class Hobby ( Base) :
__tablename__ = 'hobby'
id = Column( Integer, primary_key= True )
caption = Column( String( 50 ) , default= '篮球' )
def __str__ ( self) :
return self. caption
class Person ( Base) :
__tablename__ = 'person'
nid = Column( Integer, primary_key= True )
name = Column( String( 32 ) , index= True , nullable= True )
hobby_id = Column( Integer, ForeignKey( "hobby.id" ) )
hobby = relationship( 'Hobby' , backref= 'pers' )
def __str__ ( self) :
return self. name
def __repr__ ( self) :
return self. name
from models import Person, Hobby
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:1234@127.0.0.1:3306/sqlalchemy001?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
from sqlalchemy. orm import Session
session= Session( engine)
if __name__ == '__main__' :
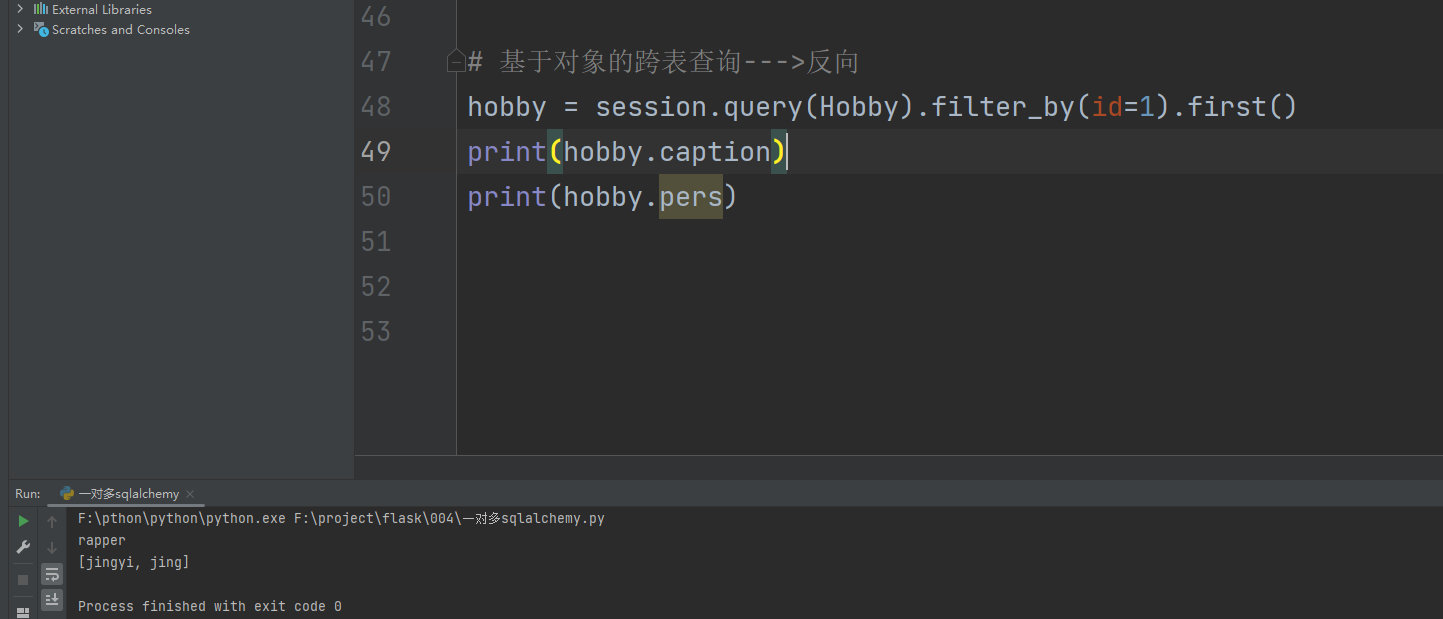
hobby = session. query( Hobby) . filter_by( id = 1 ) . first( )
print ( hobby. caption)
print ( hobby. pers)
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index
