁盘上(外设),CPU读取数据(数据+代码),都是要从内存中读取,所以也就要求要运行程序,就必须将程序先加载到内存,因为CPU只会从内存当中读取指令代码和数据。
1.3 程序的预加载:
- 几乎所有的硬件,只能被动的完成某种功能,不能主动的完成某种功能,一般都是要配合软件完成的。
- 开机等待的本质,就是将操作系统加载到内存当中,因为体系结构规定,CPU要执行代码,执行的可不仅仅是我们写的代码,还有操作系统的代码,所以必须先把操作系统加载到内存,这就是预加载。
- 操作系统一旦被加载之后,在软件层面上,就可以预先把将来要访问的数据或文件,可以提前加载到内存中。
数据在流动的时候------》输入到内存---------》从内存到CPU--------》CPU计算处理完---------------》将结果写回内存,然后定期再刷新到外设。
补充:
内存的存在可以去适配外设和CPU之间速度不匹配的问题,因为内存的存在可以去预先装载一些常见的内存管理软件,数据管理软件。
2 .认识进程
2 .1 如何理解管理
- 管理的本质是:对数据的管理
管理的本质:不是对被管理对象进行直接管理,而是只要拿到被管理对象的所有的相关数据,我们对数据的管理,就可以体现对对象的管理。 - 管理的核心理念:先描述,再组织
用C语言或C++描述,用数组结构组织数据。管理的本质是对数据做管理—对某种数据结构的管理--------》对数据结构的各种操作,增删查改。
重点:操作系统是一款软件,是一款专门搞管理的软件,软件可以管理软件,就像人可以管理人一样
2 .2 什么叫是进程:(初步理解)
- 进程是一个运行起来的程序。
- 程序是个文件,是存在磁盘上的,不能简单的认为,将程序从磁盘加载到内存,这个程序就是进程。
- 操作系统里面,可能同时存在大量的进程
- 对进程的管理,是先描述,再组织
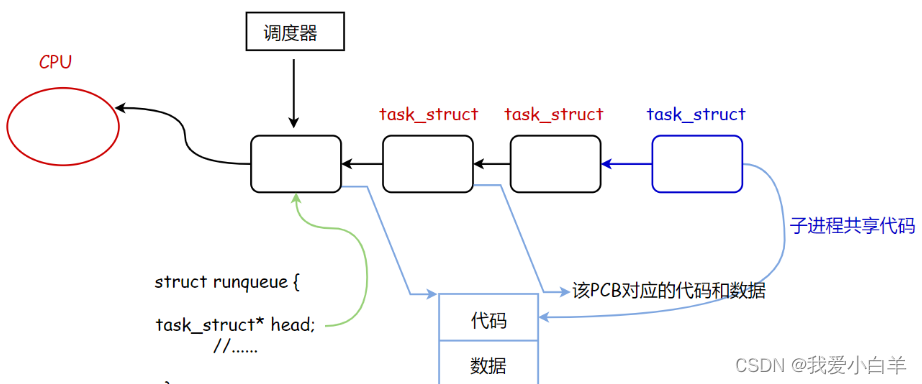
进程=对应的代码和数据 +进程对应的PCB结构体。
2 .2.1 PCB
- 描述起来,用struct结构体
- 组织起来,用链表或其他高效的数据结构
- 而Linux中的task_struct是一款具体的PCB
