JavaScript
59、JS的几条基本规范
1、不要在同一行声明多个变量
2、请使用===/!==来比较true/false或者数值
3、使用对象字面量替代new Array这种形式
4、不要使用全局变量
5、Switch语句必须带有default分支
6、函数不应该有时候有返回值,有时候没有返回值
7、For循环必须使用大括号
8、IF语句必须使用大括号
9、for-in循环中的变量应该使用vr关键字明确限定作用域,从而避免作用域
污染
60、JS 的基本数据类型
Undefined、Null、Boolean、Number、String、新增:Symbol
61、JS引用方法
61.1、行内引入
<body>
<input type="button" onclick="alert(行内引入)" value="按钮"/>
<button onclick="alert(123)">点击我</button>
</body>
61.2、内部引入
<script>
window.onload = function0 {
alert("js 内部引入!");
}
</script>
61.3、外部引入
<body>
<div></div>
<script type="text/javascript" src="./js/index.js"> </script>
</body>
注意
1、不推荐写行内或者 HTML 中插入<script>,因为浏览器解析顺序缘故,如果解析到死循环之类的JS 代码,会卡住页面。
2、建议在 onload 事件之后,即等 HTML、CSS 染完毕再执行代码。
62、数组操作
在 JavaScript 中,用得较多的之一无疑是数组操作,这里过一遍数组的一些用法
- map: 遍历数组,返回回调返回值组成的新数组
- forEach: 无法 break,可以用 try/catch 中throw new Error 来停止
- filter: 过滤
- some: 有一项返回 true,则整体为 true
- every: 有一项返回 false,则整体为 false
- join: 通过指定连接符生成字符串
- push / pop: 未尾推入和弹出,改变原数组,返回推入/弹出项[有误]
- unshift / shift: 头部推入和弹出,改变原数组,返回操作项[有误]
- sort(fn) / reverse: 排序与反转,改变原数组
- concat: 连接数组,不影响原数组, 浅拷贝
- slice(start,end): 返回截断后的新数组,不改变原数组
- splice(start, number, value...): 返回删除元素组成的数组,value 为插入项,改变原数组
- indexOf /lastIndexOf(value, fromIndex): 查找数组项,返回对应的下标
- reduce /reduceRight(fn(prev, cur), defaultPrev): 两两执行,prev 为上次化简函数的 return 值,cur 为当前值(从第二项开始)
63、JS 有哪些内置对象
Object 是 JavaScript 中所有对象的父对象
数据封装对象: Object、Array、Boolean、Number和 String
其他对象: Function、Arguments、Math、Date、RegExp、Error
64、get 请求传参长度的误区
误区: 我们经常说 get 请求参数的大小存在限制,而 post 请求的参数大小是无限
制的。
实际上 HTTP 协议从未规定 GET/POST 的请求长度限制是多少。对 get 请求参数的限制是来源与浏览器或 web 服务,浏览或 web 服务限制了 url的长度。为了明确这个概念,我们必须再次强调下面几点:
1、HTTP 协议 未规定 GET 和 POST 的长度限制
2、GET 的最大长度显示是因为 浏览器和 web 服务器限制了 URI的长度
3、不同的浏览器和 WEB 服务器,限制的最大长度不一样
4、要支持 IE,则最大长度为 2083byte,若只支持 Chrome,则最大长度 8182byte
65、补充 get 和 post 请求在缓存方面的区别
- get 请求类似于查找的过程,用户获取数据,可以不用每次都与数据库连接,所以可以使用缓存。
- post 不同,post 做的一般是修改和删除的工作,所以必须与数据库交互,所以不能使用缓存。因此 get 请求适合于请求缓存。
66、闭包
66.1、什么是闭包?