import datetime
from sqlalchemy. orm import DeclarativeBase, relationship
class Base ( DeclarativeBase) :
pass
class User ( Base) :
__tablename__ = 'user'
id = Column( Integer, primary_key= True , autoincrement= True )
name = Column( String( 32 ) , index= True , nullable= False )
email = Column( String( 32 ) , unique= True )
ctime = Column( DateTime, default= datetime. datetime. now)
extra = Column( Text, nullable= True )
def __repr__ ( self) :
return f"<User(name= { self. name} , email= { self. email} )>" class Hobby ( Base) :
__tablename__ = 'hobby'
id = Column( Integer, primary_key= True )
caption = Column( String( 50 ) , default= '篮球' )
def __str__ ( self) :
return self. caption
class Person ( Base) :
__tablename__ = 'person'
nid = Column( Integer, primary_key= True )
name = Column( String( 32 ) , index= True , nullable= True )
hobby_id = Column( Integer, ForeignKey( "hobby.id" ) )
hobby = relationship( 'Hobby' , backref= 'pers' )
def __str__ ( self) :
return self. name
def __repr__ ( self) :
return self. name
if __name__ == '__main__' :
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
Base. metadata. create_all( engine)
from models import Person, Hobby
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
from sqlalchemy. orm import Session
session = Session( engine)
res1 = Hobby( caption= 'rapper' )
session. add( res1)
person = Person( name= 'jingyi' , hobby_id= 1 )
session. add( person)
session. commit( )
session. close( )
person = Person( name= 'jingyi' , hobby= Hobby( caption= '乒乓球' ) )
session. add( person)
session. commit( )
hobby= session. query( Hobby) . filter_by( id = 1 ) . first( )
person = Person( name= 'jing' , hobby= hobby)
session. add( person)
session. commit( )
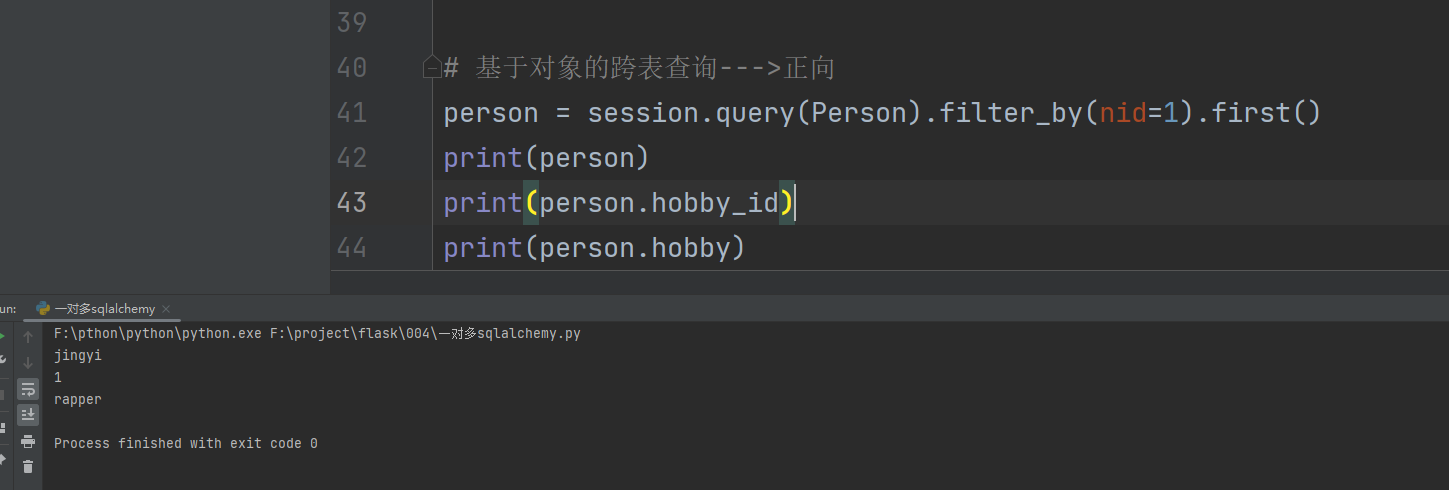
person = session. query( Person) . filter_by( nid= 1 ) . first( )
print ( person)
print ( person. hobby_id)
print ( person. hobby)
hobby = session. query( Hobby) . filter_by( id = 1 ) . first( )
