人工智能在第四次工业革命发挥着至关重要的作用,它广泛的融入日常生活,例如Google助手、Siri、智能手机摄像头、社交媒体过滤器、自动标记、医疗成像、导航等,所有这些技术都切实的改进和增强日常活动的便利性和习惯。
大模型技术发展到现在已经趋于稳定,而加入视觉的多模态大模型才开始兴起,它除了日常生活,还会广泛的融入到工业智造、无人驾驶和机器人等领域。这里计算机视觉就十分重要,它在捕获实时图像、提炼知识以及自主预测和分类图像方面是都不断地进步。计算机视觉使计算机能够解释和检测图像中的模式,其主要目的是复制人类视觉系统处理、分析和理解视觉数据的能力。
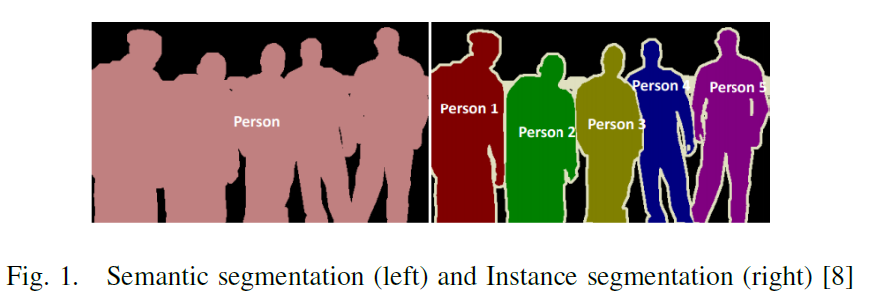
一般而言,计算机视觉任务可以进一步分为四个更广泛的类别: 1. 物体检测,2. 图像分类,3. 语义分割,4. 实例分割。

第一幅图为语义分割任务,就是将草,猫,树和蓝天隔开。第二幅图展示了图像分类,判断画面中是什么物体。第三幅图将画面中的物体都一一识别出来。第四幅图将这些物体的轮廓做出分离提炼。
物体检测涉及使用图像或视频检测和定位感兴趣的对象。它使用带有相应类标签的对象周围的边界框,目标是精确定位对象并相应地对它们进行分类。随着深度学习模型的出现,例如基于区域的卷积神经网络、更快的R-CNN、YOLO正在用于这项任务。真实世界的例子包括自动驾驶汽车,用于识别和跟踪交通科学车辆和现实生活中的障碍物。

图像分类的目的是将图像分类为几个预定义的类别之一。目标是使算法能够根据其视觉特征和模式识别图像并为图像分配正确的标签,它有多种应用,包括医学图像分类、质量控制、手势识别、手写图像分类。卷积神经网络CNN等深度学习架构及其类型,如LeNet、AlexNet、VGGNet、GoogLeNet (Inception)、ResNet、DenseNet可用于相应地对图像进行分类。

实例分割使用像素级分类,该分类为每个坐标像素分配标签,将图像划分为多个段,其中每个段对应于特定的对象类。这在不同对象之间的边界没有明确定义的情况下特别有用,这些场景需要精确的位置,例如脑肿瘤分割、自动驾驶、卫星图像,并涉及最先进的架构,包括用于此任务的U-NET和DeepLab。
即时分割是语义分割的更高级和详细的版本,它涉及通过在同一类中分配不同的标签来对类中的对象进行分类。它在同一类的不同实例之间提供像素级区分,也用于自动驾驶汽车、医疗图像等

其他技术,如全景分割、光学字符识别、图像字幕、图像重建,在该领域是值得注意的。将计算机视觉与其他突出的人工智能领域相结合,为该行业的重大进步铺平了道路。
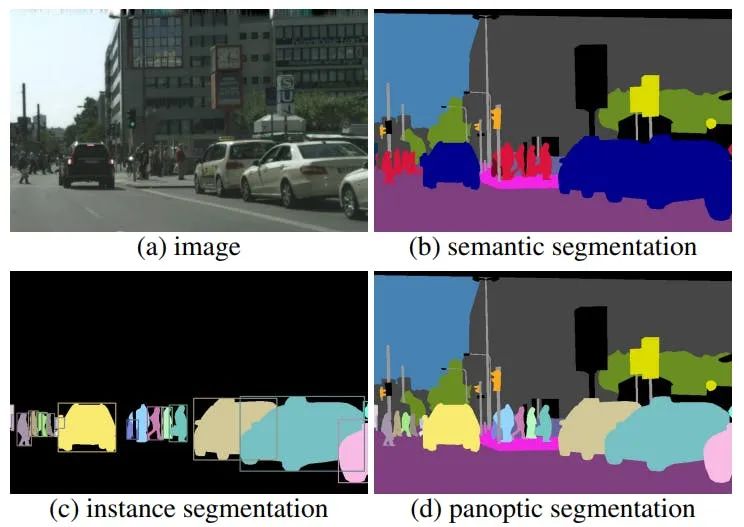
全景分割d结合了语义b和实例c分割,为更复杂的计算机视觉应用生成准确的像素级注释。它通过合并分类和检测算法来检测“物”和“物”,以实现更丰富的场景理解。
虽然全景分割是一种提高视觉理解力的强大技术,但由于以下原因,它带来了多重挑战:分割重叠对象很困难,因为算法无法识别对象边界以生成准确的蒙版。由于模糊、遮挡和形状不清晰,低图像质量使检测事物和分类事物变得具有挑战性。构建分割模型需要广泛、高质量的训练数据集来全面理解日常物体。从头开始开发此类模型既繁琐又昂贵。因此一般要依托合适的平台,这个平台提供预构建的分割框架和工具,以通过用户友好的界面有效地标记所有类型和格式的视觉数据。
最后一起聊聊大名鼎鼎的OpenCV,开源计算机视觉库,计算机视觉的扛把子。它是一个开源的计算机视觉和机器学习软件库。OpenCV旨在为计算机视觉应用提供通用基础设施,并加速机器感知在商业产品中的使用。作为 BSD 许可的产品,OpenCV使企业可以轻松使用和修改代码。
该库拥有2500多种优化算法,其中包括一整套经典和最先进的计算机视觉和机器学习算法。这些算法可用于检测和识别人脸、识别物体、对视频中的人体动作进行分类、跟踪摄像机运动、跟踪移动物体、提取物体的3D模型、从立体摄像机生成3D点云、将图像拼接在一起以生成整个场景的高分辨率图像、从图像数据库中查找相似图像、从使用闪光灯拍摄的图像中删除红眼、 跟随眼球运动,识别风景建立标记以便于将其与增强现实叠加。