一、Kafka简介
Kafka是什么
Kafka是一种高吞吐量的分布式发布订阅消息系统(消息引擎系统),它可以处理消费者在网站中的所有动作流数据。 这种动作(网页浏览,
搜索和其他用户的行动)是在现代网络上的许多社会功能的一个关键因素。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来
解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop
的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
其实我们简单点理解就是系统A发送消息给kafka(消息引擎系统),系统B从kafka中读取A发送的消息。而kafka就是个中间商。
1.1 Kafka的特性:
-
高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
-
可扩展性:kafka集群支持热扩展
-
持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
-
容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
-
高并发:支持数千个客户端同时读写
1.2 Kafka的使用场景:
Kafaka经常用于削峰、解耦、异步。
-
日志收集:一个公司可以用Kafka可以收集各种服务的log,通过kafka以统一接口服务的方式开放给各种consumer,例如hadoop、Hbase、Solr等。
-
消息系统:解耦生产者和消费者、缓存消息等。
-
用户活动跟踪:Kafka经常被用来记录web用户或者app用户的各种活动,如浏览网页、搜索、点击等活动,这些活动信息被各个服务器发布到kafka的topic中,然后订阅者通过订阅这些topic来做实时的监控分析,或者装载到hadoop、数据仓库中做离线分析和挖掘。
-
运营指标:Kafka也经常用来记录运营监控数据。包括收集各种分布式应用的数据,生产各种操作的集中反馈,比如报警和报告。
-
流式处理:比如spark streaming和storm
-
事件源
1.3 Kakfa的设计思想
Kakfa Broker Leader的选举:Kakfa Broker集群受Zookeeper管理。所有的Kafka Broker节点一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。(这个过程叫Controller在ZooKeeper注册Watch)。这个Controller会监听其他的Kafka Broker的所有信息,如果这个kafka broker controller宕机了,在zookeeper上面的那个临时节点就会消失,此时所有的kafka broker又会一起去Zookeeper上注册一个临时节点,因为只有一个Kafka Broker会注册成功,其他的都会失败,所以这个成功在Zookeeper上注册临时节点的这个Kafka Broker会成为Kafka Broker Controller,其他的Kafka broker叫Kafka Broker follower。例如:一旦有一个broker宕机了,这个kafka broker controller会读取该宕机broker上所有的partition在zookeeper上的状态,并选取ISR列表中的一个replica作为partition leader(如果ISR列表中的replica全挂,选一个幸存的replica作为leader; 如果该partition的所有的replica都宕机了,则将新的leader设置为-1,等待恢复,等待ISR中的任一个Replica“活”过来,并且选它作为Leader;或选择第一个“活”过来的Replica(不一定是ISR中的)作为Leader),这个broker宕机的事情,kafka controller也会通知zookeeper,zookeeper就会通知其他的kafka broker。