print ( hobby. caption)
print ( hobby. pers)
from sqlalchemy import Column, Integer, String, Text, ForeignKey, DateTime, UniqueConstraint, Index, Table
import datetime
from sqlalchemy. orm import DeclarativeBase, relationship
class Base ( DeclarativeBase) :
pass
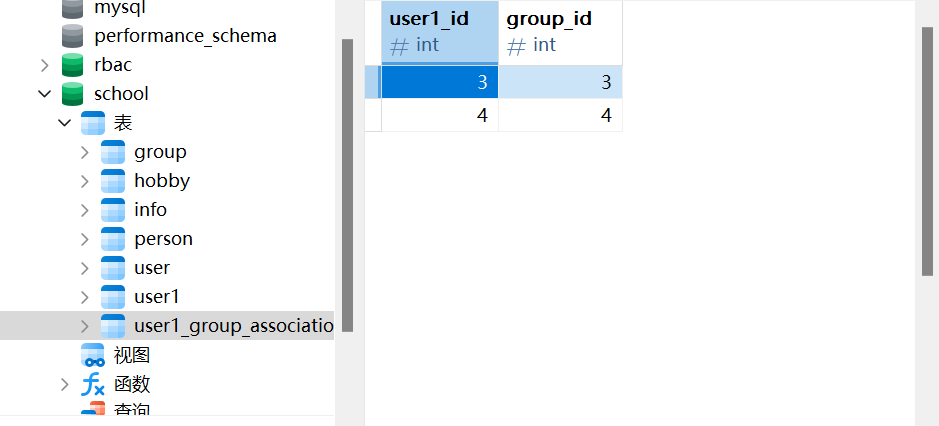
association_table = Table( 'user1_group_association' , Base. metadata,
Column( 'user1_id' , Integer, ForeignKey( 'user1.id' ) ) ,
Column( 'group_id' , Integer, ForeignKey( 'group.id' ) ) ,
UniqueConstraint( 'user1_id' , 'group_id' )
)
class User1 ( Base) :
__tablename__ = 'user1'
id = Column( Integer, primary_key= True )
name = Column( String( 32 ) , index= True , nullable= False )
groups = relationship( "Group" , secondary= association_table, backref= "users" )
class Group ( Base) :
__tablename__ = 'group'
id = Column( Integer, primary_key= True )
name = Column( String( 32 ) , index= True , nullable= False )
if __name__ == '__main__' :