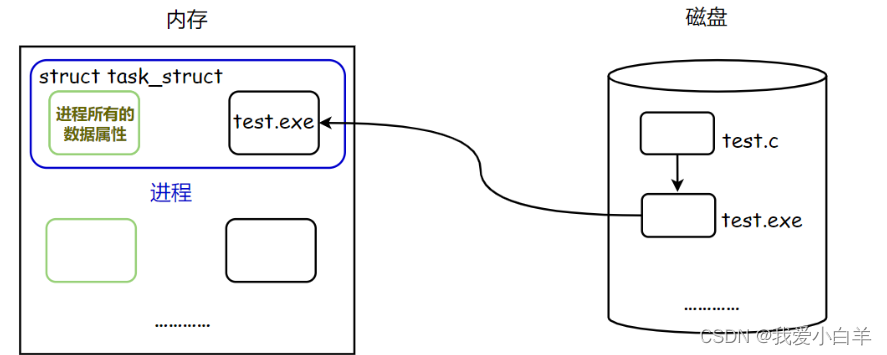
有大量的进程就必须把进程先描述再组织起来,把进程组织起来实际上是把描述进程的进程控制块组织起来。
task_ struct内容分类
-
标示符: 描述本进程的唯一标示符,用来区别其他进程。
-
状态: 任务状态,退出代码,退出信号等。
-
优先级: 相对于其他进程的优先级。
-
程序计数器: 程序中即将被执行的下一条指令的地址。
-
内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。(mm_struct–> 虚拟地址空间)
-
上下文数据: 进程执行时处理器的寄存器中的数据[休学例子,要加图CPU,寄存器]。
-
I/O状态信息:包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。(文件信息)
-
记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。
-
其他信息
那我们学习进程到底学的是什么呢?
- 我们学习的是进程控制块里面有什么属性!
第一阶段对进程的理解总结:
- 当一个程序从磁盘加载到内存,将代码和数据加载到内存只是第一步,第二步,操作系统为了管理这个进程,需要为该进程创建对应的描述该进程的进程控制块PCB,Liunx下叫task struct。
- 只要在内存当中被操作系统管理,操作系统实际管的根本不是代码和数据,而是管的则是进程的PCB结构体。
- 第一阶段进程的理解:程序加载到内存之后的代码和数据,以及操作系统为了管理进程,所生成的描述进程的进程控制块PCB结构体(内核数据结构 +代码和数据,这二者合起来,叫做进程)。
- 一个进程有一个PCB描述起来了,系统中有大量的PCB,只需要将系统中的PCB用数据结构组织起来,对应的对进程的管理就变成了对数据结构的增删查改。
2.3 简单认识操作系统
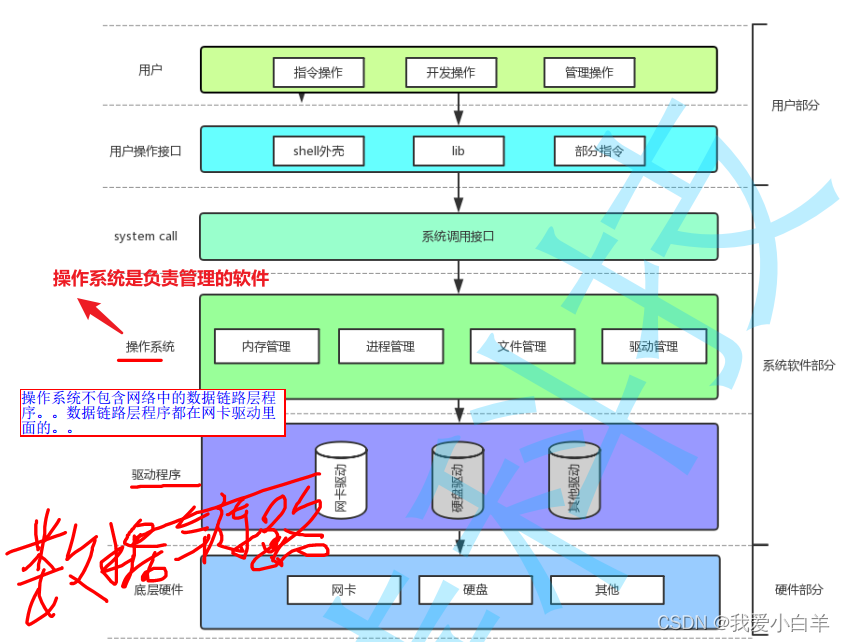
2.3 .1 操作系统如何提供服务
计算机和OS设计出来就是为了给人们服务的,那么是如何给我们提供服务的呢?