二、Kafka架构
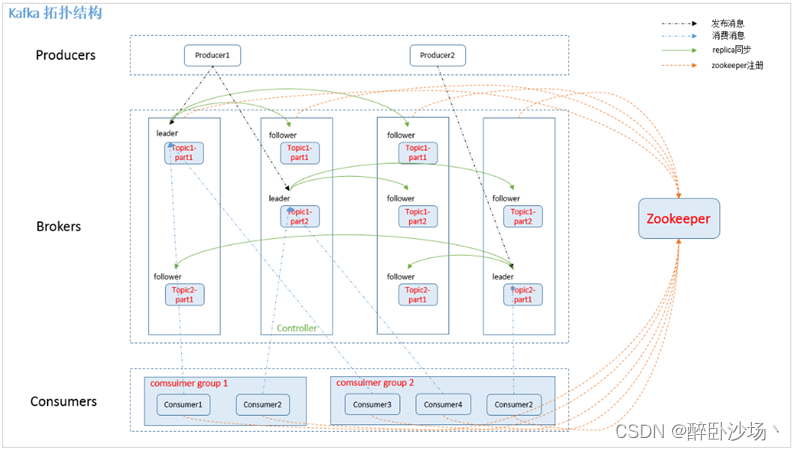
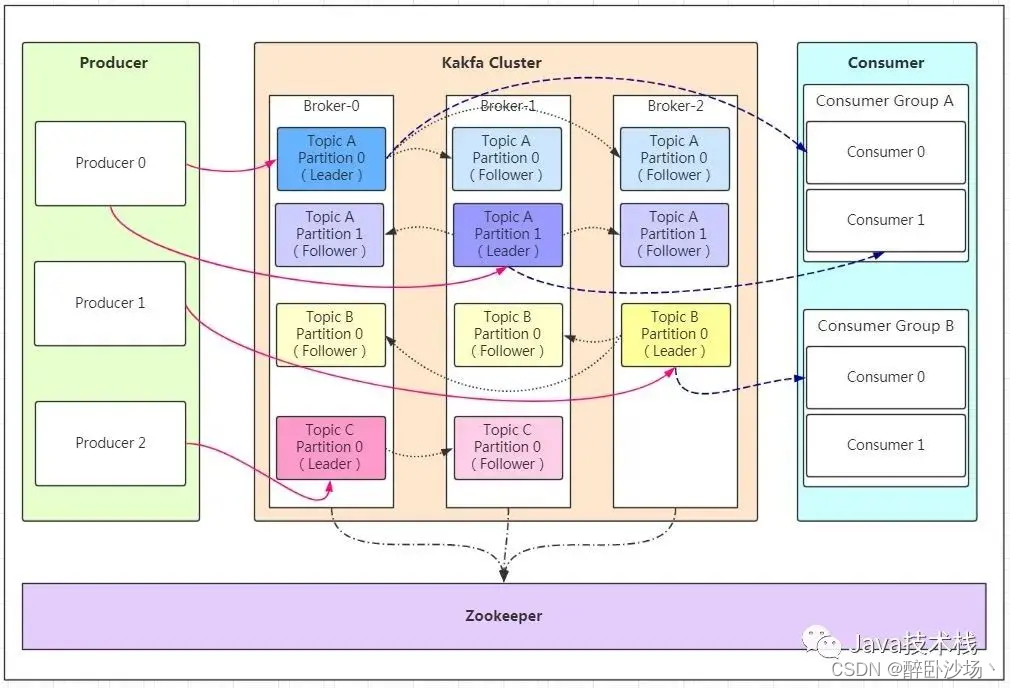
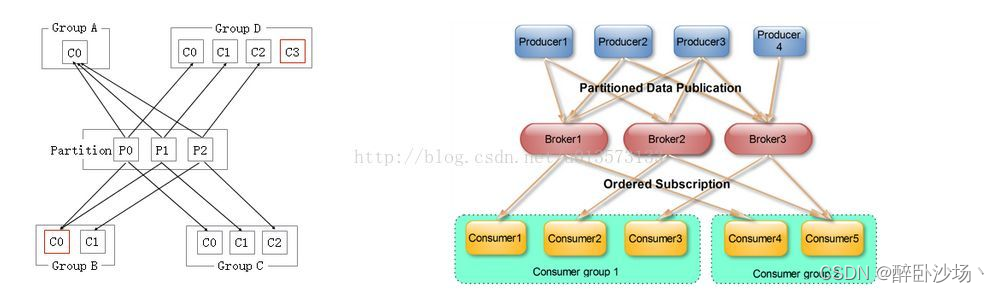
三、Kafka中的术语解释概述
Broker【服务器节点】
Kafka 集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据。
-
如果某topic有N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。
-
如果某topic有N个partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个broker不存储该topic的partition数据。
-
如果某topic有N个partition,集群中broker数目少于N个,那么一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种情况容易导致Kafka集群数据不均衡。
Topic【主题】
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic。(物理上不同Topic的消息分开存储,逻辑上一个Topic的消息虽然保存于
一个或多个broker上但用户只需指定消息的Topic即可生产或消费数据而不必关心数据存于何处)。类似于数据库的表名。在每个broker上都
可以创建多个topic。
Partition【分区】

-
topic中的数据分割为一个或多个partition。每个topic至少有一个partition。topic的数据数据会写入到不同的partition。
-
每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件。
-
partition中的数据是有序的,不同partition间的数据丢失了数据的顺序。
-
如果topic有多个partition,消费数据时就不能保证数据的顺序。
-
在需要严格保证消息的消费顺序的场景下,需要将partition数目设为1。
上面说到数据会写入到不同的分区,那kafka为什么要做分区呢?相信大家应该也能猜到,分区的主要目的是:
-
方便扩展。因为一个topic可以有多个partition,所以我们可以通过扩展机器去轻松的应对日益增长的数据量。
-
提高并发。以partition为读写单位,可以多个消费者同时消费数据,提高了消息的处理效率。
熟悉负载均衡的朋友应该知道,当我们向某个服务器发送请求的时候,服务端可能会对请求做一个负载,将流量分发到不同的服务器,那在kafka中,如果某个topic有多个partition,producer又怎么知道该将数据发往哪个partition呢?
kafka中有几个原则:
-
partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
-
如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
-
如果既没指定partition,又没有设置key,则会轮询选出一个partition。
保证消息不丢失是一个消息队列中间件的基本保证,那producer在向kafka写入消息的时候,怎么保证消息不丢失呢?