函数A 里面包含了 函数 B,而 函 B 里面使用了 函数 A 的变量,那么 函数B 被称为闭包。
又或者: 闭包就是能够读取其他函数内部变量的函数
function A() {
var a = 1;
function B(){
console.log(a):
}
return B();
}
66.2、闭包的特征
- 函数内再嵌套函数
- 内部函数可以引用外层的参数和变量
- 参数和变量不会被垃圾回收制回收
66.3、对闭包的理解
使用闭包主要是为了设计私有的方法和变量。闭包的优点是可以避免全局变量的污染,缺点是闭包会常驻内存,会增大内存使用量,使用不当很容易造成内存泄露。在 js 中,函数即闭包,只有函数才会产生作用域的概念。
闭包 的最大用处有两个,一个是可以读取函数内部的变量,另一个就是让这些变量始终保持在内存中。
闭包的另一个用处,是封装对象的私有属性和私有方法。
66.4、闭包的好处
能够实现封装和缓存等
66.5、闭包的坏处
就是消耗内存、不正当使用会造成内存溢出的问题
66.6、使用闭包的注意点
由于闭包会使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题,在 E 中可能导致内存泄露
解决方法是: 在退出函数之前,将不使用的局部变量全部删除
66.7、闭包的经典问题
for(var i = 0; i < 3; i++) (
setTimeout(function(){
console.log(i);
}, 1000);
}这段代码输出
答案: 3个3
解析: 首先,for 循环是同步代码,先执行三遍 for,i 变成了 3; 然后,再执行异步代码 setTimeout,这时候输出的 i,只能是 3 个 3 了
有什么办法依次输出 0 1 2
第一种方法
使用let
for(let i = 0; i < 3; i++) [
setTimeout(function(){
console.log(i);
}, 1000);
}
在这里,每个 let 和代码块结合起来形成块级作用域,当 setTimeout0 打印时会寻找最近的块级作用域中的 i,所以依次打印出 0 1 2
如果这样不明白,我们可以执行下边这段代码
for(let i = 0; i < 3; i++) {
console.log("定时器外部:"+ i);
setTimeout(function() {
console.log(i);
}, 1000);
}
此时浏览器依次输出的是
定时器外部: 0
定时器外部: 1
定时器外部: 2
0
1
2
即代码还是先执行 for 循环,但是当 for 结束执行到了 setTimeout 的时候它会做个标记,这样到了 console.log(i) 中,i 就能找到这个块中最近的变量定义
第二种方法
使用立即执行函数解决闭包的问题
for(let i = 0; i < 3; i++){
(function(i){
setTimeout{function(){
console.log(i);
}, 1000);
})(i)
}
67、JS 作用域及作用域链
67.1、作用域
在 JavaScript 中,作用域分为 全局作用域 和 函数作用域
67.2、全局作用域
代码在程序的任何地方都能被访问,window 对象的内置属性都拥有全局作用域
函数作用域
在固定的代码片段才能被访问
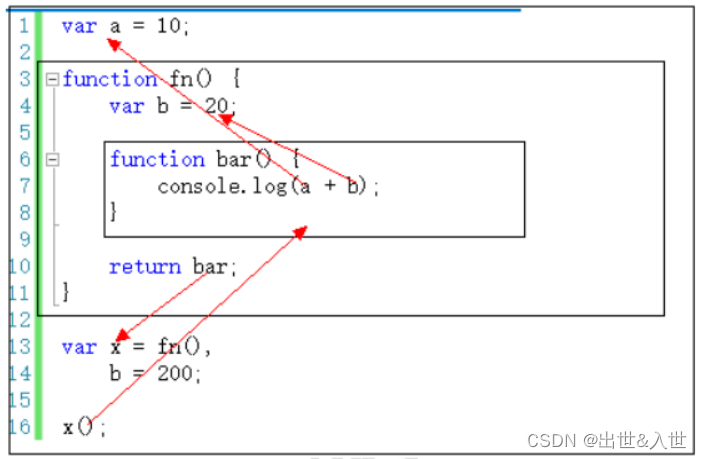
例子:

作用域有上下级关系,上下级关系的确定就看函数是在哪个作用域下创建的。如上,fin 作用域下创建了 bar 函数,那么“fn 作用域”就是“bar 作用域”的上级。
作用域最大的用处就是隔离变量,不同作用域下同名变量不会有冲突。
变量取值:到创建 这个变量 的函数的作用域中取值
67.3、作用域链
一般情况下,变量取值到 创建 这个变量 的函数的作用域中取值。
但是如果在当前作用域中没有查到值,就会向上级作用域去查,直到查到全局作用域,这么一个查找过程形成的链条就叫做作用域链。
