背景介绍
传统的视觉问答(Visual Question Answering, VQA)基准测试主要集中在简单计数、视觉属性和物体检测等问题上,这些问题不需要超出图像内容的推理或知识。然而,在knowledge-based VQA中,仅靠图像无法回答给定的问题,还需要有效利用外部知识资源。
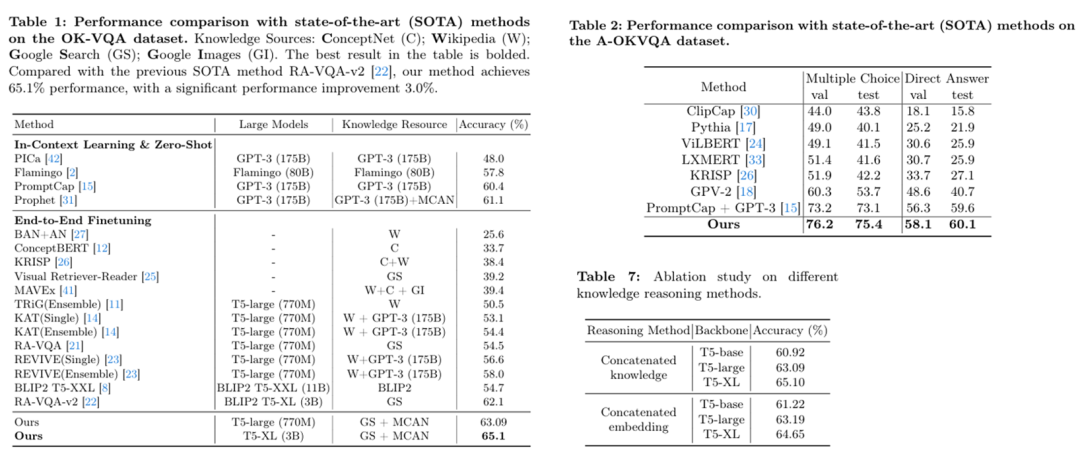
经典的知识基础VQA数据集包括OK-VQA和A-OKVQA。OK-VQA包含约14K个样本,分为9K/5K用于训练和测试,涵盖以下类别:车辆和交通;品牌、公司和产品;物品、材料和服装;体育和娱乐;烹饪和食品;地理、历史、语言和文化;人和日常生活;植物和动物;科学和技术;天气和气候。每个样本包括一个问题、一个相关图像和5个工作者标注的自由形式正确答案。A-OKVQA是OK-VQA的增强版本,包含24,903个问题,分为17.1K/1.1K/6.7K用于训练、验证和测试。与其他数据集相比,A-OKVQA中的问题不能通过简单查询知识库来回答。对于每个问题,A-OKVQA提供四选一的答案选项、10个工作者标注的自由形式的正确答案以及3个得到正确答案的理由。下图为OK-VQA样本的示例。

现有的knowledge-based VQA方法主要分为四类:利用知识库中显式知识的方法,利用大语言模型(LLM)中隐式知识的方法,知识库和LLM相结合的方法,以及让多模态大模型直接回答的方法。
基于知识库的方法
REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory
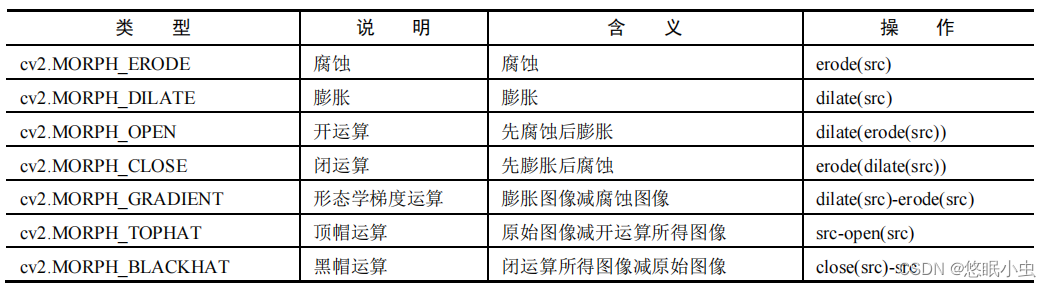
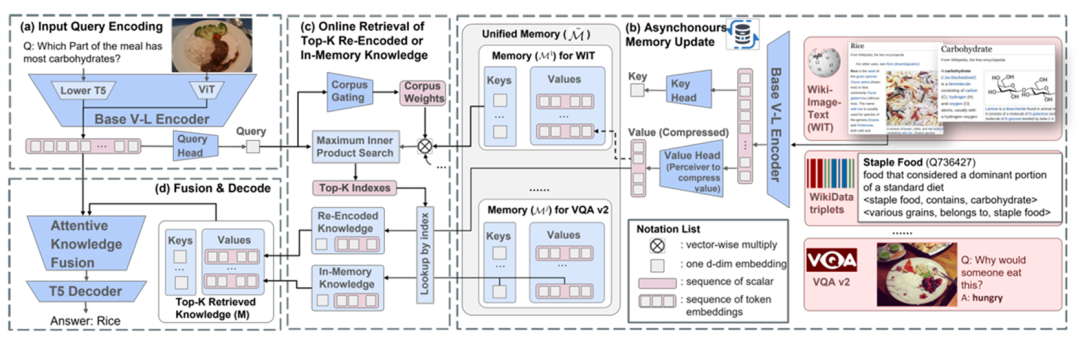
