目录
01 学习目标
02 概念
2.1 强化学习
2.2 深度Q学习(Deep Q-Learning )
03 问题描述
04 算法中的概念及原理
05 月球着陆器自动着陆的算法实现
06 拓展:基于pytorch实现月球着陆器着陆
07 总结
写在最前:关于强化学习及lunar lander问题有很多技术贴,作者尚未理解透彻,不作全面深入的原理讲解,本文仅作吴恩达老师课程的课后代码实现之用途!
01 学习目标
(1)理解什么强化学习
(2)利用深度Q学习(Deep Q-Learning)算法实现月球着陆器自动着陆
02 概念
2.1 强化学习
强化学习(Reinforcement Learning,简称RL)是一种机器学习方法,主要研究智能体(agent)如何在环境(environment)中采取行动以最大化某种累积奖励。在强化学习中,智能体通过与环境的交互来学习,即通过尝试不同的动作并观察结果,逐步优化其行为策略。
强化学习的基本要素包括:
1. 状态(State):描述环境当前情况的信息。
2. 动作(Action):智能体可以执行的操作。
3. 奖励(Reward):环境对智能体执行动作后的反馈,用于指导智能体的学习过程。
4. 策略(Policy):智能体选择动作的规则或策略,可以是确定性的或概率性的。
5. 价值函数(Value Function):评估状态或状态-动作对的好坏,通常用于指导策略的改进。
6. 模型(Model):可选,表示环境的状态转移和奖励函数。
强化学习的目标是找到一个最优策略,使得智能体在长期运行中获得的累积奖励最大化。常见的强化学习算法有Q-Learning、Deep Q-Networks (DQN)、Policy Gradients、SARSA、DDPG、PPO(近端策略优化算法)等。强化学习在游戏、机器人控制、自动驾驶、推荐系统等多个领域都有广泛的应用。例如,在AlphaGo中,深度强化学习被用来训练围棋AI,使其能够战胜世界顶级棋手。
2.2 深度Q学习(Deep Q-Learning )
Deep Q-Learning 是一种强化学习方法,它将传统的 Q-Learning 的概念扩展到了使用深度神经网络来近似 Q 函数。在传统的 Q-Learning 中,Q 值通常是在一个表格中存储和更新的,这种方法在状态空间有限且较小的情况下效果很好。然而,对于高维状态空间或连续状态空间,表格方法不再可行,因为所需的存储量会变得非常庞大。而Deep Q-Learning 通过使用深度神经网络,也就是Deep Q-Network作为函数逼近器来克服这一限制。
DQN 有以下2个关键技术点:
(1)经验回放(Experience Replay):DQN 使用经验回放缓冲区存储过去的经验(状态、动作、奖励、下一个状态),然后从中随机抽取一批数据来训练网络,这有助于打破数据的相关性,避免过度拟合最近的数据。
(2)目标网络(Target Network):DQN 使用两个神经网络,一个是主网络(或在线网络),用于决策;另一个是目标网络,用于计算目标 Q 值。目标网络的参数定期从主网络同步过来,这样做是为了让目标 Q 值的计算更加稳定,避免训练过程中的振荡。
03 问题描述
这是一个经典的强化学习案例,旨在让月球着陆器(Lunar Lander)通过算法自己学会如何安全地着陆到两面小旗中间的平台上。如下图所示:

04 算法中的概念及原理
先了解下动作空间(action space)和观察空间(obersevation space)的概念:什么是 Gym 中的观察空间(Observation Space)和动作空间(Action Space)?![]() https://zhuanlan.zhihu.com/p/658889348
https://zhuanlan.zhihu.com/p/658889348
着陆器的动作空间包括4个动作:
| 0:什么都不做 | 2:点火主引擎 |
| 1:点火左定向引擎 | 3:点火右定向引擎 |
着陆器的观察空间包括8个状态:
| x:着陆器的 x 坐标 | θ:着陆器的角度 |
| y:着陆器的 y坐标 | θ':着陆器的角速度 |
| x':着陆器在 x 方向的线速度 | l:着陆器的左腿是否与地面接触(布尔值) |
| y':着陆器在 y 方向的线速度 | r:着陆器的右腿是否与地面接触(布尔值) |
奖励 Rewards的设计:
每一步都会获得一个奖励。一个 episode(回合)总奖励是该 episode 中所有步骤的奖励之和。对于每一步,奖励如下:
着陆器离着陆点越近/远,奖励增加/减少;
着陆器移动越慢/快,奖励增加/减少;
着陆器倾斜度越大,奖励减少;
每个与地面接触的腿奖励增加10分;
每帧侧引擎点火,奖励减少0.03分;
每帧主引擎点火,奖励减少0.3分;
episode 因坠毁或安全着陆而额外获得-100或+100分的奖励。
如果一个 episode 得分至少为200分,则训练停止。
贝尔曼方程:
式中为动作-价值函数(action-value,Q函数), Q函数表示在给定状态
下,采取动作
后获得的期望累积回报。R为当前状态的奖励,γ为折扣因子,s'、a'表示下一个状态和动作。上式表示了agent在环境中总会选择奖励最大的动作,当执行动作次数足够多时(i→∞),Q就是最优解"Q(s,a;w)"。根据Q函数建立的神经网络称为“Q-network”,Q网络。
算法的核心:
算法中包含两个神经网络:一个是目标Q网络(target Q network)、另一个是主Q网络(Q network)。两个神经网络结构一样而参数不同,为“一前一后”关系,主Q网络更新快而目标Q网络更新慢。不断地训练“目标Q网络”与“主Q网络”,并通过控制两者间损失来可达到降低更新速度、增强稳定性的目的。每个回合结束计算两个Q之间的误差,如下:
每个回合结束agent会自动更新两个Q网络的参数,算法中为了agent表现稳定采用的“软更新”技术,如下式:
式中,为学习率,一般设置为非常小的值。
是目标Q网络的参数,
是主Q网络的参数。这样子,agent的目标Q网络的新参数
、也就是新经验中,有一大部分是基于之前回合的旧经验
而仅小部分来自最近一个回合学到的新经验
。
05 月球着陆器自动着陆的算法实现
(1)导包
import time