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
Base. metadata. create_all( engine)
from modelss import User1, Group
from sqlalchemy import create_engine
engine = create_engine(
"mysql+pymysql://root:123123@127.0.0.1:3306/school?charset=utf8" ,
max_overflow= 0 ,
pool_size= 5 ,
pool_timeout= 30 ,
pool_recycle= - 1
)
from sqlalchemy. orm import Session
session = Session( engine)
group1 = Group( name= '5A风景区' )
group2 = Group( name= '大清败家子慈溪' )
res1 = User1( name= '刘亦菲' )
res2 = User1( name= '赵敏' )
res1. groups. append( group1)
res2. groups. append( group2)
session. add_all( [ res1, res2] )
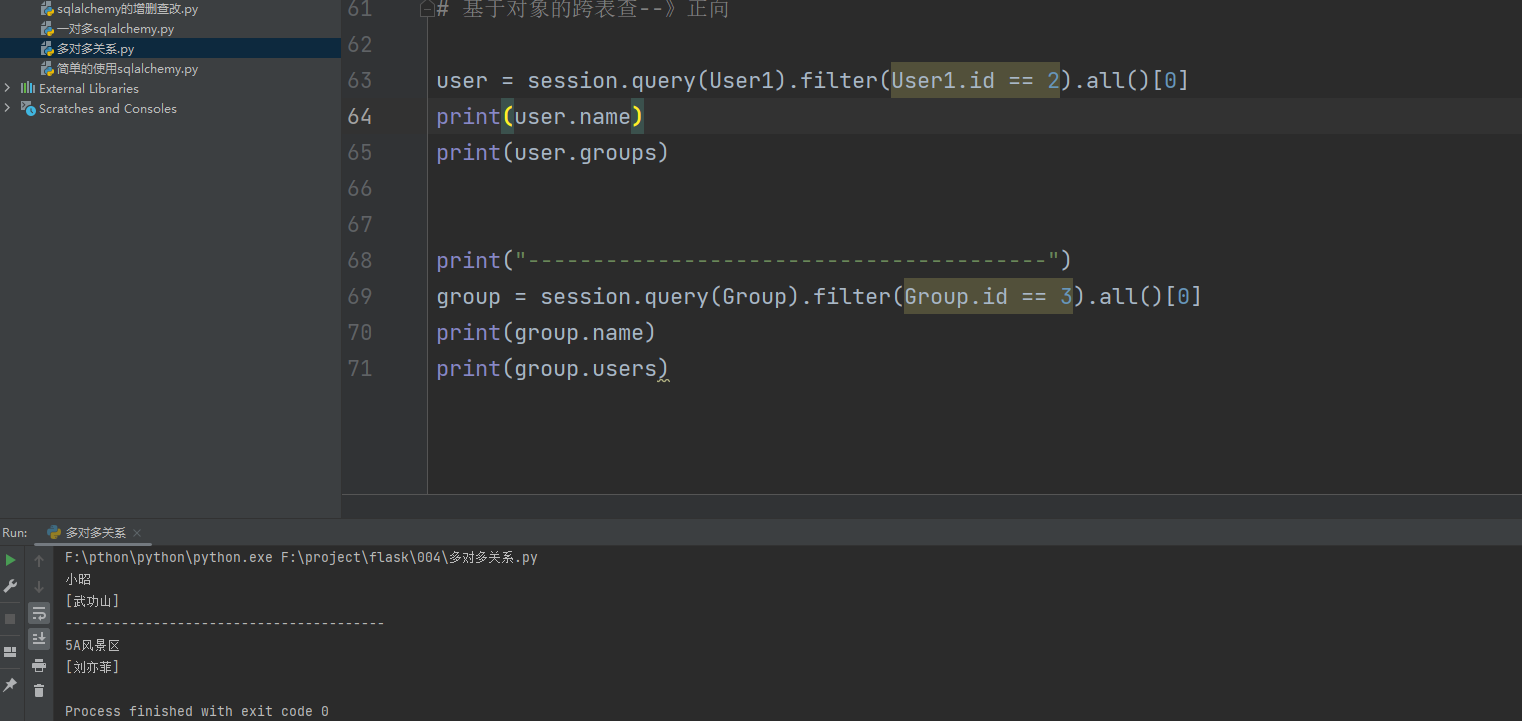
user = session. query( User1) . filter ( User1. id == 3 ) . all ( ) [ 0 ]
print ( user. name)
print ( user. groups)
session. commit( )
session. close( )
user = session. query( User1) . filter ( User1. id == 2 ) . all ( ) [ 0 ]
print ( user. name)
print ( user. groups)
group = session. query( Group) . filter ( Group. id == 3 ) . all ( ) [ 0 ]
