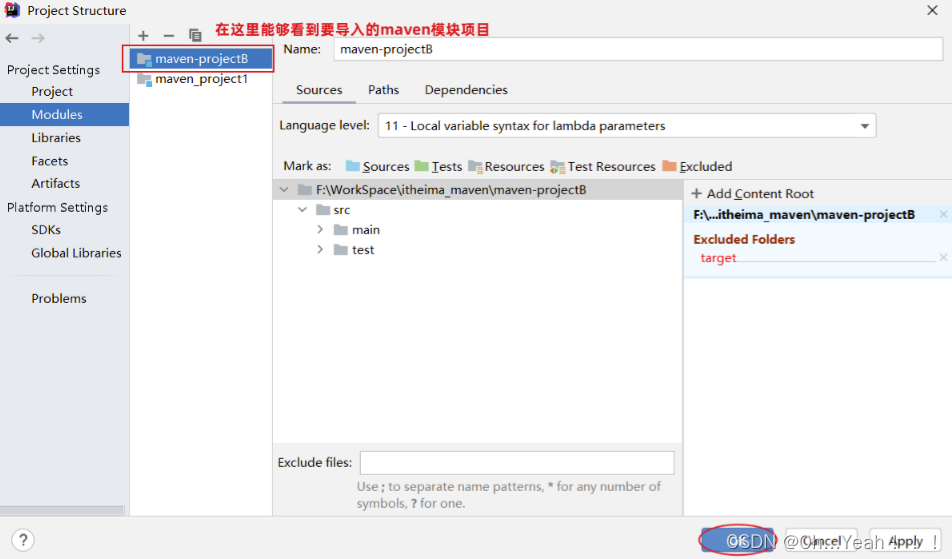
前期准备:
npm puppeteer
import puppeteer from 'puppeteer';
puppeteer文档
第一步:启动浏览器,跳转到需要爬取的页面
const browser = await puppeteer.launch({ headless: false });
const page = await browser.newPage();
await page.goto(url, { waitUntil: 'networkidle2' });第二步:打开需要爬取的网页,按“F12”查看前端的dom,查看我们想获取的文本信息的父级类名,例如:

第三步,通常列表页面都有下拉刷新,我们需要写一个脚本让页面下拉刷新
我要爬取的页面下拉到一定的地步后会有一个“加载更多”按钮,需要点击,直到页面无法滚动,且没有加载更多按钮的时候停止,脚本参考如下:
// 定义滚动函数
const scrollPage = async () => {
const distance = 100000; // 每次滚动的距离
const delay = 2000; // 每次滚动后的延迟
let previousHeight = await page.evaluate('document.body.scrollHeight');
while (true) {
await page.evaluate(`window.scrollBy(0, ${distance})`);
await new Promise(resolve => setTimeout(resolve, delay));
const newHeight = await page.evaluate('document.body.scrollHeight');
if (newHeight === previousHeight) {
const loadMoreButton = await page.$('.类名1.类名2');//锁定“加载更多按钮”
if (loadMoreButton) {
await loadMoreButton.click();
console.log('点击加载更多结果按钮');
await new Promise(resolve => setTimeout(resolve, delay)); // 等待加载更多内容
} else {
console.log('已滚动到底部,没有更多内容加载');
break;
}
}
previousHeight = newHeight;
}
};
await scrollPage();第四步,封装成对象并打印
第三步的脚本让我们把页面加载到拥有全部数据的状态,现在需要将第二步收集的类名里的文本封装成数组
await page.waitForSelector('.卡片父级类名', { timeout: 60000 });//卡片最外层
const info= await page.evaluate(() => {
const cardElements = document.querySelectorAll('.卡片父级类名');//获取所有卡片
const arr= [];
cardElements.forEach(hotel => {
const nameElement = hotel.querySelector('[需要的元素1的属性]');
const priceElement = hotel.querySelector('[需要的元素2的属性]');
const name = nameElement ? nameElement.innerText.trim() : null;
const price = priceElement ? priceElement.innerText.trim() : null;
if (name || price) {
arr.push({ name, price });
}
});
return arr;
});
console.log(JSON.stringify(info, null, 2))
// 完事关闭浏览器
await browser.close();运行