- 所有的应用程序都没有资格直接访问硬件,因为硬件的管理者是操作系统
- 操作系统是不相信任何人的!不会直接暴露自己的任何数据结构,代码逻辑,其他数据相关的细节!
- 操作系统是通过给用户提供接口的方式为用户提供服务的~
- Linux操作系统是用C语言写的,这里所谓的“接口”,本质就是C函数
- 学习系统编程本质就是在学习这里的系统接口。
补充:
一门语言跨平台可移植,在Windows和Linux下都能选择其对应的接口,上层提供的都是printf(),原因标准库中用了多态,同个接口在不同的平台下实现同一个或者不同的功能
2.4 查看进程
- 我们自己写的代码,编译成为可执行程序,启动之后就是一个进程。
- 别人写的程序,启动之后也是进程。
2. 4 .1 第一种查看进程的方式:
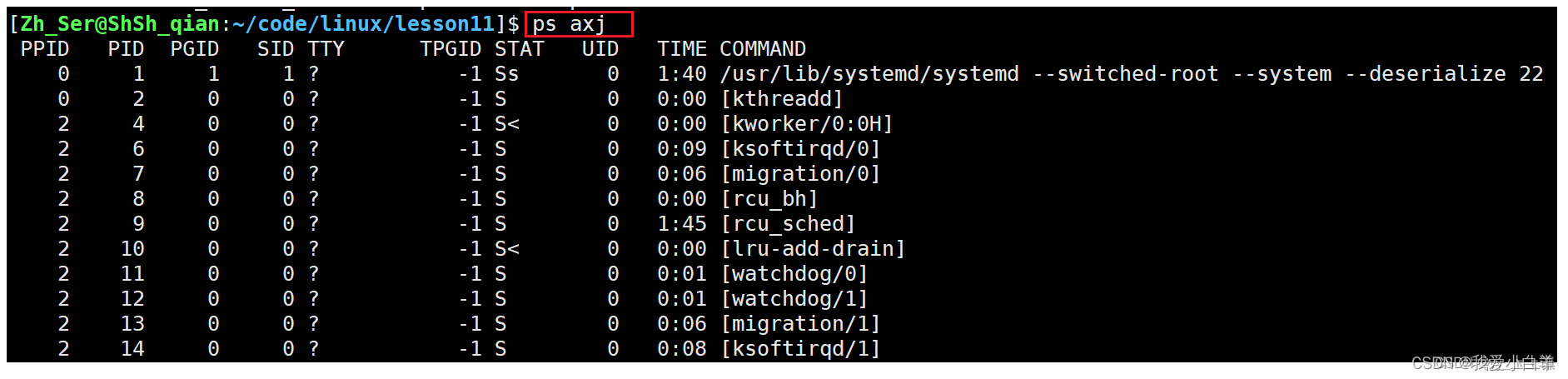
a:all
j:jobs
x:以特定格式显示
显示出前五行:

Windows下是通过双击打开一个进程, 而Linux则是通过./启动,在系统中找到可执行程序启动。
2. 4 .2 第二种查看进程的方式:
Linux的根目录下有个 proc目录里面放的就是实时的进程:

proc:内存文件系统,里面放的是当前系统实时的进程信息。
- 要想获得PID为26746的进程信息,你需要查看 /proc/26746这个文件夹。
- 在proc中打开这个进程,可以查看它的详细属性

2.5 对进程的当前工作路径的理解
我们之前学习C / C++语言的时候,我们就只是肤浅的理解,当前工作路径就是源文件或程序所在的路径。
事实上,并不是。
- 我们使用ls -al选项来在 proc目录中对应的进程中看一下它的更详细的属性:

- 当前路径并不是源文件所在的路径,而是运行进程时所处的路径。
- 换句话说,就是Bin运行时所处的路径。
3 .进程的系统调用
3 .1 父进程与子进程
- 父进程:指已创建一个或多个子进程的进程。常使用**Fork()**来创建多个子进程。
- 通过getpid函数来获取当前进程的ID,也可以通过getppid来获取父进程的ID
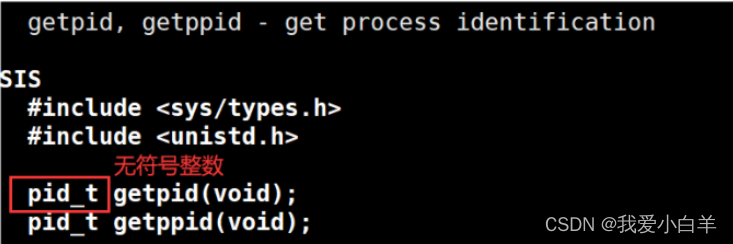
代码演示:
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main()
{
while(1)
{
printf("I am a process! pid: %d ppid: %d\n",getpid(), getppid());
sleep(1);
}
return 0;
}
- 每次执行一个可执行程序之后,进程的ID都会改变,上图也验证了这一点,但是我们惊奇的发现,为啥父进程的ID始终都是一个值,一直都是不变的呢?