print ( group. name)
print ( group. users)
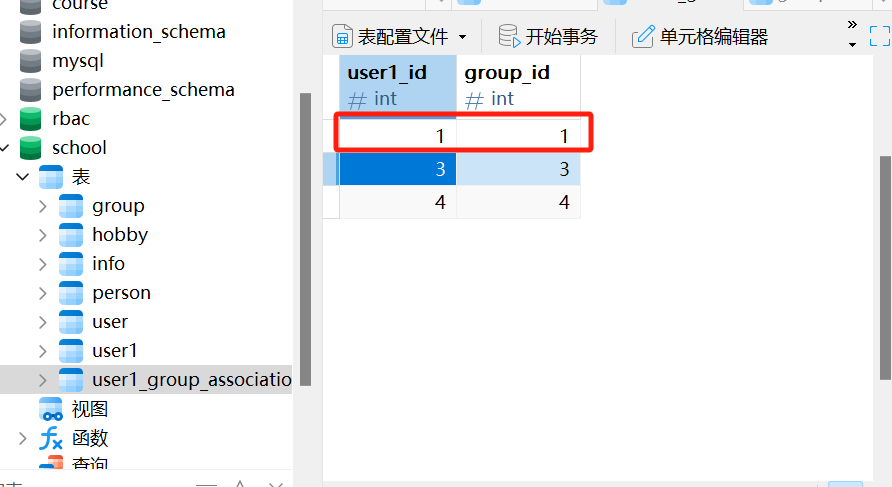
user1 = session. query( User1) . filter_by( id = 2 ) . first( )
if user1 is None :
print ( "用户不存在" )
else :
group_id = 2
group_to_add = session. query( Group) . filter_by( id = group_id) . first( )
if group_to_add is None :
print ( "组不存在" )
else :
user1. groups. append( group_to_add)
session. commit( )
print ( "关联已添加" )
session. close( )
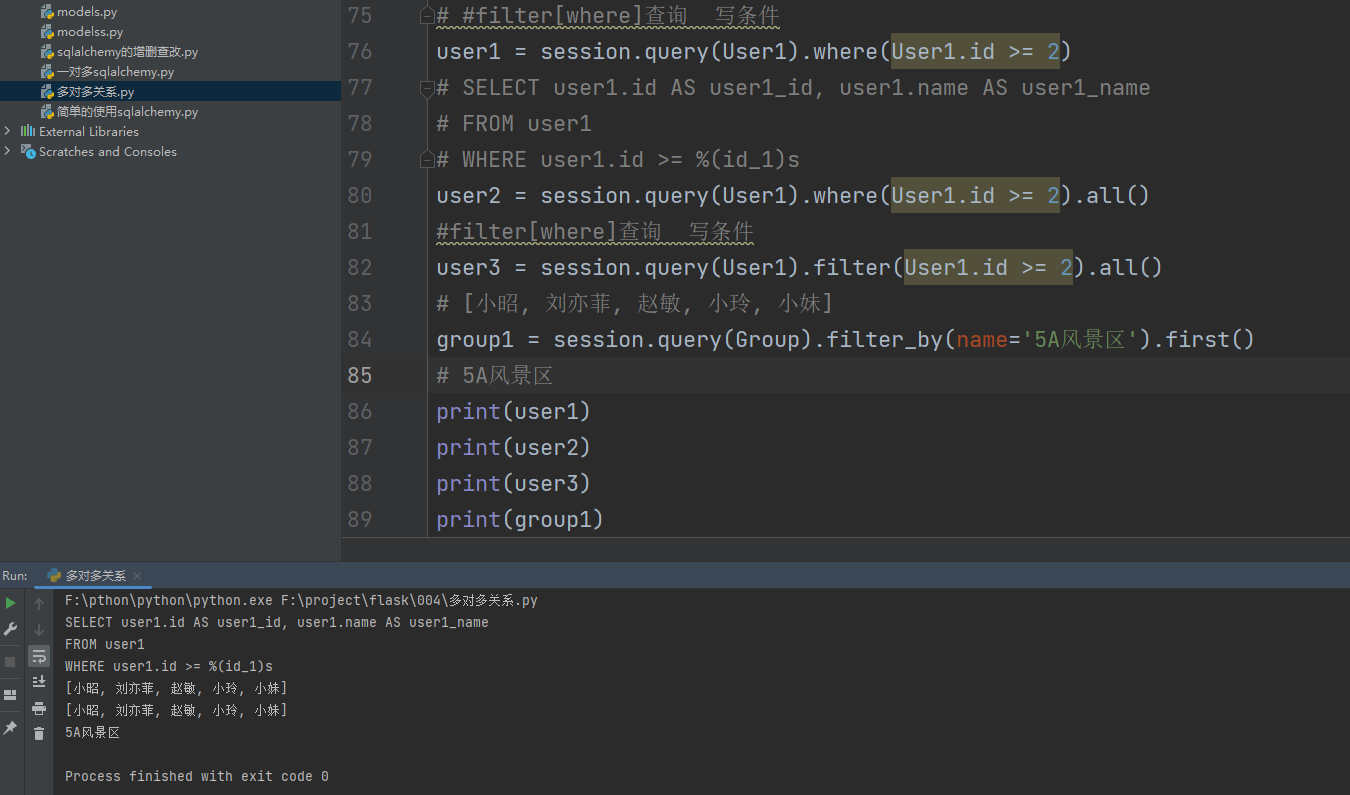
user1 = session. query( User1) . where( User1. id >= 2 )
user2 = session. query( User1) . where( User1. id >= 2 ) . all ( )
user3 = session. query( User1) . filter ( User1. id >= 2 ) . all ( )
group1 = session. query( Group) . filter_by( name= '5A风景区' ) . first( )
print ( user1)
print ( user2)
print ( user3)
print ( group1)
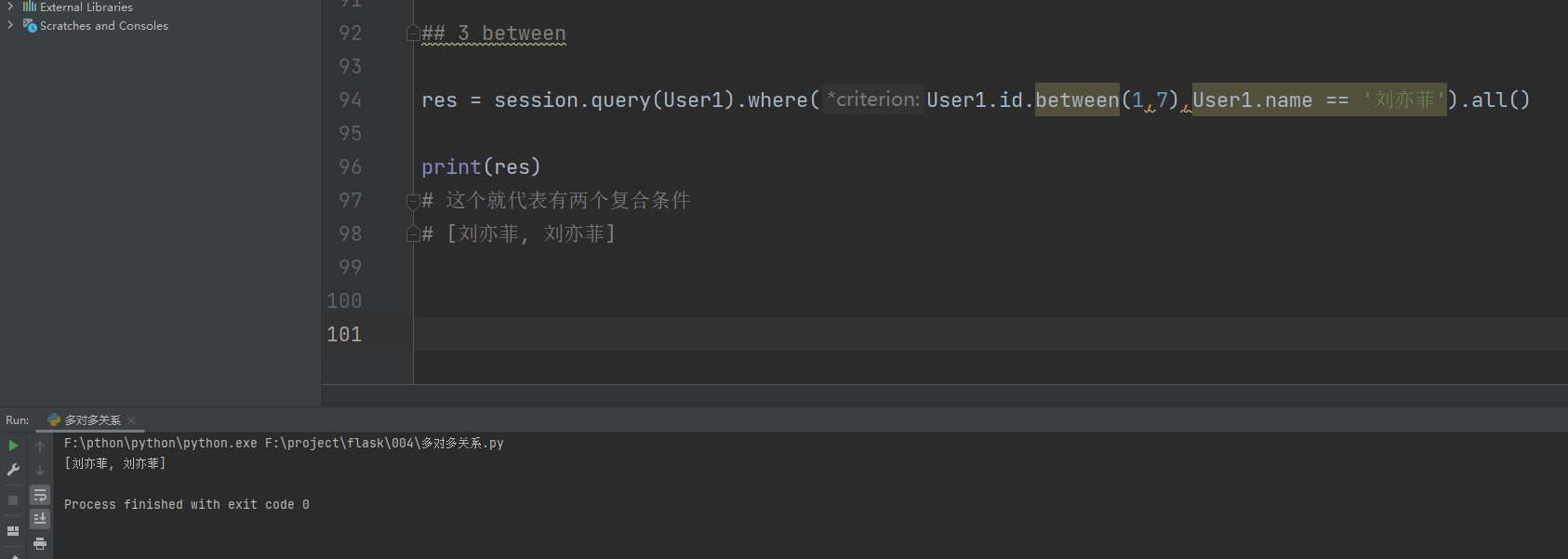
res = session. query( User1) . where( User1. id . between( 1 , 7 ) , User1. name == '刘亦菲' ) . all ( )
print ( res)
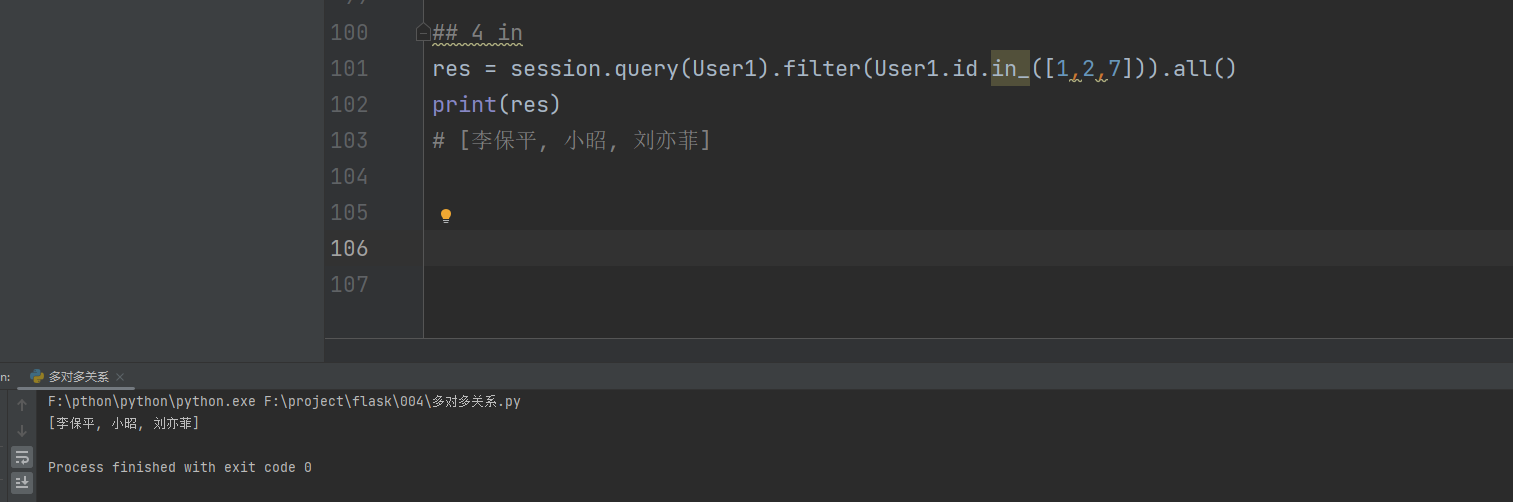
