作者及发刊详情
邓晗珂,华南理工大学
摘要
正文
实验平台
选取模型: T r a n s f o r m e r b a s e Transformer_{base} Transformerbase
训练数据集:WMT-2014 英语-德语翻译数据集、IWSLT-2014 英语-德语互译数据集
Transformer模型压缩
网络模型计算中的输入数据、权重数据和偏置数据都采取线性量化
量化过程:
- 获取训练后的得到的浮点 Transformer 模型,通过百分比校准获取各线性层权重数据的初始量化系数,而后通过均方误差校准获取各线性层的权重数据的量化系数。
- 选取训练集中一部分在上述训练后模型基础上多次前向推理,获取该浮点模型中各层矩阵运算输入数据的分布情况,从而根据百分比校准核均方误差校准获取各层矩阵运算的输入数据的量化系数,利用这些系数计算每层矩阵运算输入数据的量化系数
- 将第1点和第2点得到的系数相乘得到各层偏置数据的量化系数
采用偏移对角矩阵剪枝方法减少神经网络的模型参数量
偏移对角矩阵结构化规则稀疏剪枝的训练策略:
- 载入已训练好的模型参数
- 对分类的权重进行基于偏移对角矩阵的结构化剪枝,整体过程遵循“训练-剪枝-再训练”和分批剪枝相结合的策略
Transformer硬件加速器
加速器硬件架构
包括片内全局缓存(包括输入缓存、权重缓存和中间结果/输出缓存)、运算单元阵列、softmax 计算单元、层归一化计算单元(Layer norm)和控制模块。
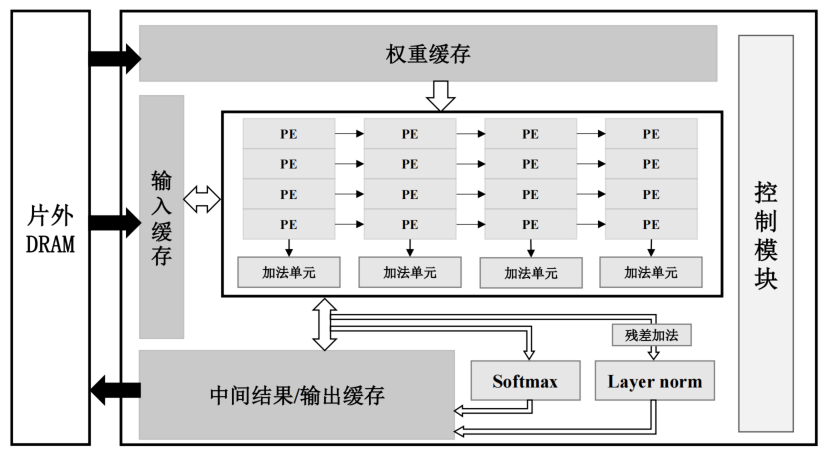
运算单元阵列的设计
多个计算单元(Processing Element, PE)和加法单元组成,每个PE对输入和权重块进行计算
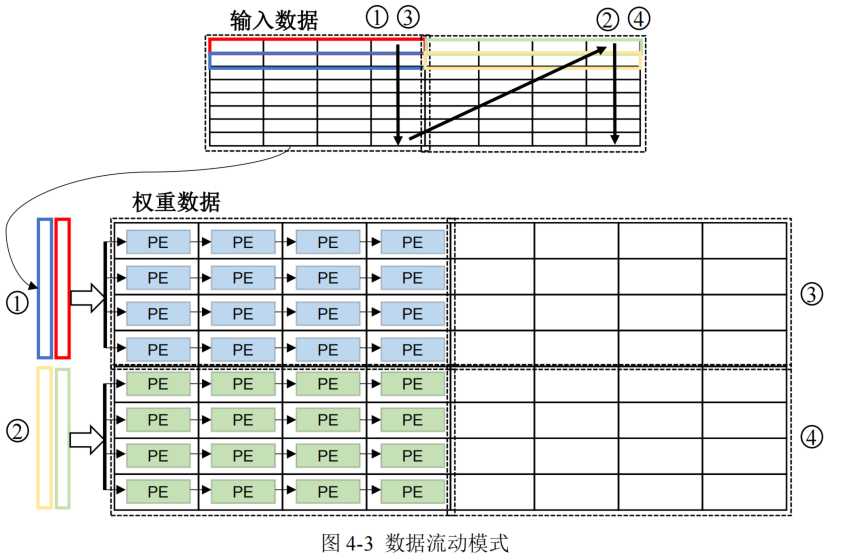
- 输入数据以行数据形式流入运算单元阵列
- 为了减少数据移动成本,本文采取权重复用最大化的策略,并且权重以稀疏块形式送入运算单元,对于输入到运算单元阵列每一块权重,将与之对应的所有输入数据进行遍历
- 输入数据在 PE 阵列间传递可以对其进行复用,输入数据的复用次数取决于 PE 阵列的列大小
PE的设计
每个 PE 中包括 16个乘法器和 1 个数据分配器,可以完成向量乘矩阵操作,输出结果送入加法单元进行加法操作。
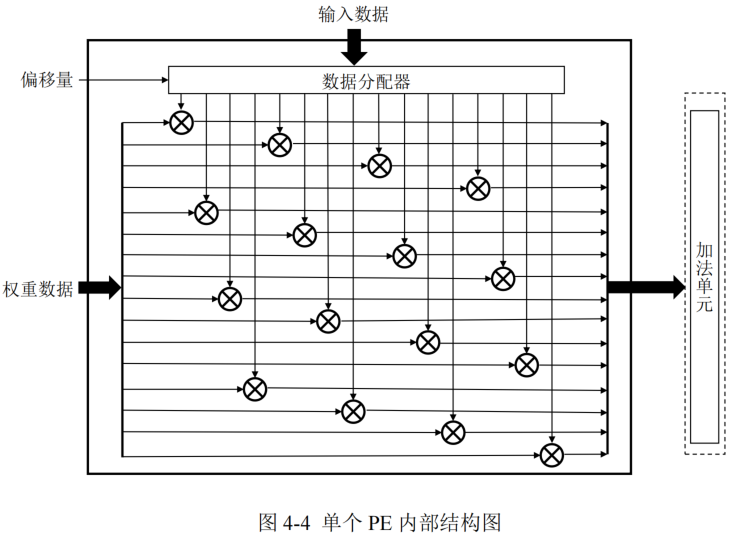
- 数据分配器的作用是根据偏移量对输入数据进行重新排列,从而完成索引匹配,保证分配后的输入数据和所对应的非零值权重数据相乘,同时也统一了密集矩阵运算和稀疏矩阵运算在 PE 内的数据流
这样无需在 PE 外对剪枝后的权重数据进行稀疏解码复原,同时不用对部分和输出或计算结果进行地址索引,乘法器的部分和输出排列顺序与最终输出数据的排列顺序一致

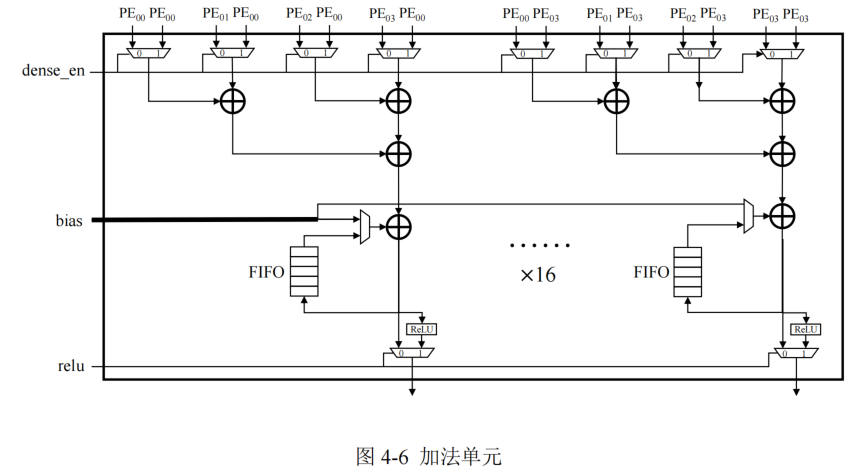
加法器的设计
加法单元负责将所在列的 4 个 PE 产生的部分和结果或者偏置数据进行加法运算,每个加法器单元内部配备用于缓存部分和结果的 FIFO,与加法单元内部的累加器进行数据交互产生最终计算结果,这样可以缩短部分和的数据移动距离。
softmax函数计算单元的设计
包括:数据预处理模块、指数计算模块、累加模块和对数计算模块等模块
softmax的计算:
对于一个K维向量
x
=
[
x
1
,
x
2
,
.
.
.
,
x
K
]
x=[x_1,x_2,...,x_K]
x=[x1,x2,...,xK],则softmax的输出向量s为:
s
j
=
e
x
j
∑
k
=
1
K
e
x
k
s_j=\frac{e^{x_j}}{\sum_{k=1}^{K} e^{x_k}}
sj=∑k=1Kexkexj
- softmax的计算存在除法运算和指数计算的数据溢出两个问题
- 除法溢出问题:通过计算域变换,即将除法运算转换为减法和对数运算
- 指数计算溢出问题:将指数函数的输入进行等比例缩小,即将所有输入数据减去数据中的最大值 x m x_m xm,将指数函数的输入范围限定为 ( − ∞ , 0 ] ,从而避免了数据溢出 (-\infty,0],从而避免了数据溢出 (−∞,0],从而避免了数据溢出
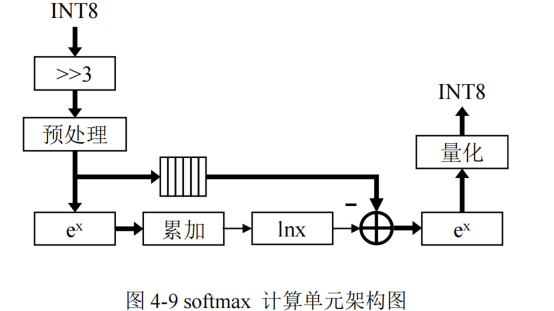
- 数据预处理模块除了要减去最大值 x m x_m xm,还需要对数据进行去量化操作
- softmax 计算单元的输入数据的格式为 INT8,而且 Transformer 中的 softmax 的输入值需要根据KaTeX parse error: Expected '}', got 'EOF' at end of input: \sqrt{d_{k}进行缩小,对应图中的右移 3bit
- 对数计算模块外的其他计算单元的计算并行度为 16
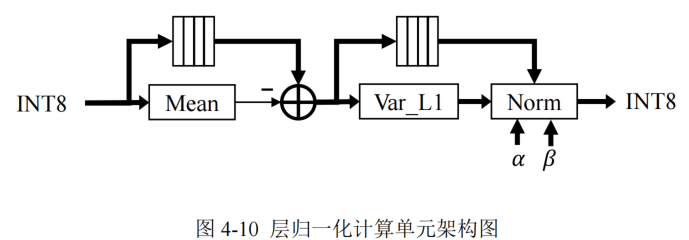
层归一化函数计算单元设计
包括计算模块有:均值计算模块、Var_L1 计算模块和 Norm 计算模块
层归一化计算存在于解码器和编码器的各子层间,为了避免复杂的标准差计算和简化量化推理过程,本文使用 L1 范数的层归一化代替了原始 Transformer 模型中的 L2 范数,通过实验证实了 L1 范数的层归一化不会影响数据分布以及模型性能。
- 计算输入矩阵每行的均值,并将输入数据进行缓存用于均值差计算
- 计算每行输入的均值差,并将均值差缓存,避免重复计算
- 将均值差结果送入 Var_L1 模块计算 L1 范数的标准差
- 在 Norm 模块中将缓存的均值差进行除法运算,并且与对应的可训练参数进行乘加计算。
权重数据存储方案
为了减少非零数据的偏移量索引成本,本设计对硬件加速器的权重数据存储进行了优化排列。
- 加速器运算单元阵列采取权重复用的数据复用模式,在整个计算过程中不重复读取片上权重缓存中的权重数据,所以将偏移量索引与权重数据存储在一起进行同步读取,可以减少偏移量索引的读取次数
- 在运算单元可以根据权重数据中的偏移量索引对输入数据的顺序进行重新排列,实现高效的索引匹配。
数据流
- 加速器的输入数据和各层权重数据从片外 DRAM 中加载,并且在所有计算完成后将最终结果写入到片外存储
- 片内全局缓存负责所有片上数据的缓存,减少片外访存的次数
- 运算单元阵列负责矩阵运算,可以兼容偏移对角稀疏权重矩阵以及密集矩阵计算,并且针对偏移对角稀疏矩阵进行了设计优化。
- softmax 单元负责模型中多头注意力层中的注意力分数计算
- 层归一化计算单元负责对编码器和解码器的子层运算结果进行归一化运算
- 控制模块负责控制整个计算过程中的数据读写和计算使能,根据计算矩阵类型、网络层类型和输入数据长度等信息实现加速器的灵活控制。