文章目录
- 题目
- 摘要
- 方法
- 实验
- 消融实验
题目
大语言模型融合知识图谱的问答系统研究

论文地址:http://fcst.ceaj.org/CN/10.3778/j.issn.1673-9418.2308070
项目地址:https://github.com/zhangheyi-1/llmkgqas-tcm/
摘要
问答系统(Question Answering,QA)能够自动回答用户提出的自然语言问题,是信息检索和自然语言处理的交叉研究方向,将知识图谱(Knowledge Graph,KG)与问答系统融合,正确理解用户语义是一大挑战。虽然知识图谱问答能够通过对问题进行分析理解,最终获取答案,但面对自然语言的灵活性与模糊性,如何处理复杂问题的语义信息、如何提高复杂推理问答的高效性仍是研究难点。
近年来,大型语言模型(Large Language Models,LLM)在多种自然语言处理任务上取得了令人印象深刻的结果,并表现出若干涌现能力。Instruct GPT、ChatGPT1、GPT4等自回归大型语言模型通过预训练、微调(Fine-tuning)等技术理解并遵循人类指令,使得其能够正确理解并回答复杂问题。LLM在各种自然语言处理任务上表现卓越,甚至能够在从未见过的任务上表现出不错的性能,这为正确处理复杂问题展示了统一解决方案潜力。然而,这些模型都存在一些固有局限性,包括处理中文能力较差,部署困难,无法获得关于最近事件的最新信息以及产生有害幻觉事实(Hallucinatory Fact)等。由于这些局限性,将大型语言模型直接应用于专业领域问答仍然存在诸多问题。
一方面难以满足大型语言模型对于硬件资源的要求;另一方面,面对专业领域,大型语言模型的能力仍然有所不足。面对专业领域的问题,大型语言模型的生成结果可能缺乏真实性和准确性,甚至会产生“幻觉事实”。为了增强大型语言模型应对专业领域问题的能力,很多工作采取数据微调的方式修改模型参数,从而让大模型具有更高的专业能力,然而一些文献指出这些数据微调的方法会产生灾难性遗忘(Catastrophic Forgetting),致使模型原始对话能力丧失,甚至在处理非微调数据时会出现混乱结果。为了应对这些问题,本文结合大型语言模型与知识图谱,设计了一种应用于专业领域的问答系统。该问答系统通过将知识库(Knowledge Base ,KB)中的文本知识、知识图谱的结构化知识、大型语言模型中的参数化知识三者融合,生成专业问答结果,因此无需使用数据微调的方式修改模型参数,就能够理解用户语义并回答专业领域的问题。同时,通过采用类似于ChatGLM-6B这样对硬件资源要求较低的模型,以降低硬件对系统的约束。另外,随着大型语言模型技术的发展,研究认知智能范式的转变,是接下来的研究重点,如何将大型语言模型与知识图谱进行有效结合是一个值得研究的课题。因此,本文以研究问答系统的形式,进一步研究大型语言模型+知识图谱的智能信息系统新范式,探索知识图谱与大型语言模型的深度结合,利用专业性知识图谱来增强LLM的生成结果,并利用LLM理解语义抽取实体对知识图谱进行检索与增强。
本文主要贡献有两点:1.提出大型语言模型+专业知识库的基于提示学习(Prompt Learning)的问答系统范式,以解决专业领域问答系统数据+微调范式带来的灾难性遗忘问题。在提升大模型专业能力的同时,保留其回答通用问题的能力。并在硬件资源不足的情况下,选择较小的大模型部署专业领域的问答系统,实现能和较大的大模型在专业领域相媲美甚至更好效果。2.探索了大型语言模型和知识图谱两种知识范式的深度结合。实现了将大型语言模型和知识图谱的双向链接,可以将易读的自然语言转换为结构化的数据进而和知识图谱中的结构化数据匹配以增强回答专业性;可以将KG中的结构化知识转换为更易读的自然语言知识来方便人们理解。
方法
系统实现了以下功能:信息过 滤、专业问答、抽取转化。 为了实现这些功能,系统基于专业知识与大语言模型,利用 LangChain 将两者结合,设计并实现了大型语言模型与知识图谱的深度结合新模式。信息过滤模块旨在减少大型语言模型生成虚假信息的可能性,以提高回答的准确性。专业问答模块通过将专业知识库与大型语言模型结合, 提供专业性的回答。这种方法避免了重新训练大语言模型所需的高硬件要求和可能导致的灾难性遗忘后果。
抽取转化(从自然语言文本抽取出知识图谱结构化数据;将知识图谱结构化数据转化为自然语言文本)是为了进一步探索问答系统新范式而设计。一方面基于大型语言模型提取出专业知识, 将知识图谱结构化数据转化为自然语言文本,易于用户理解;另一方面利用知识抽取出三元组和知识图谱对比验证,可以增强大语言模型回答专业性,同时抽取出的三元组在经专家验证后可 以插入知识图谱中以增强知识图谱。除此之外, 本系统还实现了用户友好的交互服务。如下图所示,系统交互流程是(1)用户向系统提出问题,问题通过信息过滤后,与知识库中的相关专业知识组成提示,输入到专业问答模块中得到答案;(2)信息抽取模块从回答中提取出三元组,与知识图谱进行匹配,获取相关节点数据;(3)这些节点数据可以经用户选择后,同样以提示的形式输入专业问答模块得到知识图谱增强的回答。这种双向交互实现了大型语言模型和知识图谱的深度结合。
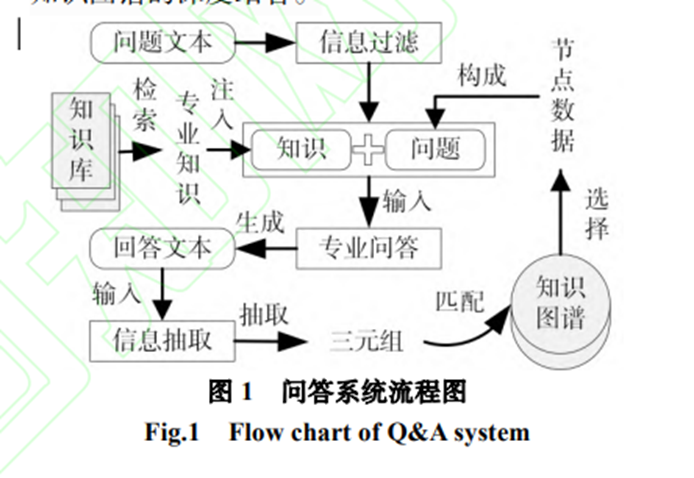
总而言之,本文提出的专业问答系统通过大语言模型与知识图谱深度结合,实现了专业的垂直领域问答效果,并提供用户友好的交互服务。 系统的信息过滤模块减少了虚假信息生成的可能性,专业问答模块提供了专业性的回答,抽取转化模块进一步增强了回答的专业性,并可以对结构化数据进行解释,降低用户理解难度,同时可用专家确认无误的知识进一步增强知识图谱。这种新的问答系统范式为用户提供了更准确、更专业的答案,同时保持了用户友好的交互体验。
从数据构造与预处理、信息过滤、专业问 答、抽取转化四个方面,以中医药方剂领域的应用为例,介绍如何构建系统。 本文针对专业领域,收集相关领域数据进行预处理,设计流程来训练一套易于部署的专业领域问答系统,并探索大型语言模型与知识图谱的融合。 该系统具备三种能力:(1)信息过滤;(2)专业问答;(3)抽取转化。
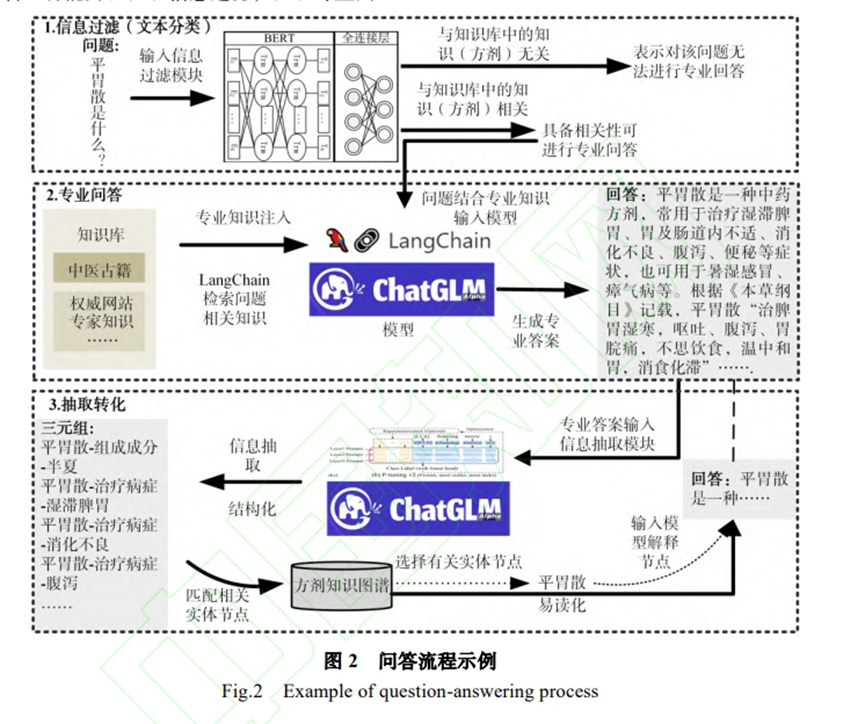
以中医药方剂专业领域为例展示了该系统的问答流程。首先,对输入的中医药方剂相关问题文本进行信息过滤,即文本分类,判断出该文本是否与中医药方剂相关,然后通过 LangChain 在知识库中检索与文本相关的知识,以提示的方式和问题一起输入大模型(ChatGLM-6B),大模型通过推理生成具备专业知识的答案。然后对该回答进行知识抽取,从回答中抽取出三元组。将抽取出的三元组和已有的方剂知识图谱进行匹配,以验证回答的专业性,同时可将知识图谱中的节点以问题的形式输入大模型,获取易读的自然语言解释,从而实现了大模型和知识图谱的双向转换。
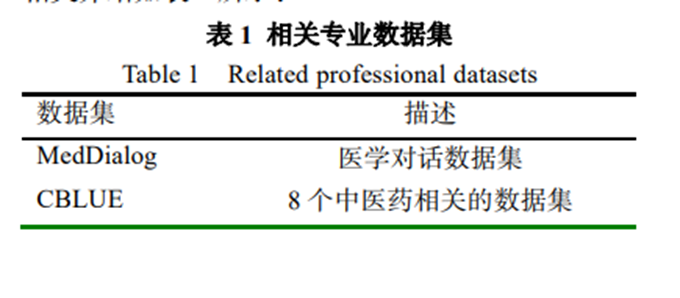
本系统的实现需要收集整理专业数据集,以支持系统的实现。本文基于多种数据构造系统所需的数据集、知识库,并对这些数据进行数据预处理。 (1)基于已有的专业领域数据集。本文直接搜集专业领域已有的相关数据集,参考其构成,从中整理筛选出所需的数据。对于中医药方剂领域,参考以下数据集整理并构建相关专业数据 : MedDialog、CBLUE、COMETA、CMeKG。 相关介绍如下表所示:
权威数据从专业书籍或权威网站收集。这部分数据来自于相关领域的专业书籍和权威网站,用于构建知识库,为大模型的回答提供专业知识支撑。对于中医药方剂领域,主要基于方剂学等专业书籍构建了中医药方剂专业知识库,同 时从 NMPA(国家药品监督管理局)、药融云-中医药数据库群、TCMID 中医药数据库、中医药证候关联数据库等专业权威网站收集中医药方剂领域的相关数据知识。 (3)问题数据。问题数据用来训练信息过滤模型。因为某些专业领域存在问题数据缺失的情况, 本文设计了一种基于提示的方法,使用大模型生成问题数据,首先从相关数据中选择一条数据用来生成提示,将提示输入大模型生成一条数据,重复以上述步骤,直到相关数据被选完。

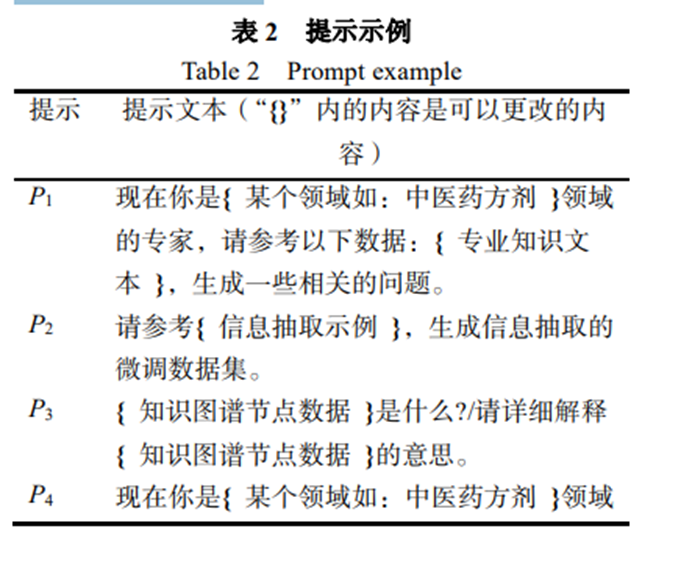