res = session. query( User1) . filter ( User1. id . in_( [ 1 , 2 , 7 ] ) ) . all ( )
print ( res)
res = session. query( User1) . filter ( ~ User1. id . in_( [ 3 , 4 ] ) , User1. name== '刘亦菲' ) . all ( )
print ( res)
session. query( User1) . filter ( User1. id . in_( session. query( Group. id ) . filter_by( name= '刘亦菲' ) ) ) . all ( )
from sqlalchemy import and_, or_
res1 = session. query( User1) . filter ( and_( User1. id > 1 , User1. name == '刘亦菲' ) ) . all ( )
res2 = session. query( User1) . filter ( or_( User1. id >= 3 , User1. name == '刘亦菲' ) ) . all ( )
print ( res1)
print ( res2)
res1 = session. query( User1) . filter ( User1. name. like( '小%' ) ) . all ( )
res2 = session. query( User1) . filter ( ~ User1. name. like( '小%' ) ) . all ( )
res3 = session. query( User1) . filter ( ~ User1. name. like( '小%' ) )
print ( res1)
print ( res2)
print ( res3)
res1 = session. query( User1) [ 5 : 9 ]
res2 = session. query( User1) [ 0 : 4 ]
print ( res1)
print ( res2)
res = session. query( User1) . order_by( User1. name. asc( ) ) . all ( )
print ( res)
res = session. query( User1) . order_by( User1. name. desc( ) , User1. id . asc( ) ) . all ( )
print ( res)
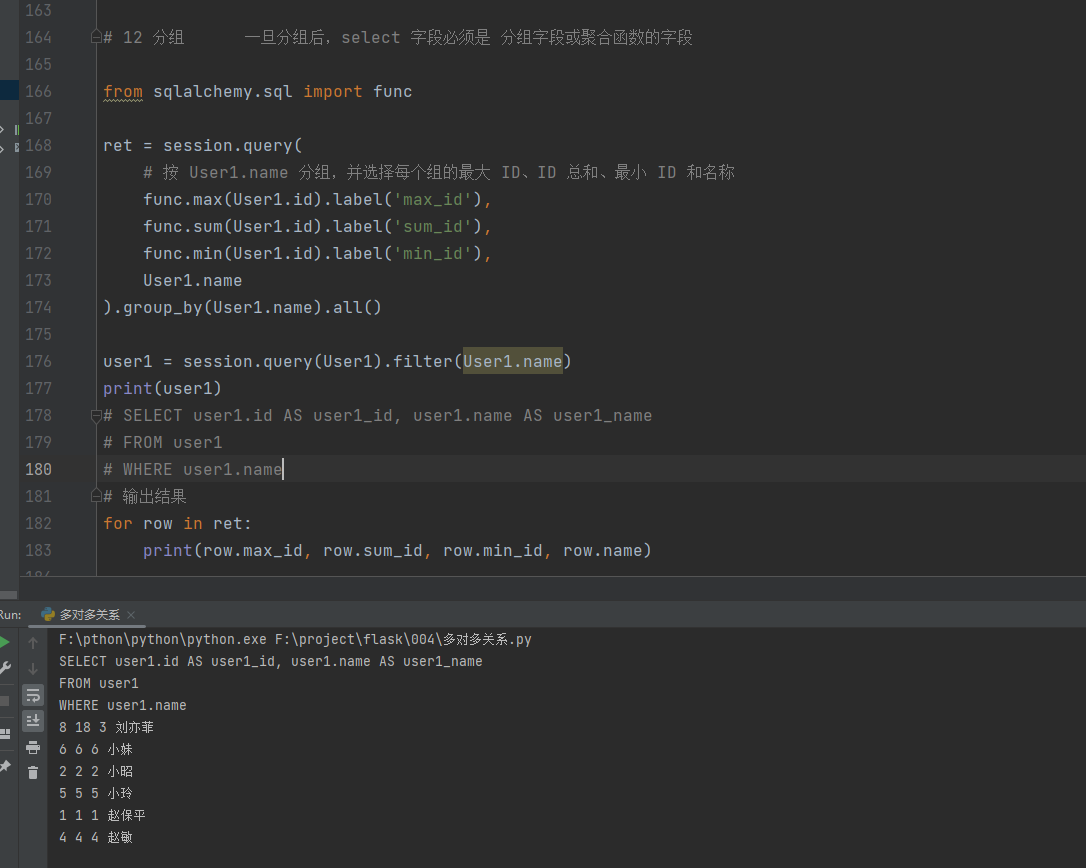
from sqlalchemy. sql import func
ret = session. query(
func. max ( User1. id ) . label( 'max_id' ) ,
func. sum ( User1. id ) . label( 'sum_id' ) ,
func. min ( User1. id ) . label( 'min_id' ) ,
User1. name
) . group_by( User1. name) . all ( )
user1 = session. query( User1) . filter ( User1. name)
print ( user1)
for row in ret:
print ( row. max_id, row. sum_id, row. min_id, row. name)
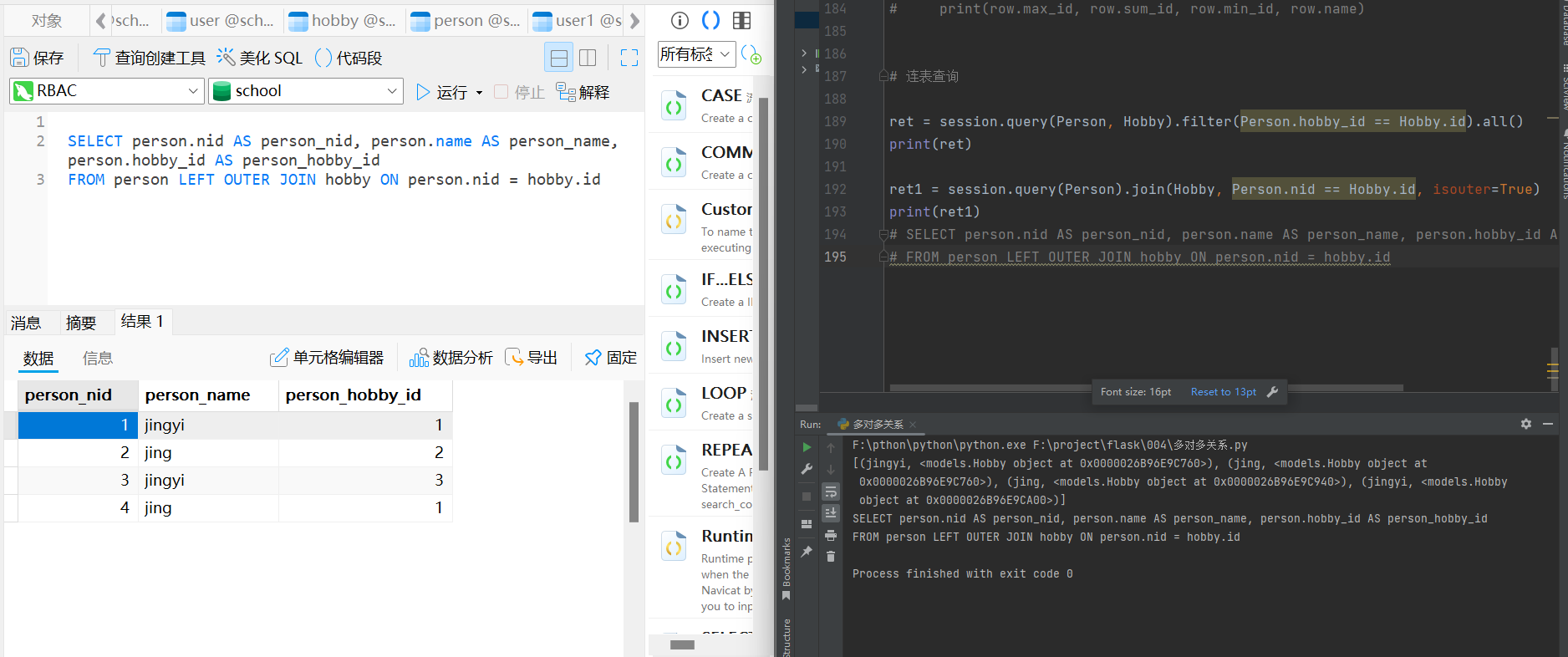
ret = session. query( Person, Hobby) . filter ( Person. hobby_id == Hobby. id ) . all ( )
print ( ret)
ret1 = session. query( Person) . join( Hobby, Person. nid == Hobby. id , isouter= True )
print ( ret1)









![【BUUCTF-PWN】7-[第五空间2019 决赛]PWN5](https://i-blog.csdnimg.cn/direct/fae5708be3dc49ff9957efef258c59c2.png)