几乎我们在命令行上所执行的所有的指令(你的cmd),都是bash进程的子进程
衍生问题:
- bash怎么创建的子进程?
- bash怎么让子进程执行我的程序?
- bash的父进程又是谁?
3 .2 fork函数创建子进程
- fork函数是用来创建子进程的,它有两个返回值。
- 子进程代码共享,数据各自开辟空间,私有一份
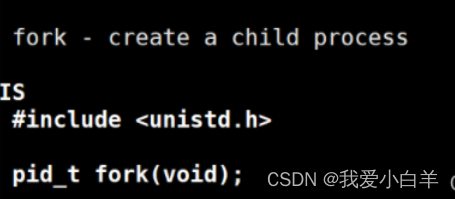
3 .2 .1 fork函数的返回值:

- 成功的话:将子进程的pid返回给父进程,0被返回给子进程。
- 失败的话:-1直接返回给父进程,没有子进程没创建。
代码演示:
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
printf("Hello World! id = %d\n", id);
return 0;
}
- 一条打印语句竟然有两个打印结果,因为Fork之后产生新的进程。
fork 之后通常要用 if 进行分流
#include <stdio.h>
#include <sys/types.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
//id == 0 : 子进程 , id > 0 : 父进程
if(id == 0)
{
while(1)
{
printf("我是子进程,我的pid:%d,我的父进程是:%d\n", getpid(), getppid());
sleep(1);
}
}
else
{
while(1)
{
printf("我是父进程,我的pid:%d,我的父进程是:%d\n", getpid(), getppid());
sleep(1);
}
}
return 0;
}
3 .2 .2 fork函数两个返回值的原因:
如何解释呢?fork如何做到会有不同的返回值?
答:fork之后,OS做了什么?是不是系统多了一个进程
父进程是:task_struct + 数据和代码
子进程也是:task_struct + 子进程的数据和代码
- 子进程的task_ stuct对象内部的数据基本是从父进程继承下来的。
- 子进程和父进程共享代码,fork之后,父子进程执行同样的代码。
- 父进程return一次,子进程return一次,不就是两次返回吗
- Fork之后,父进程和子进程返回值不同,可以通过不同的返回值,判断让父子执行不同的代码块
补充:
- 进程是由task_struct 和 对应的数据和代码组成。
- 那么我们平时用的指令的执行后,它的进程对应的代码在哪呢?
以ls为例: ls变成进程之后,该进程的代码就是从磁盘/usr/bin/ls路径下读取数据代码。
- 父子进程被创建出来,哪一个进程先运行呢??
不一定!! 谁先运行,不一定,这个是由操作系统的调度器决定的!!
