Spark SQL 基本介绍
1、什么是Spark SQL
Spark SQL是Spark多种组件中其中一个,主要是用于处理大规模的【结构化数据】
什么是结构化数据: 一份数据, 每一行都有固定的列, 每一列的类型都是一致的 我们将这样的数据称为结构化的数据 例如: mysql的表数据 1 张三 20 2 李四 15 3 王五 18 4 赵六 12
为什么要学习Spark SQL呢?
1- 会 SQL的人, 一定比会大数据的人多 2- Spark SQL 既可以编写SQL语句, 也可以编写代码, 甚至可以混合使用 3- Spark SQL 可以 和 HIVE进行集成, 集成后, 可以替换掉HIVE原有MR的执行引擎, 提升效率
Spark SQL特点:
1- 融合性: 既可以使用标准SQL语言, 也可以编写代码, 同时支持混合使用 2- 统一的数据访问: 可以通过统一的API来对接不同的数据源 3- HIVE的兼容性: Spark SQL可以和HIVE进行整合, 整合后替换执行引擎为Spark, 核心: 基于HIVE的metastore来处理 4- 标准化连接: Spark SQL也是支持 JDBC/ODBC的连接方式
2、Spark SQL 与 HIVE异同
相同点:
1- 都是分布式SQL计算引擎 2- 都可以处理大规模的结构化数据 3- 都可以建立Yarn集群之上运行
不同点:
1- Spark SQL是基于内存计算, 而HIVE SQL是基于磁盘进行计算的 2- Spark SQL没有元数据管理服务(自己维护), 而HIVE SQL是有metastore的元数据管理服务的 3- Spark SQL底层执行Spark RDD程序, 而HIVE SQL底层执行是MapReduce 4- Spark SQL可以编写SQL也可以编写代码,但是HIVE SQL仅能编写SQL语句
3、Spark SQL的数据结构对比

说明:
pandas的DataFrame: 二维表 处理单机结构数据
SparkCore的RDD: 处理任何的数据结构 处理大规模的分布式数据
SparkSQL的DataFrame: 二维表 处理大规模的分布式结构数据

RDD(Resilient Distributed Dataset)是Spark中最基本的抽象,代表了一个不可变、分布式的数据集合。RDD支持并行操作,可以在集群中的多个节点上进行处理。RDD具有容错性,即使在节点故障时也能够自动恢复。但是RDD只提供了基本的功能,对于结构化数据的处理能力有限。 DataFrame是Spark SQL中的一个概念,它是一种以列为主的分布式数据集合,类似于关系型数据库中的表格。DataFrame具有数据结构化的特点,每一列都有相应的数据类型,而且可以使用SQL语句进行查询和操作。DataFrame也支持大部分RDD的操作,但是在处理结构化数据方面更加方便。 DataSet是Spark 2.0引入的一种新的API,它是DataFrame的一个扩展,提供了类型安全的数据操作。DataSet在编译时检查数据类型,可以避免一些运行时的错误。与DataFrame相比,DataSet更加适用于需要强类型支持的场景,但是在灵活性和易用性方面可能略逊于DataFrame。 由于Python不支持泛型, 所以无法使用Dataset类型, 客户端仅支持DataFrame类型
Spark SQL的入门案例
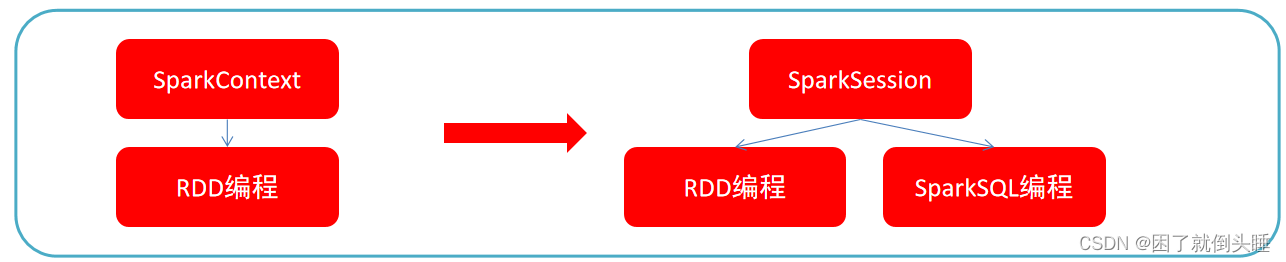
SparkSession 和 SparkContext 是 Apache Spark 中两个重要的组件,它们在 Spark 应用程序中扮演着不同的角色。
SparkContext:
SparkContext 是 Spark 1.x 版本中最重要的入口点,在 Spark 2.x 版本中,它已经被 SparkSession 取代,但在一些旧的代码和文档中仍然可能会看到它的存在。
SparkContext 是 Spark 应用程序与 Spark 集群通信的主要入口点。它负责与集群管理器(如 YARN、Mesos 或 Spark 自带的 Standalone)通信,以便分配资源和执行任务。
SparkContext 提供了创建 RDD(弹性分布式数据集)的功能,RDD 是 Spark 中基本的数据抽象,代表了分布在集群中的不可变的数据集。
SparkSession:
在 Spark 2.x 中,SparkSession 被引入来取代 SparkContext,并提供了更多功能和简化的 API。,它是 Spark 应用程序中的入口点,封装了 SparkContext。
SparkSession 提供了一种统一的入口点,用于读取数据、执行查询、进行数据处理等各种 Spark 任务。
SparkSession 提供了 DataFrame 和 Dataset API,这两种 API 提供了更高级别、更易于使用的抽象,用于处理结构化数据。
与 SparkContext 不同,SparkSession 可以与 Hive 集成,允许在 Spark 应用程序中执行 SQL 查询,并访问 Hive 中的表和数据。
总之,SparkContext 是 Spark 1.x 版本中的主要入口点,负责与集群通信和管理资源,而 SparkSession 是 Spark 2.x 中的主要入口点,提供了更多的功能和简化的 API,用于执行各种 Spark 任务,并且可以与 Hive 集成。还可以通过SparkSession对象还是可以得到SparkContext对象。
入门体验
# 导包
import os
from pyspark.sql import SparkSession
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
# 1.创建SparkContext对象
spark = SparkSession.builder.appName('pyspark_demo').master('local[*]').getOrCreate()
sc = spark.sparkContext
# print(spark,type(spark))
# print(sc,type(sc))
# 2.验证是否能生成rdd
textRDD = sc.textFile('file:///export/data/spark_project/spark_sql/data/uniqlo.csv')
# collect: 搜集数据触发任务展示数据 count:获取数据条数 type:查看类型
# print(textRDD.collect())
print(textRDD.count())
print(type(textRDD)) # <class 'pyspark.rdd.RDD'>
# 验证是否能生成DataFrame
df = spark.read.csv('file:///export/data/spark_project/spark_sql/data/uniqlo.csv')
# show: 展示数据 count:获取数据条数 type:查看类型
# print(df.show())
print(df.count())
print(type(df)) # <class 'pyspark.sql.dataframe.DataFrame'>
# 3.关闭资源
sc.stop()
spark.stop()