那就是通过ACK应答机制!在生产者向队列写入数据的时候可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
-
0代表producer往集群发送数据不需要等到集群的返回,不确保消息发送成功。安全性最低但是效率最高。
-
1代表producer往集群发送数据只要leader应答就可以发送下一条,只确保leader发送成功。
-
all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下一条,确保leader发送成功和所有的副本都完成备份。安全性最高,但是效率最低。
最后要注意的是,如果往不存在的topic写数据,能不能写入成功呢?kafka会自动创建topic,分区和副本的数量根据默认配置都是1。
Producer【生产者】
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后,broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition中,生产者也可以指定数据存储的partition。
Consumer【消费者】
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
Consumer Group【消费者组】
每个Consumer属于一个特定的Consumer Group(可为每个Consumer指定group name,若不指定group name则属于默认的group)。
同一个topic下的每个partition中message只能被组(Consumer group )中的一个consumer消费,如果想让一个message可以被多个consumer消费的话,那么这些consumer必须在不同的Consumer group。所以如果想同时对一个topic做消费的话,启动多个consumer group就可以了,但是要注意的是,这里的多个consumer的消费都必须是顺序读取partition里面的message,新启动的consumer默认从partition队列最头端最新的地方开始阻塞的读message。它不能像AMQ那样可以多个BET作为consumer去互斥的(for update悲观锁)并发处理message,这是因为多个BET去消费一个Queue中的数据的时候,由于要保证不能多个线程拿同一条message,所以就需要行级别悲观所(for update),这就导致了consume的性能下降,吞吐量不够。而kafka为了保证吞吐量,只允许同一个consumer group下的一个consumer线程去访问一个partition。如果觉得效率不高的时候,可以加partition的数量来横向扩展,那么再加新的consumer thread去消费。如果想多个不同的业务都需要这个topic的数据,起多个consumer group就好了,大家都是顺序的读取message,offsite的值互不影响。这样没有锁竞争,充分发挥了横向的扩展性,吞吐量极高。这也就形成了分布式消费的概念。
当启动一个consumer group去消费一个topic的时候,无论topic里面有多少个partition,无论我们consumer group里面配置了多少个consumer thread,这个consumer group下面的所有consumer thread一定会消费全部的partition;即便这个consumer group下只有一个consumer thread,那么这个consumer thread也会去消费所有的partition。因此,最优的设计就是,consumer group下的consumer thread的数量等于partition数量,这样效率是最高的。
- 当consumer group里面的consumer数量小于这个topic下的partition数量的时候,就会出现一个conusmer thread消费多个partition的情况,总之是这个topic下的partition都会被消费。
- 如果consumer group里面的consumer数量等于这个topic下的partition数量的时候,此时效率是最高的,每个partition都有一个consumer thread去消费。
- 当consumer group里面的consumer数量大于这个topic下的partition数量的时候,就会有consumer thread空闲。
多个Consumer Group下的consumer可以消费同一条message,但是这种消费也是以o(1)的方式顺序的读取message去消费,,所以一定会重复消费这批message的,不能向AMQ那样多个BET作为consumer消费(对message加锁,消费的时候不能重复消费message)
Leader【领导者】
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的partition。
Follower【跟随者】
- Follower跟随Leader,所有写请求都通过Leader路由,数据变更会广播给所有Follower,Follower与Leader保持数据同步。
- 如果Leader失效,则从Follower中选举出一个新的Leader。
- 当Follower与Leader挂掉、卡住或者同步太慢,leader会把这个follower从“in sync replicas”(ISR)列表中删除,重新创建一个Follower。
Replica【副本】
每个partition可以在其他的kafka broker节点上存副本,以便某个kafka broker节点宕机不会影响这个kafka集群。
存replica副本的方式是按照kafka broker的顺序存。
例如有5个kafka broker节点,某个topic有3个partition,每个partition存2个副本,那么partition1存broker1,broker2,partition2存broker2,broker3。。。以此类推(replica副本数目不能大于kafka broker节点的数目,否则报错。这里的replica数其实就是partition的副本总数,其中包括一个leader,其他的就是copy副本)。这样如果某个broker宕机,其实整个kafka内数据依然是完整的。但是,replica副本数越高,系统虽然越稳定,但是会带来资源和性能上的下降;replica副本少的话,也会造成系统丢数据的风险。
-
传送消息:producer先把message发送到partition leader,再由leader发送给其他partition follower(如果让producer发送给每个replica那就太慢了)。 再向Producer发送ACK前需要保证有多少个Replica已经收到该消息:根据ack配的个数而定。
-
处理某个Replica不工作的情况:如果这个部工作的partition replica不在ack列表中,就是producer在发送消息到partition leader上,partition leader向partition follower发送message没有响应而已,这个不会影响整个系统,也不会有什么问题。如果这个不工作的partition replica在ack列表中的话,producer发送的message的时候会等待这个不工作的partition replca写message成功,但是会等到time out,然后返回失败因为某个ack列表中的partition replica没有响应,此时kafka会自动的把这个部工作的partition replica从ack列表中移除,以后的producer发送message的时候就不会有这个ack列表下的这个部工作的partition replica了。
-
处理Failed Replica恢复回来的情况:如果这个partition replica之前不在ack列表中,那么启动后重新受Zookeeper管理即可,之后producer发送message的时候,partition leader会继续发送message到这个partition follower上。如果这个partition replica之前在ack列表中,此时重启后,需要把这个partition replica再手动加到ack列表中。(ack列表是手动添加的,出现某个部工作的partition replica的时候自动从ack列表中移除的)。
四、Kafka可视化管理工具
【Kafka可视化工具】kafka-manager
kafka-manager安装及基本使用
【Kafka可视化工具】Offset Explorer
Kafka-Offset Explorer安装及基本使用










![BulingBuling - 作息安排 [Reset Your Routine] - 1](https://img-blog.csdnimg.cn/img_convert/3b6e52ebfbc2ac9314c89bffbc1e0446.png)