在上表中 D 表示所有的相关数据,d 表示一条相关数据,R 表示所有生成的问题数据,r 表示一条生成的数据。create 根据用户提供的 API_KEY 创建 与 ChatGPT 的链接,select 表示选择一条数据,P 表示根据数据生成合适的提示,chatgpt 表示获取 ChatGPT 生成的回复,abstract 表示从生成回复中提取出问题数据并进行汇总。 在中医药方剂领域,如下表中 P1 所示,将提示 P1 输入 ChatGPT,生成相关问题。中医药方剂领域问答系统的问题数据,80%来自于现有的问答数据集如 MultiMedQA、CMRC2018、CMedQASystem、cMedQA等,本文从中整理相关问题, 并将其按照是否为中医药方剂专业领域添加标签。 20%的中医药方剂相关问题使用大模型生成的方式构建。
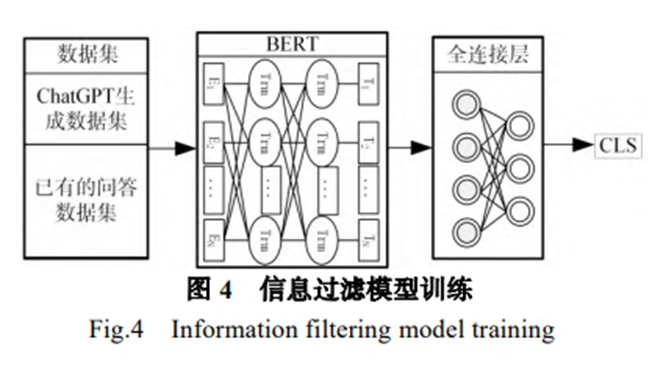
针对专业领域的问答,大型语言模型无需回答其他领域的问题,为此本系统添加了基于 BERT的文本过滤器对问题进行过滤,以限制大模型可以回答的问题范围。 其他模型在面对专业领域的边界问题或交叉问题时往往会产生微妙的幻觉事实,生成错误文本。 尽管使用微调的形式同样也可以使得大模型具备一定的问题甄别能力,但是这种能力在面对和微调数据集中相似的其他问题时,仍然会被迷惑,甚至对于原本可以正确回答的问题也会生成错误的答案。 因此需要单独设计文本过滤器以对信息进行过滤。 假设可输入大模型的所有的问题集合为 Q,大模型在某一专业领域可以回答的问题集合为 R,可以生成专业回答的问题集合为 D,显然有 Q>R>D。 使用微调方式限制将使得 R→D,会让模型回答能力减弱。而使用过滤器的形式,使得 Q→R,将尽可能保证询问的问题在 R 的范围之内,虽然会有部分 R 之外的数据进入大模型,但是由于本文设计的专业增强问答系统仍然保留一定的通用能力,因此对 R 之外的问题也可以进行无专业验证的回答。 信息过滤将保证本系统可以尽可能回答在系统能力范围以内的问题,以减少其产生幻觉事实的可能。
训练过程如下图所示,将训练数据输入 BERT,再将 BERT 的结果输入全连接层(Fully Connected Layer,FCL)得到对本文的分类结果[CLS]。根据数据集中的标签,训练时只需要更新全连接层的参数即可。 一般来说使用 BERT 进行文本分类任务,会采用BERT 结果的分类词向量 H ,基于 softmax 做一个简单的分类器,预测类别的标签 L的概率:P(L|H)= softmax(WH) 这里 W 是分类任务的参数矩阵,最终通过最大化正确标签的对数概率来微调 BERT 和 W 中的所有参数。将其修改为使用全连接层得到每个标签的概率:P(L|H)= FC(H) 训练时输入全连接层的向量维度为 768,具有两个隐藏层,维度分别为 384、768,输出维度为类别个数,这里是一个二分类任务,因此为 2。最终选择概率更大的标签作为分类的结果[CLS]。在中医药方剂学领域中,[CLS]为问题是否与中医药方剂相关,通过过滤问题,减少生成幻觉事实的可能,并同检索结果一起判断能否进行专业回答。