REVEAL模型通过将知识编码到大规模存储器中,并从中检索知识来回答VQA问题。其整体工作流程包括四个主要步骤:
Query Embedding部分:将问题-图像对编码为token embedding序列和一个汇总的query embedding。
Memory部分:将来自不同知识库的知识条目编码为键值对,其中key用于索引,使用与query embedding相同的编码器,value包含知识条目的完整信息。在预训练阶段,每1000个训练步骤异步更新整个memory。
Retriever部分:从不同的知识源中检索top-K相似知识条目。为了支持模型端到端训练,从头开始对其中10%检索到的知识条目进行重新编码,将重新编码的知识条目与memory中的知识条目串联,构建出最终的top-K知识条目的键/值对。
Generator部分:将query embedding和检索到的K个value embedding串联起来,使用注意力融合模块将retriever得分作为计算跨知识注意力的先验,最终生成文本输出,实现记忆、编码器、检索器和生成器的端到端联合训练。
REVEAL模型通过soft VQA accuracy metric评估生成的答案,即:
如果数据集中至少有3个标注者的答案与模型生成的答案相同,则该答案被视为100%准确。在比较之前,所有答案均转换成小写,数字转换为阿拉伯数字,并删除标点符号和冠词。在OK-VQA数据集上,该方法的准确率达到了59.1%,而在A-OKVQA数据集上,准确率达到了52.2%。

基于LLM的方法
A Simple Baseline for Knowledge-Based Visual Question Answering
传统的显性知识检索侧重于图像与知识条目之间的语义匹配,但这种方法难以获得隐性的常识性知识,而这些知识可以在LLM中找到。该方法旨在利用LLM中的隐式知识,通过少量的上下文学习实现问题的推理。
具体实现步骤如下:
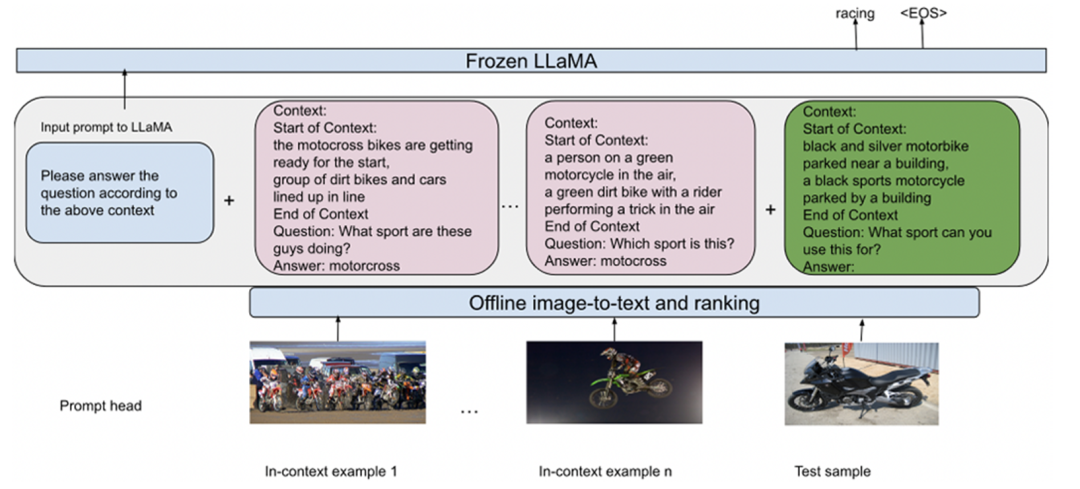
生成视觉上下文:使用Plug-and-Play VQA (PNPVQA)框架生成问题为导向的图像描述。对于每个图像-问题对生成50个视觉上下文,并根据视觉上下文与图像之间的余弦相似度选出最相似的前m个视觉上下文。
示例选择:计算问题-图像对与所有示例中问题-图像对的相似度,将问题文本相似度与图像相似度进行平均,取相似度最高的n个样本作为示例。
构建Prompt:将提示头、n个相似度最高的示例(包含视觉上下文、问题和对应的答案)和VQA输入(包含视觉上下文和问题)连接起来,作为输入LLM的prompt。
多查询集合:给定一个VQA问题,使用k*n个示例,生成k个prompt输入LLM,从而获得k个答案,从中选出出现次数最多的答案作为最终答案。
在OK-VQA数据集上,该方法的准确率达到了61.2%,而在A-OKVQA数据集上,验证集准确率达到了58.6%,测试集准确率则达到了57.5%。
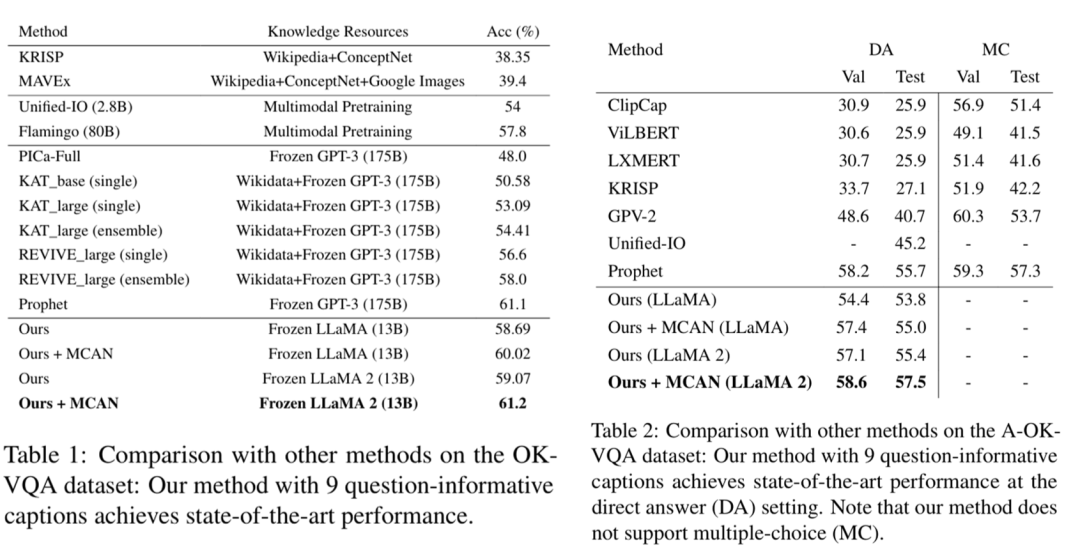
知识库和LLM相结合的方法
REVIVE: Regional Visual Representation Matters in Knowledge-Based Visual Question Answering
该方法利用图像的区域特征进行知识库中显式知识和LLM中隐式知识的检索,并根据区域特征和检索到的知识生成最终答案。
具体包含下面几个部分:
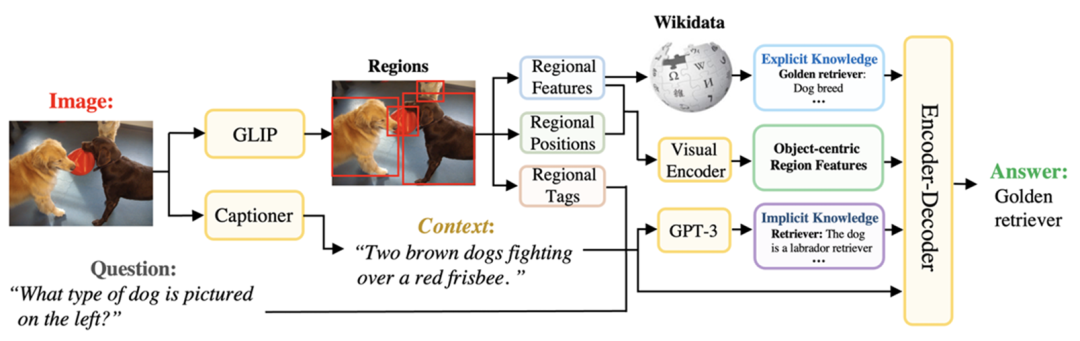
区域特征抽取模块:模型使用文本提示“检测:人、自行车、汽车……、牙刷”等MSCOCO数据集中所有对象类别,进行图像的目标检测,生成区域提案。在预先构建的标签集中,选择与区域特征相似度最高的标签作为区域标签。此外,模型引入了位置信息,并通过Captioner描述主要对象之间的关系,提供更多上下文。
以对象为中心的知识检索模块:
-
显式区域知识:基于Wikidata构建外部知识库Q,每个条目由实体和相应的描述组成,格式化为“{entity} is a {description}”,并检索与所有区域提案最相关的K个条目,作为显式知识。
-
带有区域描述的隐式知识:使用prompt“context: {caption}+{tags}. question: {question}”并利用GPT-3生成多个候选答案,再用prompt“{question} {answer candidate}. This is because”获取每个候选答案的解释。
Encoder-Decoder模块:
-
知识Encoder:对于检索到的显式知识,格式化输入为“entity: {entity} description: {description}”,对于隐式知识,格式化为“candidate: {answer} evidence: {explanation}”然后进行编码。
-
区域视觉Encoder:根据区域提案的视觉embedding和位置参数计算区域特征。
-
问题Encoder:将VQA问题格式化为“context: {caption}+{tags}. question: {question}”,并进行编码。
-
将编码后的知识、区域特征和VQA问题串联起来进行解码,生成最终答案。
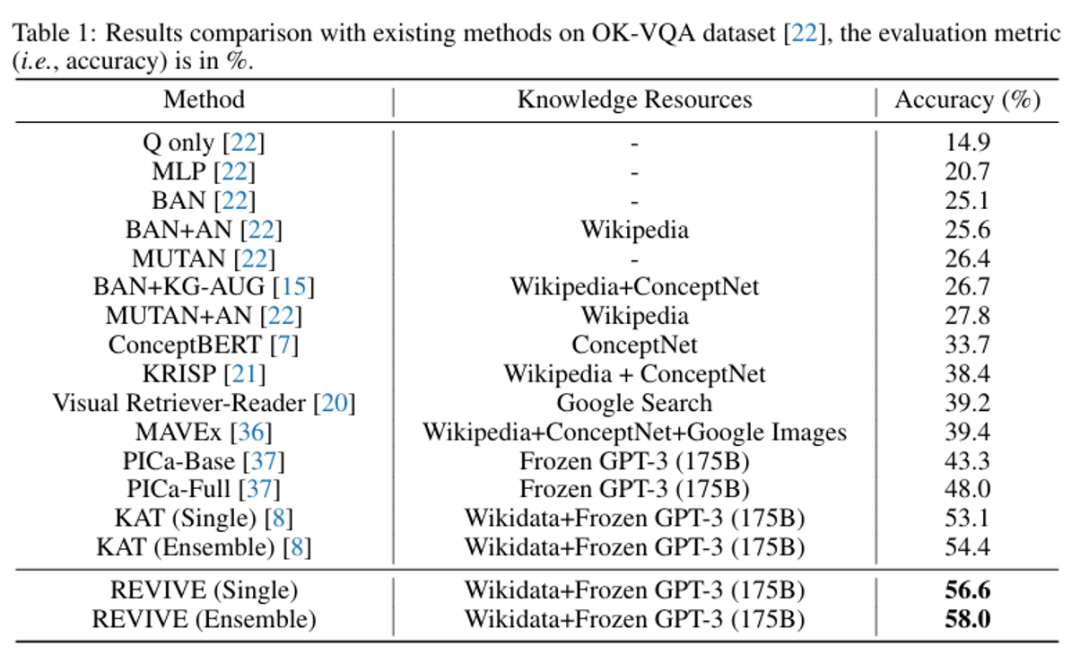
在实验中,该工作训练了三个不同初始化种子的模型,从这些模型生成的结果中选择频率最高的结果作为每个样本的最终答案预测值,并使用soft VQA accuracy metric评估生成的答案。下图展示了该方法在OK-VQA数据集上的表现,准确率达到了58%.
