相关概念
TF-IDF
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于资讯检索与文本挖掘的常用加权技术。TF-IDF是一种统计方法,用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF
tf(term frequency:指的是某一个给定的词语在该文件中出现的次数,这个数字通常会被归一化(一般是词频除以该文件总词数),以防止它偏向长的文件。

IDF
idf (inverse document frequency):反应了一个词在所有文本(整个文档)中出现的频率,如果一个词在很多的文本中出现,那么它的idf值应该低,而反过来如果一个词在比较少的文本中出现,那么它的idf值应该高。
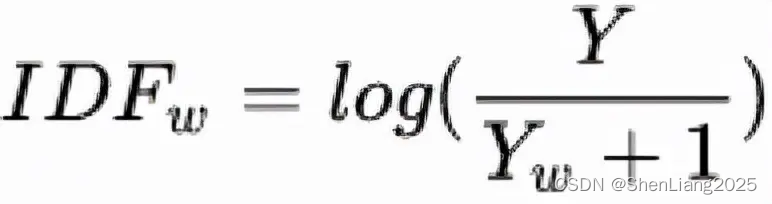
N
N代表文档的总数。
W
W是某个单词在几个文档里出现过,同一一个文档出行多次,计为1。
代码示例
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
# 定义更复杂的文档集
complex_documents = [
"The quick brown fox jumps over the lazy dog.",
"The brown fox is quick and the brown dog is lazy.",
"The sky is blue and beautiful.",
"Look at the bright blue sky!",
"The quick brown dog jumps over the lazy fox."
]
# 创建TF-IDF模型
complex_vectorizer = TfidfVectorizer(smooth_idf=True)
#将文档转换为TF-IDF矩阵
complex_tfidf_matrix = complex_vectorizer.fit_transform(complex_documents)
#print(complex_tfidf_matrix)
#获取特征名称
feature_names = complex_vectorizer.get_feature_names_out()
#将TF-IDF矩阵转换为DataFrame
complex_tfidf_df = pd.DataFrame(complex_tfidf_matrix.toarray(), columns=feature_names)
#打印 TF-IDF矩阵
#print(complex_tfidf_df)
#TF-IDF矩阵保存成csv文件
complex_tfidf_df.to_csv('./output/complex_tfidf_matrix.csv', index=True)计算过程详解
原始文档见下:
The quick brown fox jumps over the lazy dog
The brown fox is quick and the brown dog is lazy
The sky is blue and beautiful
Look at the bright blue sky
The quick brown dog jumps over the lazy fox
确定N
不难看出文档总共有5份,所以这里的N为5.
确定W
我们以“Look at the bright blue sky”为例来演示:
这句话里每个单词在该文档里都是唯一的,所以每个单词的TF = 1/6。
计算每个单词的IDF值
以单词blue为例,它总共在两个文档里出现,所以W=2,所以其IDF=ln((1+5)/(1+2))+1,其它以此类推。
| 单词 | IDF值 |
| look | ln((1+5)/(1+1))+1=2.0986122886681096913952452369225 |
| at | ln((1+5)/(1+1))+1=2.0986122886681096913952452369225 |
| the | ln((1+5)/(1+5))+1 = 1 |
| bright | ln((1+5)/(1+1))+1=2.0986122886681096913952452369225 |
| blue | ln((1+5)/(1+2))+1 = 1.69314718055994530941723212145818 |
| sky | ln((1+5)/(1+2))+1 = 1.69314718055994530941723212145818 |
计算每个单词的TF-IDF值
即上述每个单元格*(1/6)
| 单词 | tfidf值 |
| look | 0.34976871477801824 |
| at | 0.34976871477801824 |
| the | 0.16666666666666666 |
| bright | 0.34976871477801824 |
| blue | 0.2821911967599909 |
| sky | 0.2821911967599909 |
TF-IDF值进行归一化
计算这组单词TF-IDF的平方根
(0.34976871477801824**2 + 0.34976871477801824**2 + 0.16666666666666666**2 + 0.34976871477801824**2 + 0.2821911967599909**2+ 0.2821911967599909**2)**0.5
= 0.7443493684741389
生成最终TF-IDF值
| 单词 | 归一化后TFIDF值 |
| look | 0.34976871477801824/0.7443493684741389=0.4698985847130068 |
| at | 0.34976871477801824/0.7443493684741389=0.4698985847130068 |
| the | 0.16666666666666666/0.7443493684741389=0.22390919335139758 |
| bright | 0.34976871477801824/0.7443493684741389=0.4698985847130068 |
| blue | 0.2821911967599909/0.7443493684741389=0.3791112194243705 |
| sky | 0.2821911967599909/0.7443493684741389=0.3791112194243705 |
对比sklearn里的结果