背景介绍
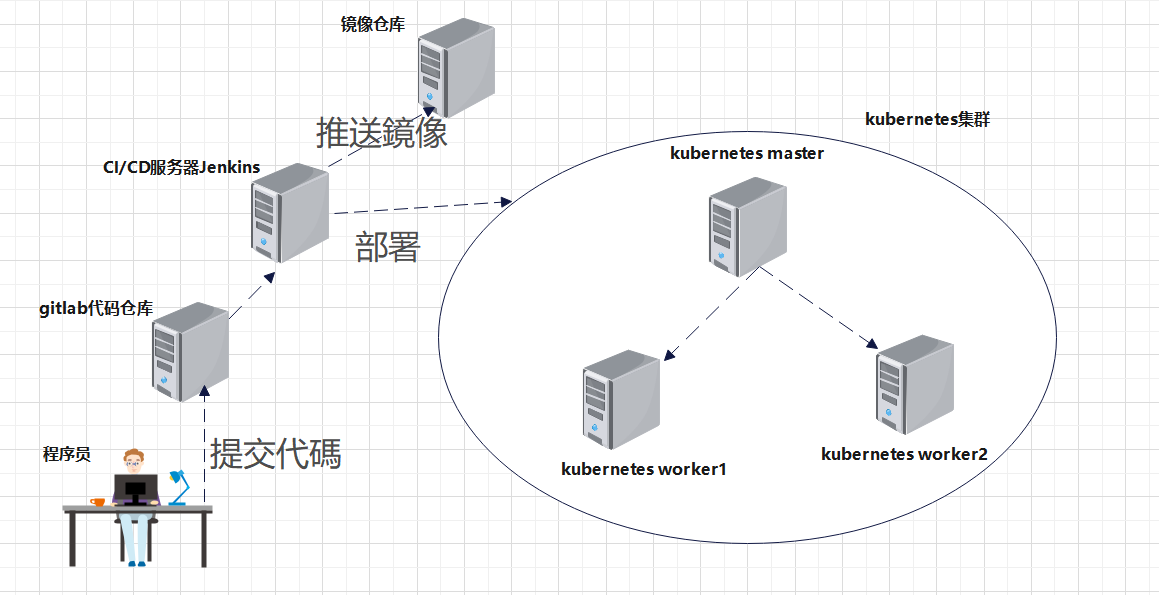
最近被不同的人安利了 FastGPT 项目,实际上手体验了一下,使用流程类似之前调研过的 Dify, 包含的功能主要是:任务流的编排,知识库管理,另外还有一些外部工具的调用能力。使用页面如下所示:

实际去看了下项目的代码分布,结果发现如下所示:

难道后端 Python 只需要如此少的代码量就可以实现一个大模型应用了?深入了解了 FastGPT 的实现,发现其 Python 为测试代码,完整的项目实现都是基于前端语言 ts 和 js 实现。这篇文章就主要介绍下 FastGPT 知识库 RAG 设计的实现细节。
FastGPT 简介
FastGPT 被设计为基于 LLM 大语言模型的知识库问答系统,与常规的 RAG 相比增加了额外工作流编排的能力,这部分类似 Dify。但是相对 Dify 而言可调用的第三方应用更少一些。按照习惯先查看项目的架构图:

一般而言,从架构图中就可以看到项目的独特之处。之前 qanything 和 ragflow 同样从架构图看出 RAG 项目的设计差异。
对于常规的 RAG 架构图,这张图可以明显看到大模型模块被放大,而且文件入库的流程都会先调用大模型。从大模型的输出来看,存在 QA 拆分, 文本分段 和 手动输入 三种情况:
文本分段是常规的 RAG 的处理方案QA 拆分看起来是基于原始文本生成问答对,这部分猜测应该是根据大模型生成问答对,之前 Dify 也有类似的功能,被称为Q&A 模式手动输入则是直接输入问答对,这部分应该是手工输入数据进行补充;
预计文件入库环节的大模型调用主要作用于 QA 拆分。
技术选型
官方给出的技术栈为:NextJs + TS + ChakraUI + Mongo + Postgres (Vector 插件)
- NextJs 用于构建前后端服务,可以在单个工程中同时构建前后端代码,熟悉 Flask 应该对这个玩法不陌生,只是 Flask 是后端想把前端的活干了,而 NextJs 则是前端把后端的活干了;
- TS 用于编写具体的代码;
- ChakraUI 是 UI 组件库;
- MongoDB 是作为业务数据库使用,事实上 FastGPT 中的文件也是基于 MongoDB 的 GridFS 进行存储;
- Postgres 用于存储向量数据;
核心模块解读
与常规的 Python 实现大模型应用不同,基于 TypeScript 没有类似 langchain 的框架,因此需要自行实现知识库构建的完整流程。
文件入库流程
实际文件的入库对应的接口为 api/core/dataset/collection/create/fileId, 因为是基于 NextJs 实现的,接口与文件的组织结构是一样的,对应的处理实现是在 projects/app/src/pages/api/core/dataset/collection/create/fileId.ts 中
文件入库会执行文件读取,切片,然后会依次写入知识库,实际会根据不同写入模式内容上有一些差异,具体的实现如下所示:
// 1. 读取文件
const { rawText, filename } = await readFileContentFromMongo({
teamId,
bucketName: BucketNameEnum.dataset,
fileId
});
// 2. 切片,文本分段会保留 20% 的重叠,QA 拆分则没有重叠
const chunks = rawText2Chunks({
rawText,
chunkLen: chunkSize,
overlapRatio: trainingType === TrainingModeEnum.chunk ? 0.2 : 0,
customReg: chunkSplitter ? [chunkSplitter] : []
});
// 3. 查询限制
await checkDatasetLimit({
teamId,
insertLen: predictDataLimitLength(trainingType, chunks)
});
await mongoSessionRun(async (session) => {
// 4. 构建知识库集合
const { _id: collectionId } = await createOneCollection({
...body,
teamId,
tmbId,
type: DatasetCollectionTypeEnum.file,
name: filename,
fileId,
metadata: {
relatedImgId: fileId
},
// special metadata
trainingType,
chunkSize,
chunkSplitter,
qaPrompt,
hashRawText: hashStr(rawText),
rawTextLength: rawText.length,
session
});
// 5. 创建训练账单,确认消耗金额
const { billId } = await createTrainingUsage({
teamId,
tmbId,
appName: filename,
billSource: UsageSourceEnum.training,
vectorModel: getVectorModel(dataset.vectorModel)?.name,
agentModel: getLLMModel(dataset.agentModel)?.name,
session
});
// 6. 分片数据写入 MongoDB 数据库
await pushDataListToTrainingQueue({
teamId,
tmbId,
datasetId: dataset._id,
collectionId,
agentModel: dataset.agentModel,
vectorModel: dataset.vectorModel,
trainingMode: trainingType,
prompt: qaPrompt,
billId,
data: chunks.map((item, index) => ({
...item,
chunkIndex: index
})),
session
});
在目前的流程中只是写入业务数据库 MongoDB,之后再根据 MongoDB 数据库中内容进行向量化。
对于 QA 模式,可以查看对应的 prompt 设计:
标记中是一段文本,学习和分析它,并整理学习成果:\n
- 提出问题并给出每个问题的答案。\n
- 答案需详细完整,尽可能保留原文描述。\n
- 答案可以包含普通文字、链接、代码、表格、公示、媒体链接等 Markdown 元素。\n
- 最多提出 30 个问题。\n
可以看到就是基于大模型直接生成不超过 30 个问答对。
知识库检索
FastGPT 的知识检索目前支持多种检索模式,主要关注下最复杂的混合检索。
FastGPT 实现的是基于向量检索 + 文本检索实现的混合检索,并基于 RRF 实现多种检索结果的融合。对应的实现在 packages/service/core/dataset/search/controller.ts ,具体的简化后如下所示:
// 向量检索 + 文本检索召回
const { embeddingRecallResults, fullTextRecallResults, tokens } = await
multiQueryRecall({
embeddingLimit,
fullTextLimit
});
// 重排序的支持
const reRankResults = await (async () => {
if (!usingReRank) return [];
set = new Set<string>(embeddingRecallResults.map((item) => item.id));
const concatRecallResults = embeddingRecallResults.concat(
fullTextRecallResults.filter((item) => !set.has(item.id))
);
// remove same q and a data
set = new Set<string>();
const filterSameDataResults = concatRecallResults.filter((item) => {
// 删除所有的标点符号与空格等,只对文本进行比较
const str = hashStr(`${item.q}${item.a}`.replace(/[^\p{L}\p{N}]/gu, ''));
if (set.has(str)) return false;
set.add(str);
return true;
});
return reRankSearchResult({
query: reRankQuery,
data: filterSameDataResults
});
})();
// 使用 rrf 合并向量检索和文本检索的结果
const rrfConcatResults = datasetSearchResultConcat([
{ k: 60, list: embeddingRecallResults },
{ k: 60, list: fullTextRecallResults },
{ k: 58, list: reRankResults }
]);
可以看到基本上是目前比较中规中矩的混合检索方案,只是转换为 TypeScript 进行了实现。
总结
本文是对 FastGPT 现有知识库流程的解读,整体看起来 FastGPT 的处理流程中规中矩。
通过前后端使用相同的开发语言,可以解决前后端代码复用的问题,借助 NextJs 也可以简化框架设计与部署,同时对团队的技术栈要求也更低了。但是因为没有使用 Python 实现后端服务,导致无法使用大量现有的大模型应用框架,为未来的拓展能力带来了一些限制,有得有失。














![[图解]SysML和EA建模住宅安全系统-11-接口块](https://i-blog.csdnimg.cn/direct/bb7ddea205744947a0cdd6abb14fb3e8.png)