68、原型和原型链
68.1、原型和原型链的概念
每个对象都会在其内部初始化一个属性,就是 prototype(原型),当我们访问一个对象的属性时,如果这个对象内部不存在这个属性,那么他就会去 prototype 里找这个属性,这个 prototype 又会有自己的 prototype,于是就这样一直找下去
68.2、原型和原型链的关系
instance.constructor.prototype = instance._proto_68.3、原型和原型链的特点
JavaScript 对象是通过引用来传递的,我们创建的每个新对象实体中并没有一份属于自己的原型副本。当我们修改原型时,与之相关的对象也会继承这一改变。
当我们需要一个属性的时,Javascript引警会先看当前对象中是否有这个属性,如果没有的就会查找他的 Prototype 对象是否有这个属性,如此递推下去,一直检索到Object 内建对象。
69、组件化和模块化
组件化
69.1、为什么要组件化开发
有时候页面代码量太大,逻辑太多或者同一个功能组件在许多页面均有使用,维护起来相当复杂,这个时候,就需要组件化开发来进行功能拆分、组件封装,已达到组件通用性,增强代码可读性,维护成本也能大大降低
69.2、组件化开发的优点
很大程度上降低系统各个功能的耦合性,并且提高了功能内部的聚合性。这对前端工程化及降低代码的维护来说,是有很大的好处的,耦合性的降低,提高了系统的伸展性,降低了开发的复杂度,提升开发效率,降低开发成本
69.3、组件化开发的原则
- 专一
- 可配置性
- 标准性
- 复用性
- 可维护性
模块化
69.4、为什么要模块化
早期的 javascript 版本没有块级作用域、没有类、没有包、也没有模块,这样会带来一些问题,如复用、依赖、冲突、代码组织混乱等,随着前端的膨胀,模块化显得非常迫切
69.5、模块化的好处
避免变量污染,命名冲突提高代码复用率提高了可维护性方便依赖关系管理
69.6、模块化的几种方法
- 函数封装
var myModule = (
var1: 1,
var2: 2,
fn1: function(){
},
fn2: function(){
}
}总结: 这样避免了变量污染,只要保证模块名唯一即可,同时同一模块内的成员也有了关系
缺陷:外部可以睡意修改内部成员,这样就会产生意外的安全问题
- 立即执行函数表达式(IIFE)
var myModule = (function(){
var var1 = 1;
var var2 = 2;
function fn1(){
}
function fn2(){
}
return{
fn1: fn1,
fn2: fn2
};
})();总结: 这样在模块外部无法修改我们没有暴露出来的变量、函数
缺点: 功能相对较弱,封装过程增加了工作量,仍会导致命名空间污染可能、闭包是有成本的
70、图片的预加载和懒加载
- 预加载: 提前加载图片,当用户需要查看时可直接从本地缓存中渲染懒
- 加载:懒加载的主要目的是作为服务器前端的优化,减少请求数或延迟请求数
两种技术的本质:两者的行为是相反的一个是提前加载,一个是迟缓甚至不加载。预加载则会增加服务器前端压力,懒加载对服务器有一定的缓解压力作用。
71、mouseover和 mouseenter 的区别
mouseover: 当鼠标移入元素或其子元素都会触发事件,所以有一个重复触发冒泡的过程。对应的移除事件是 mouseout
mouseenter: 当鼠标移除元素本身 (不包含元素的子元素)会触发事件,也就是不会冒泡,对应的移除事件是 mouseleave
72、解决异步回调地狱
promise、generator、async/await
73、对 This 对象的理解
this 总是指向函数的直接调用者 (而非间接调用者)
如果有 new 关键字,this 指向 new 出来的那个对象
在事件中,this 指向触发这个事件的对象,特殊的是,IE 中的 attachEvent 中的this 总是指向全局对象 Window