Knowledge Condensation and Reasoning for Knowledge-based VQA
传统模型直接使用检索到的知识段落生成答案,尽管有效,但这些段落包含很多无关信息和干扰信息。为了提升回答准确性,该方法通过知识浓缩模型将冗长的知识段落浓缩成精炼的知识概念和知识精华,将知识概念和知识精华以及其他隐含知识整合到知识推理模型中,以预测最终答案。
该模型主要由知识检索、知识浓缩模型和知识推理模型组成。
知识检索:利用Google Search Corpus(GSP)作为OK-VQA的外部知识库,Wikidata作为A-OKVQA的外部知识库。将图像转化为由描述、对象、属性和OCR组成的原始文本,并采用DPR作为知识检索器,从知识库中索引出Top-K相关的知识段落。
知识浓缩模型:知识浓缩模型包括VLM和LLM部分。
-
VLM部分:给定图像、问题和知识段落,以问题答案为标准,训练模型生成知识段落对应的具体知识概念(通常为一两个词)。
-
LLM部分:使用captioner获取样本中每张图片的视觉上下文,以图像的视觉上下文,问题文本和知识段落作为prompt,生成每个知识段落对应的的知识精华(通常为一句话),并预测问题的答案。
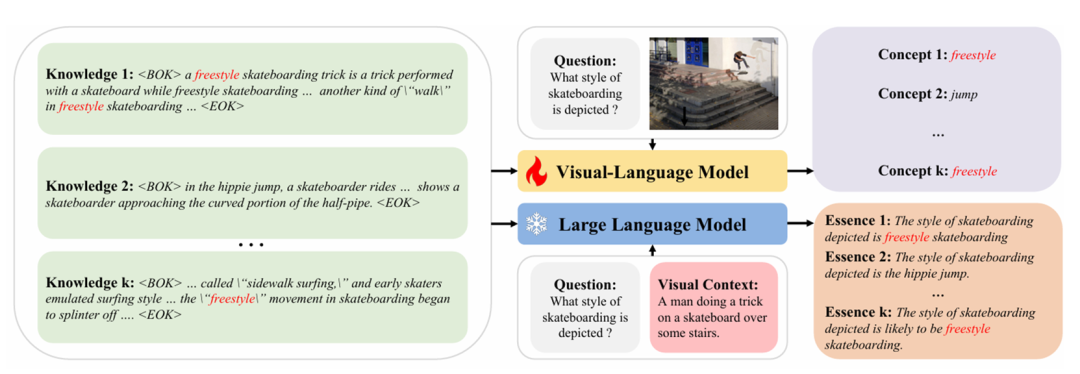
知识推理模型:结合根据图像生成的视觉上下文、问题文本、知识概念、知识精华和内隐知识(已有的VQA模型MCAN的输出),尝试两种方法推理出最终答案:
-
串联知识:将视觉上下文、问题文本、知识概念、知识精华和内隐知识串联成一个句子,编码-解码生成最终答案。
-
串联embedding:将视觉上下文、问题和不同类型的知识分别串联成句子,将编码得到的embedding合并起来,解码生成最终答案。
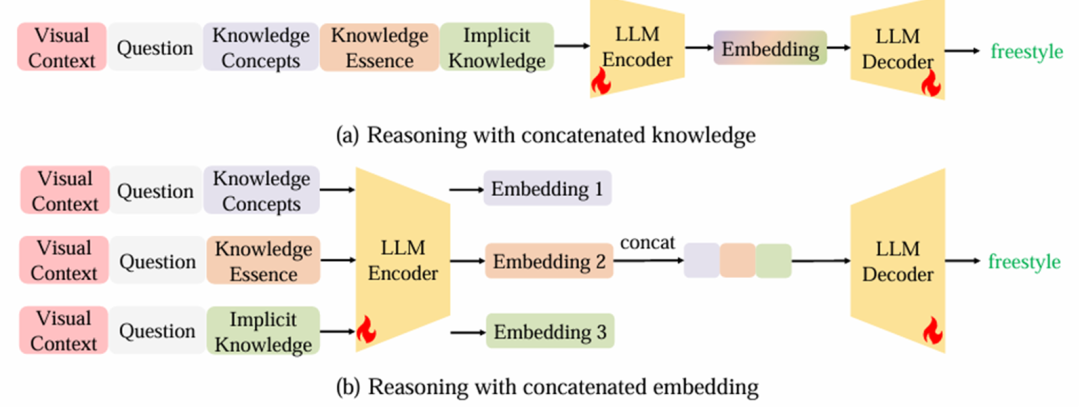
该模型使用soft VQA accuracy metric评估生成的答案,评估过程中,发现知识推理模型以T5-XL作为backbone,使用串联知识的方法表现最佳。在OK-VQA数据集上,该方法达到了65.1%的准确率,而在A-OKVQA数据集上则达到了60.1%的准确率。
多模态大模型
A Comprehensive Evaluation of GPT-4V on Knowledge-Intensive Visual Question Answering