操作系统和CPU运行某一个进程,本质从task_struct 形成的队列中挑选一个task_struct,来执行它的代码。
4 .进程的状态
操作系统就像是计算机里的哲学一样,因为操作系统这门学科讲的范围很宽泛,它的理论内容适用于各个操作系统,而我们要具体的学习某一款操作系统,那就是Linux。
凡是说进程,就必须先想到进程的task_ struct。
- 进程状态本质上是个uint8 整数,整数在进程的task struct中。
- task_ struct中会包含进程的相关的信息。

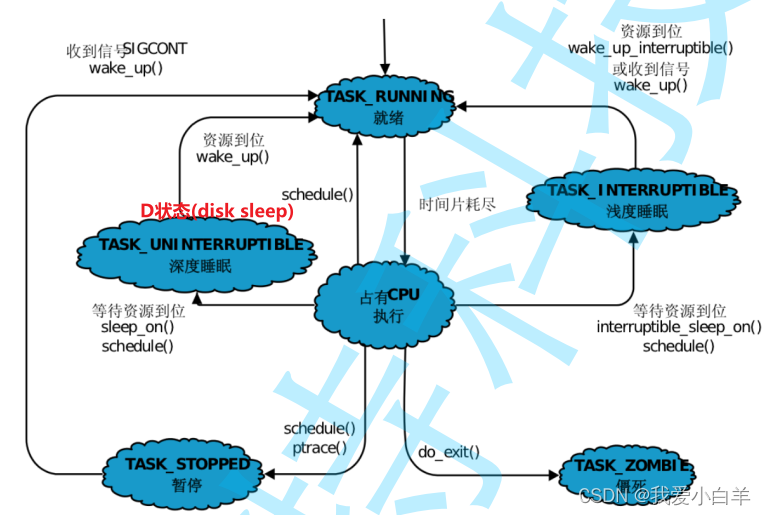
4 .1 运行状态(R)
- 运行状态 是进程在CPU上运行,就叫运行态吗?
答:不是的,操作系统当中每个CPU,都会创建一个runqueue,所以一个进程想被调动,说白了就是将自己的进程放到运行队列当中。
进程只要在运行队列中叫做运行态,不代表正在运行,代表我已经准备好了,随时可以调度!
4 .2 死亡状态(X dead)
死亡状态又叫做终止状态:这个状态只是一个返回状态,你不会在任务列表里看到这个状态。
- 进程终止状态:进程已完成执行,
- 终止就是最终资源释放,但是PCB控制块至少还在,要让操作系统来释放
- X状态,瞬时性非常强。
4 .3 阻塞状态(s)
- 进程运行可能需要申请更多的资源:磁盘,网卡,显示器资源,声卡/音响等
-我们申请资源时,如果该资源暂时没有准备好,当前进程要从runqueue中移除。
重点: - 当我们的进程此时在等待外部资源的时候,该进程的代码,不会被执!!
- 我的进程卡住了 — 进程阻塞!上层看来就是某些任务卡住了。
补充知识点:
- CPU运行的速度非常快,但是运行队列的周转周期非常短,看起来所有进程都在运行。
- 单核CPU在任意时间点都只能运行一个进程。

疑问:为什么我们一直向显示器打印,但却是S状态?
- 因为CPU足够快,外设又很慢,CPU速度的速度是远大于外设的
所以大部分时间都是S状态,都是睡眠阻塞状态
虽然一直在刷屏,但是还是S状态,原因也是在printf上,不断地往显示器上打印,但是显示器是个外设速度非常慢,即便是闲着准备好被刷新也需要花费时间。这个进程90%的情况都是在等,在等显示器就绪。
只有光是一个死循环,不调用外设的时候才是一直处于R状态。
4 .4 深度睡眠状态(D)
- D状态,可以理解为磁盘休眠状态(Disk sleep)有时候也叫不可中断睡眠状
- 在这个状态的进程通常会等待IO的结束
- 是Linux中特有的状态。
假设场景:
当一个进程向磁盘写文件的时候,由于要写的文件很大,所以进程要在那里等,如果等的时间太长了的话,操作系统见到一个进程在那里很悠闲直接把它干掉了,那等磁盘将文件写完之后,回头一看,傻眼了,进程不见了,那写入的文件怎么处理呢??如果该文件写入失败了,结果返回的时候发现进程不见了,那么数据就丢了,后果很严重。
尽然进程要等,就是要等一个返回值,就是为了判断文件写成功了没!!
所以这个进程不能随便杀掉,所以操作系统就将该进程设置成了D状态
- 凡是D状态的进程,操作系统无权杀掉该进程,只能等该进程自己醒来。
- D状态的进程操作系统没权利将其杀掉,只能通过关机重启 or 拔掉电源的方式来强制杀掉该进程。
- 如果一个系统当中存在大量的D状态进程,关机都关不掉
- 一般而言,linux中,如果我们等待的是磁盘资源,我们进程阻塞所处的状态就是D
不过这种情况不多见,很难能见到~
补充:
有时候闪退的问题,是服务器压力过大,OS是会终止用户进程的!
4 .5 僵尸状态(Z)
- 一个进程已经退出,但是还不允许被OS释放处于一个被检测的状态----僵尸状态。
- 维持僵尸状态,是为了让该进程被操作系统或父进程回收。
- 当一个linux中的进程退出的时候,一般不会直接进入X(终止)状态,而是进入Z状态。
我们不禁发出疑问,为什么?
- 首先我们知道,子进程被创建出来,一定是要执行任务的
- 当子进程退出的时候,一般需要将进程的执行结果,告知到父进程os.
进程Z,就是为了维护退出信息,可以让父进程或者os读取的。
僵尸进程存在的意义,就是说明这个进程退出的时候,是因为什么原因退出的。
4 .5.1 模拟僵尸进程
如果创建子进程,子进程退出了,父进程不退出,也不等待子进程,子进程退出之后所处的状态就是Z状态。(ps:所谓等待子进程就是回收)
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
//child
int cnt = 5;
while(cnt)
{
printf("我是子进程,我剩下 %d S\n", cnt);
cnt--;
sleep(1);
}
printf("我是子进程,我已经僵尸了,等待被检测\n");
exit(0);
}
else
{
while(1)
{
sleep(1);
}
}
return 0;
}
子进程5秒后退出,父进程一直在跑,也不回收子进程,我们代码没有写回收,所以子进程就是没有回收
4 .5.2 长时间僵尸的危害
- 如果没有人回收子进程的僵尸,该状态会一直维护!该进程的相关资源(task_struct) 不会被释放!一个很严重的问题那就是 — 内存泄漏
- 什么情况会一直僵尸?