from collections import deque, namedtuple
import gymnasium as gym
#import gym
import numpy as np
import PIL.Image
import tensorflow as tf
import utils
from pyvirtualdisplay import Display
from pyglet.gl import gl
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Input
from tensorflow.keras.losses import MSE
from tensorflow.keras.optimizers import Adam(utils是吴恩达老师编写的计算模块,包括get_experiences、check_update_conditions、get_new_eps、get_action、update_target_network和plot_history等函数)
(2)设置超参数
# 为TensorFlow设置随机种子
tf.random.set_seed(utils.SEED)
# 设置超参数
MEMORY_SIZE = 100_000 # 设置经验缓冲区的大小
GAMMA = 0.995 # 折扣因子
ALPHA = 1e-3 # 学习率
NUM_STEPS_FOR_UPDATE = 4 # 每4步执行一次学习更新(3)模拟环境
# 加载月球模拟环境
env = gym.make('LunarLander-v2', render_mode='rgb_array')
# 设置初始状态
env.reset()
PIL.Image.fromarray(env.render())LunarLander-v2是gym中模拟月球表面的虚拟环境。初始状态为agent位于显示窗口的中心顶部位置。运行以上代码,结果如下:

(4)设置状态和动作
# 设置观察和动作变量
state_size = env.observation_space.shape
num_actions = env.action_space.n
# 获取初始状态
initial_state = env.reset()
# 选择第1个动作
action = 0
# step函数返回当前动作下的四个变量
next_state, reward, done, info, _= env.step(action)
print('State Shape:', state_size)
print('Number of actions:', num_actions)
with np.printoptions(formatter={'float': '{:.3f}'.format}):
print("Initial State:",initial_state)
print("Action:",action)
print("Next State:", next_state)
print("Reward Received:", reward)
print("Episode Terminated:", done)
print("Info:", info)运行以上代码,结果如下:

在Open AI的Gym环境中,使用.step()方法来运行环境动态的单个时间步。在我们使用的gym版本中,.step()方法接受一个动作并返回五个值(最后1个为空):
observation(object):在月球着陆器环境中,对应于包含着陆器位置和速度的numpy数组,即前面所说的观测空间的状态。
reward (float):采取特定行动所获得的奖励。在月球着陆器环境中,对应于前面描述的奖励。
done (bool):当done为True时,它表示回合结束,可以重置环境进行下一回合了。
Info (dictionary):用于调试的诊断信息。算法中并没有使用这个变量。
(5)神经网络
# 创建 主Q网络
q_network = Sequential([
Input(shape=state_size),
Dense(units=64,activation='relu', name='qL1'),
Dense(units=64,activation='relu', name='qL2'),
Dense(units=num_actions, name='qL3')
])
# 创建目标 Q网络
target_q_network = Sequential([
Input(shape=state_size),
Dense(units=64,activation='relu', name='tqL1'),
Dense(units=64,activation='relu', name='tqL2'),
Dense(units=num_actions, name='tqL3')
])
optimizer = Adam(learning_rate=ALPHA)(6)经验回放
# 将经验存储为命名元组
experience = namedtuple("Experience", field_names=["state", "action", "reward", "next_state", "done"]) (在Python中,namedtuple是collections模块中的一个函数,用于创建具有命名字段的小而简单的类。它非常适合用来创建只读的、轻量级的对象集合。Experience在这里被定义为一个namedtuple,用来存储智能体在环境中的经历,它有五个字段:state, action, reward, next_state, 和 done)
定义损失函数:
def compute_loss(experiences, gamma, q_network, target_q_network):
"""
损失函数
Args:
experiences: (tuple) 元组 ["state", "action", "reward", "next_state", "done"]
gamma: (float) 折扣因子.
q_network: (tf.keras.Sequential) 主Q网络,用于预测q_values
target_q_network: (tf.keras.Sequential) 目标Q网络,用于预测y_targets
Returns:
loss: (TensorFlow Tensor(shape=(0,), dtype=int32)) 返回目标Q网络和主Q网络之间的均方误差.
"""
# 返回经验
states, actions, rewards, next_states, done_vals = experiences
# 计算目标Q网络的最大值 max Q^(s,a)
max_qsa = tf.reduce_max(target_q_network(next_states), axis=-1)
# 贝尔曼方程计算目标Q网络的值
y_targets = rewards + gamma * max_qsa * (1 - done_vals)
# 获得主Q网络估计值 q_values
q_values = q_network(states)
q_values = tf.gather_nd(q_values, tf.stack([tf.range(q_values.shape[0]),
tf.cast(actions, tf.int32)], axis=1))
# 计算loss
loss = MSE(y_targets, q_values)
return loss(7)更新网络参数
@tf.function # 装饰器,可以将Python函数转换为TensorFlow图结构,函数中的所有操作都会在TensorFlow图中执行
def agent_learn(experiences, gamma):
"""
更新Q网络的权重参数.
Args:
experiences: (tuple) 元组["state", "action", "reward", "next_state", "done"]
gamma: (float) 折扣因子.
"""
# 计算损失函数
with tf.GradientTape() as tape:
loss = compute_loss(experiences, gamma, q_network, target_q_network)
# 计算梯度
gradients = tape.gradient(loss, q_network.trainable_variables)
# 更新主Q网络的权重参数
optimizer.apply_gradients(zip(gradients, q_network.trainable_variables))
# 更新目标Q网络的权重参数
utils.update_target_network(q_network, target_q_network)(8)训练智能体(agent)
start = time.time() # 开始计时
num_episodes = 2000 # 训练回合总数
max_num_timesteps = 1000 # 每个回合训练步数
total_point_history = []
num_p_av = 100 # number of total points to use for averaging
epsilon = 1.0 # ε-greedy策略的初始值
# 创建经验缓冲区
memory_buffer = deque(maxlen=MEMORY_SIZE)
# target Q network的初始权重参数设置为与Q-Network相同
target_q_network.set_weights(q_network.get_weights())
for i in range(num_episodes):
# 每个回合开始时,重设环境得到初始状态
state = env.reset()[0]
total_points = 0
for t in range(max_num_timesteps):
# 使用ε-greedy策略,在当前状态s选择一个动作a
state_qn = np.expand_dims(state, axis=0)
q_values = q_network(state_qn)
action = utils.get_action(q_values, epsilon)
# 计算采取当前动作a可得到的奖励r,及下个状态s'
next_state, reward, done, info, _ = env.step(action)
# 储存经验元组 (S,A,R,S')至经验缓冲区
memory_buffer.append(experience(state, action, reward, next_state, done))
# 通过当前步数和缓冲区数据量判别是否达到更新条件
update = utils.check_update_conditions(t, NUM_STEPS_FOR_UPDATE, memory_buffer)
if update:
# 随机选取经验样本
experiences = utils.get_experiences(memory_buffer)
# 梯度下降法更新网络参数
agent_learn(experiences, GAMMA)
state = next_state.copy()
total_points += reward
if done:
break
total_point_history.append(total_points)
av_latest_points = np.mean(total_point_history[-num_p_av:])
# 更新ε
epsilon = utils.get_new_eps(epsilon)
print(f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}", end="")
if (i+1) % num_p_av == 0:
print(f"\rEpisode {i+1} | Total point average of the last {num_p_av} episodes: {av_latest_points:.2f}")
# 如果最近100个回合的平均分超过200分,停止训练
if av_latest_points >= 200.0:
print(f"\n\nEnvironment solved in {i+1} episodes!")