在本文中,我们提出了 FoodGPT,一个用于食品测试领域的大型语言模型。 FoodGPT 基于 Chinese-LLaMA2-13B 基础模型构建,具有增量预训练、指令微调和外部知识图集成。由于图像、扫描文档和私有结构化知识库中存在大量知识,而基础模型缺乏这些知识,因此我们认为有必要进行增量预训练。我们提出了处理这些数据的新方法,并将它们与其他数据一起合并到我们的增量预训练数据库中。在指令微调阶段,我们从论坛中抓取问题答案对,并在领域专家提供的种子指令的指导下,使用 evol-instruct 构建微调数据集。鉴于食品检测领域对输出指标的严格要求,我们还构建了一个知识图作为外部数据库,以协助FoodGPT生成输出。值得一提的是,本文是FoodGPT预发布版本的技术报告,我们将在未来的版本中详细阐述实验细节和分析。
为了使得大模型知识图谱问答系统的回答更具备专业性,本文通过提示的方式注入知识库中的专业知识,增强回答的专业性。通过检索知识库,大模型可以回答其本身能力之外的专业问题,这使得大型语言模型支持的问题边界扩大。这种方式和引入专业数据的微调方法对比,无需重新训练就可以部署一个专业领域大型语言模型。 如下图所示,在中医药方剂领域,本文使用 LangChain+ChatGLM-6B,生成更具备专业知识的回答。本系统基于 LangChain 在知识库中检索与问题相关的专业知识,然后专业知识和问题文本一起 构成 P4输入大模型,最终得到答案文本,这里选择使用 ChatGLM-6B 作为大模型。
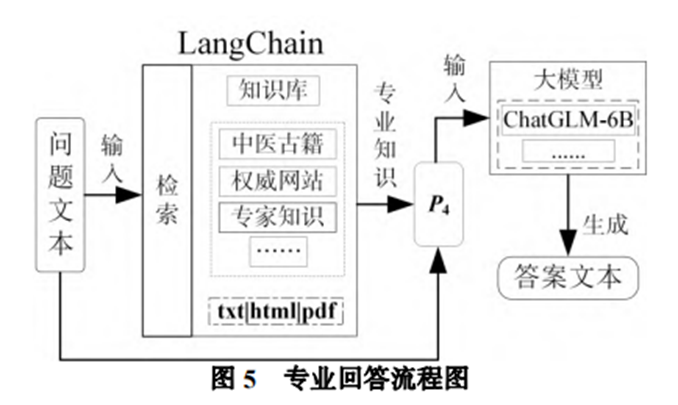
假设知识库中的第 i 个文件为𝐹𝑖(𝑖 = 1,2,3, … , 𝑛), 基于 LangChain 进行检索会将各个文件中的文本进行分块,𝐷𝑖𝑗(𝑖 = 1,2,3, … , 𝑛;𝑗 = 1,2,3, … , 𝑚. )表示对 第 i 个文件的第 j 个文本块。然后对每一块文本建立为向量索引𝑽𝒊(𝑖 = 1,2,3, … , 𝑛 × 𝑚),在检索时将问题文本向量化,得到问题文本向量 Q,最后通过向量相似度计算出和 Q 最相似的 k 个向量索引,并返回其对应的文本块。将匹配到的专业知识文本 D 和问题文本以𝑃4的形式拼接,最终输入 ChatGLM6B 中得到大模型生成的专业回答。该过程的伪代码如下表所示:

在上表中,q 表示问题文本, f 表示知识库文件,d 表示知识文本块,Q 表示问题文本向量,V 表示文本块的向量索引,split 表示划分文本块的过程,trans 表示从文本转化为向量,de_trans 表示从向量转化为文本,score 将返回 k 个最相似的向量索引,model(P4(q,dk))表示将问题文本和专业知识文本以 P4 形式输入大模型 ChatGLM-6B。
该节探索大型语言模型和知识图谱的深度结合。 大模型的回答是易读的自然语言数据,而知识图谱的数据是结构化的知识。为了将两者交互结合,需 要实现两者的相互转换:(1)实现对自然语言的结构化;(2)可将结构化的知识转换为自然语言。前者是信息抽取的任务,后者可以通过提示的方式输入大模型转换成自然语言文本。 以中医药方剂领域的应用为例,(1)对于信息抽取,使用 P-tuning v2 微调的方式强化 ChatGLM6B 的信息抽取能力。具体来说,在语言模型的每一 层上将𝑙个可训练的注意力键和值嵌入连接到前缀 上,给定原始的键向量𝑲 ∈ 𝑹 𝒍×𝒅和值向量𝑽 ∈ 𝑹 𝒍×𝒅, 可训练的向量𝑷𝒌,𝑷𝒗将分别与𝑲和𝑽连接。注意力机制头的计算就变为:headi(x)=Attention(xW(i), [P(i)k :K(i)], [P(i)v :V(i)]) 其中上标(𝑖)代表向量中与第𝑖个注意力头对应的部分,本文通过这种方法来微调大语言模型。 将大模型生成的自然语言答案文本, 输入经过信息抽取增强微调后的大模型中,提取出结构化的三元组信息,将其与知识图谱进行匹配, 进行专家验证后,可以存储到方剂知识图谱中,效果见下图。对于结构数据的易读化,使用提示的方式,将知识图谱相关节点转换为 P3 后,再将 P3 输入大模型得到自然语言的回答,效果见下图。 本文尝试将专业知识图谱与大语言模型结合, 利用大模型生成自然语言回答,抽取出专业的结构化知识,并和已有的专业方剂知识图谱进行知识匹配,以进行专业验证,同时可以将知识图谱中的结构化知识转化成易读的自然语言。
实验
对于问题 1,由于知识库中存在相关的知识, 专家问答系统可以进行专业回答,ChatGLM 则无法生成方剂学的专业回答,相比于 ChatGPT 的回答专家问答系统更精细,不仅有方剂名称、适用范围还有具体的方剂信息。对于问题 2,此问题是数学和方剂学的交叉问题,知识库中并没有相关信息,直接由 ChatGLM 回答,会生成幻觉事实。专业问答系统可以判断无足够专业知识进行回答,进而避免生成幻觉事实。这些结果表明,本文设计的系统具备良好的专业回答能力,同时也能对自身无法专业回复的问题表示拒绝 。 专业问答系统仍然保留 ChatGLM 本身的能力,能对一些绕过信息过滤的问题进行回答,这种能力能够保证在面对专业领域边界问题或交叉问题时可以有较好的回答。

本实验请三个中医药方面的专家对不同模型的回答进行评估,用以验证系统效果。将 100 个问题分别输入三个不同的模型生成答案,然后把来自不同模型的每个问题的结果,交给专家进行评估,比较对于同一个问题,专家更喜欢哪一个模型的回答。 如下图所示,横坐标表示不同的专家,纵坐标表示最满意问题所占问题总数比例。模型 1 是本文所提专业问答系统,模型 2 表示 ChatGLM,模型 3 表示 ChatGPT。由于是对比三个模型的结果,因此只需专家最满意比例大于总体三分之一就可以证明专业问答系统的回答更好。专家们对模型 1 的回答结果最满意总个数分别是 37、42、42,都超过总问题个数的三分之一,因此本文所设计的系统更受专家喜欢。

实验过程中,问题被分为两类,一种是普通问题,另一种是专业问题,两者分别有 50 个问题,共 100 个问题。普通问题是相对常见的问题,对专业知识需求较低;专业问题是考验式问题,类似于考试题,回答专业问题需要具备更多的知识。模型 1 取得了最高的满意率, 可看出本系统提出的方法更受中医药专家的喜欢。 对于简单问题,远远优于其他两个模型,对于专业问题,虽然 ChatGPT 取得最优的结果,但是模型 1 相对于模型 2 仍更受专家喜欢。相对于其他模型,模型 1 的回复更加详细,会补充更多专业知识。但是当问题难度上升,回答问题需求知识更多,当知识库中没有这部分知识时,模型 1 的回答专业性就不如 ChatGPT。这是可能是因为 ChatGPT 训练时所用的语料中涉及专业问题,因此 ChatGPT 在回答专业问题时更具备优势。 结果表明,总体上本文所提系统更受专家喜欢。 虽然面对复杂问题时,表现不如 ChatGPT,但是相对其基线模型 ChatGLM-6B 仍保持更高的满意率。 这表明了本文所提系统的有效性。
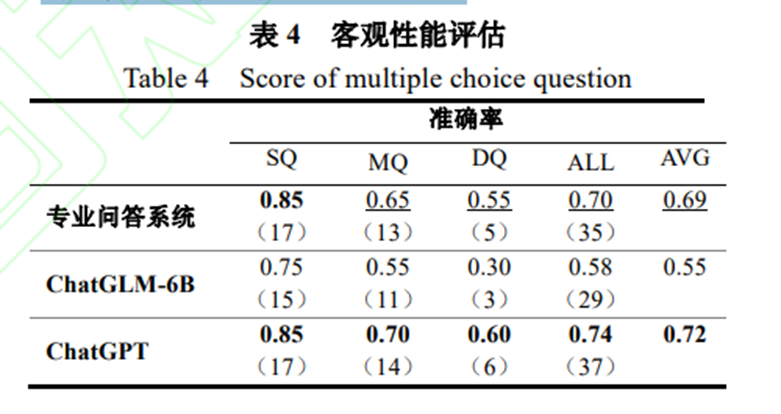
实验过程中,问题按照问题的难度分为三类, 简单题(Simple Question,SQ)、中等题(Medium Question,MQ)、困难题(Difficult Question,DQ)。 准确率以正确问题个数除以总问题个数进行计算。 小括号中的数字表示正确回答问题的个数。从其中结果看,显然随着问题难度提升, 回答的正确率依次下降。对于平均正确率而言,专业问答系统显著高于 ChatGLM-6,略低于 ChatGPT。 说明专业问答系统能够显著提升大模型的专业能力, 甚至能够达到和 ChatGPT 相媲美的结果。 结果表明,和 ChatGLM-6B 相比专业问答系统答对题目的数量更多,从客观上验证了系统的性能。
消融实验
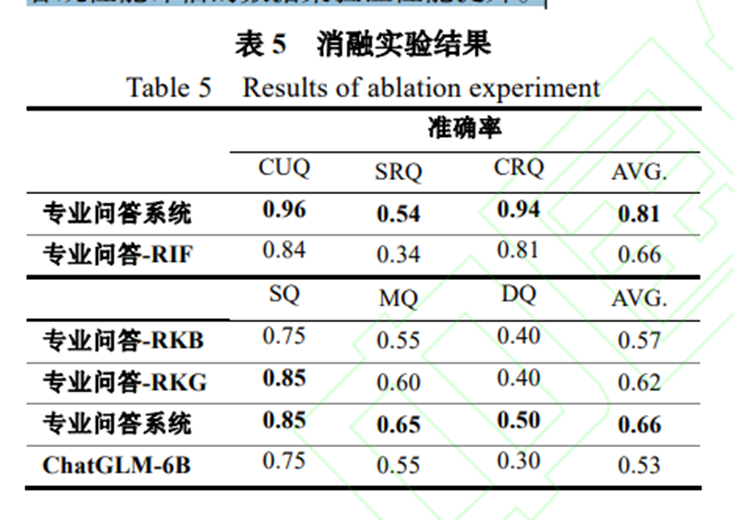
实验过程中,为了验证信息过滤模块的能力, 将输入的问题按照相关程度划分了三种类型的问题, 无关问题(Completely Unrelated Question,CUQ)、 部分相关问题(Some Related Question, SRQ)、完全相关问题(Completely Related Question, CRQ)。对于部分相关问题,是在无关问题的基础上增加相关的信息或在相关问题的基础上增加无关信息,作为干扰。通过将无关信息和相关信息混合的方式制造部分相关问题,可以验证信息过滤的鲁棒性。准确率使用正确过滤问题个数除以问题总个数进行计算。 RIF(Remove Information Filter)表示去除信息过滤,RKB(Remove Knowledge Base) 表示去除知识库,RKG(Remove Knowledge Graph) 表示去除知识图谱交互。去除信息过滤模块后,专业问答系统可以通过合适的提示机制进行信息过滤,从结果看,专业问答-RIF 的过滤准确率低于专业问答系统的过滤准确率,说明了去除信息过滤模块后系统的信息过滤能力有所降低,验证了信息过滤模块的有效性。对于简单问题的回答,专业问答-RKB 的准确率与 ChatGLM-6B 基本相同,专业问答-RKG 的准确率与专业问答系统基本相同,说明对于 SQ, 大模型本身具备一定的回答能力,其增幅主要依靠知识库,知识图谱进行交互增强不明显。对于困难问题,专业问答-RKB 和专业问答-RKG 的准确率低于专业问答系统高于 ChatGLM-6B,可见对于 MQ、 DQ,通过知识图谱进行交互发挥一定的作用,猜测这可能是因为知识图谱能够注入相关知识或辅助大模型进行推理,激活大模型的边缘知识。总体来说 RKB、RKG 都会使得专业问答系统的回答准确率下降,并且高于 ChatGLM-6B 的准确率,由此验证了系统各个模块均发挥作用。对于简单问题知识图谱作用不明显,我们猜测这是因为,回答问题相对简单时,所需要知识是孤立的,无需通过深度推理得出,当不存在相应知识时,就无法通过知识图谱辅助推理得到正确的答案, 因此知识图谱交互对回答的增强不明显。
系统界面截图,展示了系统问答、图谱数据易读化、自然语言回答结构化的效果。左上角的问答截图是用户向系统发出提问,系统生成答案,然后对答案进行结构化,生成三元组,并和已有的知识图谱进行匹配后,展示出右上角的知识图谱节点。用户可以选择其中的节点,用户选择相关节点,系统将其转化为问题再次生成答案,最终两个答案相结合就是系统的回复。 这样即为用户提供了良好的交互服务,也实现了大语言模型与知识图谱的双向交互。 在中医药方剂领域,系统生成的回复有一定的参考价值,但是由于中医药方剂领域本身的一些特性,系统还具有很多可以改进的地方,比如加入中医如何开方的数据和相关问诊的多模态数据如:患者的舌苔、脉象、气色等。该系统针对不同的领域,需有相应的调整。