引言
- 在一个使用 pandas 做数据分析的项目过程中,再次深刻理解了一下 pandas 中使用 groupby 进行分组的一些细节问题,以及对想要做的操作如何实现,在此记录;
- 问题 1:groupby 分组查看分组结果,以及重设分组列列名
- 问题 2:如何获取分组后的值和分组条件的值(比如有一周内用户访问页面的记录,我们需要拿到用户周几最活跃呢?最活跃的时间段是什么时候?判断最活跃的 count 次数如何获取呢?)
- 注:中间包含一些中间函数的用法,仅供参考;
问题 1:
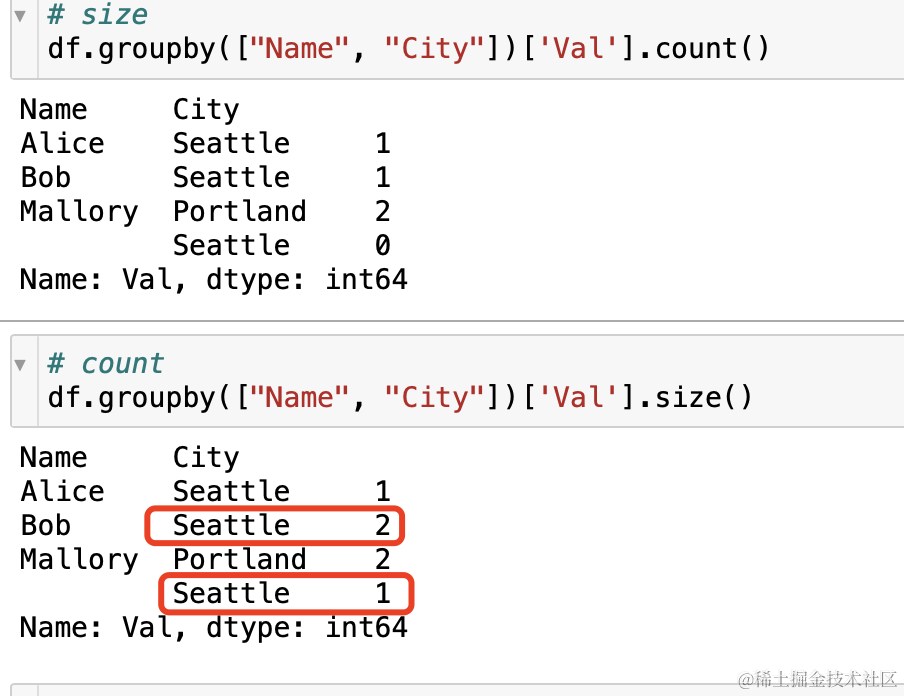
延伸 1:关于count 和 size 的区别
- 一般来说分组后结果都会接一个聚合函数,如 count,sum,agg 等,但是意外发现了还有 size,特此记录 size 和 count 的区别
- 总结:size计数时包含NaN值,而count不包含NaN值
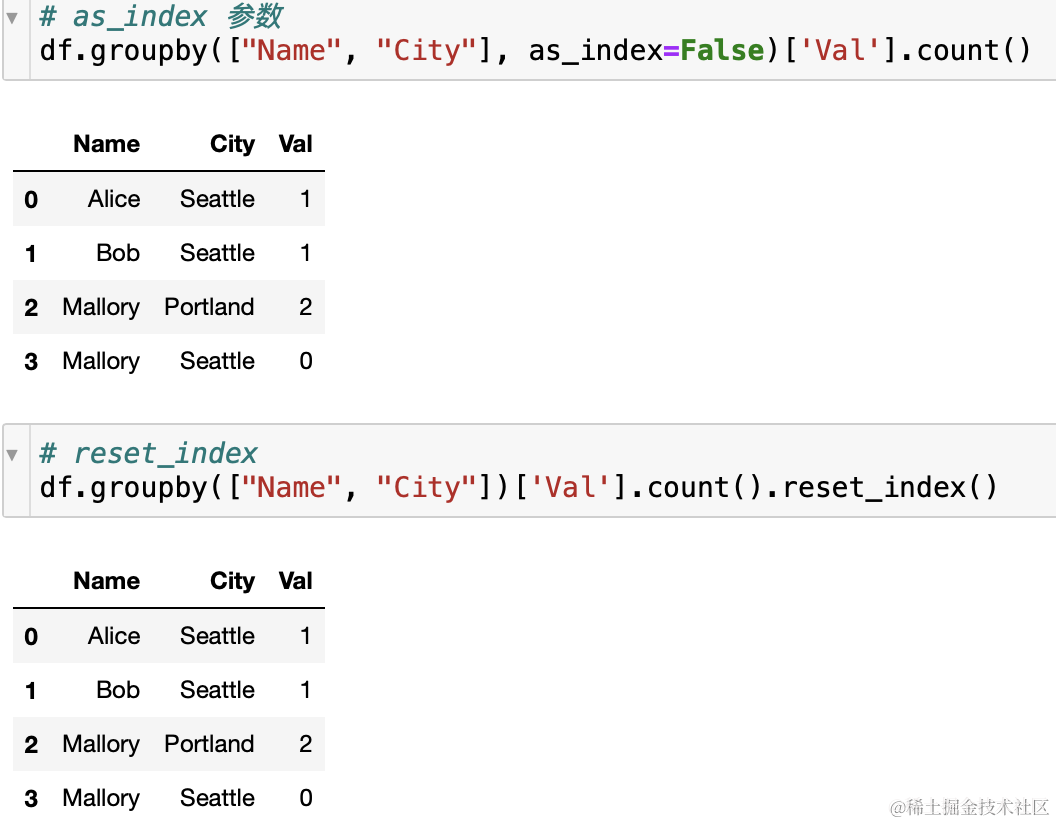
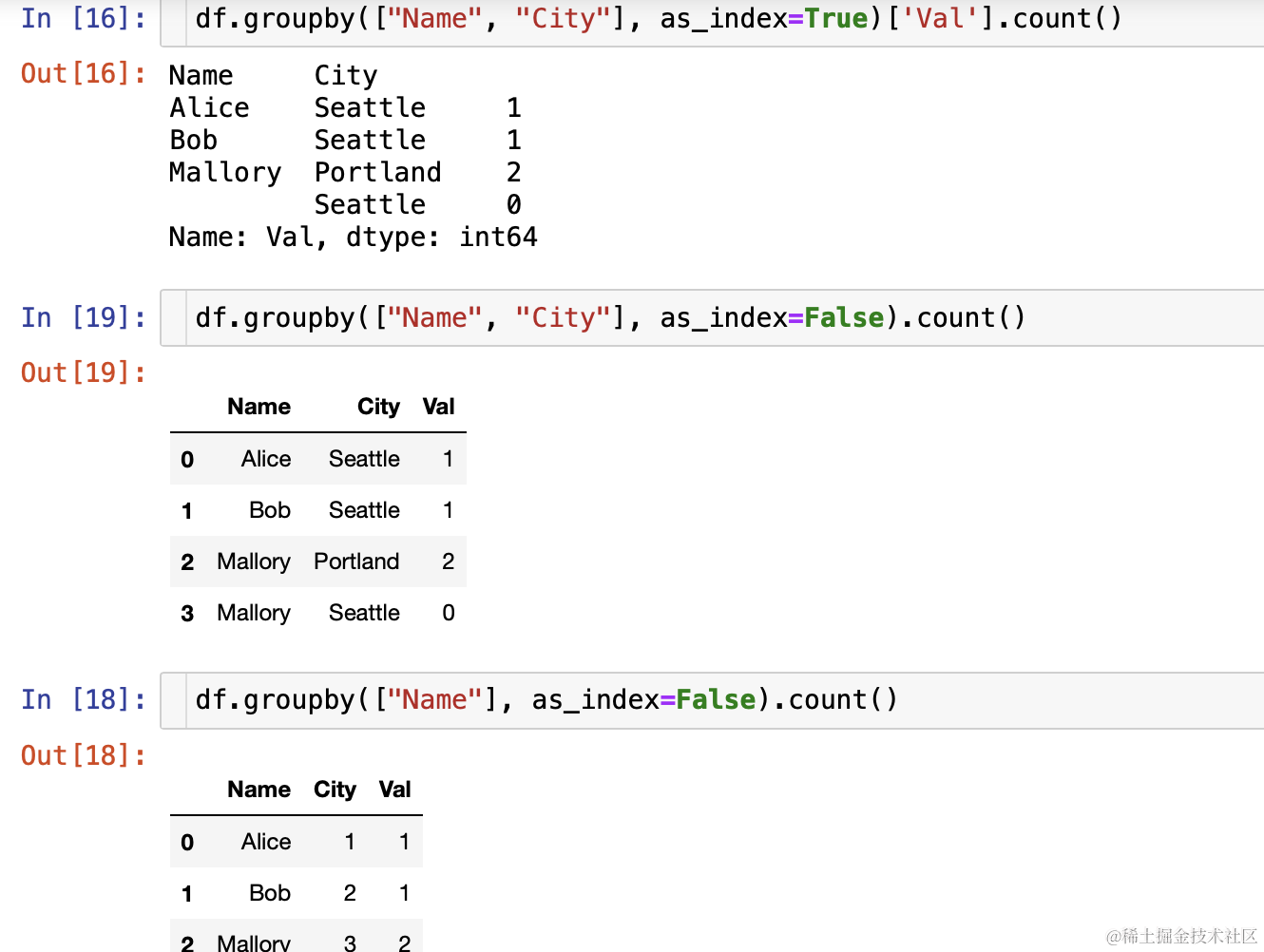
延伸 1.1 reset_index()函数和 as_index 参数的作用
- 个人理解groupby 内参数 as_index 1可以直接把结果转换成 DF,2就是分组后的重命名(使用参数重命名可以看测试结果,个人感觉不如 reset_index 看着直接)
- 对一个字段分组,剩余俩字段 count 结果也不同(这个是个人的一个认知错误一直以为结果是不参与分组的字段分组后的值是相同的,这只是工作时候使用数据的问题)
延伸 2:如何查看 groupby 分组结果
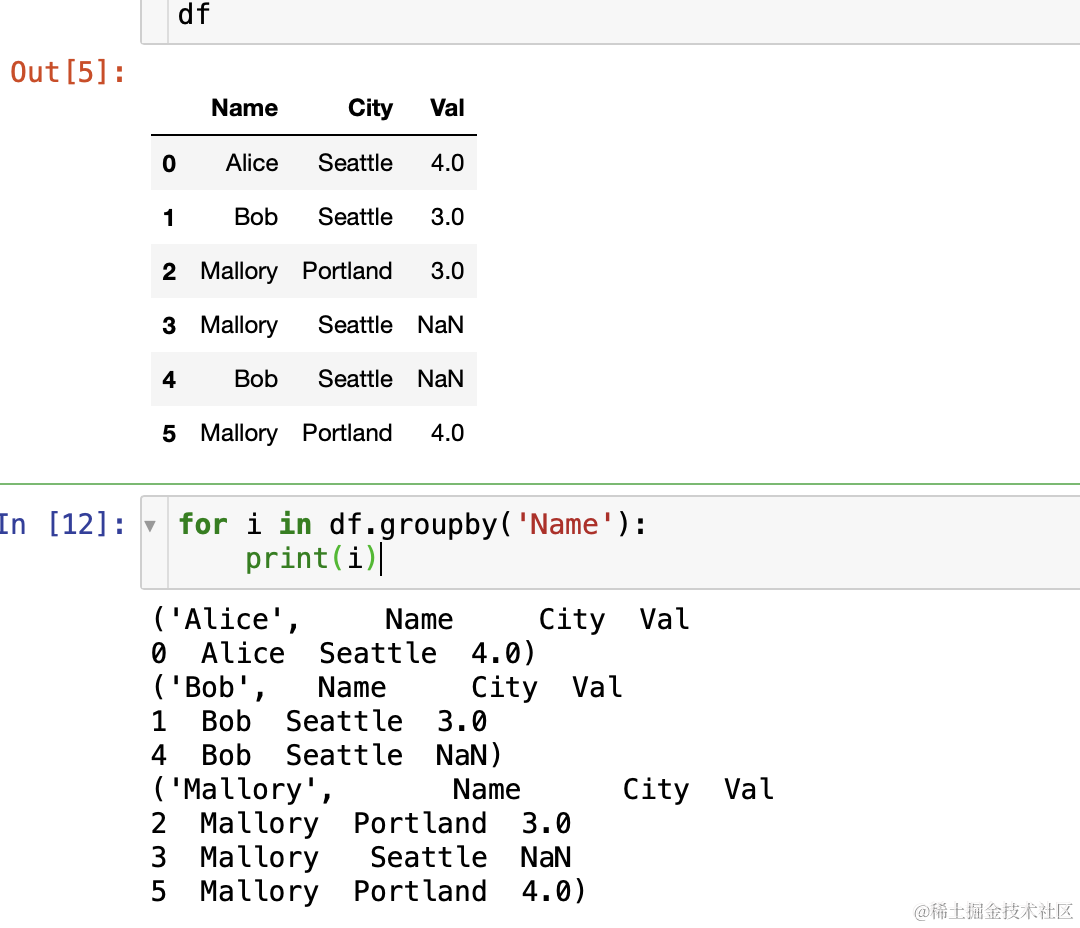
