前言
此前出了目标改进算法专栏,但是对于应用于什么场景,需要什么改进方法对应与自己的应用场景有效果,并且多少改进点能发什么水平的文章,为解决大家的困惑,此系列文章旨在给大家解读最新目标检测算法论文,帮助大家解答疑惑。解读的系列文章,本人已进行创新点代码复现,有需要的朋友可关注私信我。
一、摘要
在建筑业、工地等场景下,由于受到天气、人数、光照强度、拍摄角度和距离等因素的影响,导致在安全帽智能检测时容易出现准确度低、漏检率大、错检率高的问题.为了解决该问题,提出了一种基于YOLO-ST的安全帽佩戴检测算法.该算法具有两个优势:首先,使用更容易捕获图像全局信息的Swin Transforner作为网络的特征提取器,增强网络对安全帽特征的提取能力;其次,设计密集的空间金字塔池化模块并引入到YOLO-ST中,以获取目标中更加丰富的细节信息.实验结果表明,在公开的SHWD数据集上,YOLO-ST的平均识别精度达到了91.3%.与其它方法相比,YOLO-ST取得了更精确的检测结果.
二、网络模型及核心创新点
个人解读:这篇文章最大的创新在于借鉴稠密连接的思想,对原YOLOv5中的SPP模块进行改进,提出新的DSPP模块,从而有效解决了SPP存在的信息丢失问题,进一步提高了安全帽检测的准确性。Swin Transformer模块之前也有过介绍。损失函数的话,采用的GIoU算是一般的点了。
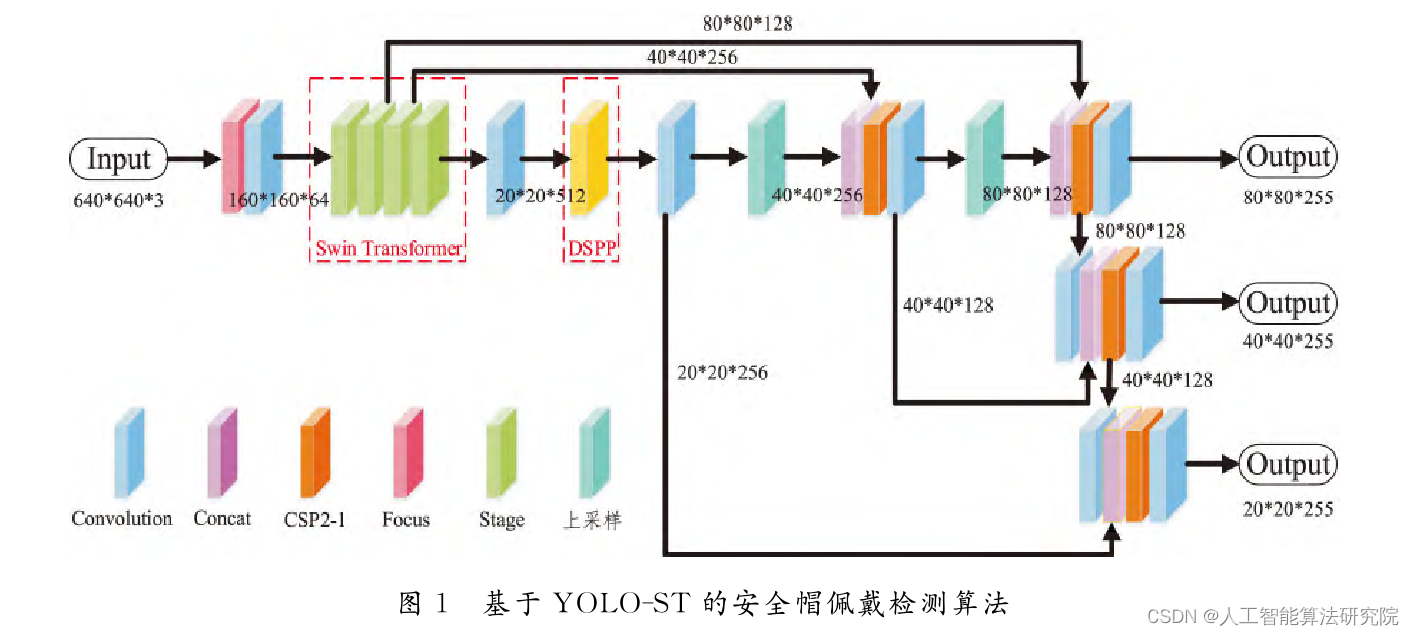
1.特征提取网络Swin Transformer
2.密集的空间金字塔池化DSPP
3. 损失函数
三、应用数据集
本文选用的安全帽检测数据集SHWD包括7581个不同场景、天气、光照条件、人数、拍摄距离的样本图像.主要包含两类样本:佩戴安全帽safe类别和未佩戴安全帽person类别.
四、实验效果(消融实验)
为了研究算法中各个模块对实验结果的影响,本节共设计了四组对比方案.其中,“√”代表模型使用了此模块,“×”代表未使用此模块.实验通过AP30、AP50以及mAP三种评价指标来衡量模型能,消融实验结果如表2所示.
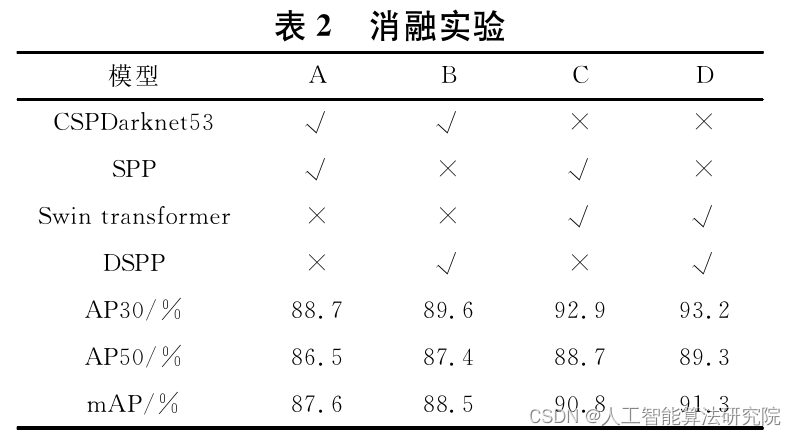
从表2可以看出,模型A的AP30、AP50、mAP分别为88.7%、86.5%和87.6%.在模型A的基础上,模型B采用DSPP模块替代SPP,保证模型获取多尺度信息的基础上,解决由于池化操作导致细节信息丢失的问题,从而提高安全帽检测的准确性.
五、实验结论
实验结果表明,模型B中的各项指标相比模型A均提高了0.9%.模型C是在模型A的基础上,保持原有池化方式不变,同时选择特征提取能力更强的Swin Transformer作为主干网,使得主干网可以提取更加高级的特征信息,进一步提高模型检测能力.相比于模型A,模型C的mAP提高了3.2%.模型D是在模型C的基础上,采用DSPP模块进行池化操作,即本文提出的YO-LO-ST.与模型A相比,AP30、AP50和mAP分别提高了4.5%、2.8%和3.7%,与模型B和模型C相比,mAP分别提高了2.8%和0.5%.综上所述,本文提出的YOLO-ST在安全帽检测任务中的具有更好的准确性.
六、投稿期刊介绍
注:论文原文出自 杜晓刚,王玉琪,晏润冰,古东鑫,张学军,雷 涛;YOLO-ST的安全帽佩戴精确检测算法;陕西科技大学学报.
解读的系列文章,本人已进行创新点代码复现,有需要的朋友可关注私信我。