目录
树形分类菜单(递归查询,强扩展)
1)需求
2)数据库表设计
3)实现
4)关于 asSequence 优化
性能压测
1)Jmeter 安装使用说明
2)中间件对性能的影响
三级分类数据查询性能优化
需求分析
1)未优化
2)第一次优化(数据库一次查询)
3)第二次优化(SpringCache 整合 Redis)
4)3 种不同实现性能测试
树形分类菜单(递归查询,强扩展)
1)需求
展示如下属性分类菜单

实际上是一个三级分层目录,并且考虑到将来可能会拓展成为 四级、五级... 目录.
2)数据设计
a)表设计如下
CREATE TABLE `pms_category` (
`cat_id` bigint NOT NULL AUTO_INCREMENT COMMENT '分类id',
`name` char(50) DEFAULT NULL COMMENT '分类名称',
`parent_cid` bigint DEFAULT NULL COMMENT '父分类id',
`cat_level` int DEFAULT NULL COMMENT '层级',
`show_status` tinyint DEFAULT NULL COMMENT '是否显示[0-不显示,1显示]',
`sort` int DEFAULT NULL COMMENT '排序',
`icon` char(255) DEFAULT NULL COMMENT '图标地址',
`product_unit` char(50) DEFAULT NULL COMMENT '计量单位',
`product_count` int DEFAULT NULL COMMENT '商品数量',
PRIMARY KEY (`cat_id`),
KEY `parent_cid` (`parent_cid`)
) ENGINE=InnoDB AUTO_INCREMENT=1433 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci COMMENT='商品三级分类';b)vo 设计如下
data class CategoryTreeVo (
val catId: Long,
val name: String,
val parentCid: Long, //父分类 id
val catLevel: Int, //层级
val showStatus: Int, //是否显示 (0不显示 1显示)
val sort: Int,
val icon: String?, //图标地址,
val productUnit: String?, //计量单位
val productCount: Int, //商品数量
var children: List<CategoryTreeVo> //孩子节点
)
3)实现
这里我们可以先将 pms_category 表中所有数据取出来,然后在内存中通过流的方式来操作数据.
具体的流操作,如下:
- filter:过滤出一级菜单分类.
- map:通过递归的方式来查询子菜单分类,包装到 vo 中
- filter:先从所有的数据中过滤出当前菜单的子菜单
- map:递归的方式继续查询子菜单,包装到 vo 中.
- ......
- sortedBy:按照 sort 字段来进行升序排序.
@Service
class CategoryServiceImpl(
private val categoryRepo: CategoryRepo,
): CategoryService {
override fun listWithTree(): List<CategoryTreeVo> {
//1.获取所有分类
val vos = categoryRepo.queryAll().map(::map)
//2.分级
val result = vos.asSequence() //数据量较大,使用 asSequence 有优化
.filter { category -> //1) 找到所有一级分类
category.catLevel == 1
}.map { category -> //2) 递归的去找 children 分类
category.children = getCategoryChildrenDfs(category, vos)
return@map category
}.sortedBy { // 降序 sortedByDescending { it.sort }
it.sort
}.toList()
return result
}
/**
* 递归的去找 children 分类
*/
private fun getCategoryChildrenDfs(
root: CategoryTreeVo,
all: List<CategoryTreeVo>
): List<CategoryTreeVo> {
//递归终止条件: 当 filter 过滤出来的数据为空,就直接返回 空list,不会走下一个 map 逻辑了
val result = all
.filter { category -> //1.从所有分类中找出父节点为当前节点(找到当前节点的所有孩子节点)
category.parentCid == root.catId
}.map { category -> //2.递归的去找孩子
category.children = getCategoryChildrenDfs(category, all)
return@map category
}.sortedBy { category ->
category.sort
}.toList()
return result
}
fun map(obj: Category) = with(obj) {
CategoryTreeVo (
catId = catId,
name = name,
parentCid = parentCid,
catLevel = catLevel,
showStatus = showStatus,
sort = sort,
icon = icon,
productUnit = productUnit,
productCount = productCount,
children = emptyList(),
)
}
}
4)关于 asSequence 优化
这里我也做了一个压测(1min/100用户并发)
没有使用 asSequence 如下:

使用 asSequence 如下:

Ps:asSequence 在处理大数据量时速度更快的原因主要是因为它采用了惰性求值策略,避免了不必要的多次迭代和中间集合的创建(原本的集合操作,每进行例如 filter 就会创建中间集合),从而减少了内存和处理时间的消耗。这种优化在处理大数据集时尤其显著
性能压测
1)Jmeter 安装使用说明
a)安装
Apache JMeter - Download Apache JMeter
解压后点击 \apache-jmeter-5.6.3\bin 目录下的 jmeter.bat 即可.


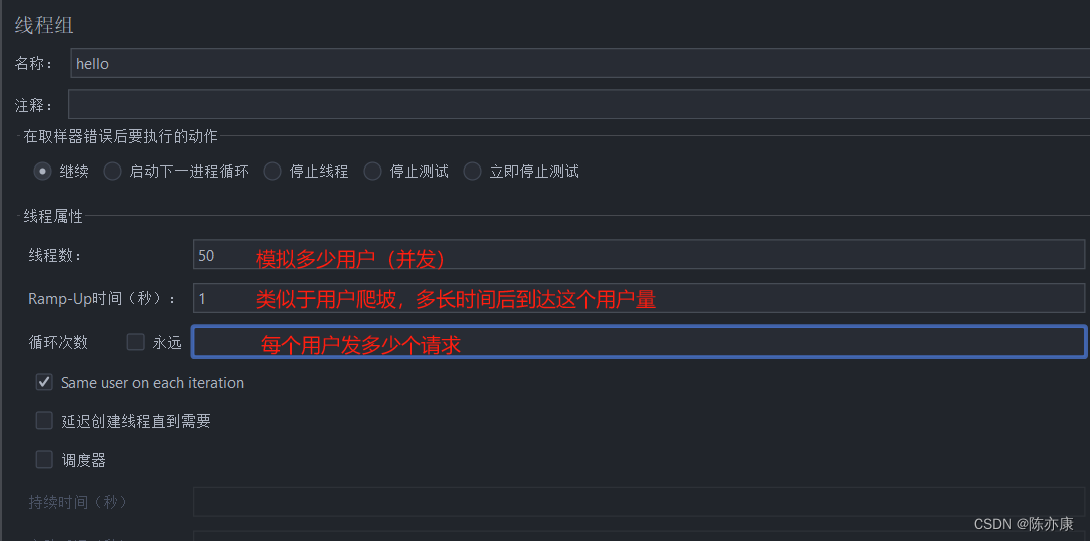
b)参数说明


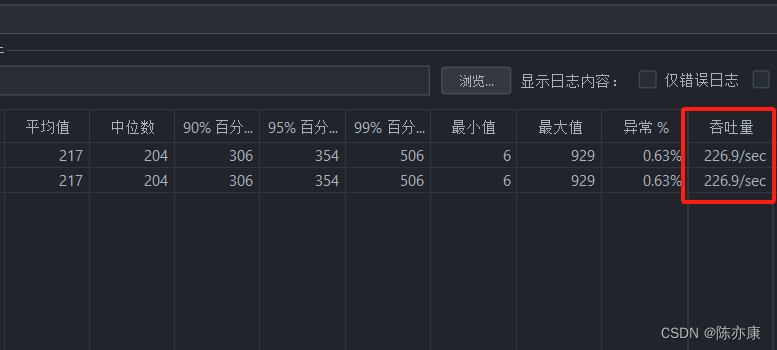
吞吐量:每秒处理的请求个数
一般自己测的时候,主要观察这两个指标即可.
关于吞吐量,这里可以给出一个业界的标准~
-
电商网站
- 小型:几十到几百 RPS (10-500)
- 中型:几百到几千 RPS (500-5,000)
- 大型:几千到数万 RPS (5,000-50,000)
-
社交媒体平台
- 中型:几千到几万 RPS (5,000-50,000)
- 大型:数万到数十万 RPS (50,000-500,000)
-
流媒体服务
- 小型:几百到几千 RPS (500-5,000)
- 大型:数千到数万 RPS (5,000-50,000)
-
在线游戏服务器
- 小型:几十到几百 RPS (10-500)
- 大型:几千到几万 RPS (5,000-50,000)
2)中间件对性能的影响
这里我们对当前系统进行一个性能测试,先来看看中间件(例如 nginx、网关...)对系统的影响.
| 测试内容 | 线程数 | 吞吐量/s |
|---|---|---|
| 网关(直接将请求打到网关端口即可,404 也算正常返回) | 50 | 25262 |
| 简单服务(直接将请求打到对应的微服务即可) | 50 | 39234 |
| 网关 + 简单服务(服务就简单的返回一个 hello 字符串即可) | 50 | 12072 |
- 分析:引入中间件会带来更大的网络开销.
- 起初,只需要客户端和服务之间进行通讯.
- 引入网关后,需要 客户端先和网关通讯,再有网关和服务通讯,最后在原路返回响应.
- 结论:中间件越多,性能损耗越大.
- 优化:考虑跟高效的网络协议、买更好的网卡,增加网络带宽...
三级分类数据查询性能优化
需求分析
a)需要给前端返回的结果是一个 json 结构数据,格式如下:
最外层是一个 Map<String, List<Any>> 的结构. key 就是一级分类id. value 是一个对象数组

这个对象就是 二级分类 的数据

二级分类中又包含该分类下的三级分类列表

对应 data class 如下:
//二级分类数据
data class Catalog2Vo (
val catalog1Id: String, //一级分类 id (父分类 id)
val catalog3List: List<Catalog3Vo>, //三级子分类
val id: String,
val name: String,
)
//三级分类数据
data class Catalog3Vo (
val catalog2Id: String, //二级分类 id (父分类 id)
val id: String,
val name: String,
)
最后给前端返回 Map<String, List<Catalog2Vo>> 数据. key 是一级分类 id
1)未优化
a)实现方式:
最直接的方法就是先从数据库中查到所有一级分类数据,然后再拿着每一个一级分类 id 去查对应的二级分类数据,最后拿着每个二级分类的 id 去查对应的三级分类数据.
override fun getCatalogJson(): Map<String, List<Catalog2Vo>> {
//1.查询所有一级分类
val level1List = categoryRepo.queryLevel1CategoryAll()
//2.封装 二级 -> 三级 分类
val result = level1List.associate { l1 -> l1.catId.toString() to run {
//1) 查到这个一级分类中的所有二级分类
val level2Vos = categoryRepo.queryCategoryByParentId(l1.catId)
.map { l2 ->
//2) 查到这个二级分类中所有三级分类
val leve3Vos = categoryRepo.queryCategoryByParentId(l2.catId)
.map { l3 -> Catalog3Vo(l2.catId.toString(), l3.catId.toString(), l3.name) }
//3) 将 三级分类List 整合到 二级分类List
return@map Catalog2Vo(l1.catId.toString(), leve3Vos, l2.catId.toString(), l2.name)