q_network.save('lunar_lander_model.keras')
break
tot_time = time.time() - start
print(f"\nTotal Runtime: {tot_time:.2f} s ({(tot_time/60):.2f} min)")
# Plot the point history
utils.plot_history(total_point_history)运行以上代码,结果如下:
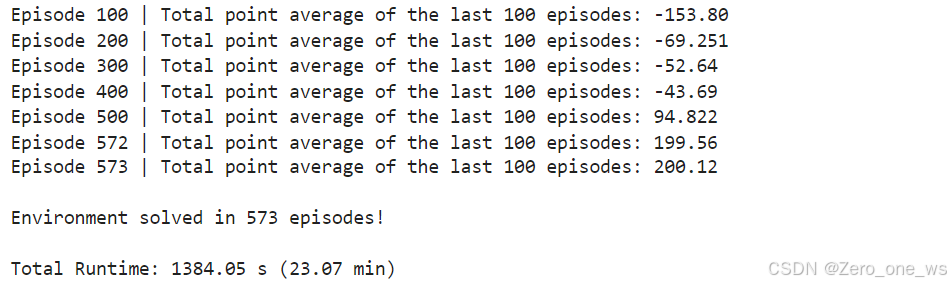

(9)训练过程保存为视频
import logging
import imageio
import base64
import IPython
logging.getLogger().setLevel(logging.ERROR)
def create_video(filename, env, q_network, fps=30):
with imageio.get_writer(filename) as video:
done = False
state = env.reset()[0]
frame = env.render()
#frame = env.render(mode="rgb_array")
video.append_data(frame)
while not done:
state = np.expand_dims(state, axis=0)
q_values = q_network(state)
action = np.argmax(q_values.numpy()[0])
state, _, done, _, _ = env.step(action)
frame = env.render()
frame = PIL.Image.fromarray(frame)
video.append_data(frame)
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="840" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
filename = "./videos/lunar_lander.mp4"
create_video(filename, env, q_network)
embed_mp4(filename)最后一步,我这里保存视频失败,生成的视频打不开,哪位大佬知道原因的可以在评论区解答下!
06 拓展:基于pytorch实现月球着陆器着陆
由于拿到吴恩达老师课程的代码后,折腾几天都跑不通,终于能跑了又不能生成视频,就先找了个大神的pytorch代码跑了下,可以正常训练和保存视频,基于tensorflow和pytorch的步骤都是一样的。链接放在下面:
【机器学习】强化学习(六)-DQN(Deep Q-Learning)训练月球着陆器示例-CSDN博客![]() https://blog.csdn.net/cxyhjl/article/details/135812771
https://blog.csdn.net/cxyhjl/article/details/135812771
07 总结
(1)强化学习的高级之处在于:只需给定目标、设置好奖励机制,agent就可以自主学习完成任务,特斯拉最新的Optimus机器人身上就采用了强化学习。
(2)强化学习实现着陆器着陆月球的主要内容包括:超参数、虚拟环境、两个Q神经网络、经验重放缓冲区、epsilon贪婪策略、软更新、训练agent,前6块内容柔和进了最后一步“训练agent”中,强化学习中很重要的奖励设置本文没有涉及,因为lunar lander的奖励机制在采用的env.step()方法中.。



















![FIND_IN_SET使用案例--[sql语句根据多ids筛选出对应数据]](https://i-blog.csdnimg.cn/direct/1e4b5dac32c1494c904ed47b8070ffba.png)