- pandas 中 groupby 后结果不是 df 无法直接查看,可以通过循环遍历打印,groups,get_group来查看,如下所示:
- 可以看出返回的内容是由若干个二元组构成的,元组第一位是分组名,第二位是组内成员构成的DF。而元组之间并不是由python通常的元组、列表或字典连接的,这也是groupby的返回类型难以直接查看的原因
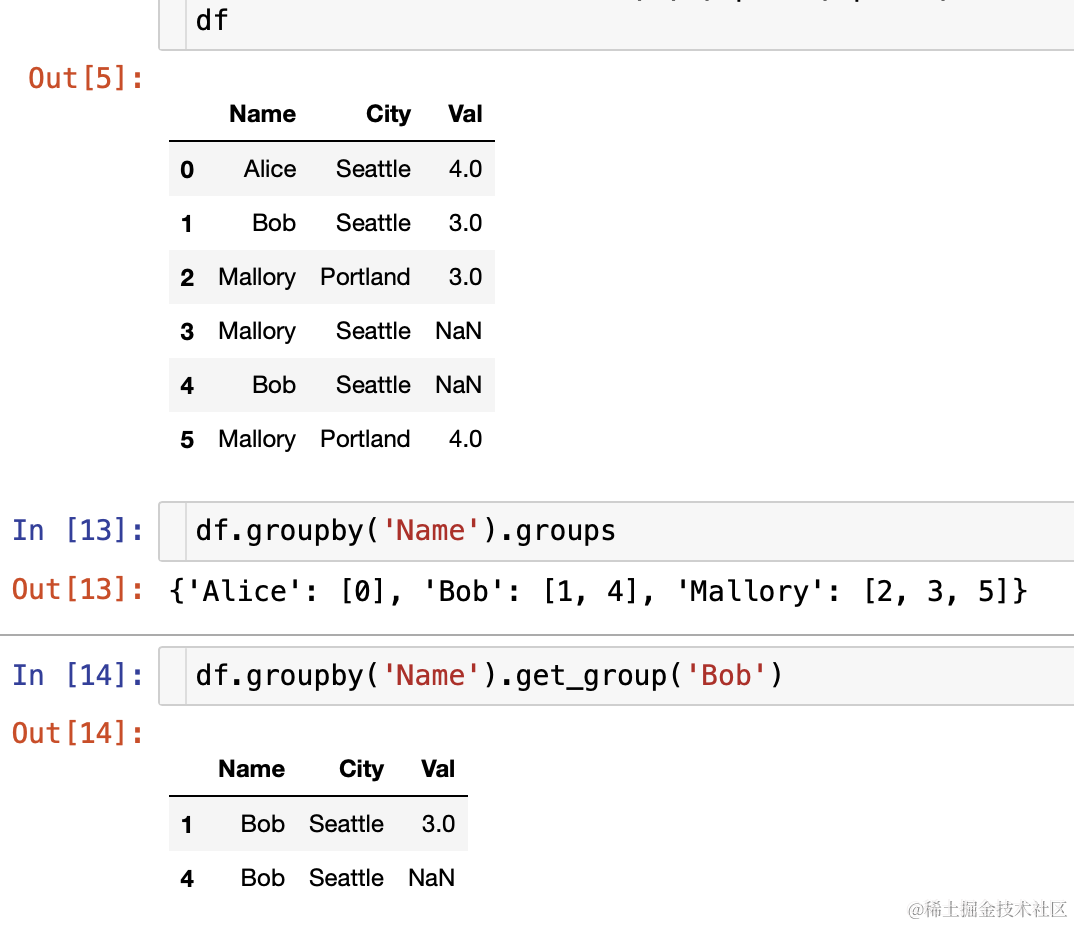
- 其实想看到分组结果直接接一个 size 或者 count 函数即可
1 重设分组列名
- reset_index()函数的用法:重设分组后列名
- 比如上面分组,三个字段使用前两个字段分组,最后分组结果使用的是第三个字段的名称,如何修改呢?
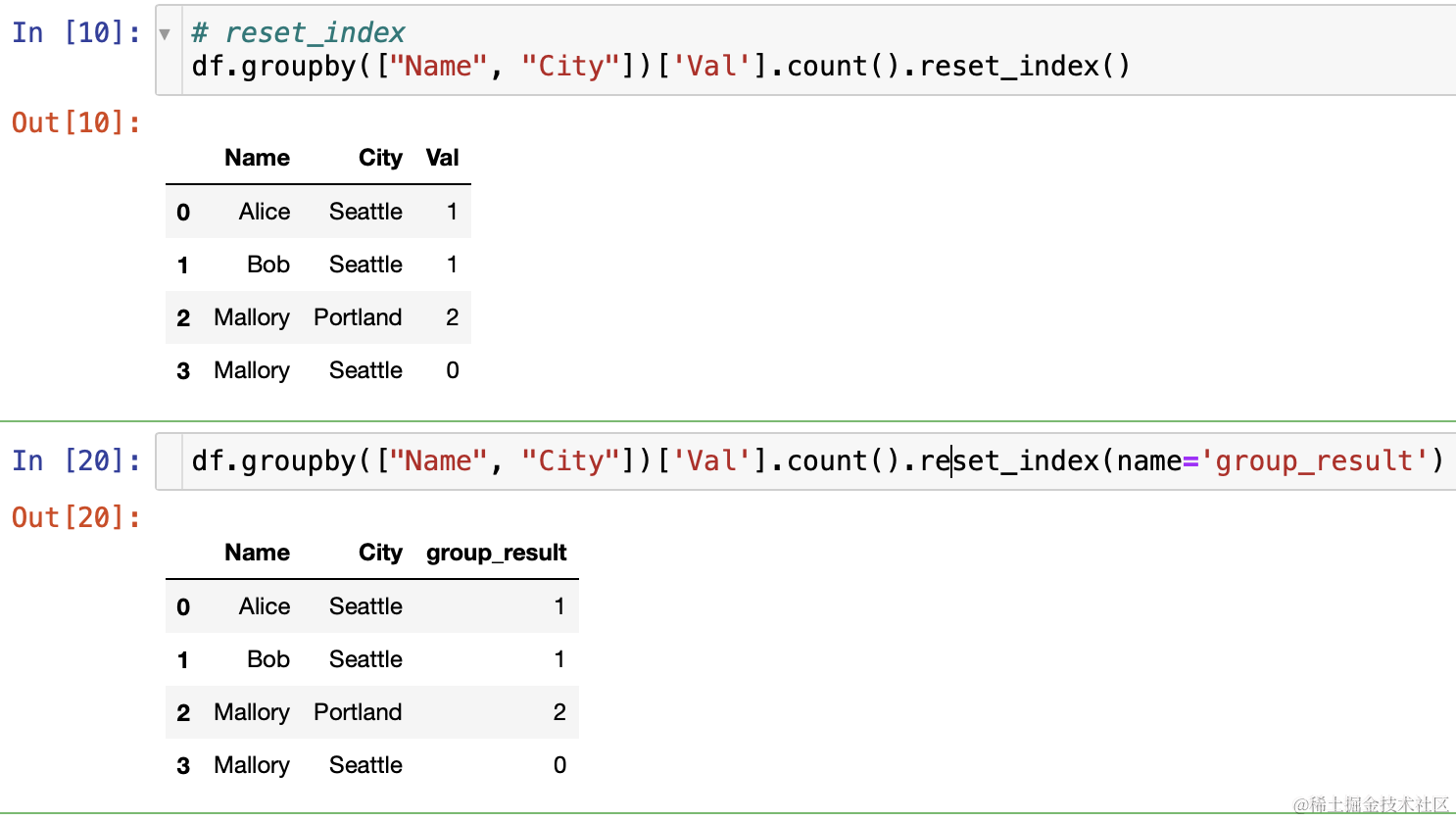
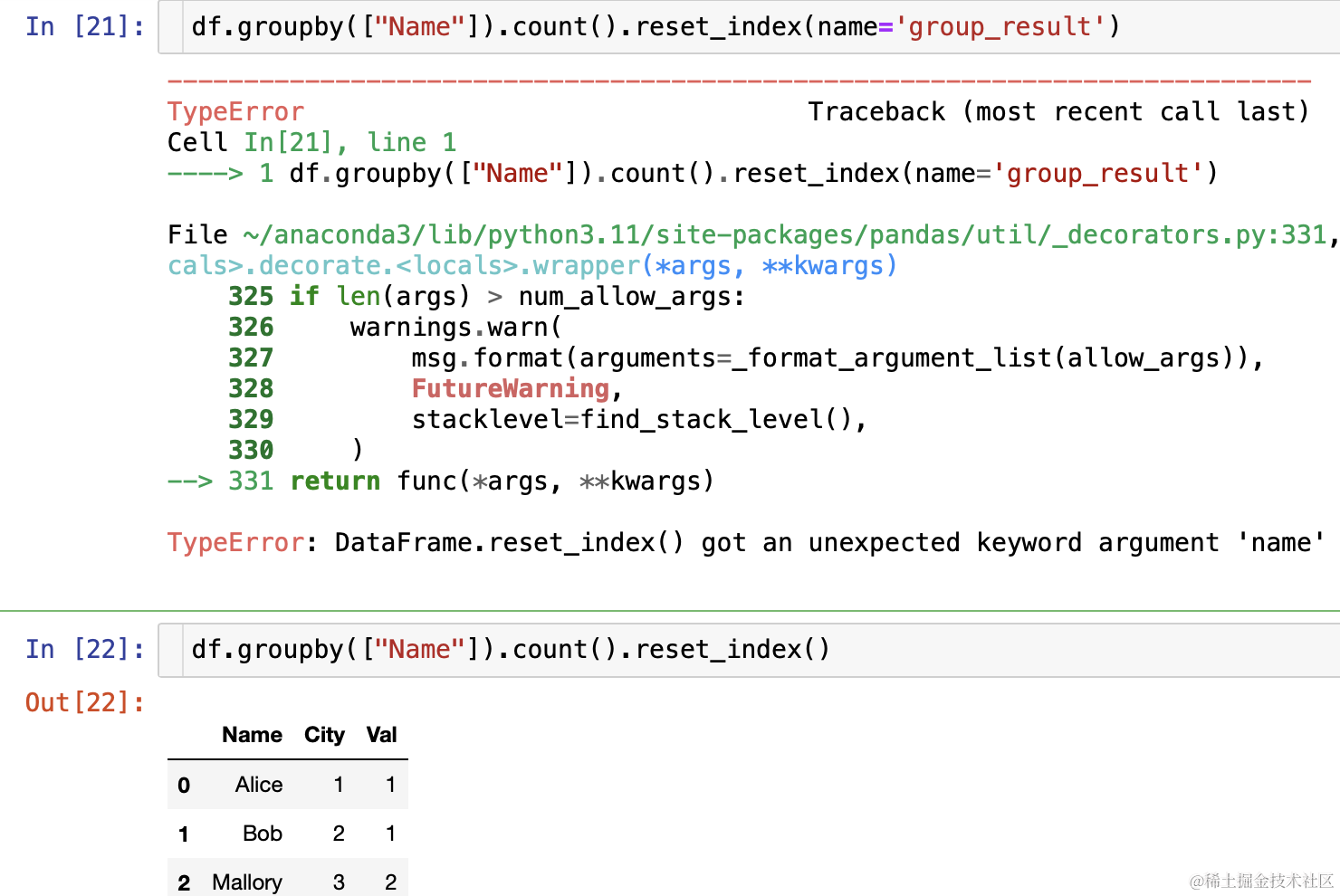
- 加入分组后不选择一列会怎样呢?(当然是报错,因为函数不知道你要对分组后的哪个字段重命名)
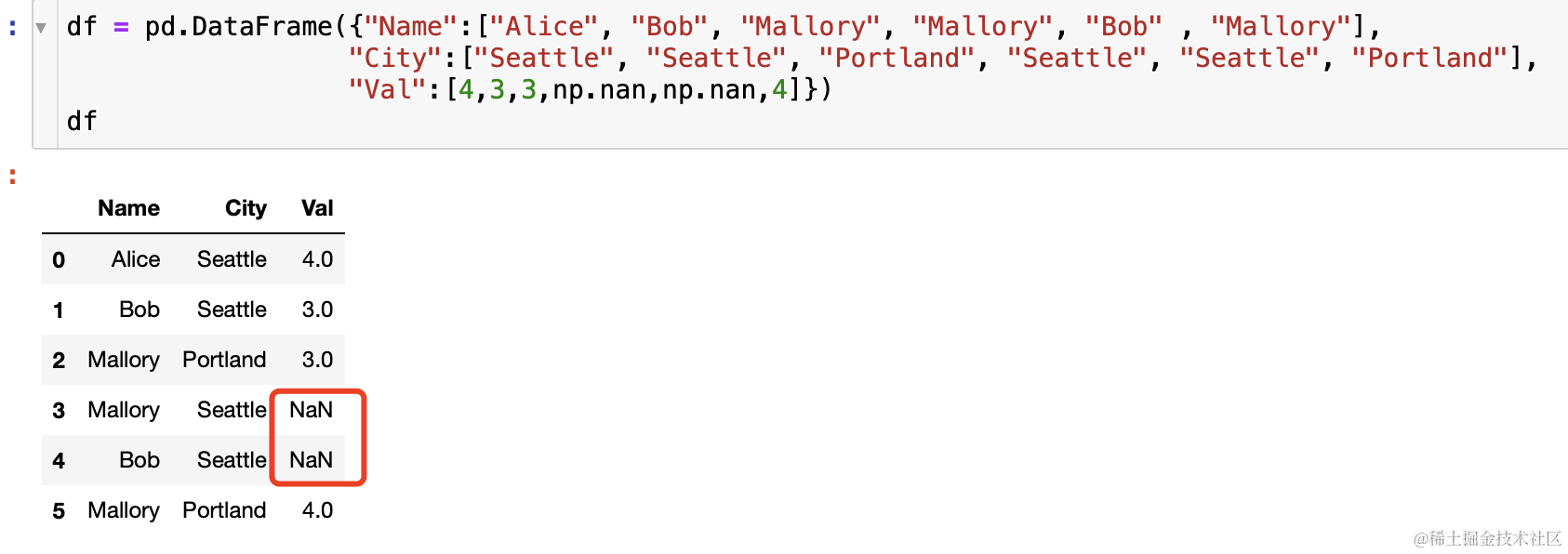
df = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"],
"City":["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"],
"Val":[4,3,3,np.nan,np.nan,4]})
问题 2
- 如何获取到周几最活跃?(此处还有个知识点就是如何把日期转换为周几,下篇文章写时间相关的转化的时候再介绍)
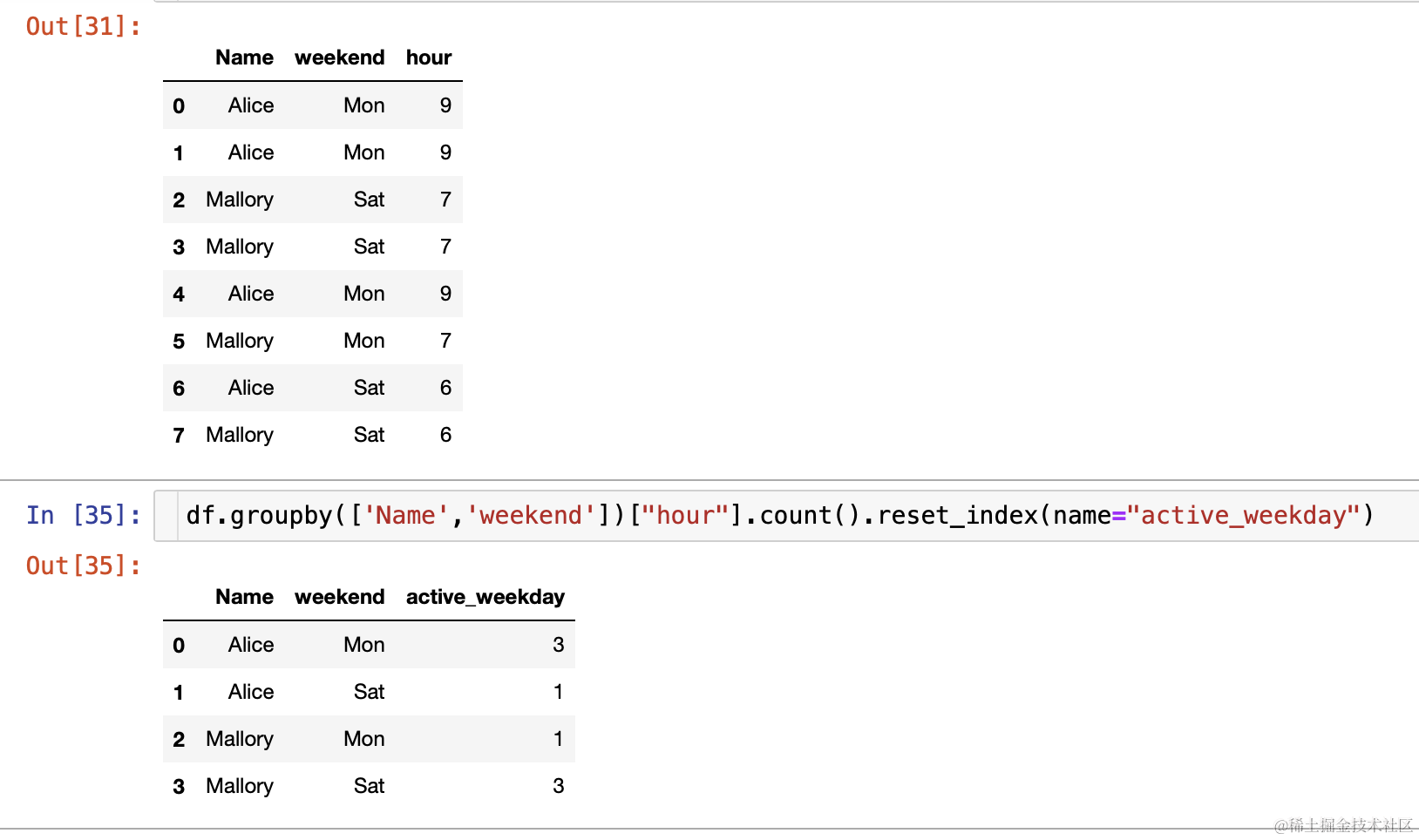
- 但是如何根据 count 值拿到最活跃的是周几呢?此处需要换个思维想一想 first函数
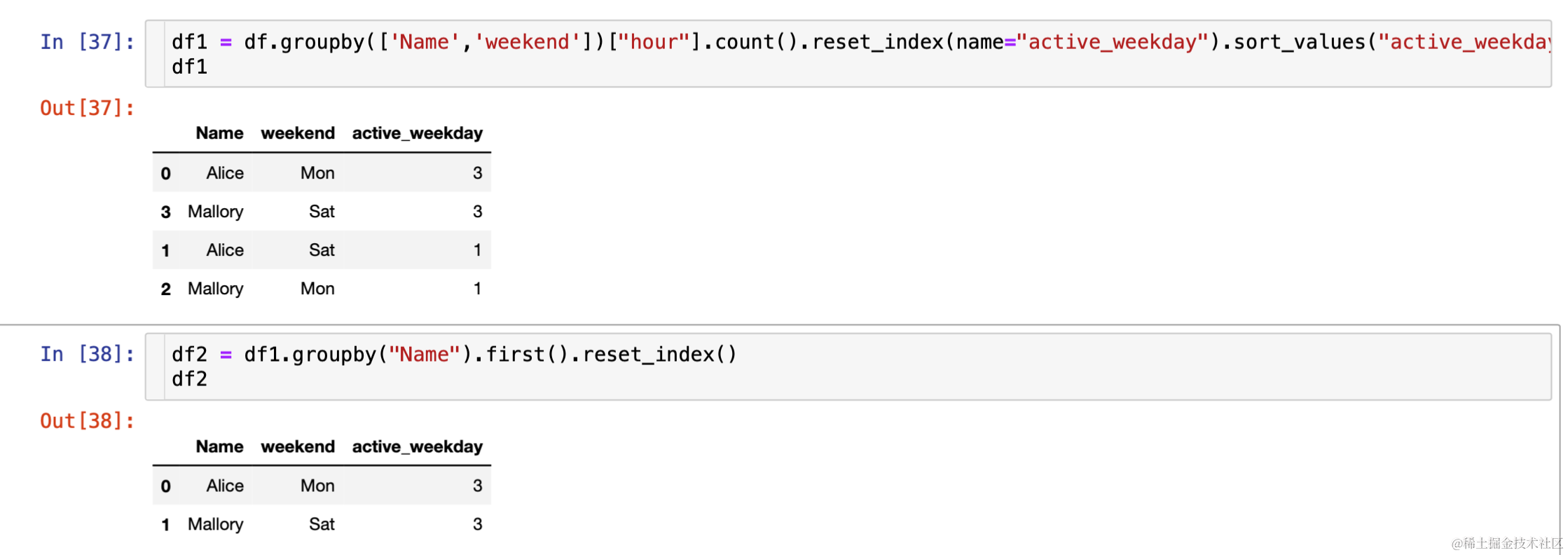
- 同理,获取最活跃的时间段可以取 top 值然后转换成列表(可以结合 1 再进行 2,也可以去一下重)
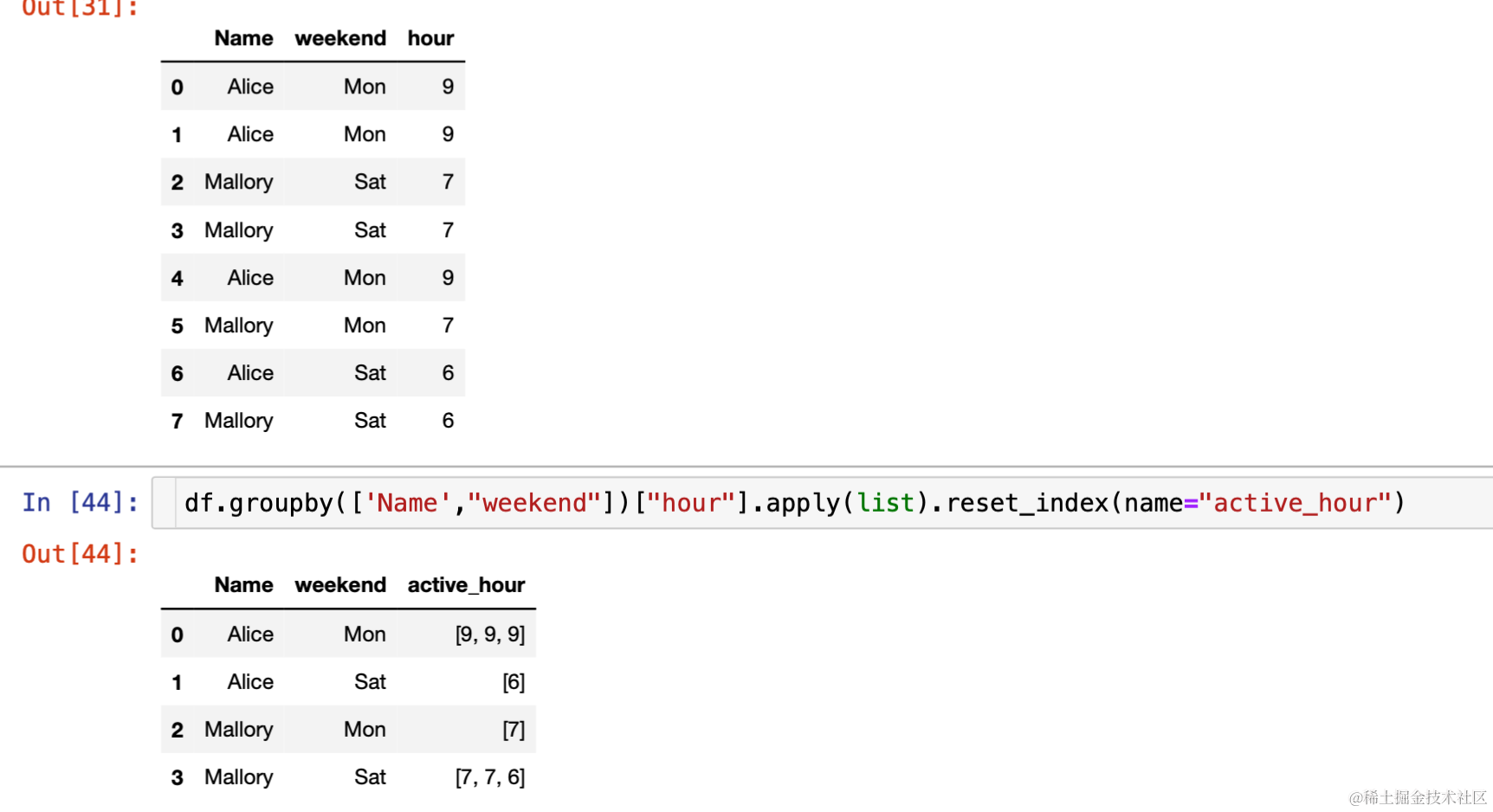
- 以上数据均为个人阐述用法编造,理解意思即可
df = pd.DataFrame({"Name":["Alice", "Alice", "Mallory", "Mallory", "Alice" , "Mallory","Alice", "Mallory"],
"weekend":["Mon", "Mon", "Sat", "Sat", "Mon", "Mon","Sat","Sat"],
"hour":[9,9,7,7,9,7,6,6]})











![[单master节点k8s部署]20.监控系统构建(五)Alertmanager](https://img-blog.csdnimg.cn/direct/1677f991002140ab82ff06465a97f27f.png)