父进程不回收它,会一直僵尸状态。
- 一个进程僵尸了,是不可被杀死的。都已经成僵尸了还怎么杀死
1.使用wait()或waitpid():父进程可以调用wait()或waitpid()函数来等待子进程终止,并获取它的终止状态
此方法父进程会被挂起
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
int main() {
pid_t pid = fork();
if (pid == 0) {
// 子进程代码
_exit(0);
} else if (pid > 0) {
// 父进程代码
wait(NULL); // 等待子进程终止
} else {
// fork失败
perror("fork");
}
return 0;
}
2.父进程忽略SIGCHLD信号:如果不想让子进程编程僵尸进程,可在父进程中加入:signal(SIGCHLD,SIG_IGN);
如果将此信号的处理方式设为忽略,可让内核把僵尸子进程转交给init进程去处理
signal(SIGCHLD,SIG_IGN);
3.注册SIGCHLD信号处理函数: 父进程可以通过捕获SIGCHLD信号来处理子进程终止事件,并调用waitpid()来避免僵尸进程的产生
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
#include <signal.h>
#include <stdio.h>
void sigchld_handler(int signum) {
// 使用非阻塞方式调用waitpid(),防止阻塞父进程
while (waitpid(-1, NULL, WNOHANG) > 0);
}
int main() {
struct sigaction sa;
sa.sa_handler = sigchld_handler;
sigemptyset(&sa.sa_mask);
sa.sa_flags = SA_RESTART;
sigaction(SIGCHLD, &sa, NULL);
pid_t pid = fork();
if (pid == 0) {
// 子进程代码
_exit(0);
} else if (pid > 0) {
// 父进程代码
sleep(10); // 模拟父进程的工作
} else {
// fork失败
perror("fork");
}
return 0;
}
4.daemon进程: 将父进程设计成守护(后台)进程(daemon),这样孤儿进程会被init进程(PID 1)领养,而init进程会自动回收孤儿进程,避免僵尸进程的产生。
状态后面有S+的,代表这个进程是个前台进程,能在键盘ctr/ + C的是前台进程; 后台进程ctr/ + C干不掉。
孤儿进程没有那个S+,它是个后台进程。
4 .6 暂停状态(T/t)
- 可以通过发送 SIGSTOP 信号给进程来停止(T)进程。这个被暂停的进程 通过发送SIGCONT 信号让进程继续运行。

- 暂停状态主要用于调试场景中。
5 .进程状态的整体总结
- 系统中一定是存在各种资源的(不仅仅是CPU)网卡,磁盘,显卡都是资源;所以,系统中不只是只存在一种队列
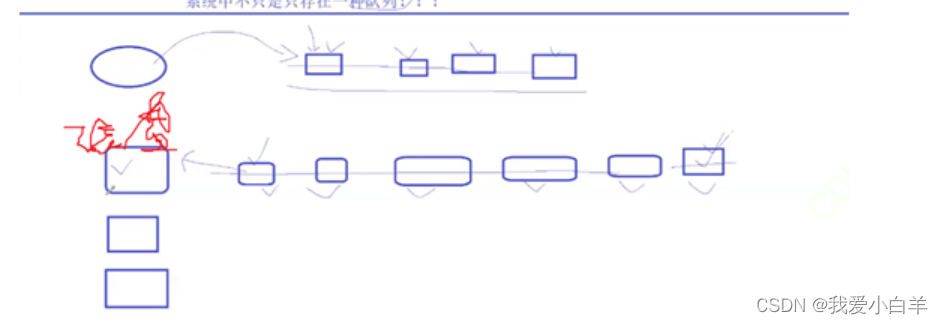
- 理解操作系统中的进程状态:
a.新建
b.运行:task_struct 结构体在运行,队列中排队,就叫做运行态
c.阻塞:等待非CPU资源就绪,阻塞状态
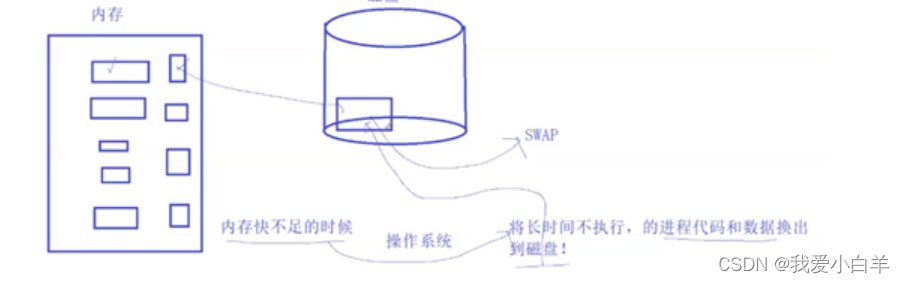
d.挂起:当内存不足的时候,Os通过适当的置换进程的代码和数据到磁盘,进程的状态就叫做挂起!
尾声
看到这里,相信大家对这个C++有了解了。
如果你感觉这篇博客对你有帮助,不要忘了一键三连哦