}
return@run level2Vos
} }
return result
}
b)问题:
查询效率非常低,循环套循环频繁的和数据建立和断开连接,带来很大一部分网络开销.
2)第一次优化(数据库一次查询)
a)实现方式:
为了避免大量数据库连接,可以换一个思路~
一开始就从数据库中拿到 分类表 中的所有数据,然后在内存中操作,过滤出每一个一级分类下的所有二级分类数据.......
override fun getCatalogJson(): Map<String, List<Catalog2Vo>> {
//1.查询所有分类数据
val all = categoryRepo.queryAll()
//2.查询所有一级分类数据
val level1List = getCategoryByParentId(all, 0L)
//2.封装 二级 -> 三级 分类
val result = level1List.associate { l1 -> l1.catId.toString() to run {
//1) 查到这个一级分类中的所有二级分类
val level2Vos = getCategoryByParentId(all, l1.catId)
.map { l2 ->
//2) 查到这个二级分类中所有三级分类
val leve3Vos = getCategoryByParentId(all, l2.catId)
.map { l3 -> Catalog3Vo(l2.catId.toString(), l3.catId.toString(), l3.name) }
//3) 将 三级分类List 整合到 二级分类List
return@map Catalog2Vo(l1.catId.toString(), leve3Vos, l2.catId.toString(), l2.name)
}
return@run level2Vos
} }
return result
}
//从所有数据中过滤出指定 parentId 的数据
private fun getCategoryByParentId(all: List<Category>, parentId: Long): List<Category> {
return all.filter { it.parentCid == parentId }
}
3)第二次优化(SpringCache 整合 Redis)
对于分类数据这种每次在内存中计算很耗时,并且更新频率低的数据就非常适合保存到 Redis 缓存中.
a)实现方式:
直接使用 SpringCache 整合 Redis 对数据进行缓存
@Cacheable(value = ["category"], key = "#root.methodName")
override fun getCatalogJson(): Map<String, List<Catalog2Vo>> {
println("查询了数据库...")
return getCatalogJsonFromDb()
}
//三级分类查询(数据库一次查询)
fun getCatalogJsonFromDb(): Map<String, List<Catalog2Vo>> {
//1.查询所有分类数据
val all = categoryRepo.queryAll()
//2.查询所有一级分类数据
val level1List = getCategoryByParentId(all, 0L)
//2.封装 二级 -> 三级 分类
val result = level1List.associate { l1 -> l1.catId.toString() to run {
//1) 查到这个一级分类中的所有二级分类
val level2Vos = getCategoryByParentId(all, l1.catId)
.map { l2 ->
//2) 查到这个二级分类中所有三级分类
val leve3Vos = getCategoryByParentId(all, l2.catId)
.map { l3 -> Catalog3Vo(l2.catId.toString(), l3.catId.toString(), l3.name) }
//3) 将 三级分类List 整合到 二级分类List
return@map Catalog2Vo(l1.catId.toString(), leve3Vos, l2.catId.toString(), l2.name)
}
return@run level2Vos
} }
return result
}
//从所有数据中过滤出指定 parentId 的数据
private fun getCategoryByParentId(all: List<Category>, parentId: Long): List<Category> {
return all.filter { it.parentCid == parentId }
}
4)3 种不同实现性能测试
50 个线程并发
a)未优化

b)第一次优化 (数据库一次查询)
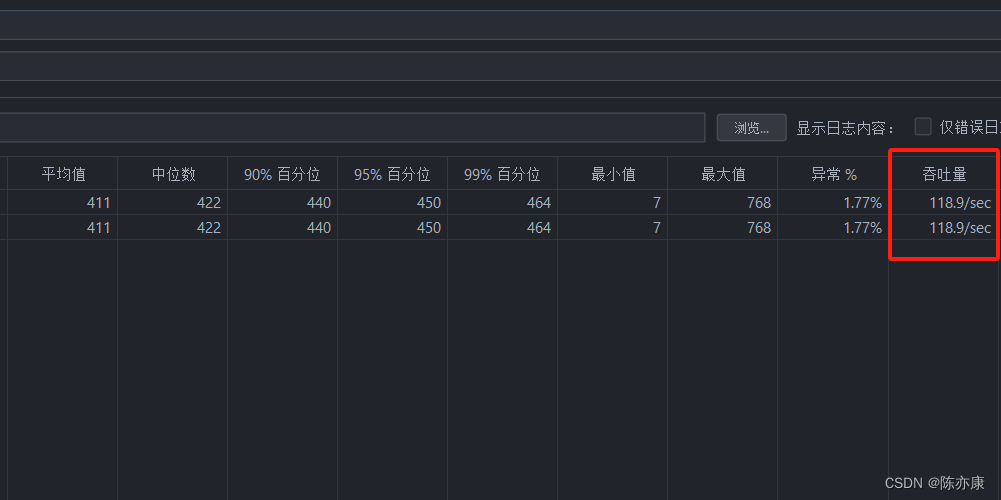
c)第二次优化(SpringCache 整合 Redis)