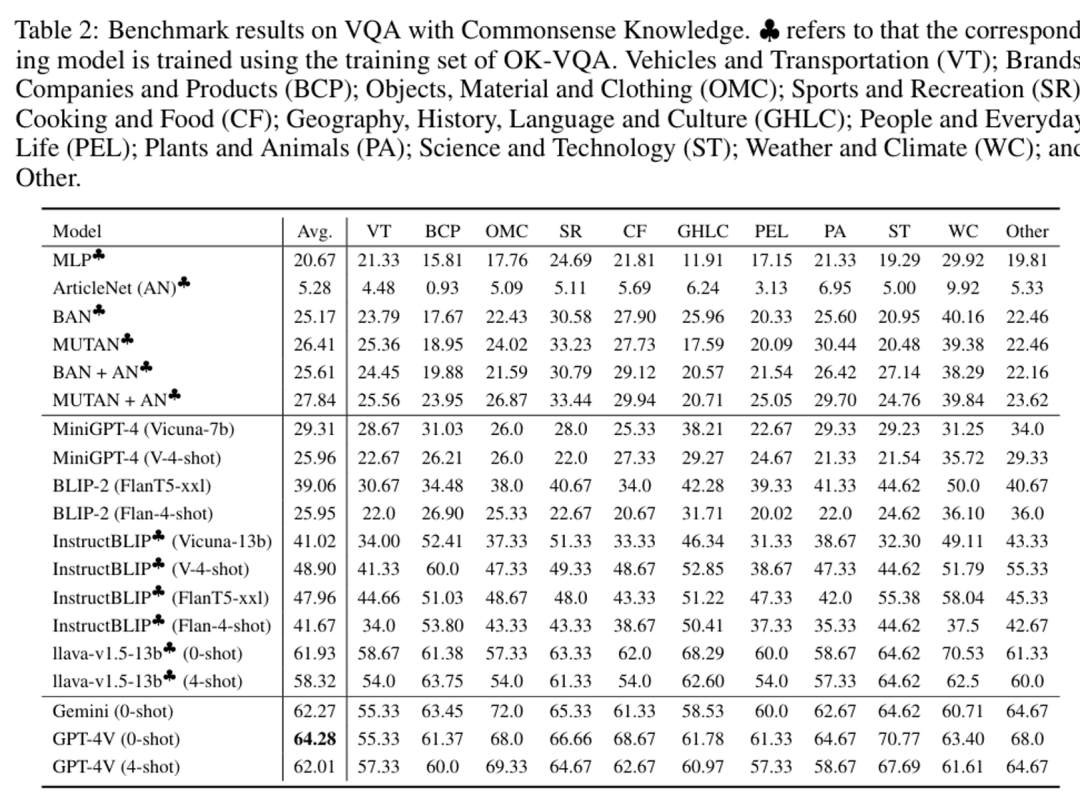
这篇工作评估了多模态大模型GPT4-V在基于知识的视觉问答(Knowledge-based VQA)中的表现。该工作通过判断生成的答案与参考答案集中的任一答案是否完全匹配来评估回答的准确率。
下图展示了GPT4-V在OK-VQA测试集的一个子集上评估时的prompt设计及其表现,准确率可达到64.28%。

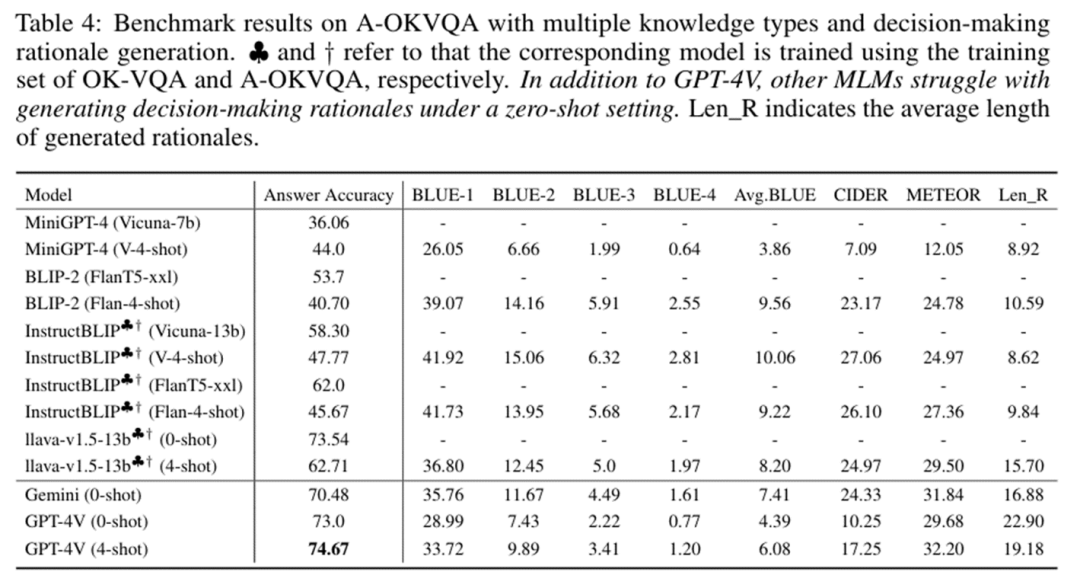
下图展示了GPT4-V在A-OKVQA验证集上评估时的prompt设计和模型表现,答案准确率可以达到74.67%。

参考文献
[1] Marino, K., Rastegari, M., Farhadi, A., & Mottaghi, R. (2019). Ok-vqa: A visual question answering benchmark requiring external knowledge. In Proceedings of the IEEE/cvf conference on computer vision and pattern recognition (pp. 3195-3204).
[2] Schwenk, D., Khandelwal, A., Clark, C., Marino, K., & Mottaghi, R. (2022, October). A-okvqa: A benchmark for visual question answering using world knowledge. In European Conference on Computer Vision (pp. 146-162). Cham: Springer Nature Switzerland.
[3] Hu, Z., Iscen, A., Sun, C., Wang, Z., Chang, K. W., Sun, Y., ... & Fathi, A. (2023). Reveal: Retrieval-augmented visual-language pre-training with multi-source multimodal knowledge memory. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 23369-23379).
[4] ALEXANDROS XENOS, Themos Stafylakis, Ioannis Patras, & Georgios Tzimiropoulos (2023). A Simple Baseline for Knowledge-Based Visual Question Answering. In The 2023 Conference on Empirical Methods in Natural Language Processing.
[5] Lin, Y., Xie, Y., Chen, D., Xu, Y., Zhu, C., & Yuan, L. (2022). Revive: Regional visual representation matters in knowledge-based visual question answering. Advances in Neural Information Processing Systems, 35, 10560-10571.
[6] Hao, D., Jia, J., Guo, L., Wang, Q., Yang, T., Li, Y., ... & Liu, J. (2024). Knowledge Condensation and Reasoning for Knowledge-based VQA. arXiv preprint arXiv:2403.10037.
[7] Li, Y., Wang, L., Hu, B., Chen, X., Zhong, W., Lyu, C., & Zhang, M. (2023). A comprehensive evaluation of gpt-4v on knowledge-intensive visual question answering. arXiv preprint arXiv:2311.07536.


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
实验室开源产品图数据库gStore:
gStore官网:https://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore