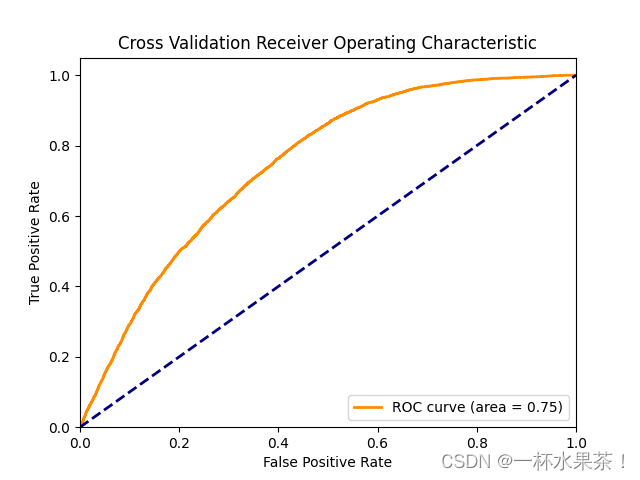
目录
- 1. 时间序列
- 2. word embedding
- 2.1 one hot
- 2.2 word2vec
- 2.3 GloVe
1. 时间序列
具有时间相关性的序列叫做时间序列,比如:语音、文本句子
2. word embedding
2.1 one hot
针对句子来说,可以用[seq_len, vector_len]
有多少个单词vector_len就是多少,比如汉字有3500个,句子长度是5,那么就表示为[5, 3500]
如下图:
vector index 0为1表示Rome, index 1为1表示Pairs,其他位置都为0

one hot编码的问题是:比较稀疏,数据长度可能比较长,但是有用的数据比较少。比如:英文常用单词有2-4w个,那么这种方式就很难用了。
2.2 word2vec
利用语言相关性,相近或者相反
如下图:
king 与kings最相近,值也就越大,这个值是通过两个单词向量的cos夹角计算的(角越大值越小)
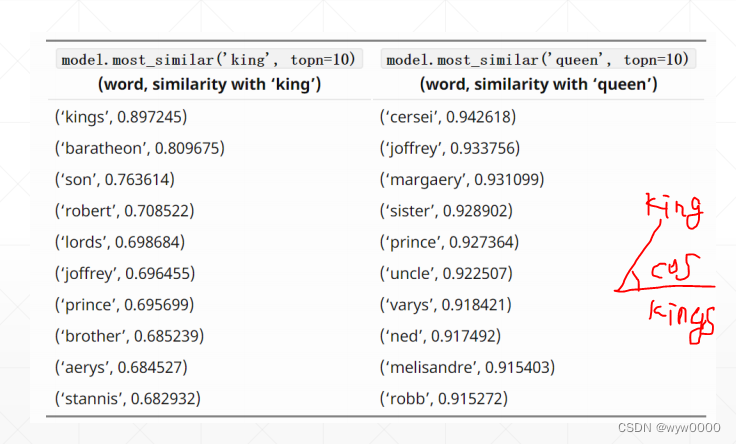
2.3 GloVe
下图是自己建立一个单词向量表,有两个单词索引是0和1,然后使用torch.nn.Embedding(2, 5)生成单词向量表,即2个单词,每个单词用5个dimension vector表示。

torch.nn.Embedding(2, 5)生成的词向量表,采用随机值进行初始化,这种随机值初始化后的向量值,并不能反映特定单词与单词之间的余弦距离以及不同单词之间的相关性。而且还需要根据特定的文本对其进行训练,以符合特定业务场景的需求。
Glove是预定义的,他人已经根据大量的文本数据训练好的数据集,可以直接使用,一般不需要自己修改。
glove使用见下图: