使用香橙派AIpro做目标检测
文章目录
- 使用香橙派AIpro做目标检测
- 香橙派AIpro开发板介绍
- 香橙派AIpro应用体验
- 识别图像
- 识别视频
- 摄像头
- 香橙派AIpro AI应用场景
- 总结
香橙派AIpro开发板介绍
OrangePi AIpro(8-12T)是一款集成昇腾AI技术的开发板,搭载4核64位CPU和AI处理器,配备图形GPU,提供8-12TOPS的AI计算能力。它支持8GB或16GB LPDDR4X内存,并可扩展至不同容量的eMMC模块。该开发板具备双4K视频输出能力。
接口方面,OrangePi AIpro提供了丰富的选项,包括双HDMI、GPIO、Type-C电源、M.2插槽(兼容SATA/NVMe SSD)、TF卡槽、千兆以太网、USB3.0、USB Type-C、Micro USB(串口功能)、MIPI摄像头和显示屏接口,以及电池接口预留。
该开发板适用于AI计算、深度学习、视频分析、自然语言处理、智能机器人、无人机、云计算、AR/VR、智能安防和家居等多个AIoT领域。支持Ubuntu和openEuler操作系统,适合AI算法原型和应用开发。
我们再来看看开发板的样貌
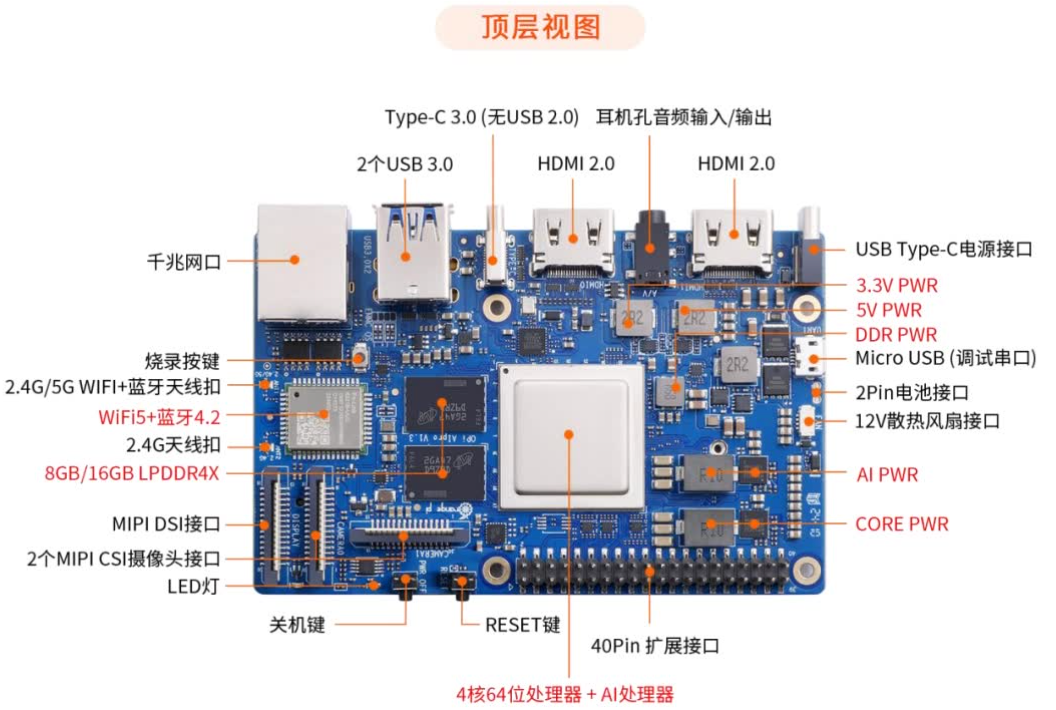
关于更多香橙派AIpro的信息,阔以到官网一探究竟
香橙派AIpro官网
香橙派AIpro应用体验
OK,我们现在开始体验
准备工作
- 开发板和数据线(这个购买时会有)
- HDMI转接口和显示幕(如果要可视化界面的话)
- 网线(可以通过共享网络的方式)
我们看下我收到的开发板长什么样子吧

1、插上电源后,我们的屏幕上就会出现登录界面
2、我们输入账户和密码(账户会给你默认写好)
注意📢
默认账户名:HwHiAiUser
默认密码:Mind@123
输入后我们就可以进入桌面
3、我们可以点击右上角连接WiFi
4、然后我们就可以开始体验了
香橙派AIpro支持多种编程语言和软件开发环境,比如Python、 Jupyter、C等,这使得开发者可以根据自己的需求选择适合的操作系统和开发工具~
我这里体验了下香橙派AIpro的AI支持功能
识别图像
我们采用YOLOv5s目标检测算法来实现识别正在的跑操人
我们按照以下几个步骤来处理
- 加载模型
- 处理输入图像
- 执行检测
- 绘制检测结果和显示或保存结果
这里我给出参考代码,大家可以根据自己的需求做修改
def load_model(weights_path, device_id):
"""加载模型并返回模型对象"""
device = select_device(device_id)
model = attempt_load(weights_path, map_location=device)
return model
def process_image(img, model, names, img_size, stride):
"""处理图像,进行目标检测,并返回标记后的图像"""
img = torch.from_numpy(img).to(device).float() / 255.0
img = img.unsqueeze(0) # 增加批次维度
pred = model(img)[0]
pred = non_max_suppression(pred, 0.4, 0.5, classes=None, agnostic=False)
annotated_img = img.copy() # 复制原始图像以进行标注
for *xyxy, conf, cls in reversed(pred): # 遍历检测结果
label = f'{names[int(cls)]} {conf:.2f}'
plot_one_box(xyxy, annotated_img, label=label, color=(255, 0, 0), line_thickness=3)
return annotated_img
def plot_one_box(xyxy, img, label, color, line_thickness):
"""在图像上绘制检测框和标签"""
x1, y1, x2, y2 = xyxy
cv2.rectangle(img, (x1, y1), (x2, y2), color, line_thickness)
cv2.putText(img, label, (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, line_thickness)
def main(weights_path, source_path, device_id='cpu'):
"""主函数,用于加载模型、处理视频或图像流,并显示结果"""
model = load_model(weights_path, device_id)
stride = int(model.stride.max())
imgsz = check_img_size(640, s=stride)
names = model.module.names if hasattr(model, 'module') else model.names
dataset = LoadStreams(source_path, img_size=imgsz, stride=stride)
for path, img, im0s, vid_cap in dataset:
try:
annotated_img = process_image(img, model, names, imgsz, stride)
cv2.imshow('Object Detection', annotated_img)
cv2.waitKey(1) # 1ms延迟
except Exception as e:
print(f"Error processing frame {path}: {e}")
cv2.destroyAllWindows()
if __name__ == '__main__':
# 替换为你的模型权重文件路径和视频或图像文件路径
weights_path = 'path_to_your_yolov5s_weights.pt'
source_path = 'path_to_your_video_or_image'
main(weights_path, source_path)
我这里先放一张原图

稍等片刻,运行结果就出来了

我们会发现其实框选住的人并不多
导致的原因可能是
- 置信度阈值设置得太高
- 模型训练数据不足
- 非极大值抑制
- 等等
有这个问题的可以参考下面的代码片段尝试解决
# 原始的non_max_suppression调用
pred = non_max_suppression(pred, conf_thres=0.5, iou_thres=0.4, classes=None, agnostic=False)
# 调整置信度阈值和NMS阈值
conf_thres = 0.3 # 降低置信度阈值
iou_thres = 0.3 # 降低NMS阈值
pred = non_max_suppression(pred, conf_thres=conf_thres, iou_thres=iou_thres, classes=None, agnostic=False)
经过微调后,效果就明显了很多

识别视频
使用YOLOv5s算法识别视频中正在打篮球的人
我们按照下面的步骤来处理
- 加载YOLOv5s模型
- 读取视频流
- 处理视频帧
- 绘制检测框
- 显示或保存结果
这里我给出参考代码,大家可以根据自己的需求做修改
# 函数定义
def detect(frame, model, names, img_size, device):
# 模型输入处理
img = torch.from_numpy(cv2.resize(frame, (img_size, img_size))).to(device).float() # 调整大小并转换为模型需要的格式
img /= 255.0 # 归一化
img = img.unsqueeze(0) # 增加批次维度
# 模型推理
pred = model(img)[0]
pred = non_max_suppression(pred, 0.4, 0.5) # 应用NMS
# 绘制检测框
for det in pred:
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], frame.shape).round() # 将坐标映射回原图
for *xyxy, conf, cls in reversed(det):
label = f"{names[int(cls)]} {conf:.2f}"
cv2.rectangle(frame, (int(xyxy[0]), int(xyxy[1])), (int(xyxy[2]), int(xyxy[3])), (255, 0, 0), 2)
cv2.putText(frame, label, (int(xyxy[0]), int(xyxy[1])), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (255, 0, 0), 2)
# 主函数
def main(weights, source, img_size=640, conf_thres=0.4, iou_thres=0.5):
# 加载模型
device = select_device('')
model = attempt_load(weights, map_location=device) # 加载模型
names = model.module.names if hasattr(model, 'module') else model.names # 获取类别名称
# 检查图像大小
img_size = check_img_size(img_size, s=model.stride.max()) # 确保图像大小符合模型要求
# 读取视频
cap = LoadStreams(source, img_size=img_size)
# 处理视频帧
while cap.isOpened():
frame = cap.read()
if frame is None:
break
detect(frame, model, names, img_size, device)
# 显示结果
cv2.imshow('YOLOv5s Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 按'q'退出
break
cap.release()
cv2.destroyAllWindows()
# 入口点
if __name__ == '__main__':
# 替换为你的模型权重文件路径和视频源
weights = 'yolov5s.pt'
source = 0
main(weights, source)
程序会处理单帧图像,进行目标检测然后绘制检测框,返回标注后的图像

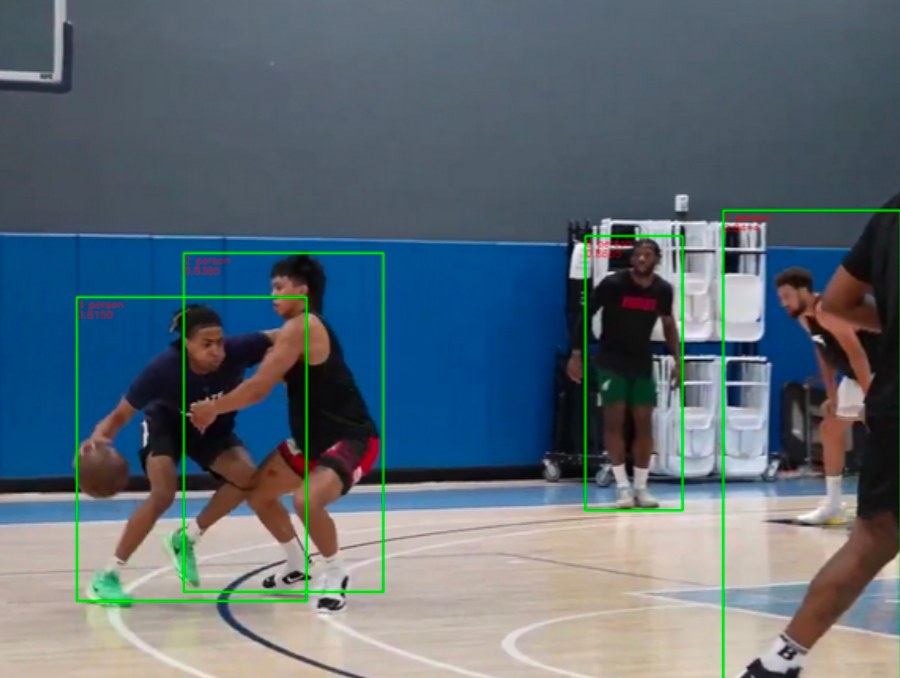
摄像头
还可以通过摄像头录入的画面进行实时处理,由于我这里暂时没有摄像头,就没有进行演示了,我这里可以给出代码参考参考
def detect_frame(frame, model, img_size, device, names):
# 调整图像大小并转换为模型需要的格式
frame = cv2.resize(frame, (img_size, img_size))
img = torch.from_numpy(frame).to(device).float() # 转换为模型需要的格式
img /= 255.0 # 归一化
img = img.unsqueeze(0) # 增加批次维度
# 模型推理
with torch.no_grad():
pred = model(img)[0]
pred = non_max_suppression(pred, 0.4, 0.5) # 应用NMS
# 绘制检测框
for det in pred:
x1, y1, x2, y2, conf, cls = det.cpu()
label = f"{names[int(cls)]} {conf:.2f}"
plot_one_box(frame, x1, y1, x2, y2, label, color=(255, 0, 0), line_thickness=2)
def plot_one_box(frame, x1, y1, x2, y2, label, color, line_thickness):
"""在图像上绘制检测框和标签"""
cv2.rectangle(frame, (x1, y1), (x2, y2), color, line_thickness)
cv2.putText(frame, label, (x1, y1 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.5, color, line_thickness)
def main(weights, img_size=640, source=0):
# 加载模型
device = select_device('')
model = attempt_load(weights, map_location=device).eval()
names = model.module.names if hasattr(model, 'module') else model.names
# 检查图像大小
img_size = check_img_size(img_size)
# 读取视频流
cap = cv2.VideoCapture(source)
while True:
ret, frame = cap.read()
if not ret:
break
detect_frame(frame, model, img_size, device, names)
# 显示结果
cv2.imshow('YOLOv5s Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'): # 按'q'退出
break
cap.release()
cv2.destroyAllWindows()
if __name__ == '__main__':
weights = 'yolov5s.pt'
main(weights)
香橙派AIpro AI应用场景
香橙派AIpro开发板因其集成的华为Ascend系列AI处理器和强大的计算能力,适用于多种AI应用场景
目标检测:使用如YOLOv5s这样的轻量级网络模型,可以在边缘设备上进行实时目标检测,适用于智能监控、工业自动化等领域
图像分类:AIpro可以部署图像分类模型,用于场景识别、物体识别等任务,这在内容审核、社交媒体分析等方面有广泛应用
视频图像分析:在视频流分析中,AIpro可以进行实时视频处理,用于人流统计、行为识别等,适用于零售分析、公共安全等场景
深度学习模型推理:AIpro支持深度学习模型的快速推理,适用于需要快速响应的AI应用,如自动驾驶辅助系统、机器人视觉等
总结
能够较快运行处结果得益于香橙派AIpro集成的软件环境,其中包括Python编程语言、Jupyter Notebook等交互式开发工具,以及功能强大的OpenCV图像处理库,这些工具的集成为深度学习模型的构建和实施提供了坚实的基础。同时,香橙派AIpro配备了高性能的处理器,这确保了其在处理复杂算法和处理大量数据时的优越计算能力,进而显著提高了目标检测任务的执行效率
特别值得一提的是,香橙派AIpro拥有详尽的国产中文文档支持,大大降低了学习和使用的门槛,使得国内开发者能够更加顺畅地进行项目开发。而且,系统的图形化界面设计美观,提升了用户体验。